1977年,两位以色列教授Lempel和Ziv提出了查找冗余字符和用较短的符号标记替代冗余字符的概念。1985年,由Welch加以充实而形成LZW,简称“LZW”技术。
- 举例说明


- 首先将图像从左到右,从上到下扫描,将所有像素排成一列,叫做被处理像素
- 研究符号出现的规律--拼接
- 构造当前识别序列,这个序列是动态产生的,其初始值为“空”
- 以当前识别序列和当前被处理像素进行拼接
- 如果所形成的符号串在字典中已经有了,则将拼接符号串置为当前识别序列,将下一个像素置为当前被处理像素,重复第(2)步
- 如果拼接所形成的符号串在字典中没有
- (输出当前识别序列在字典中的位置,这位就是该 符号序列的编码
- 生成一个新的字典条目
- 将当前被处理像素变成当前识别序列,将下一个像素置为当前被处理像素,重复第(2)步。?
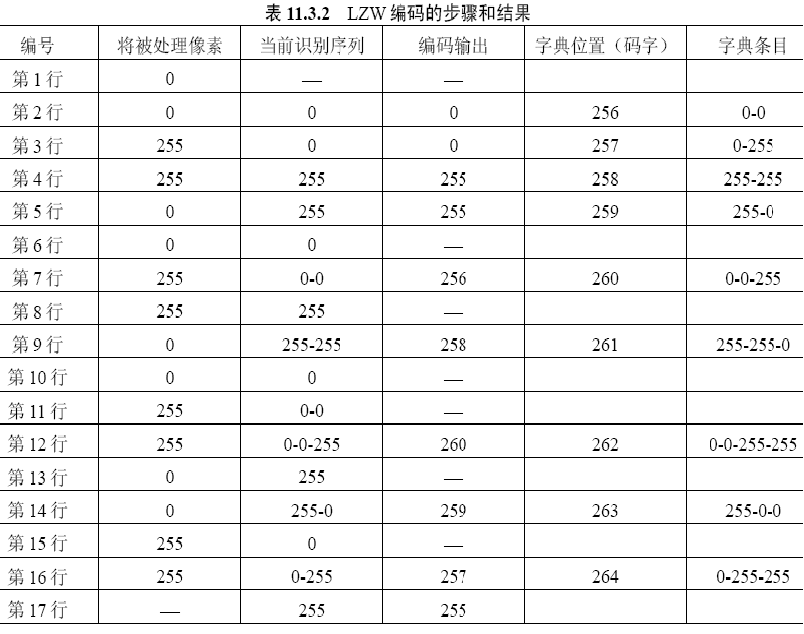
?最后的编码:0,0,255,255,256,258,260,259,257,255
LZW的解码:根据编码查找字典?
| 编码值 | 象素 |
| 0 | 0 |
| 0 | 0 |
| 255 | 255 |
| 255 | 255 |
| 256 | 0-0 |
| 258 | 255-255 |
| 260 | 0-0-255 |
| 259 | 255-0 |
| 257 | 0-255 |
| 255 | 255 |
?
代码实现
以灰度图的LZW压缩编码为例,用Python实现
import cv2 as cv
import numpy as np
import argparse
parser = argparse.ArgumentParser(description='')
parser.add_argument("--mode", choices=["encode", "decode"], type=str, default=None)
parser.add_argument("--encodeFile", type=str, default="pout.png")
parser.add_argument("--decodeFile", type=str, default="lzw.npy")
args = parser.parse_args()
def encode_init():
m_dict = {}
for i in range(0, 256):
m_dict[i] = [i]
return m_dict
def LZW_encode(input_l, m_dict):
previous_char = []
output = []
for s in input_l:
# !!!!!! 用copy
p_c = previous_char.copy()
p_c.append(s)
if p_c in m_dict.values():
previous_char = p_c
else:
output.append(list(m_dict.keys())[list(m_dict.values()).index(previous_char)])
m_dict[len(m_dict)] = p_c
previous_char = [s]
output.append(list(m_dict.keys())[list(m_dict.values()).index(previous_char)])
return output
def LWZ_Decode(input_l, m_dict):
output = []
print(m_dict)
for i in range(len(input_l)):
value = m_dict[input_l[i]]
for ss in value:
output.append(ss)
return output
def encode():
origin = cv.imread(args.encodeFile, 0)
origin_re = origin.ravel()
dictionary = encode_init()
print(dictionary)
print(origin.shape[0])
lzw_data = [origin.shape[0], origin.shape[1]]
lzw_data = lzw_data + LZW_encode(origin_re, dictionary)
print(len(lzw_data))
np.save('LWZ', np.array(lzw_data))
np.save('dictionary.npy', dictionary)
def decode():
lzw_data = np.load(args.decodeFile).tolist()
h = lzw_data[0]
w = lzw_data[1]
lwz_data = lzw_data[2:len(lzw_data)]
dictionary = np.load('dictionary.npy', allow_pickle=True).item()
result = LWZ_Decode(lwz_data, dictionary)
print(len(result))
k = 0
res = np.zeros((h, w))
for i in range(h):
for j in range(w):
if k >= len(result):
res[i][j] = 0
else:
res[i][j] = result[k]
k = k + 1
print(res)
cv.imwrite('result.png', res)
if __name__ == '__main__':
if args.mode == "encode":
encode()
if args.mode == "decode":
decode()
?

