音频内容已成为一种流行的交流来源。一个缺点是,当您想查找某些内容时,您不能只按键盘上的 Control + F 来开始搜索。想象一下,您想过滤您最近的电话,以找到您正在谈论您的健康保险的电话。或者,也许您喜欢收听播客,并想找到演讲者谈论日本的播客。
在本教程中,我将向您展示如何转录音频文件以使其可搜索。作为一个技术栈,我们将使用 Python 的库,例如 NLTK、语音识别等。
让我们开始吧!
项目流程
首先,让我们了解一下程序的思想:
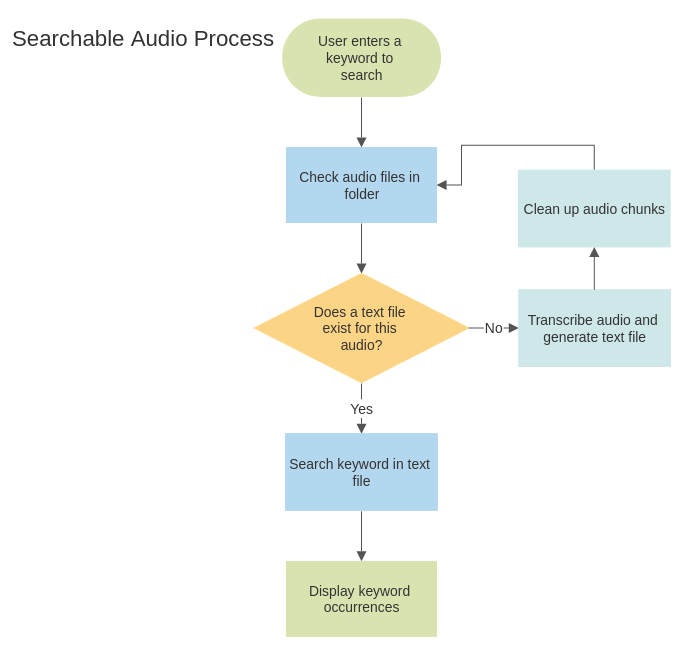
- 我们将在命令行提示符中输入关键字。
- 该程序将尝试识别和转录所有可用的音频文件。
- 它将每个音频的文本写入一个单独的文件。
- 结果将显示所有包含关键字和上下文的文件。
准备代码
我已将此项目所需的库导出到requirements.txt文件。它可以在本文末尾链接的我的 GitHub 存储库中找到。在终端中执行此命令:
pip install -r requirements.txt
接下来,创建一个新的 Python 文件。导入以下库:
import speech_recognition as sr
import os
import re
import nltk
from pydub import AudioSegment
from pydub.silence import split_on_silence
from nltk.tokenize import Rege

