ժҪ
����Ԥ��������ṹ�����ݵ�һ���ؼ����⡣��·Ԥ������ʽ����ʹ��һЩ�÷ֺ���,�繲ͬ�ھӺ�Katzָ������������·�Ŀ����ԡ��������ǵļ��ԡ��ɽ�����,�Լ�������һЩ����ʽ�����Ŀ���չ��,��˻���˹㷺��ʵ��Ӧ�á�Ȼ��,ÿһ������ʽ����һ����ǿ�ļ���,�������ڵ��ʱ�п�������,�������������Щ����ʧЧʱ����������·Ԥ���Ч�����á����ⷽ��,�������ķ���Ӧ���ǴӸ���������ѧϰһ�����ʵ�����ʽ,������ʹ��Ԥ���������ʽ��ͨ����ȡÿ��Ŀ����·��Χ�ľֲ���ͼ,���ǵ�Ŀ����ѧϰһ������ͼģʽӳ�䵽��·���ڵĺ���,�Ӷ��Զ�ѧϰһ���ʺϵ�ǰ����� ������ʽ�����ڱ�����,�����о���������������Ԥ�������ʽѧϰ��ʽ��
����,���������һ����ӱ�Ħ�-˥������ʽ���ۡ������۽���������ʽѧϰͳһ��һ�������,��֤��������Щ����ʽѧϰ�����ԴӾֲ���ͼ�кܺõرƽ������ǵĽ������,�ֲ���ͼ����������·������صķḻ��Ϣ�����,���ڦ�-˥������,���������һ���µķ���,����ͼ������(GNN)�Ӿֲ���ͼѧϰ����ʽ����ʵ������ʾ����ǰ��δ�е�����,�ڶ��������϶����ȶ��ع�����
����
����Ԥ�����Ԥ�������е������ڵ��Ƿ��п��ܴ������ӡ�һЩ����Ч������Ԥ�ⷽ������Ϊ����ʽ����,���繲ͬ�ھӡ�Katz��,��Щ����ʹ��Ԥ��ļ�����Ԥ��ڵ�֮�����·�����һ������ʧЧ,Ԥ��Ч��Ҳ���
����ʽ�㷨������ָijһ������ij����, ����ijһЩ����Ч��Ԥ�ⷽ��
���ڵ�����: ��������ʽ�����Ǽ�����кܶͬ�ھӵ������ڵ�,���п�������, ����������罻��������Ч��, �����ڵ������������, ���й�ͬ�ھӵ����������ʺܿ��ܲ�û�������
����ʽ�㷨ѧϰ������ͼ�п��Ա��۲쵽�Ľڵ�������Ե�ṹ�ڵ�����, ��Щ��������ֱ�Ӵ�ͼ�м������, ��Щ����Ҳ����Ϊͼ�ṹ����
��һ��������� Zhang��Chen��������ʽ�㷨���Ա���ΪԤѵ����ͼ�ṹ����, �����һ��WLMN(��)��ģ��, ���ģ��ͨ����ȡ������Χ�ľֲ������ͼ����Ϊѵ������, ʹ��һ��ȫ���ӵ�������ȥѧϰ��Щ�����ͼ��Ӧ����������ͨ��, ���������ģ��������Ԥ������Ч���ܺ�
�������� Weisfeiler-Lehman Neural Machine for Link Prediction
�����ͼ��һ�Խڵ� (x, y) �Լ��� h �����ھӽڵ����, һ�������ͼֻ����x,y��ֱ���ھ�, ����������x,y���ھӽڵ� �� �ھӵ��ھӽڵ�, �Դ�����, ��Щ�����ͼ����Ϊ����Ԥ���ṩ�ḻ����Ϣ, ���е�һ������ʽ�㷨���Դӷ����ͼ�м������
���о����� : �߽�����ʽ�㷨������Ҫ���ڵͽ�����ʽ�㷨, Ϊ��ѧϰ�߽�����, ������Ҫһ���dz��������ȥ���������ͼ. ��������hԽ�ߵ�������ѵ��ʱ��Ҫ���Ĵ������ڴ���Դ��ʱ��, Ȼ�����������һ������ :
�Ƿ�����б�Ҫ��ô���������ѧϰ�߽�����ʽ�㷨��?
������, ͨ���о�����Ԥ������ڻ���, ����ͨ��٤��˥�����ۿ��ԶԴ�����ĸ߽�����ʽ����ͳһ.
���µ� : ����٤��˥������, ʹ��һ��С��h������ͼȥ�ƽ�������ͼ, �Դ���ʹ�õ�������ͼȥѧϰ�߽�����ʽ������.
���ĵĹ��� :
�� �����һ��ѧϰ����Ԥ�������������ʽѧϰ��������,֤���˴Ӿֲ���ͼ��������������ѧϰ�ĺ�����
�� �����SEAL��һ������GNN����������Ԥ����(����ͼ��ʾ)��SEAL������������ʽ������DZ���������������������Ƕ�뷽�����кܴ����ơ�SEALҲ����֮ǰ���Ƚ��ķ���WLNM��
������ :
���Ŷ���
��
DZ����������ʽ����
���ij���ͼ�ṹ������,���о���DZ����������ʽ�����Խ�������Ԥ�⡣DZ����������ͨ���ֽ������һЩ�����ʾ,��ѧϰÿ���ڵ�ĵ�άDZ�ڱ�ʾ/Ƕ�롣ʾ����������ֽ�[3]�������ģ��[18]�ȡ����,�Ѿ��������������Ƕ�뼼��,����DeepWalk [19]��LINE [21]��node2vec [20],����Ҳ��DZ����������,��Ϊ����Ҳ�����طֽ���һЩ����[22]����ʽ����ͨ���Խڵ����Ե���ʽ�ṩ,�����йظ����ڵ�ĸ��ָ�����Ϣ���������,��ͼ�ṹ������DZ����������ʽ�������Ͽ����������
ͳһ������Ԥ�������ʽ����
�����ƪ��, ��Ҫ�ǽ�������Ԥ������ʽ����ĸ��ֻ���, �����������еĴ���ͼѧϰ����, ���Ա�ƪ����ȥ����ijһ���ض������ķ������, ������Ҫ���ص��ע�ڳ�ȡ��������ͼ�е�����ʽ��������Ϣ��
�����ͼ�Ķ��� :
����һ��ͼΪ :
G
=
(
V
,
E
)
G=(V,E)
G=(V,E) ���������ڵ�
x
,
y
��
V
x, y \in V
x,y��V
��Ӧ�� h ������ͼ
G
x
,
y
h
G_{x,y}^h
Gx,yh? �Ǵ�ͼ
G
G
G���Ƶ����Ľڵ㼯:
{
i
�O
d
(
i
,
x
)
��
h
?or?
d
(
i
,
y
)
��
h
}
\{i \mid d(i, x) \leq h \text { or } d(i, y) \leq h\}
{i�Od(i,x)��h?or?d(i,y)��h}
����1
�κ�
(
x
,
y
)
(x,y)
(x,y)�� h �� ����ʽ�����Դ�
G
x
,
y
h
G_{x,y}^h
Gx,yh?��ȷ�ļ���
����,һ��2���İ�Χ��ͼ�����������κ�һ�Ͷ��������������������Ϣ������,����һ�Ͷ�������ʽ�������ֲ���Χ��ͼ�ܺõظ���,������ѧϰ�߽�����ʽ������˵,�ƺ���Ȼ��Ҫһ���dz����h������ʽ���������˾��ȵ���,��������ķ�������,ѧϰ�߽�����ʽ������С��h��Ҳ�ǿ��еġ�
��������ͨ������õݼ�����ʽ��֧����һ�㡣���ǽ�������ijЩ������,�õݼ�����ʽ���Ժܺõش� h-hop
��Χ����ͼ������,���ǻ���֤��,�������������ĸ߽�����ʽ����������ͳһ������õݼ�����ʽ�Ŀ���С�
����1: ٤��˥������ʽ
(
x
,
y
)
(x,y)
(x,y)��
��
\gamma
�� ˥������ʽ�������µ���ʽ :
KaTeX parse error: No such environment: equation at position 7: \begin{?e?q?u?a?t?i?o?n?}? \mathcal{H}(x,��
������ʽ��
��
\gamma
���ǽ���0��1֮���˥������,
��
\eta
����
��
\gamma
����һ������������������, ���Ͻ���һ������
������,���ǽ�֤����һ��������,һ��
��
\gamma
��˥������ʽ���Դ�һ��h����Χ��ͼ�н���,���ҽ������������h��ָ����С��
����2
����һ��
��
\gamma
��˥������ʽ
H
(
x
,
y
)
=
��
��
l
=
1
��
��
l
f
(
x
,
y
,
l
)
\mathcal{H}(x, y)=\eta \sum_{l=1}^{\infty} \gamma^{l} f(x, y, l)
H(x,y)=����l=1��?��lf(x,y,l) ���
f
(
x
,
y
,
l
)
f(x,y,l)
f(x,y,l)���� :
Ȼ�� H(x,y) �Ϳ��Դ� G x , y h G_{x,y}^h Gx,yh?�н��Ƶõ�, ���ҽ���������� h ����������ָ��������
֤������ :
SEAL : ����GNN������ʵ��
�ڱ��½���Ҫ�ǽ���SEAL���, SEAL�����Ҫ��ѧϰͼ�ṹ��һ��������������Ԥ��.
�������� :
�� ��ȡ�����ͼ
�� ����ڵ���Ϣ����
�� GNNѧϰ
����һ������, Ŀ���ǿ����Զ���ѧϰһ���ܹ���ý��������γɵ�����ʽ����, �ܵ����۽��������, �ú�����������Χ�ķ����ͼ��Ϊ����, �����һ�����Ӵ��ڵĿ�����. Ϊ��ѧϰ������һ������, �����ڷ����ͼ��ѵ��һ��ͼ�����硣
SEAL�ĵ�һ���� : ��ȡһ������Ŀ��Ա��۲쵽�������� �� ���ɱ��۲쵽�ĸ����ӵķ����ͼ������ѵ�����ݡ�GNNͨ������
(
A
,
X
)
(A,X)
(A,X) ������, ����
A
A
A����Ϊ������ͼ���ڽӾ���,
X
X
X�Ƿ����ͼ�Ľڵ���Ϣ����, ÿһ���Ƕ�Ӧһ���ڵ������������
SEAL�ĵڶ����� : Ϊÿ�������ͼ����ڵ���Ϣ����
X
X
X ,��һ������ѵ��һ���ɹ��� GNN����Ԥ��ģ���൱��Ҫ, �������������������, ���� SEAL�еĽڵ���Ϣ����
X
X
X����������� : �ṹ�ڵ��ǩ���ڵ�Ƕ�� �� �ڵ����ԡ�
�ṹ�ڵ��ǩ
�ڵ���Ϣ���� X X X�ĵ�һ��������ÿ���ڵ�Ľṹ��ǩ, �ڵ��ǩ���� : f ( x ) : V �� N f(x) : V \rightarrow N f(x):V��N �����ͼ�е�ÿһ���ڵ� i i i���ᱻ����һ��������ǩ f ( i ) f(i) f(i), Ŀ����Ϊ��ʹ�ò�ͬ�ı�ǩ����ǽڵ��ڷ����ͼ�еIJ�ͬ�Ľ�ɫ��
- ���Ľڵ�x��y���������ڵ�Ŀ��ڵ�
- �����Ľڵ��в�ͬ���λ�õĽڵ�
�����Ľڵ�����λ�ò�ͬ�Ľڵ�����ӽṹ��Ҫ��Ҳ��ͬ, һ���ʵ��Ľڵ�Ӧ�ñ�dz���Щ����, ����GNN��Ԥ��Ŀ��ڵ�֮���Ƿ�����, �Ҷ�ʧ�ṹ��Ϣ��
�ڵ�ı�Ƿ��������� : - Ŀ��ڵ� x �� Ŀ��ڵ�y �ı�ǩ��������ͬ�ı�ǩ
- һ���ڵ�
i
i
i ��һ����յ���ͼ�е�����λ�ÿ�������������������Ľڵ�İ뾶������, �� :
(
d
(
i
,
x
)
,
d
(
i
,
y
)
)
(d(i, x), d(i, y))
(d(i,x),d(i,y))
���, ��������ͬ�Ĺ���ϵĽڵ������ͬ�ı�ǩ, �����ڵ�ı�ǩ�Ϳ��Է�Ӧ�ڵ�����ͼ�е����λ�úͽṹ��Ҫ��.
����������,����������µ�˫�뾶�ڵ���(DRNL)������,����ǩ 1 ����� x �� y��Ȼ��,�����κξ��� ( d ( i , x ) , d ( i , y ) ) = ( 1 , 1 ) (d(i, x), d(i, y)) = (1, 1) (d(i,x),d(i,y))=(1,1)�Ľڵ� i,�����ǩ ( f l ( i ) = 2 ) (f_{l}(i) = 2) (fl?(i)=2)���뾶Ϊ (1, 2) �� (2, 1) �õ���ǩ 3. �뾶Ϊ (1, 3) �� (3, 1) �Ľڵ�õ� 4. ���� (2, 2) �Ľڵ�õ� 5. ���� (1, 4) �� (4, 1) �Ľڵ�õ� 6. �ڵ��� (2, 3) �� (3, 2) �õ� 7���Դ����ơ����仰˵,���ǵ����ؽ�����ı�ǩ��������и���뾶 w.r.t �Ľڵ㡣�������Ľڵ�,���б�ǩ f l ( i ) f_{l}(i) fl?(i)��˫�뾶 ( d ( i , x ) , d ( i , y ) ) (d(i, x), d(i, y)) (d(i,x),d(i,y)) ����
���DZ�ں���ʽ����
���˽ṹ�ڵ��ǩ֮��,�ڵ���Ϣ���� X ���ṩ�˰���DZ�ں���ʽ�����Ļ��ᡣͨ����ÿ���ڵ��Ƕ�������������ӵ����� X �е���Ӧ��,���ǹ۲쵽 GNN ����ͨ��������ⲿ����Ϣ�������ҳ��������Ӵ�����Ϣ�������Ż���������ǵ�ʵ���з������ܲ��ѡ����ǵļ����ǽ� E n E_n En? ��ʱ���ӵ� E ��, �����Ӳ����ڵıߡ�����,����ѵ�����ӽ�������ͬ�����Ӵ�����Ϣ��¼��Ƕ����,��� GNN ����ͨ������ⲿ����Ϣ�������ӽ��з��ࡣ����ƾ������֤����һ���ɶ� SEAL �����ܴ����ߡ����ǽ��˼�������Ϊ��ע�롣
ʵ����
Code : https://github.com/muhanzhang/SEAL/tree/master/Python
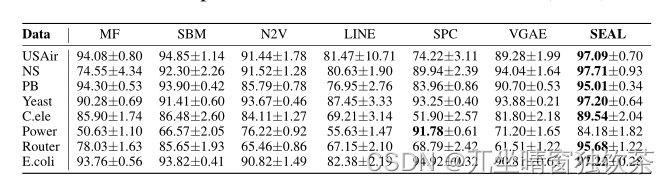
ͼ1��������ʽ�����ıȽϽ��

ͼ2����DZ�������ȽϵĽ��