原论文地址: FM
参考代码: 推荐算法(一)――FM因式分解(原理+代码)
算法简述
相比于一般的线性模型,FM模型将交叉特征的影响考虑在内。
也适用于处理输入数据稀疏的情况。
数学公式
因子分解机模型

二项交互的推导,使复杂度降低到 线性
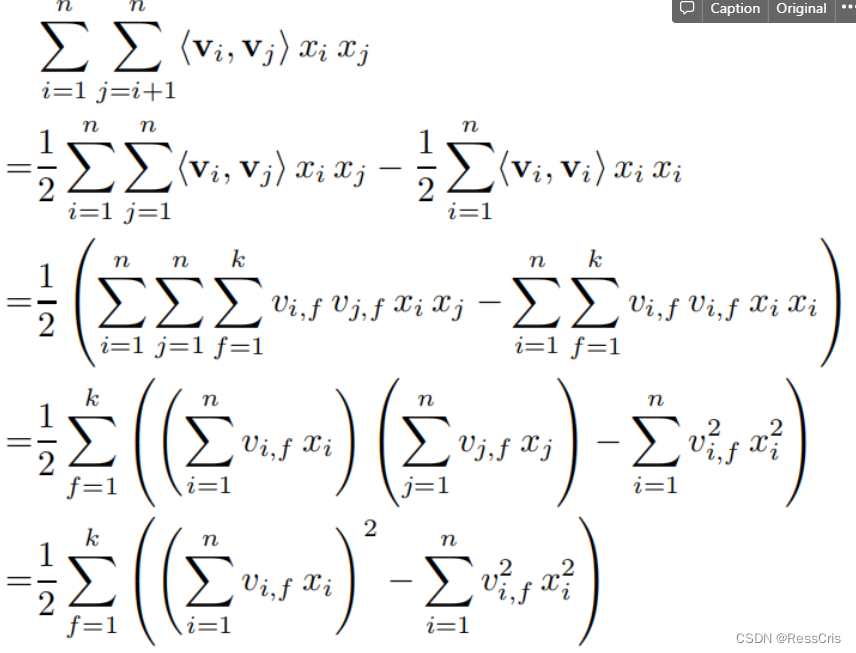
进一步转换为矩阵形式
y m × 1 = W 0 m × 1 + X m × n W 1 n × 1 + 1 2 ( ∑ ( ( X m × n V n × k ? X m × n 2 V n × k 2 ) m × k ) ) m × 1 y_{m\times 1} = W_{0_{m\times 1}} + X_{m\times n}W_{1_{n\times 1}} + \frac{1}{2}(\sum((X_{m\times n}V_{n\times k} -X_{m\times n}^2V^2_{n\times k} )_{m\times k}) )_{m\times 1} ym×1?=W0m×1??+Xm×n?W1n×1??+21?(∑((Xm×n?Vn×k??Xm×n2?Vn×k2?)m×k?))m×1?
输入数据稀疏适用
假设给定数据:
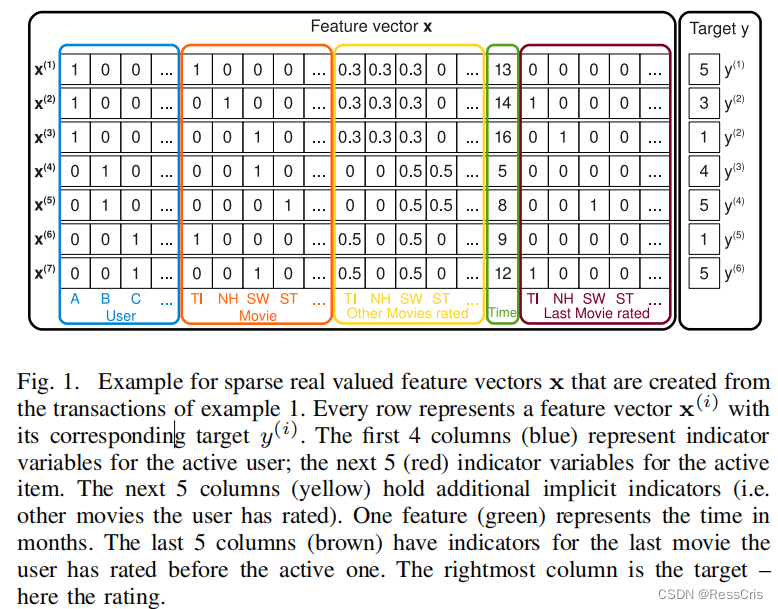
给定数据集如上图所示,表达的是用户对电影的评分,附加给了一些电影的信息,用户对其他电影的评分情况,以及用户的一些其他特征。每一行表示一个样本。
在FM模型的设定下,针对稀疏数据,也可以估计出特征的交互对预测目标的影响。
举个例子,假设我们想估计 Alice(A) 和 Star Trek 的交互关系对 评分y的贡献。
数据中,并没有 Alice 对 Star Trek 直接的评分数据, 交互关系是 0.
但是,借助于 FM, 我们可以估算出
<
V
A
,
V
S
T
>
<V_{A}, V_{ST}>
<VA?,VST?>.
- 由于对 SW 有相同的评分,Bob 和 Charlie 与 SW 的交互相似,也就是 < V B , V S W > <V_{B}, V_{SW}> <VB?,VSW?>, < V C , V S W > <V_{C}, V_{SW}> <VC?,VSW?>相近.
- Alice 和 Charlie 对 Titanic 和 SW 的评分不同, V A V_{A} VA? 和 V C V_{C} VC? 不同.
- Bob 对 ST 和 SW 的评分接近,所以 V S W V_{SW} VSW? 和 V S T V_{ST} VST? 相近.
- 从而, < V A , V S T > <V_{A}, V_{ST}> <VA?,VST?> 与 < V A , V S W > <V_{A}, V_{SW}> <VA?,VSW?> 相近.
代码实现
这里只给出 交互部分的实现供参考
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow as tf
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
class interaction_layer(layers.Layer):
def __init__(self, k_units) -> None:
super(interaction_layer,self).__init__()
self.k_units = k_units
def build(self, input_shape):
self.V = self.add_weight(
shape=(input_shape[-1], self.k_units), initializer="random_normal", trainable=True
)
def call(self, X):
# 传入 X 后的计算
# X 输入的形状是(m, n), self.V (n, k)
x = 0.5 * tf.reduce_sum(tf.matmul(X, self.V) **2 - tf.matmul( X**2,self.V **2), axis = 0)
return x
所以 FM 中完全没有激活函数对吧,也就是没有加入任何非线性变换的。

