StyleNeRF内容回顾+附录解读
StyleNeRF内容回顾
- 框架结合了NeRF和StyleGAN。仅使用volume rendering 来产生低分辨率的特征映射,再在此基础上通过上采样回复高分辨率。
- 效果: StyleNerf可以快速和合成高分辨率图像,并且保留3D一致性,可以控制相机poses 和不同层级的风格。它还支持具有挑战性的任务,包括放大和缩小、样式混合、反转和语义编辑。


附录解读
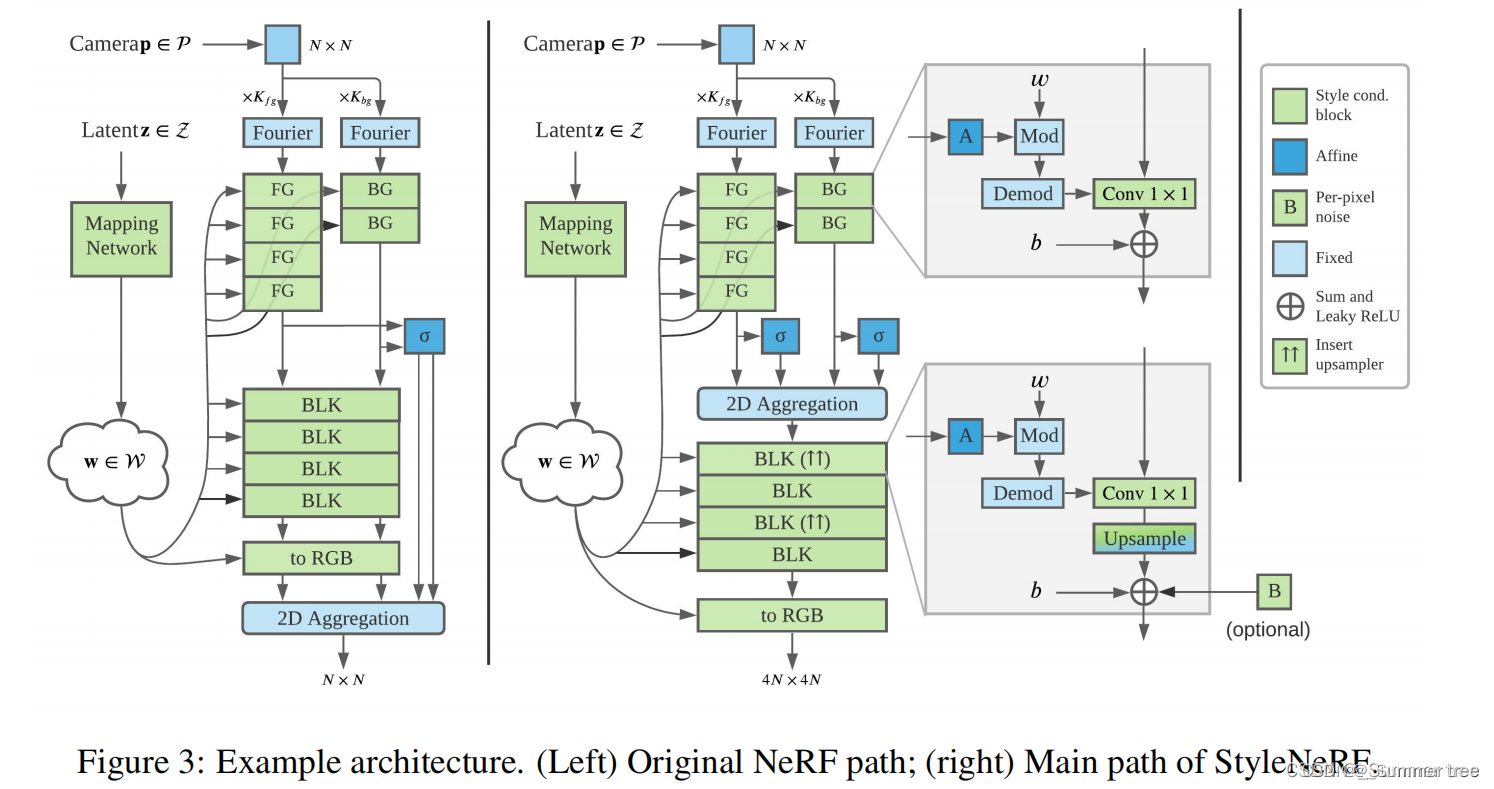
A1 IMPLICIT FIELDS MODELING
用NeRF++建模背景
和NeRF++ 一样,我们将整个场景划分为前景和背景,其中背景用一个额外的网络建模,该网络将背景潜在代码(backgound latent codes)和一个使用倒置球面参数化(inverted sphere parameterization)进行转换的3D点x = (x, y, z)作为输入
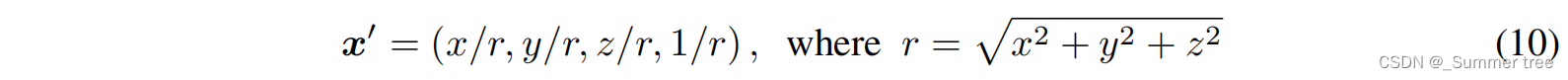
Hierachical volume sampling
- 对前景网络学习采用了Hierachical volume sampling。
- 和NeRF不同的是,我们使用单一的网络粗采样和细采样来预测颜色和密度。
A2 Camera
我们根据数据集,从高斯分布或均匀分布手动设置参数φ和θ。
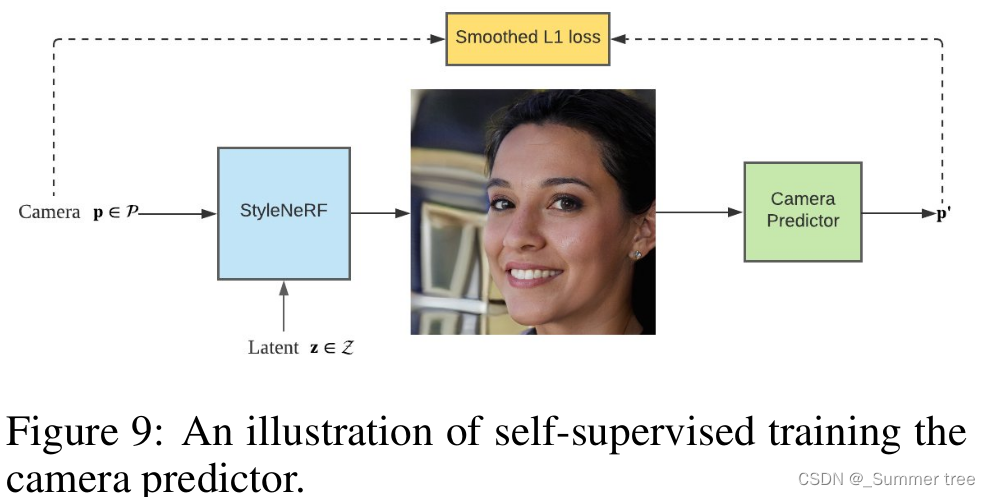
camera predictor:
1, 随机采样camera pose和latent codes 来渲染输出的图像。
2. 用预训练的ResNet18 初始化CNN-based encoder。
3. 用encoder 对输入图像的camera 参数进行预测。
A3 噪音注入的细节
为了提高合成质量和保持多视图一致性,我们设计了一种几何感知的噪声注入方法
- 对于每个特征层的分辨率N2,我们使用基于预测密度的移动立方体提取底层几何。
- 我们相应地设置volume分辨率为N3
- 我们在提取的网格的每个顶点分配独立的高斯噪声,并从同一视角通过栅格化来渲染噪声图。
- 在非线性激活之前,我们将产生的噪声注入到每一层
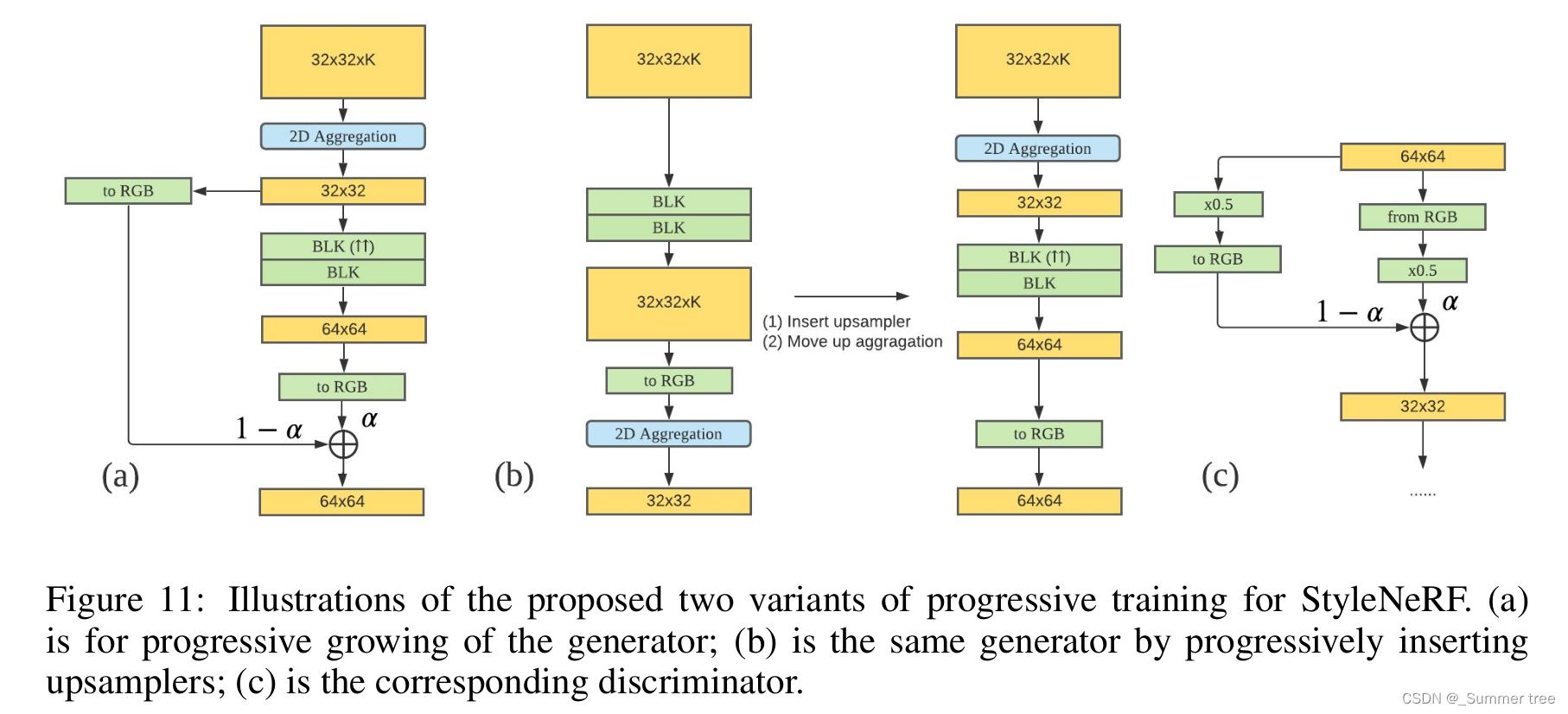
A4 渐进训练