Yolo v5 (v6.1)����(һ)
���Ķ�YOLOv5ģ�͵�detect.py�ļ��IJ�����������ϸ����,�����Ժ�ᶨ�ڽ������ģ�͵�������ģ������ؼ���,����Ҳ������һ������Ŀ����Ľ���Ⱥ:781334731,���Ҳ��ɨ��������ͼƬ����qqȺ,��ӭ���ӻԾ����,һ��ѧϰѼ
1.��Ŀ��ַ
Դ���ַ:https://github.com/ultralytics/yolov5
����ַ��,���master��ѡȡ��ͬ�汾�ķ�֧,���Ķ�Yolov5���°汾v6.1����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-ZJvmz5w9-1651574372865)(C:\Users\�γ�\Desktop\ÿ������\assets\image-20220427193834219.png)]](https://img-blog.csdnimg.cn/a3286334899d4ae696e949b2031108af.png)
2.�����
������Conda������Ϳ��Խ�����Ŀ��,����ͨ�������ṩ��requirements.txt�ļ����п��ٰ�װ
�����ն��м�������ָ��:pip install -r requirements.txt
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-uK4R44Yw-1651574372867)(C:\Users\�γ�\Desktop\ÿ������\assets\image-20220427194120530.png)]](https://img-blog.csdnimg.cn/84f544ad4a144fdeb14a463d8fba2109.png)
3.��������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-zWosquDJ-1651574372867)(C:\Users\�γ�\Desktop\ÿ������\assets\image-20220427194309785.png)]](https://img-blog.csdnimg.cn/51603d529f2b42c1bb7a0605a35c158c.png)
�����ǹٷ������Ĵ������з�ʽ,���ǿ�����Yolov5ģ��Ԥ��ͼ����Ƶ������ͷ����վ��Ƶ��RTSP���ļ���,ģ�ͻ��Զ�����Ȩ���ļ�(yolov5s.pt��yolov5m.pt��yolov5l.pt��),Ԥ���Ľ�����Զ����浽runs/detect/expĿ¼��,�´����н���ᱣ����runs/detect/exp1Ŀ¼��,��������;��ͼ����yolov5ģ�͵�Ȩ�غͳߴ�,��������Ϣ��ο�:https://github.com/ultralytics/yolov5/releases
4.ģ������
�������ǿ�������PyTorch Hub������Yolov5ģ��(���û����,���Զ�����ģ��Ȩ�ص���Ŀ¼��),֮�������Ҫ����ͼƬ,������÷�װ�õ�ģ�����������,��ͼ���������ʵ�ֲ��衣
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-lqEZjeF1-1651574372868)(C:\Users\�γ�\Desktop\ÿ������\assets\image-20220427195125517.png)]](https://img-blog.csdnimg.cn/1954a41de86543e28b6176d8e65cc3ae.png)
5. detect.py�ļ����🚀
5.1 �����
���ǿ���ֱ������detect.py�ļ�����Ч��,���к�ϵͳ��Ѽ����������runs\detect\exp3·����(֮ǰ�Լ��ܹ�)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-xyMIvWbq-1651574372869)(C:\Users\�γ�\Desktop\ÿ������\assets\image-20220427195731606.png)]](https://img-blog.csdnimg.cn/d829bb813d5742c9a67198ec432ad613.png)
��ͼ���Ǽ����:

5.2 �������
��detect.py�ļ�,��λ��213��:

5.2.1 weights

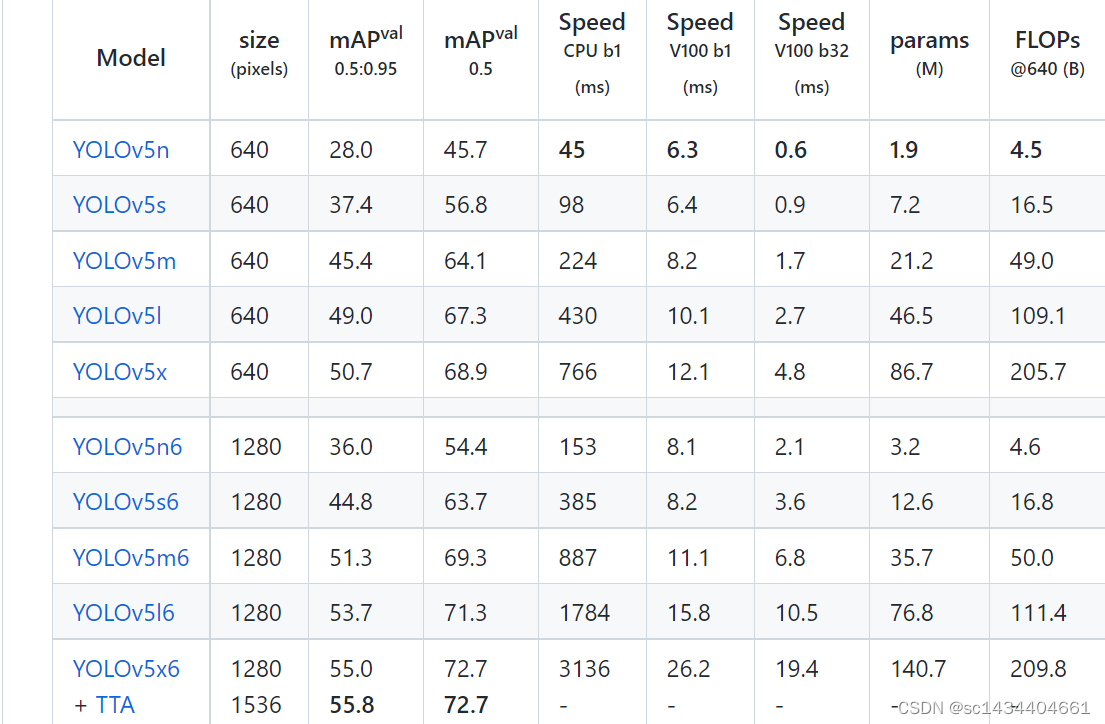
�������ָ������Ȩ�ص�·��,Ĭ���ǡ�yolov5s.pt��(default��Ĭ�ϵIJ���,��ʹ����������ʱ��ָ���������,��ôϵͳҲ��ִ��Ĭ�ϵ�ֵ);�ٷ��ṩ�˺ܶ�İ汾,��Ҫ����ʱֱ�Ӱ����滻�ɶ�ӦModel�����־Ϳ�����(��Ȼʹ���Լ�ѵ����ģ��Ҳ�ǿ��Ե�),�����Զ������ض�Ӧ��Ȩ��(�������̫������ʧ��ֻ��ȥ����������,���غ���ֱ�ӷŵ���Ŀ¼�¾Ϳ���);��ͼ������Ӧģ�ͼ���ʵ����
5.2.2 source
���������ָ�����������·��,Ĭ��ָ�������ļ���,Ҳ����ָ��������ļ�������չ����,��������ɲο��Ͻ�ģ������

5.2.3 data
������������ļ���һ��·��,�����ļ��������������·����һЩ���ݼ�������Ϣ(��ѵ��ʱ������Լ�ָ�����ݼ�,ϵͳ���Լ�����coco128���ݼ�)

5.2.4 imgsz, img, img-size

���������ģ���ڼ��ͼƬǰ���ͼƬresize��640�ijߴ�,Ȼ�����ͽ�������(������˵��������յõ��Ľ��resize��640)
5.2.5 conf-thres

������������Ŷȵ���ֵ,���Ŷ�ͨ����˵��������Լ��Ŀ�����ŵij̶�,ͨ���������̫С������϶�ļ���,������ù�������ܻ���˵���ȷ��Ԥ���(�����Ҫʵ�ʸ����Լ������ݼ������൱��ֵ)
5.2.6 iou-thres

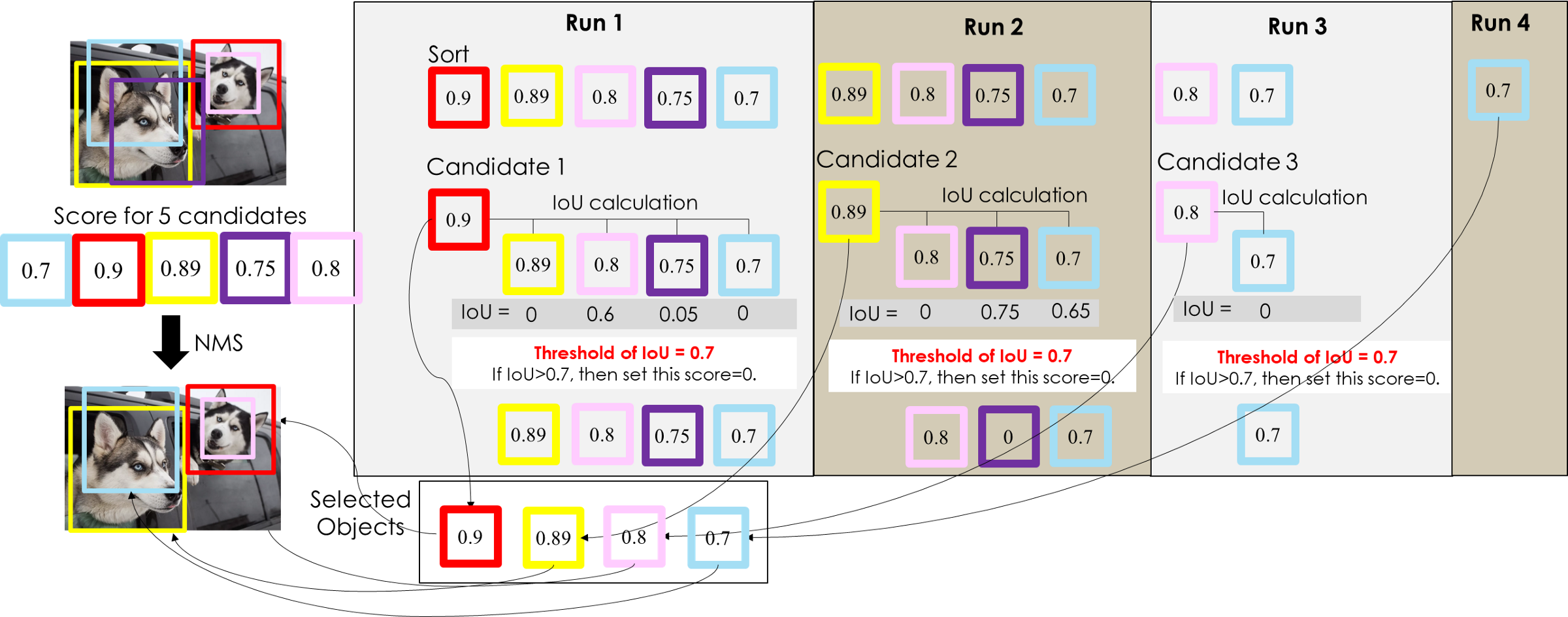
��������ǵ���IoU����ֵ,��NMS(�Ǽ���ֵ����)�����õ�,NMS���岽������
- �� BBox �����Ŷ�����,ѡȡ���Ŷ���ߵ� BBox(����һ��ʼ���Ŷ���ߵ� BBox һ���ᱻ������)
- ��ʣ�µ� BBox ���Ѿ�ѡȡ�� BBox ���� IOU,����IOU �����趨��ֵ�� BBox
- �ظ�������������,ֱ�����е� BBox ����������,��ʱ��ÿһ��ѡȡ�� BBox ���������
- ��������ɲο���ͼ
5.2.7 max-det

��������������Ŀ������,Ĭ���������1000��Ŀ��(���ռ�����ŷ��������)
5.2.8 device

���������ָ��GPU����,�����ָ���Ļ�,�����Զ����
5.2.9 action=��store_true����˵��

������͵IJ�����֮ǰ��Ĭ���кܴ�����,���൱��һ�������ء�,���������г����ʱ�����ָ���˴���action='store_true�����͵IJ���,��ô���൱�����������������Ӧ�Ĺ���,��֮��
5.2.10 view-img

��������Ǽ��ʱ�Ƿ�ʵʱ�İѼ������ʾ����,��Ϊ��action='store_true�����͵IJ���,�����Ҫ�ڼ��ʱʵʱ��ʾ��������ն�����������ָ�� :python detect.py --view-img
5.2.11 save-txt

����������Ƿ�Ѽ���������һ��txt��ʽ���ļ�,�����Ҫ�������������ն�����������ָ�� :python detect.py --save-txt
���ļ����Ŀ¼runs/detect/expĿ¼�»�����labels�ļ���,����ļ����»����ɶ�Ӧͼ������txt�ļ�,���汣����һЩ�����Ϣ�ͱ߿��λ����Ϣ
5.2.12 save-conf

����������Ƿ���txt��ʽ���ļ�����Ŀ������Ŷȵ÷�,�������ָ�����������û��Ч����,��Ҫ����ͨCsave-txt���ʹ��,�����ն�����������ָ��: python detect.py --save-txt --save-conf
5.2.13 save-crop

����������Ƿ��ģ�ͼ�������ü�����,��������������������runs/detect/exp/crops�ļ����¿�������������������ļ���,���汣��Ķ��Dzü�������ͼƬ
5.2.14 nosave

��������Dz�����Ԥ��Ľ��,���ǻ�������runs/detect/exp�ļ���,ֻ������һ���յ�exp
5.2.15 classes

�����ֳ���һ���µIJ���nargs,������˼�������ǿ��Ը�����ָ�������ֵ,Ҳ����˵���ǿ���0��ֵ��classes,Ҳ����0��1��2����ֵ��classes

���������ֻ����������Ŀ��,ʹ�÷�ʽ�����ն�����:python detect.py --classes 0
5.2.16 agnostic-nms

����������Ƿ�ʹ����ǿ���nms,һ��trick(�ʼ�ʹ���벻ʹ���������Ч������)
5.2.17 augment

���������������ʱ�Ƿ�ʹ��������ǿ����(�����ض�Ч�����кܺõ�Ч��)
5.2.18 visualize

����������Ƿ������ͼ���ӻ�����,�������������������Կ���runs/detect/exp�ļ������ֶ���һЩ�ļ�,����.npy��ʽ���ļ����DZ����ģ���ļ�,����ʹ��numpy��д.png����ͼƬ�ļ�
5.2.19 update

��������Ƕ�ģ�ͽ���strip_optimizer����,ȥ��pt�ļ��е��Ż�������Ϣ
5.2.20 project

�������������Ԥ���������·��:runs/detect
5.2.21 name

���������Ԥ����������ļ�������,Ĭ����exp(��һ����exp,��һ�ξ���exp1),��������ϵ���������ļ�·������runs/detect/exp
5.2.22 exist-ok

���������ÿ��Ԥ��ģ�͵Ľ���Ƿ���ԭ�����ļ���,���ָ������������Ļ�,��ô����Ԥ��Ľ�����DZ�������һ�α�����ļ�����;�����ָ������ÿ��Ԥ��������һ���µ��ļ�����
5.2.23 line-thickness

��������ǵ���Ԥ���������ϸ
5.2.24 hide-labels

������������ؽ����ǩ(������ʾ���Ŀ�������)
5.2.25 hide-conf

������������ر�ǩ�����Ŷ�(������ʾ���������ŷ�)
5.2.26 half

����������Ƿ�ʹ�� FP16 �뾫������;��ѵ����,�ݶȵĸ��������Ǻ�С��,��Ҫ��Խϸߵľ���,һ��Ҫ�õ�FP32����;��������ʱ��,����Ҫ��û����ô��,һ��F16(�뾫��)�Ϳ���,����������INT8(8λ����),����Ӱ�첻��ܴ�;ͬʱ�;��ȵ�ģ��ռ�ÿռ��С��,�����ڲ�����Ƕ��ʽģ������
5.2.27 dnn

����������Ƿ�ʹ�� OpenCV DNN(Deep Neural Networks)���� ONNX ����
�����
Դ���ַ:https://github.com/ultralytics/yolov5/tree/master
�ʵ�
���Ķ�YOLOv5ģ�͵�detect.py�ļ��IJ�����������ϸ����,�����Ժ�ᶨ�ڽ������ģ�͵�������ģ������ؼ���,����Ҳ������һ������Ŀ����Ľ���Ⱥ:781334731,���Ҳ��ɨ����������ͼƬ����,��ӭ���ӻԾ����,һ��ѧϰѼ!