
introduction
���һ�ּĽ�SSD���������������Ŀ����,�÷����м����ص�:
- �ѱ߽�������ռ���ɢΪ��feature map��ÿ��λ���Ͼ��в�ͬ��С�ͳߴ��һ��Ĭ�ϵ�box
- �����������Բ�ͬ�ֱ��ʵĶ��feature map��Ԥ��,������Ȼ�Ĵ�����ͬ��С��Ŀ��
- ��һ������Ŀ�������IJ���ҪΪ�߽��������ػ��������������,ͬʱ����Щ�����ķ���һ����ȷ��
SSD��������˸߾��ȼ����ٶ�,59FPS with mAP 74.3% on VOC 2007 test,VS.Faster R-CNN 7FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%.������������Ϊ������bounding box proposals �Լ����������ػ������ز����Ρ�ͨ��һϵ������,���Դ�����Ӿ��ȡ���Ҫ�������¼�������:
- ʹ��С�ľ����˲���ȥԤ��bounding box λ��Ŀ������offsets��
- ��������Ԥ����(�˲���)���ڲ�ͬ�ݺ�ȵļ��,���ҽ���Щ�˲��������������һ���εĶ��feature maps���������ڶ��scales�Ͻ��м�⡣
ͨ����Щ���ر���ʹ�ö�����ڲ�ͬ�߶��Ͻ���Ԥ��,�����ڵͷֱ��ʵ�������ȡ�ýϸ߾��ȵļ����,��һ�����Ӽ���ٶȡ�
���߽���Ҫ�����ܽ�Ϊ���¼�������:
- �����Ŀǰ���ε�yolo �ٶȸ���,���������Faster R-CNN����ҪRPN ��pooling�ļ�����ȷ�����졣
- SSD�ĺ�����ʹ��С�ľ����˲�����feature maps��,ΪĬ�ϵ�bounding box�ļ���Ԥ����������box offsets��
- Ϊ��ȡ�ø߾���,��ͬscales��feature map������ͬscales��Ԥ����,���Ҹ����ݺ����ʽ�ķ���Ԥ������
- ��Щ�������������һ���˵��˵�ѵ������,��ʹ�ڵͷֱ���ͼ��������Ҳ����ȡ�þ��Ⱥ��ٶȵ�ƽ�⡣
SSD

default box
Faster R-CNN�в�����RPN�ڶ�������ͼ�϶Խ�������Ԥ��,Ϊ��ʹ������ܴ�����ͬ��С��Ŀ��,������3�ֲ�ͬ�����ͳߴ繲9��anchor��SSD��Ϊ����ⷽ��,���Խ�������Ԥ��,ֱ�Ӷ�Ŀ��ñ߽�����Ԥ��,Ԥ��ʱ,������default box�ĸ���(�൱��Faster R-CNN�е�anchor),SSD�ڲ�ͬ�ߴ�����ͼ�ϼ�ⲻͬ��ͬ�ߴ��Ŀ��,��˲�ͬ�ߴ��default box���ɲ�ͬ�ߴ������ͼ��ʾ,Խ���������default box�ߴ�Խ��,�������ϴ�Ŀ��,Խ�����ײ��default box �ߴ�ԽС�������СĿ��,��ͼ����ʾ,8x8�е���ɫ������Ԥ��è,4x4�еĺ�ɫ������Ԥ���
��ͼ��ʾΪ��ͬscales��feature map,�ֱ�Ϊ 8 ? 8 / 4 ? 4 8*8/4*4 8?8/4?4,ÿ��feature map�ϵ�ÿ��cell����4��bounding box,������ÿ��λ�þ��в�ͬ������default box�ļ���,����ÿ��bounding boxԤ������״ƫ�ƺ������������Ŷȷ�������ѵ���ڼ�,���Ƚ���ЩĬ��box����ʵ�����ƥ��,��������Ĭ�Ͽ�ƥ�乷,һ��ƥ��è,�ͽ�����Ϊ������,�������Ϊ��������ģ����ʧ��λ����ʧ�����Ŷ���ʧ�ļ�Ȩ�͡�
Model
SSD�ǻ���ǰ��������+NMS�Ľṹ,ǰ��������������bounding box�Ĺ̶��ߴ�ļ����Լ�����Щbox�е�Ŀ��ʵ�������Ե÷�,������һ���Ǽ���ֵ����NMS�����������ļ����������ڵ�����ʹ��һ����������ͼ�������������֮ǰ�IJ���,���߳�Ϊbase network,����backbone,�������������˸����ṹ�������ɾ���������Ҫ�����ļ��:
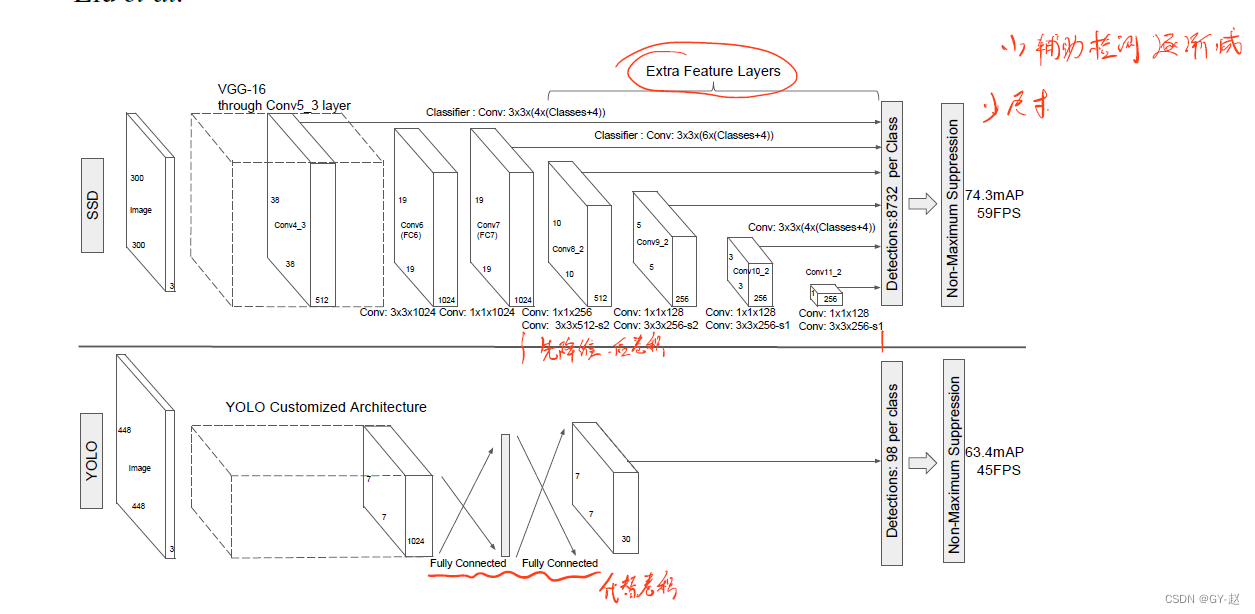
-
��߶�����ӳ�����ڼ��.�ڻ��������ĩβ���Ӽ���������,��Щ��ijߴ���С,����Ԥ���߶ȼ��,����Ԥ����ĵ�ģ����ÿһ�������㶼��ͬ������ͼ��ʾ,�ڶ������������,�����ijߴ�Խ��ԽС��
-
���ڼ��ľ���Ԥ������ÿһ�����ӵ�������(������������е�������)����ʹ��һϵ�о����˲������ɼ��Ԥ��Ĺ̶����ϡ���ͼ2��ʾ��Щ��λ��SSD����Ķ��㡣����һ��ӵ��p��channel,m*n��С������layer,����Ԥ��DZ�ڼ������Ļ���Ԫ����һ��** 3 ? 3 ? p 3*3*p 3?3?p**��С������,����Ϊÿһ���������һ��score,�Լ������Ĭ��box�������״ƫ�ơ��� m ? n m*n m?n��ÿ��λ�����С�˶���ʹ��,�������ֵ��
-
Ĭ��box & �ݺ�ȡ��������綥��Ķ��feature map,��һ��Ĭ��box��ÿһ��feature map��cell��Ӧ����,Ĭ��box�Ծ����ķ�ʽƽ����������feature map,����ÿ����Ӧ��cell��box��λ���ǹ̶���,����һ��ӵ��k��Ĭ��box�ĵ�cell,Ҫ����C��score(C�����)�Ͷ�Ӧ��ԭʼĬ��box����״ƫ�ƨC4������,������feature map��ÿ��λ��Ӧ�� ( C + 4 ) ? K (C+4)*K (C+4)?K���˲���,���� m ? n m*n m?n��С��feature map,һ������ ( C + 4 ) ? K ? m ? n (C+4)*K*m*n (C+4)?K?m?n�����
ѵ��
ѵ��SSD��ѵ��ʹ��region proposal��������Ҫ��������,��Ҫ��ground truth information ��������������ϵ��ض������һ��ȷ���˷���,�Ͷ˵��˵�Ӧ����ʧ�����ͷ���,ѵ������ѡ��Ĭ��box�ļ��Ϻͼ��ߴ�,�Լ�Ӳ�������ھ��������ǿ���ԡ�
ƥ�����
��ѵ��������,��Ҫȷ����ЩĬ��box��Ӧ����ʵ���,����Ӧ��ѵ�����硣����ÿ��ground truth box,�Ӳ�ͬλ�á��ݺ�ȺͲ�ͬ�ߴ��default box����ѡ����ÿ��ground truth box ��������IoU��default box����ƥ�䡣Ȼ��default boxes�����iou����0.5��ground truth box����ƥ�䡣����������ѧϰ����,��������Ԥ�����ص���Ĭ��box����߷�,������Ҫ����ֻѡ��Iou����һ����
ѵ��Ŀ��
SSDѵ��Դ��Multibox Objective����,������չ�����Դ�����Ŀ�������
x
i
,
j
p
=
{
1
,
0
}
x_{i,j}^{p}=\{1,0\}
xi,jp?={1,0}�ǽ���
i
i
i��default box�����
p
p
p�ĵ�
j
j
j��ground truth box����ƥ���ָʾ�����������ϵ�ƥ�����,������
��
i
x
i
,
j
p
?
1
\sum_{i}x_{i,j}^{p}\geqslant1
��i?xi,jp??1, �ܵ�Ŀ����ʧΪ��λ��ʧ�����Ŷ���ʧ�ļ�Ȩ��:
L
(
x
,
c
,
l
,
g
)
=
1
N
(
L
c
o
n
f
(
x
,
c
)
+
��
L
l
o
c
(
x
,
l
,
g
)
)
L(x,c,l,g)=\frac{1}{N}(L_{conf}(x,c)+\alpha L_{loc}(x,l,g))
L(x,c,l,g)=N1?(Lconf?(x,c)+��Lloc?(x,l,g))
����N����ƥ��default boxes����Ŀ,���N=0,��������ʧΪ0.
��λ��ʧ(localization loss)��Ԥ��box( l l l)��ground truth box( g g g)����֮���smooth L1 ��ʧ��������Faster R-CNN ,�ع����default box����������( c x , c y cx,cy cx,cy)�Լ�����( w w w)�߶�( h h h)��
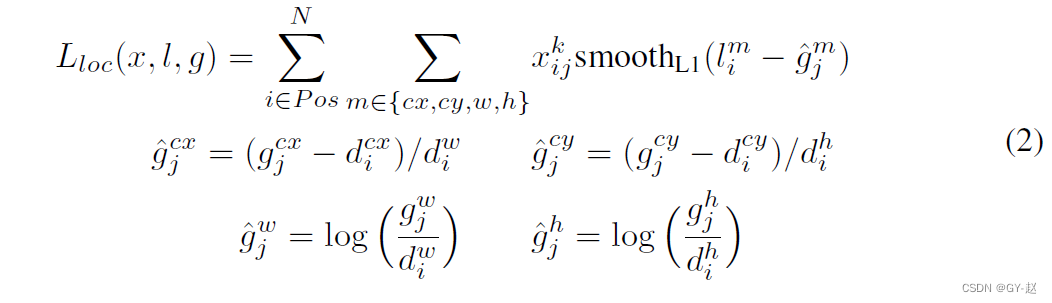
���Ŷ���ʧ(confidence loss)�Ƕ��������ŵ�sofrmax��ʧ(
C
C
C),ͨ��������֤����Ȩ��
��
\alpha
����Ϊ1.
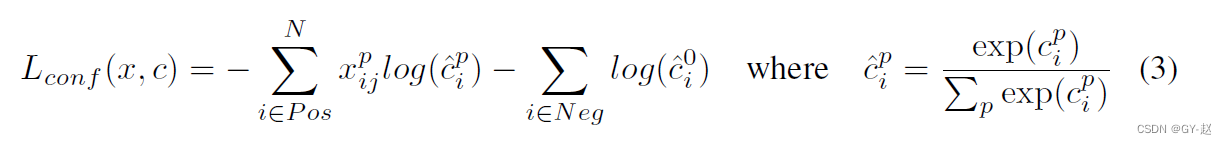
Ϊdefault boxѡ��scales��aspect
ʹ���˵ײ�߲������map���ڼ��,ͼ1 ��ʾ�˿����ʹ�õ���������ӳ�������(8x8��4x4��Դ�ڲ�ͬlayer���),ʵ���Ͽ���ʹ�ø��ࡣͬһ����������Դ�ڲ�ͬlevel�ĵ�feature map���в�ͬ�ĸ���Ұ��С������SSD��,Ĭ��box����Ҫ��ÿһ���ʵ�ʸ���Ұ���Ӧ�����������default box��ƽ��,�Ա��ض�feature mapѧϰ��Ŀ���ʵ��scales������Ӧ��������Ҫʹ��m��feature maps����Ԥ��,��ÿ��feature map��default box�ĵ�scale��������:
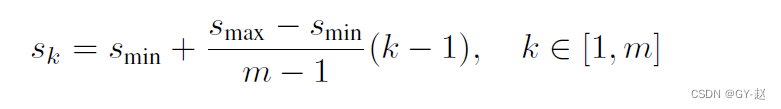
����
S
m
i
n
=
0.2
,
s
m
a
x
=
0.9
S_{min}=0.2,s_{max}=0.9
Smin?=0.2,smax?=0.9,��ζ����ײ�Ĺ�ģΪ0.2,��߲�Ĺ�ģΪ0.9.,�����м�㰴������������default boxʵ�в�ͬ�ݺ��,�����ʾΪ
a
r
��
{
1
,
2
,
3
,
1
2
,
1
3
}
a_r \in\{1,2,3,\frac{1}{2} ,\frac{1}{3}\}
ar?��{1,2,3,21?,31?}.����ÿһ��default box�Ŀ���Ϊ(
w
k
a
=
s
k
a
r
w_{k}^{a}=s_{k}\sqrt{a_r}
wka?=sk?ar??),�߶�(
h
k
a
=
s
k
/
a
r
h_{k}^{a}=s_{k}/\sqrt{a_r}
hka?=sk?/ar??).
���ڳ�����Ϊ1 ��,����һ��scale��
s
k
��
=
s
k
s
k
+
1
s_{k}^{\prime}=\sqrt{s_k s_{k+1}}
sk��?=sk?sk+1??,�����ÿ��feature mapλ����6��default box����������ÿһ��default box ������Ϊ(
i
+
0.5
�O
f
k
�O
,
j
+
0.5
�O
f
k
�O
\frac{i+0.5}{\left | f_k \right|},\frac{j+0.5}{\left |f_k \right |}
�Ofk?�Oi+0.5?,�Ofk?�Oj+0.5?),����
�O
f
k
�O
\left | f_k \right |
�Ofk?�O�ǵ�k������������ӳ��ijߴ�,
i
,
j
��
[
0
,
�O
f
k
�O
]
i,j\in[0,\left |f_k \right|]
i,j��[0,�Ofk?�O]
ͨ�������������feature map������λ�õIJ�ͬ�ߴ�ͱ�����default boxes,���Ի�ú����˸��ֵ���������С����״�Ķ�������Ԥ�⼯������,��ͼ1 ��,����4X4��feature map��default boxƥ��,������8x8 feature map �е��κο�ƥ��
�Ѹ������ھ�
ƥ��֮��,�����default box���Ǹ�����,�������������֮�����������,�����и���������ÿ��default box��������ŶȽ�������,ѡ�������������,ʹ�����������������Ϊ1:3,���õ�������Ż����ȶ���ѵ����
ʵ��

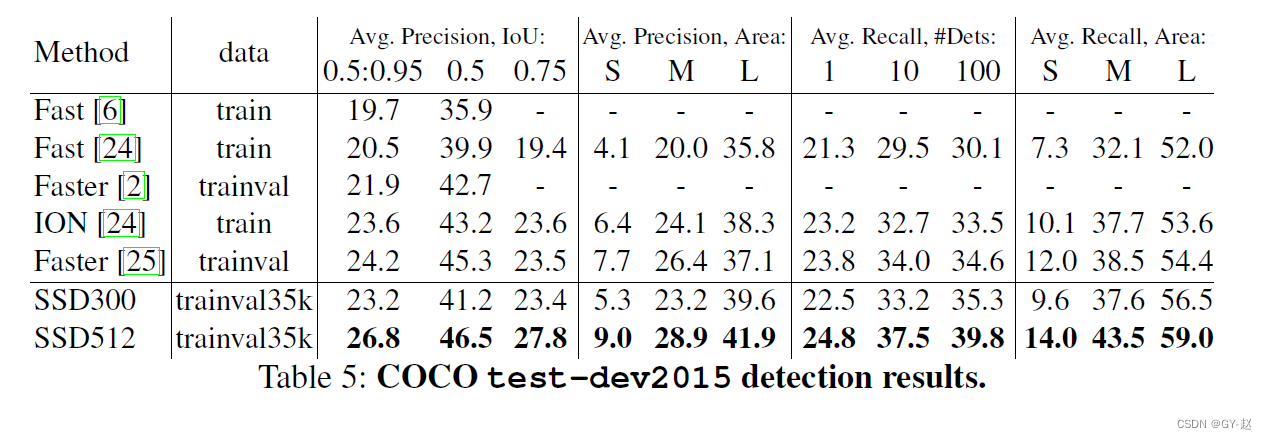
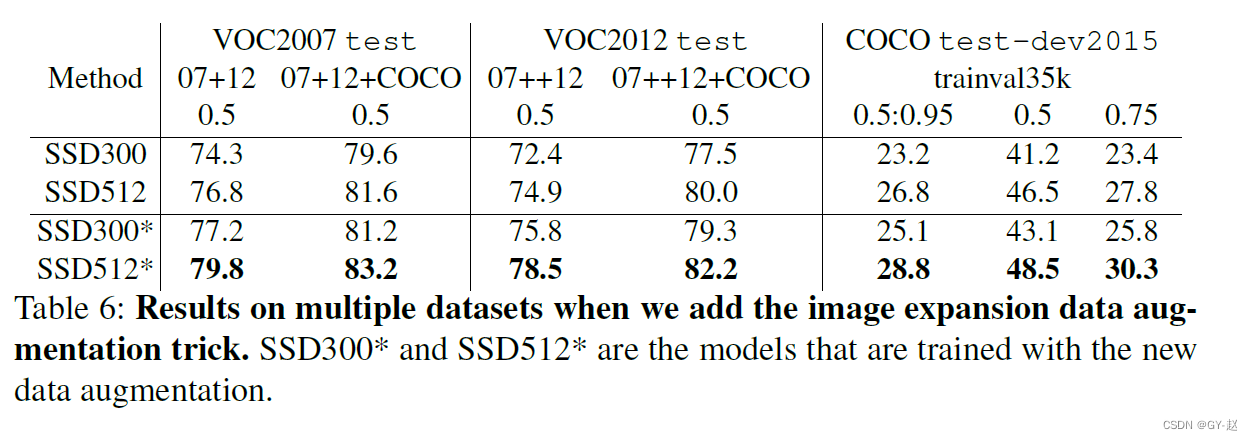
��PACAL VOC2007 test�϶�SSD ��Fast R-CNN ��Faster R-CNN���бȽ�,����SSDģ�ͳ��������С��һ����(300X300��500X500),�������ö�һ��,��ȻSSD��Խ��Faster R-CNN,�������ݼ�Խ������ߴ�Խ��,���Խ�á�

��VOC2012�Ͻ���ͬ����ʵ��,������VOC2007��һ���ġ�
����ʵ��

����˸���ʵ��ѡ����֤ÿһ���ֵ�����,����ʵ��������һ�ֲ²�,�ܶ����²�û����ϸ���������ݺ;���˵��,�����Ǹ���ʵ��������֤��ʵ�鷽�����õ�һ���ֶ�,�������������д���п�����������ָ�����������۷���Ӧ�������µ�һ�����㡣
����������������������Ҫ�����¼�������:
- ������ǿ����Ҫ,���ߵķ�������YOLO,��չ�˳�������,��Table 2 ���Կ�������һ�к����һ��������8.8%mAP,���ò��Զ�R-CNNϵ�в�һ������,��Ϊ����ʹ���������ػ�����,�Ƚ�³����
- ���ֱ����ͳߴ��default box shape �ƺ������ڼ�����
- VGG16�ϲ�����atrous �汾����,��ʹ���������,�ٶ�Ҫ�½�20%
- ʹ�ö����ͬ�ֱ��ʵ������Ч������

SSD��һ�������ڲ�ͬ��������ϲ��ò�ͬscales��default box,Ҳ����ʹ�ý�����Ԥ��,��ͬ�����������������ߴ粻һ��,�ۺ϶��������ļ������ʵ�ֲ�ͬ�ߴ�Ŀ��ļ��,�ڶ������ͼ�Ͻ���Ԥ��,���ڲ�ͬ�ߴ������ͼ�Ͻ��в�ͬ�ߴ�Ŀ���Ԥ�⡣
Ϊ�˹�ƽ�Ƚ�,һ��һ�����Ƴ�,���ߵ���default boxƽ��feature map����box��Ŀ��ԭʼ����(8732).����ͨ���ڱ��������IJ��϶ѵ�����scales��boxesʵ�ֵ�,����Ҫ�Ļ��͵���box��scales����ÿһ��������,���߲�û�й����Ż�����ƽ��,Table 3 ��չʾ��ʵ���������Է���,����layer�ļ���,�������͡�
���߹۲췢��������һ������,���ʹ�÷dz������ȵ�����ӳ��,��ô�Ἣ�����ģ������(����conv 11_2����conv 10_2),ԭ��������ڼ�֦֮��(ȥ��layer֮��)���Dz�û���㹻���box�����Ǵ�Ķ�����Ҫʹ��ϸ���ȵ�����ӳ���,ģ�����ܿ�ʼ����,�������ʹ��conv 7,�ǽ������ġ����������ٴ�ǿ��������һ����Ϣ:�ڲ�ͬlayers����չ��ͬscales��boxes����Ҫ����

