pytorch编程环境是1.9.1+cu10.2
建议有能力的直接看官方网站英文版!
下面所示是本次教程的主要目录:
pytorch官方教程中文版:
tensors: 张量,其实这种翻译是可以的,但是我终究是选择不翻译tensor 还有翻译的语序问题,比如if,汉语中需要将if后面语句放到前面,但是因为大量有这样的语句,我还是选择在译成中文的时候,放到了后面。
(一)PyTorch介绍
1、1基础学习
大多数机器学习工作流程涉及处理数据、创建模型、优化模型参数和保存训练好的模型。本教程介绍一个用PyTorch实现的完整的ML工作流程,并提供链接来了解这些概念中的每一个。
将使用FashionMNIST数据集来训练一个神经网络,预测输入图像是否属于以下类别之一。T恤/上衣、长裤、套头衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包、或踝靴。
本教程假定对Python和深度学习概念有基本的了解。
1、1、1运行教程里的代码
你可以用几种方式运行这个教程。
- 在云中。这是最简单的入门方法 每个部分的顶部都有一个 "在Microsoft Learn中运行 "的链接,它可以在完全托管的环境中打开Microsoft Learn中的集成笔记本和代码。
- 在本地。这个选项要求您首先在本地机器上设置PyTorch和TorchVision(安装说明)。下载notebook或将代码复制到你喜欢的IDE中。
1、1、2如何使用教程
如果您熟悉其他深度学习框架,请先查看快速入门,快速熟悉PyTorch的API。
如果你是深度学习框架的新手,请直接进入我们指南的tensor部分。
1、2快速开始
本节介绍了机器学习中常见任务的API。请参考每一节中的链接来深入了解。
1、2、1处理数据
PyTorch有两个处理数据的方法:Torch.utils.data.DataLoader和Torch.utils.data.Dataset。Dataset存储了样本及其相应的标签,而DataLoader则围绕Dataset包装了一个可迭代的数据。
#处理数据
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as pltPyTorch提供了特定领域的库,如TorchText、TorchVision和TorchAudio,它们都包括数据集。在本教程中,我们将使用一个TorchVision数据集。
torchvision.datasets模块包含了许多真实世界的视觉数据的数据集对象,如CIFAR、COCO。在本教程中,我们使用FashionMNIST数据集。每个TorchVision数据集都包括两个参数:transform和target_transform,分别用来修改样本和标签。
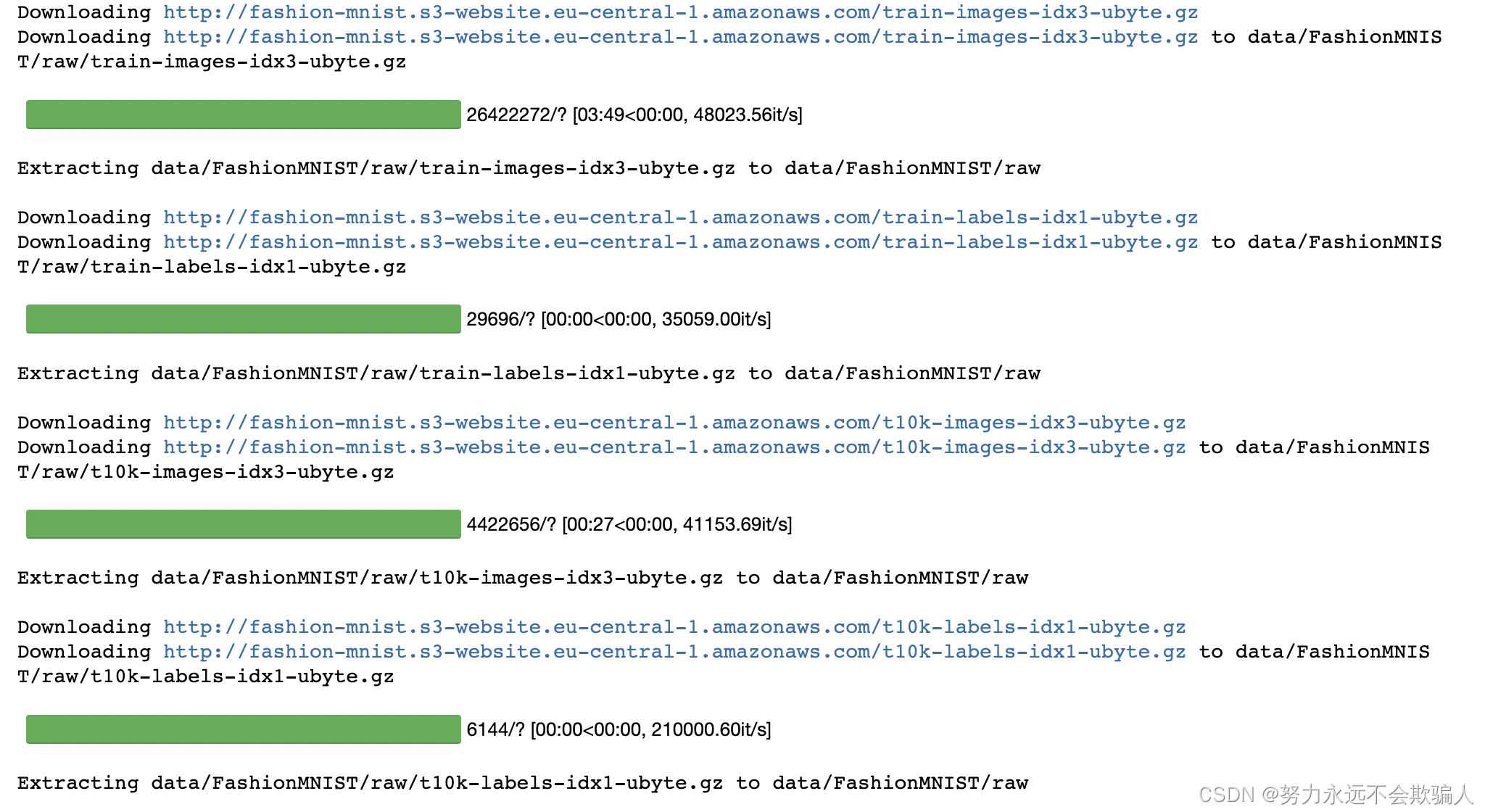
?我们将数据集作为参数传递给DataLoader。这在我们的数据集上包裹了一个可迭代的数据集,并支持自动批处理、采样、洗牌和多进程数据加载。
在这里,我们定义了一个64的批处理大小,即dataloader可迭代的每个元素将返回一个批次,包括64个元素的特征和标签。

对应每次64张图,通道数为1(黑白),图片的大小是28*28;标签y的尺寸。
1、2、2创建模型
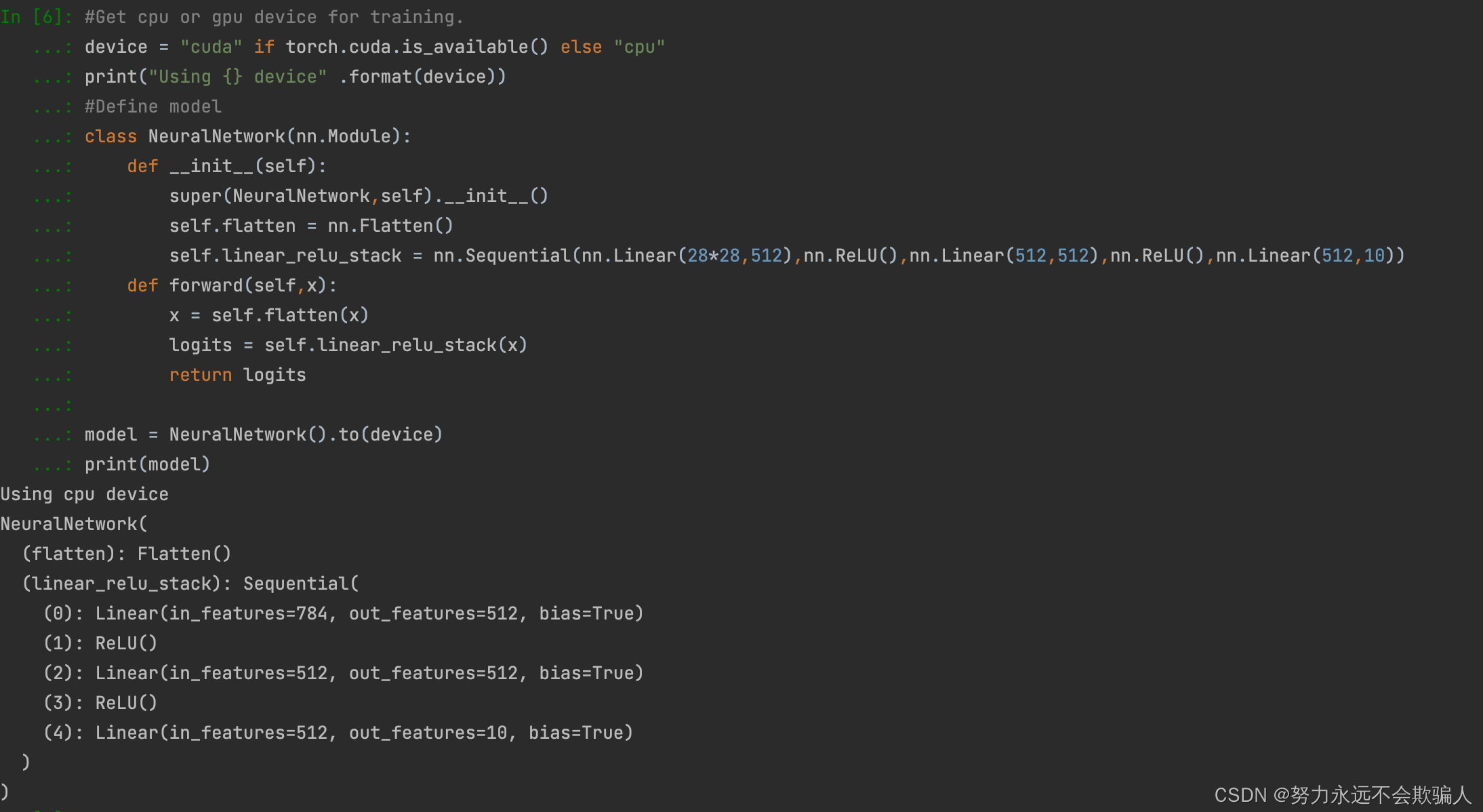
为了在PyTorch中定义一个神经网络,我们创建一个继承自nn.Module的类。我们在__init__函数中定义网络的层,并在forward函数中指定数据将如何通过网络。为了加速神经网络的操作,如果有GPU的话,我们把它移到GPU上。
flatten()函数用法
flatten是numpy.ndarray.flatten的一个函数,即返回一个一维数组。
flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用!
1、2、3优化模型参数
为了训练一个模型,需要一个损失函数和一个优化器。
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters,lr = 1e-3)在一个单一的训练循环中,模型对训练数据集(分批送入)进行预测,并通过反向传播预测误差来调整模型的参数。
def train(dataloader,model,loss_fn,optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X,y) in enumerate (dataloader):
X,y = X.to(device), y.to(device)
#Compute prediction error
pred = model(X)
loss = loss_fn(pred,y)
#Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss,current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d} / {size:>5d}]")我们还根据测试数据集检查模型的性能,以确保它在学习。
#根据测试数据集监测模型性能
def test(dataloader,model,loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss,correct = 0,0
with torch.no_grad():
for X,y in dataloader:
X,y = X.to(tensor), y.to(tensor)
pred = model(X)
test_loss += loss_fn(pred,y).item()
correct += (pred.argmax(1) == y).type(toech.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%,Avg loss:{test_loss:>8f} \n")训练过程是通过几个迭代(epochs)进行的。在每个epoch中,模型学习参数以做出更好的预测。我们在每个epoch中打印模型的准确度和损失;我们希望看到准确度在每个epoch中增加,损失在每个epoch中减少。
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------")
train(train_dataloader,model,loss_fn,optimizer)
test(test_dataloader,model,loss_fn)
print("Done!")输出结果为
Epoch 1 ------------------------- loss: 1.156493 [ 0 / 60000] loss: 1.171077 [ 6400 / 60000] loss: 0.979696 [12800 / 60000] loss: 1.117862 [19200 / 60000] loss: 0.991124 [25600 / 60000] loss: 1.021222 [32000 / 60000] loss: 1.064837 [38400 / 60000] loss: 1.001265 [44800 / 60000] loss: 1.047198 [51200 / 60000] loss: 0.965791 [57600 / 60000] Test Error: Accuracy: 65.7%,Avg loss:0.984534 Epoch 2 ------------------------- loss: 1.040607 [ 0 / 60000] loss: 1.074578 [ 6400 / 60000] loss: 0.867450 [12800 / 60000] loss: 1.026376 [19200 / 60000] loss: 0.905349 [25600 / 60000] loss: 0.927424 [32000 / 60000] loss: 0.987350 [38400 / 60000] loss: 0.926713 [44800 / 60000] loss: 0.968327 [51200 / 60000] loss: 0.898793 [57600 / 60000] Test Error: Accuracy: 66.7%,Avg loss:0.912300 Epoch 3 ------------------------- loss: 0.953451 [ 0 / 60000] loss: 1.006197 [ 6400 / 60000] loss: 0.785461 [12800 / 60000] loss: 0.960918 [19200 / 60000] loss: 0.848042 [25600 / 60000] loss: 0.857450 [32000 / 60000] loss: 0.932683 [38400 / 60000] loss: 0.875633 [44800 / 60000] loss: 0.910384 [51200 / 60000] loss: 0.850081 [57600 / 60000] Test Error: Accuracy: 67.9%,Avg loss:0.859877 Epoch 4 ------------------------- loss: 0.885792 [ 0 / 60000] loss: 0.954469 [ 6400 / 60000] loss: 0.723592 [12800 / 60000] loss: 0.911645 [19200 / 60000] loss: 0.807442 [25600 / 60000] loss: 0.804527 [32000 / 60000] loss: 0.891161 [38400 / 60000] loss: 0.839526 [44800 / 60000] loss: 0.866708 [51200 / 60000] loss: 0.812328 [57600 / 60000] Test Error: Accuracy: 69.1%,Avg loss:0.820029 Epoch 5 ------------------------- loss: 0.831598 [ 0 / 60000] loss: 0.913053 [ 6400 / 60000] loss: 0.675240 [12800 / 60000] loss: 0.873379 [19200 / 60000] loss: 0.776931 [25600 / 60000] loss: 0.763822 [32000 / 60000] loss: 0.857460 [38400 / 60000] loss: 0.812635 [44800 / 60000] loss: 0.832454 [51200 / 60000] loss: 0.781857 [57600 / 60000] Test Error: Accuracy: 70.6%,Avg loss:0.788298 Done!
1、2、4保存模型
保存模型的一个常见方法是序列化内部状态字典(包含模型参数)。

?1、2、5载入模型
加载模型的过程包括重新创建模型结构并将状态字典加载到其中。

?这个模型现在可以用来进行预测
# 进行预测
classes = ["T-shirt/top","Trouser","Pullover","Dress","Coat","Sandal","Shirt","Sneaker","Bags","Ankle boot",]
model.eval()
x,y = test_data[0][0],test_data[0][1]
with torch.no_grad():
pred = model(X)
predicted, actual = classes[pred[0].argmax(0)],classes[y]
print(f'Predicted: "{predicted}",Actual:"{actual}"')
?1、3 tensors
tensor是一种专有的数据结构,与数组和矩阵非常相似。在PyTorch中,我们使用tensor来编码一个模型的输入和输出,以及模型的参数。
tensor类似于NumPy的ndarrays,只是tensor可以在GPU或其他硬件加速器上运行。事实上,tensor和NumPy数组通常可以共享相同的底层内存,不需要复制数据。tensor还为自动微分进行了优化(我们将在后面的Autograd部分看到更多关于这一点)。如果你熟悉ndarrays,你就会对Tensor API感到很熟悉。如果没有,请跟上!

1、3、1 初始化tensor
tensor可以通过各种方式进行初始化。请看下面的例子。
直接初始化,tensor可以直接从数据中创建。数据类型是自动推断出来的。

从Numpy数组中初始化,可以从Numpy中创建tensor

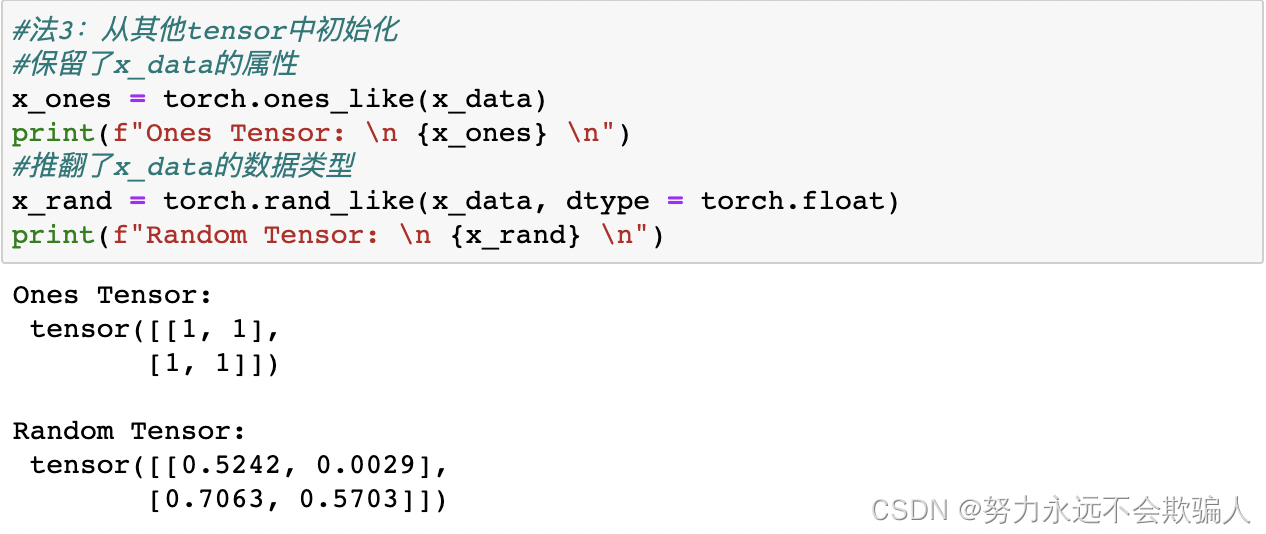
从其他tensor中初始化,新的tensor保留了参数tensor的属性(形状、数据类型),除非明确重写。
使用随机数和常数初始化,shape是一个tensor的元组。在下面的代码中,它决定了输出tensor的维度。
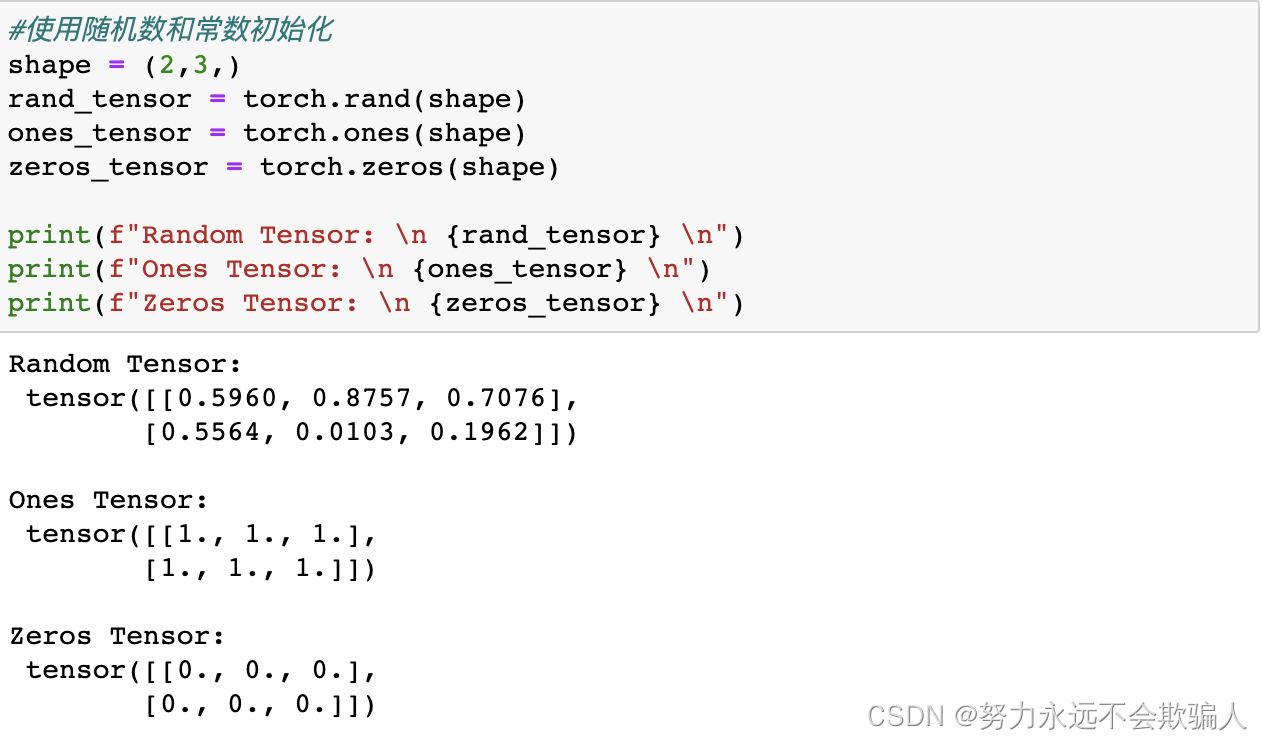
?1、3、2 tensor的性质
tensor属性描述了它们的形状、数据类型以及存储它们的设备。

?1、3、3 tensor的操作
这里全面介绍了100多种tensor操作,包括算术、线性代数、矩阵操作(转置、索引、切片)、采样等。
这些操作中的每一个都可以在GPU上运行(速度通常比在CPU上高)。如果你使用Colab,通过进入Runtime > Change runtime type > GPU来分配一个GPU。
默认情况下,tensor是在CPU上创建的。我们需要使用.to方法明确地将tensor移动到GPU上(在检查GPU的可用性之后)。请记住,在不同的设备上复制存储信息大的tensor,在时间和内存上都是很昂贵的!

尝试一下列表中的一些操作。如果你熟悉NumPy的API,你会发现Tensor API使用起来非常容易。
标准的类似numpy的索引和切分
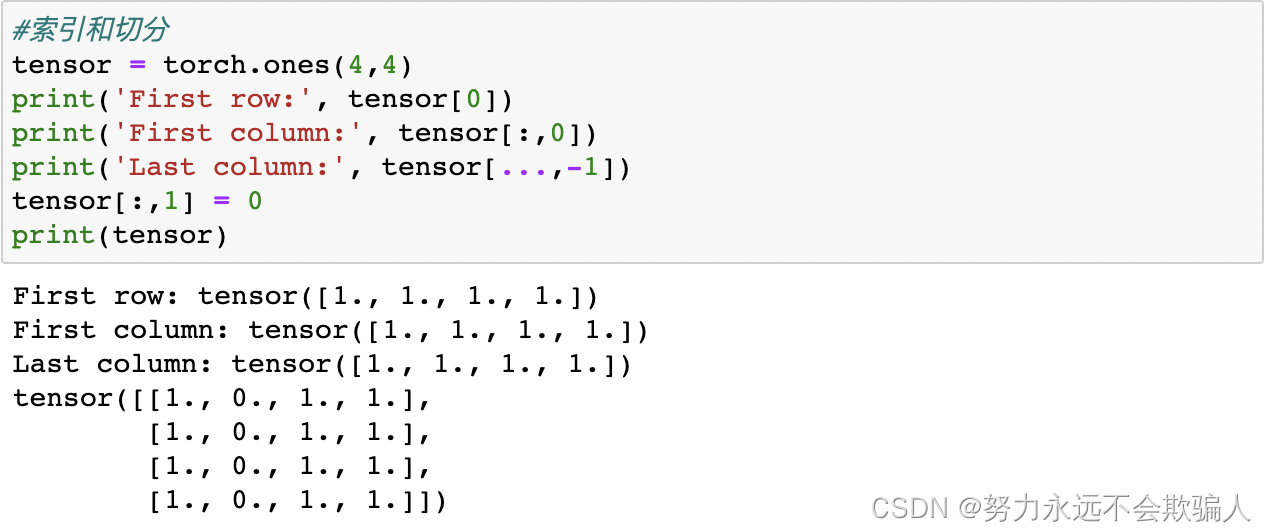 b=a[;, ;, ;number]与b=a[;, ;, number]
b=a[;, ;, ;number]与b=a[;, ;, number]
[: , :, :number],假设原来的a维度是(3X3X3),[: , :, :2]表示将原来的维度变为(3X3X2)。
[: , :, number],假设原来的a维度是(3X3X3),[: , :, 2]表示将只保留标号为2的那一列。
**连接tensor:**你可以使用torch.cat沿着给定的维度连接多个tensor。也请看torch.stack,它是另一个与torch.cat有细微差别的tensor连接操作。
cvtutorials.com: torch.cat中的cat全称是concatnate,其中con是前缀,所以取cat代指concatenate,linux中的cat命令也是这个单词。
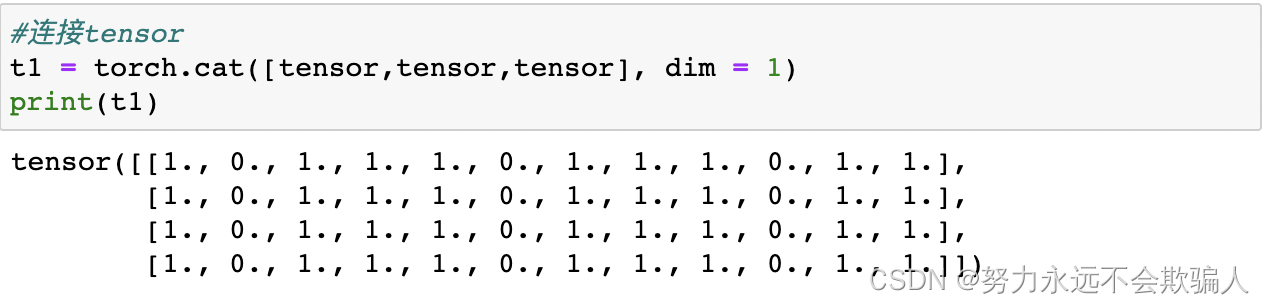
dim = 1 在第一个维度进行拼接,即水平方向。
算术运算
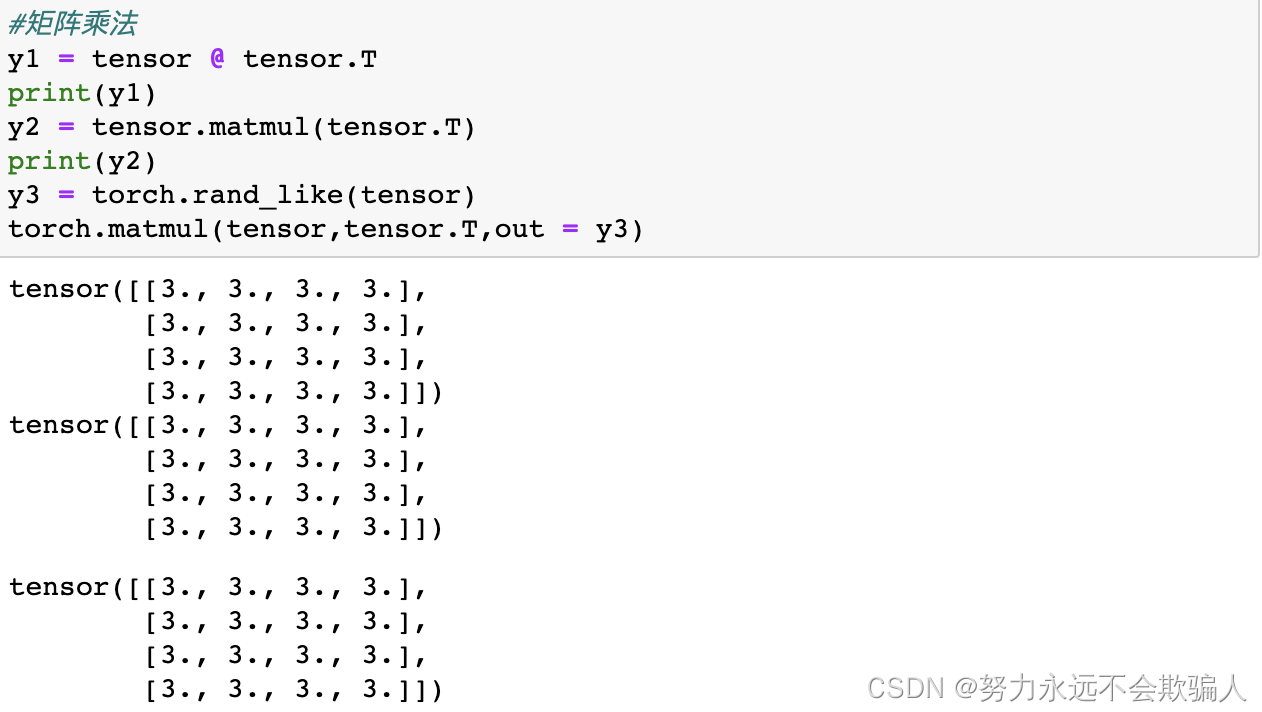

单元素tensor:如果你有一个单元素tensor,例如将一个tensor的所有值总计成一个值,你可以使用item()将其变换为Python数值。
 原位操作?将结果存储到操作数中的操作被称为原位操作。它们用后缀来表示。例如:x.copy(y), x.t_(), 将改变x。
原位操作?将结果存储到操作数中的操作被称为原位操作。它们用后缀来表示。例如:x.copy(y), x.t_(), 将改变x。
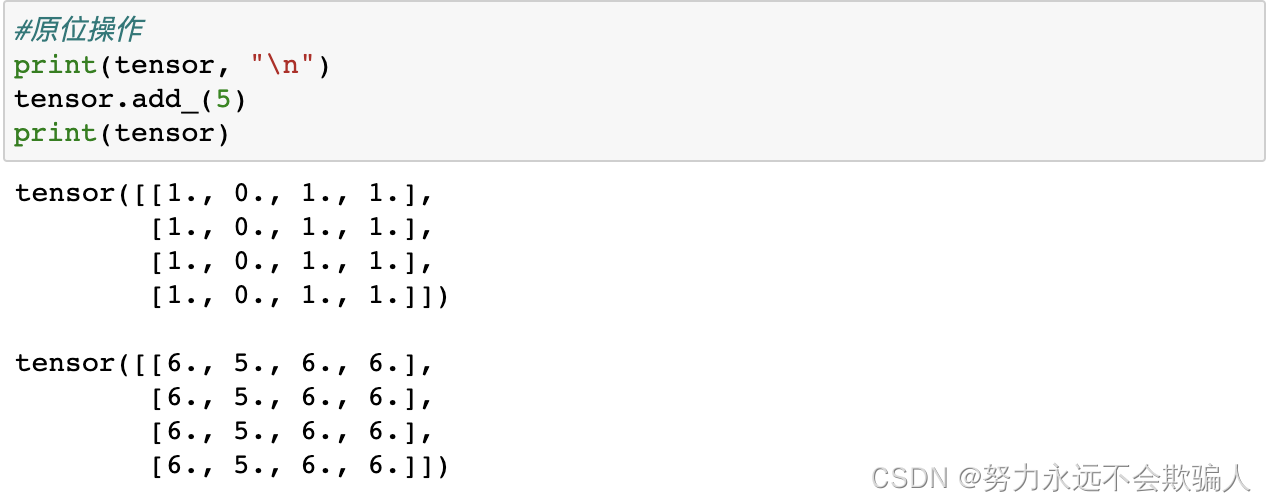
原位操作可以节省一些内存,但是在计算导数时可能会有问题,因为会立即丢失历史记录。因此,我们不鼓励使用这种操作。
1、3、4 和Numpy转换
CPU上的张量和NumPy数组可以共享它们的底层内存位置,改变一个将改变另一个。
tensor转换为NumPy数组,tensor的变化反映在NumPy数组中。
 Numpy数组转换为tensor,Numpy数组中的变化反映在tensor中。
Numpy数组转换为tensor,Numpy数组中的变化反映在tensor中。

1、4数据集和数据载入器
处理数据样本的代码可能会变得杂乱无章且难以维护;我们希望我们的数据集代码能够与我们的模型训练代码解耦,以提高可读性和模块化程度。
PyTorch提供了两个数据模块:torch.utils.data.DataLoader和torch.utils.data.Dataset,允许你使用预先加载的数据集以及你自己的数据。Dataset存储了样本及其相应的标签,而DataLoader对Dataset包裹了一个可迭代的数据集,以便能够方便地访问这些样本。
PyTorch库提供了一些预加载的数据集(如FashionMNIST),这些数据集是torch.utils.data.Dataset的子类,并实现了针对特定数据的功能。它们可以用来为你的模型建立原型和基准。
1、4、1 加载数据集
下面是一个如何从TorchVision加载Fashion-MNIST数据集的例子。Fashion-MNIST是一个由60,000个训练实例和10,000个测试实例组成的Zalando杂志中的图像数据集。每个例子包括一个28×28的灰度图像和这个图像的标签,标签是10类中的一个类别。
我们用以下参数加载FashionMNIST数据集。
- root是存储训练/测试数据的路径。
- train指定训练或测试数据集。
- download=True如果root目录下没有数据,则从互联网上下载数据,下载数据到
root路径下。 - transform和target_transform指定特征和标签的变换。

-
root="data", # 数据集下载路径
-
train=True, # True为训练集,False为测试集
-
download=True, # 是否要下载
-
transform=ToTensor() # 对样本数据进行处理,转换为张量数据
1、4、2?数据集的迭代和可视化
我们可以像列表一样手动索引数据集:training_data[index]。我们使用matplotlib来可视化我们训练数据中的一些样本。


1、4、3?为你的文件创建一个自定义数据集
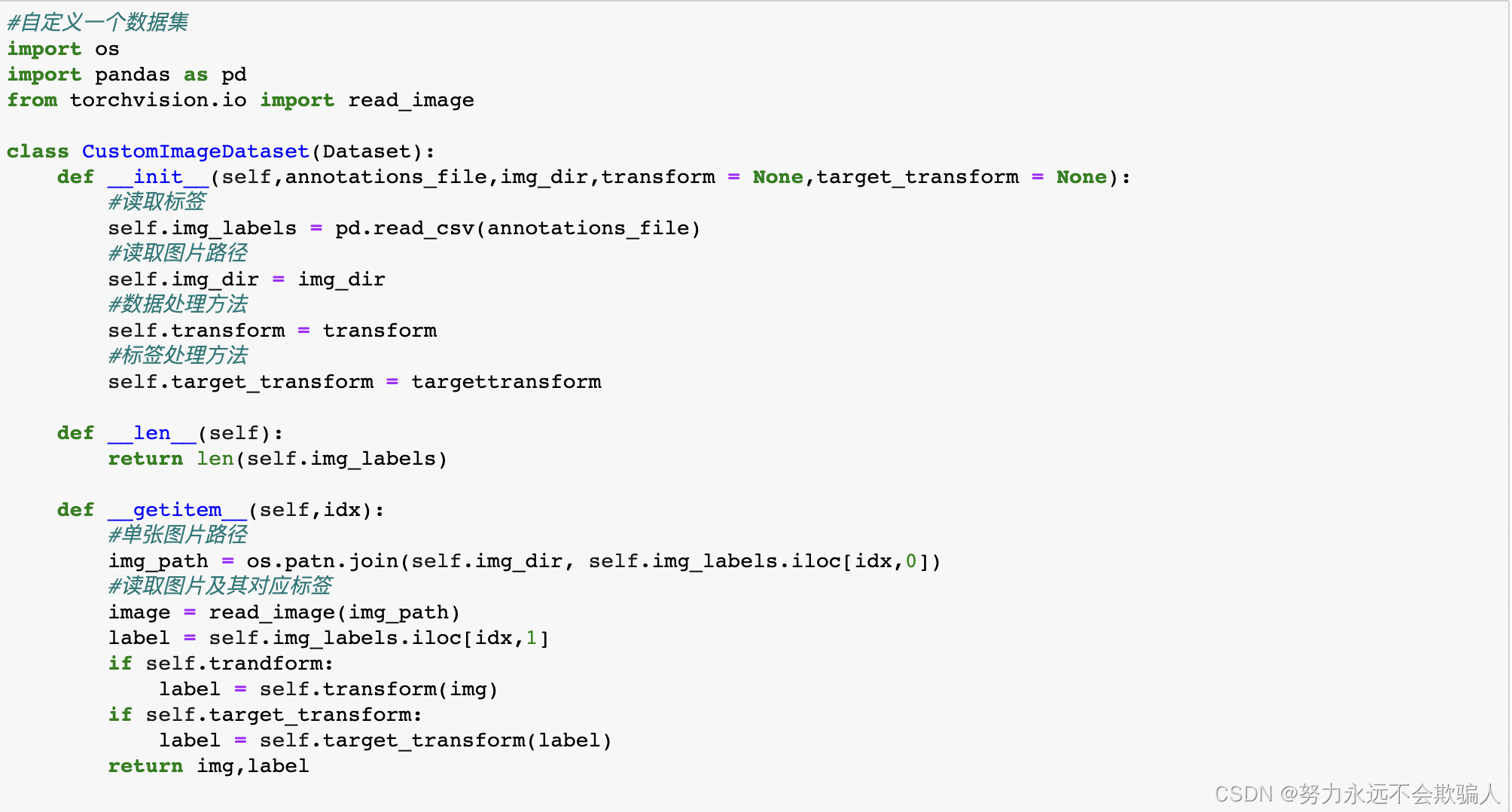
在定义自己的数据集时,需要继承Dataset类,类必须实现三个函数:__init__,?__len__, 和?__getitem__。看看这个实现;FashionMNIST的图片被存储在一个目录img_dir中,它们的标签被分别存储在一个CSV文件annotations_file中。
__init__:实例化Dataset对象时运行,完成初始化工作。(初始化包含图像目录、标注文件目录和变换(在下一节有更详细的介绍)。)__len__:返回数据集的大小。__getitem__:根据索引返回一个样本(数据和标签)。在给定的索引idx处加载并返回数据集中的一个样本。基于索引,它确定图像在磁盘上的位置,使用read_image将其变换为tensor,从self.img_labels中的csv数据中获取相应的标签,对其调用变换函数(如果适用),并在一个元组中返回tensor图像和相应标签。
1、4、4?用Dataloaders准备你的数据进行训练
数据集每次都会检索我们的数据集的特征和标签。在训练模型时,我们通常希望以 "小批 "的形式传递样本,在每个epoch中重新洗牌以减少模型的过拟合,并使用Python的multiprocessing来加快数据的检索速度。
DataLoader根据数据集生成一个可迭代的对象,它用一个简单的API为我们抽象了这种复杂性。
常用参数:
- dataset (Dataset) :定义好的数据集。
- batch_size (int, optional):每次放入网络训练的批次大小,默认为1.
- shuffle (bool, optional) :是否打乱数据的顺序,默认为False。一般训练集设置为True,测试集设置为False。
- num_workers (int, optional) :线程数,默认为0。在Windows下设置大于0的数可能会报错。
- drop_last (bool, optional) :是否丢弃最后一个批次的数据,默认为False。
两个工具包,可配合DataLoader使用:
- enumerate(iterable, start=0):输入是一个可迭代的对象和下标索引开始值;返回可迭代对象的下标索引和数据本身。
- tqdm(iterable):进度条可视化工具包

1、4、5?通过DataLoader进行迭代
我们已经将该数据集加载到DataLoader中,可以根据需要迭代数据集。下面的每次迭代都会返回一批train_features和train_labels(分别包含batch_size=64的特征和标签)。因为我们指定了shuffle=True,所以在我们迭代完所有的批次后,数据会被洗牌(要想对数据加载顺序进行更精细的控制,请看Samplers)。
在训练模型时,我们通常希望以小批量的形式传递样本,这样可以减少模型的过拟合。
将数据加载到DataLoader后,每次迭代一批样本数据和标签(这里批量大小为64),且样本顺序是被打乱的。


1、5 变换
数据并不总是以训练机器学习算法所需的最终处理形式出现。我们使用变换来对数据进行一些操作,使其适合训练。
所有的TorchVision数据集都有两个参数--用于修改特征的transform和用于修改标签的target_transform--它们接受包含变换逻辑的调用语句。torchvision.transforms模块提供了几个常用的变换,开箱即用。
FashionMNIST的特征是PIL图像格式的,标签是整数。对于训练,我们需要将特征作为归一化的tensor,将标签作为one-hot编码的tensor。为了进行这些变换,我们使用ToTensor和Lambda。
Lambda变换
Lambda变换应用任何用户定义的Lambda函数。在这里,我们定义了一个函数,把整数变成一个one-hot的tensor。它首先创建一个大小为10(我们数据集中的标签数量),值为0的tensor,并调用scatter_,在标签y给出的索引上分配一个value=1。
transforms.ToTensor()
将PIL图像或numpy.ndarray格式的变换为FloatTensor,像素亮度值范围为[0., 1.]。
transforms.Normalize()
对输入进行标准化,传入均值(mean[1],…,mean[n])和标准差(std[1],…,std[n]),n与输入的维度相同。结果计算公式如下:
output[channel] = (input[channel] - mean[channel]) / std[channel]transforms.ToPILImage()
将tensor或者numpy.ndarray格式的数据转换为PIL Image图片格式。
以下操作传入的输入格式可以为PIL Image或者tensor
transforms.Resize()
修改图片的尺寸。参数size可以是序列也可以是整数,如果传入序列,则修改后的图片尺寸和序列一致;如果传入整数,则等比例缩放图片。

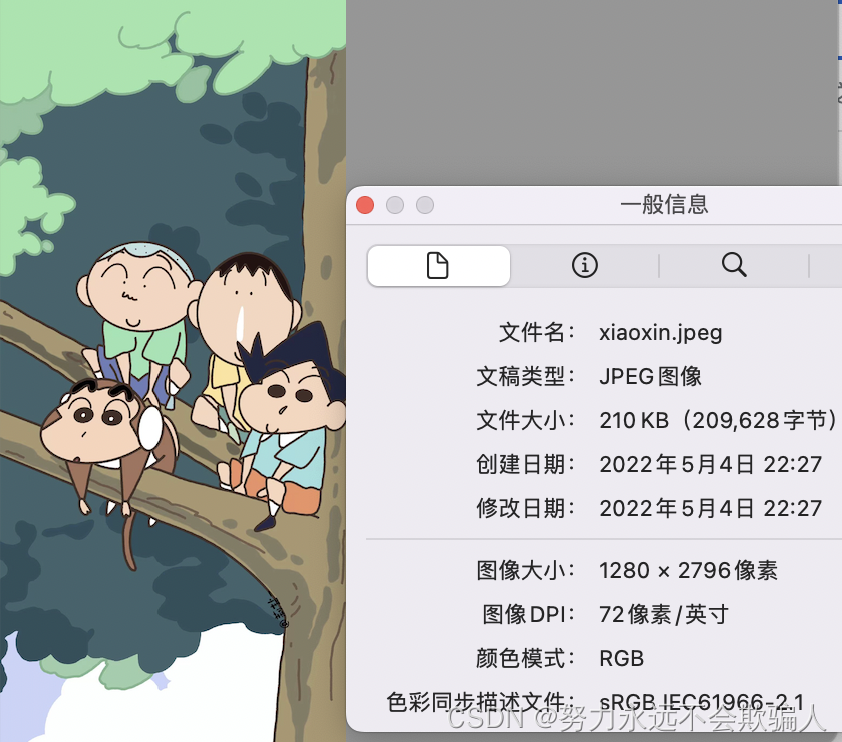
?原始图像大小为1280*2796

?transforms.CenterCrop()
中心裁剪图片。参数size可以是序列也可以是整数,如果传入序列,则裁剪后的图片尺寸和序列一致;如果传入整数,则裁剪尺寸长宽都为size的正方形。

 transforms.RandomCrop()
transforms.RandomCrop()
随机裁剪。参数size可以是序列也可以是整数,如果传入序列,则裁剪后的图片尺寸和序列一致;如果传入整数,则裁剪尺寸长宽都为size的正方形。

 transforms.RandomResizedCrop()
transforms.RandomResizedCrop()
将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小。(即先随机采集,然后对裁剪得到的图像缩放为同一大小)
transforms.RandomHorizontalFlip()
有一定概率将图片水平翻转,默认概率为0.5。
transforms.RandomVerticalFlip()
有一定概率将图片垂直翻转,默认概率为0.5。
transforms.RandomRotation()
将图片旋转。参数degrees可以为序列或者数值,如果为序列,则旋转角度为(min_degree, max_degree);如果为数值,则旋转角度为(-degrees, +degrees)。
1、6 搭建神经网络
神经网络由对数据进行操作的层/模块组成。torch.nn提供了构建神经网络所需的全部模块。PyTorch中的每个模块都是nn.Module的子类。一个神经网络本身就是一个由其他模块(层)组成的模块。这种嵌套结构允许轻松构建和管理复杂的架构。
在下面的章节中,我们将搭建一个神经网络来对FashionMNIST数据集中的图像进行分类。
 1、6、1 获取训练的设备
1、6、1 获取训练的设备
在GPU或CPU上训练我们的模型。
 1、6、2 定义类
1、6、2 定义类
模型的定义需要继承基类torch.nn.Module。__init__函数初始化网络模型中的各种层;forward函数对输入数据进行相应的操作。
 实例化
实例化NeuralNetwork类,并将其移动到device上。
 为了使用这个模型,我们把输入数据传给它。这就执行了模型的forward函数,以及一些后台操作。请不要直接调用model.forward()!
为了使用这个模型,我们把输入数据传给它。这就执行了模型的forward函数,以及一些后台操作。请不要直接调用model.forward()!
我们可以将输入数据传入模型,会自动调用forward函数。模型会返回一个10维张量,其中包含每个类的原始预测值。我们使用nn.Softmax函数来预测类别的概率。

1、6、3 模型层
让我们分解一下FashionMNIST模型中的各层。为了说明这一点,随机生成3张大小为 28x28 的图像的小批量样本,观察每一层对输入数据处理的结果。
 nn.Flatten
nn.Flatten
nn.Flatten层以将每个大小为28x28的图像转换为784个像素值的连续数组(保持批量维度(dim=0))。

nn.Linear
线性层使用其存储的权重w和偏差b对输入应用线性变换。

nn.ReLU
在线性变换后应用以引入非线性,帮助神经网络学习各种现象。(为什么要非线性激活?)
在这个模型中,我们在线性层之间使用nn.ReLU,但是还有其他非线性激活函数。
 引入非线性激活函数的原因:
引入非线性激活函数的原因:
非线性激活函数可以使神经网络逼近复杂函数。没有激活函数带来的非线性,多层神经网络和单层神经网络没有差别。
nn.Sequential
nn.Sequential可以理解为网络层的容器,在其中我们定义各种网络层,数据会按照我们设置的顺序经过所有网络层。
nn.Softmax
神经网络的最后一个线性层返回的logits,取值为[-infty, infty] 。在经过nn.Softmax函数后,logits的值收敛到[0, 1],表示模型对每个类别的预测概率。dim参数指示值必须总和为 1 的维度。
在这个例子中,我们遍历每个参数,并打印其大小和预览其值。

?1、6、4 模型参数
使用parameters()或named_parameters()方法可以查看模型的参数。


1、7 使用torvh.autograd进行自动微分
在训练神经网络时,最常使用的算法是反向传播算法。在这种算法中,参数(模型权重)是根据损失函数相对于给定参数的梯度来调整的。
为了计算这些梯度,PyTorch有一个内置的微分引擎,叫做torch.autograd。它支持对任何计算图的梯度进行自动计算。
考虑最简单的单层神经网络,输入x,参数w和b,以及一些损失函数。它可以在PyTorch中以如下方式定义:
 1、7、1 tensor、函数和计算图
1、7、1 tensor、函数和计算图
这段代码定义了以下计算图:
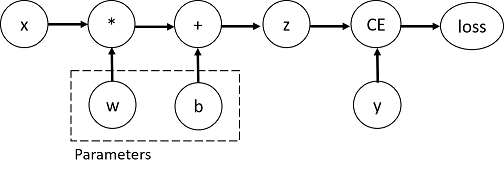
在这个网络中,w和b是我们需要优化的参数,设置了requires_grad=True属性。(可以在创建张量时设置该属性,也可以使用x.requires_grad_(True)来设置)
构建计算图的函数是Function类的一个对象。这个对象知道如何计算正向的函数*,*以及如何在反向传播步骤中计算导数,可以通过张量的grad_fn属性查看。 1、7、2 计算梯度
1、7、2 计算梯度
为了优化神经网络中参数的权重,我们需要计算损失函数对参数的导数。我们可以调用?loss.backward()来完成这一操作,在w.grad和?b.grad中可以查看相应的导数值。
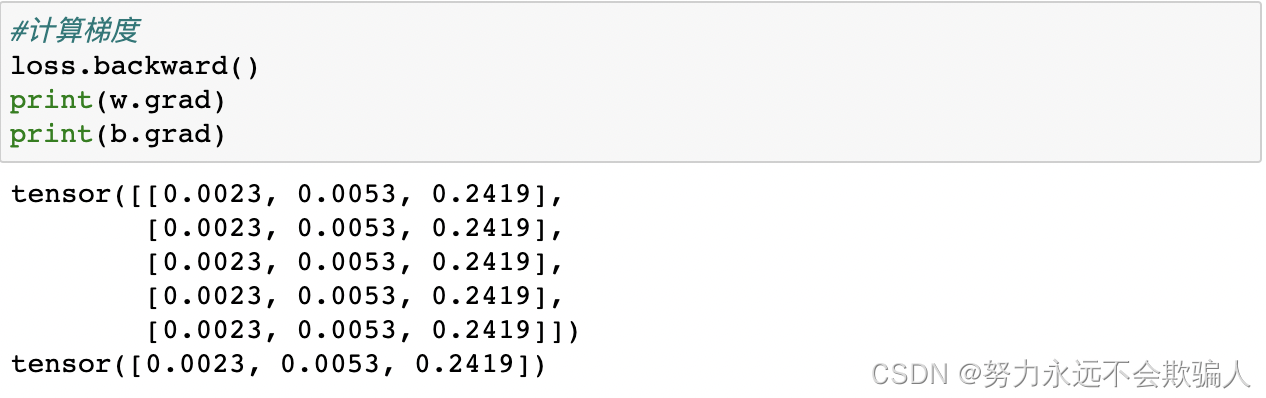
- 我们只能获得计算图的叶子节点的grad属性,这些节点的requires_grad属性设置为True。对于我们图中的所有其他节点,梯度将不可用。
- 出于性能方面的考虑,我们只能在一个给定的图上使用一次backward来进行梯度计算。如果我们需要在同一个图上进行多次backward调用,我们需要在backward调用中传递 retain_graph=True。
1、7、3 禁止梯度跟踪
默认情况下,所有张量的属性都设置为requires_grad=True,用来跟踪它们的计算历史并支持梯度计算。但是,在某些情况下我们不需要这样做,例如,模型训练完成后将其用于预测时,只需要前向计算即可。
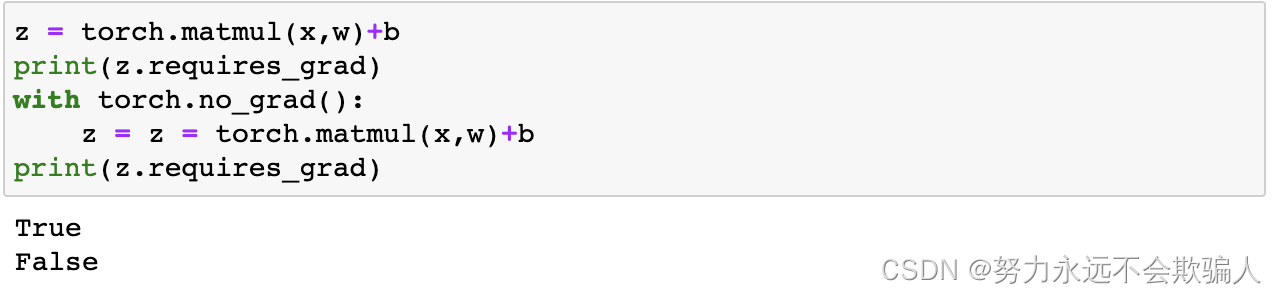 另一种实现相同结果的方法是在tensor上使用detach()方法。
另一种实现相同结果的方法是在tensor上使用detach()方法。 你可能想禁用梯度跟踪,原因如下:
你可能想禁用梯度跟踪,原因如下:
- 将神经网络中的一些参数标记为冻结参数。这是对预训练的网络进行微调的一个非常常见的情况。
- 当你只做前向传递时,为了加快计算速度,对不跟踪梯度的tensor的计算会更有效率。
1、7、4 更多关于计算图
从概念上讲,autograd在一个由Function对象组成的有向无环图(DAG)中保存了数据(tensor)和所有执行的操作(以及产生的新tensor)的记录。在这个DAG中,叶子是输入tensor,根部是输出tensor。通过追踪这个图从根到叶,你可以使用链式规则自动计算梯度。
在一个前向传递中,autograd同时做两件事。
- 运行请求的操作,计算出一个结果tensor。
- 在DAG中维护该操作的梯度函数。
当在DAG根上调用.backward()时,后向传递开始了。
- 计算每个.grad_fn的梯度。
- 将它们累积到各自tensor的 .grad 属性中
- 使用链式规则,一直传播到叶子tensor。
注意:在PyTorch中,DAG是动态的。需要注意的是,图是从头开始重新创建的;在每次调用.backward()后,autograd开始填充一个新的图。这正是允许你在模型中使用控制流语句的原因;如果需要,你可以在每次迭代时改变形状、大小和操作。
选读:tensor梯度和雅各布乘积
在许多情况下,我们有一个标量损失函数,需要计算相对于某些参数的梯度。然而,有些情况下,输出函数是一个任意的张量。在这种情况下,PyTorch允许你计算雅各布乘积,而不是实际的梯度。
PyTorch允许你计算雅各布乘积,而不是计算雅各布矩阵本身。对于一个给定的输入矢量v=(v_1...v_m)。 这可以通过调用v作为参数的backward来实现。v的大小应该与原始张量的大小相同,我们要进行乘积计算。
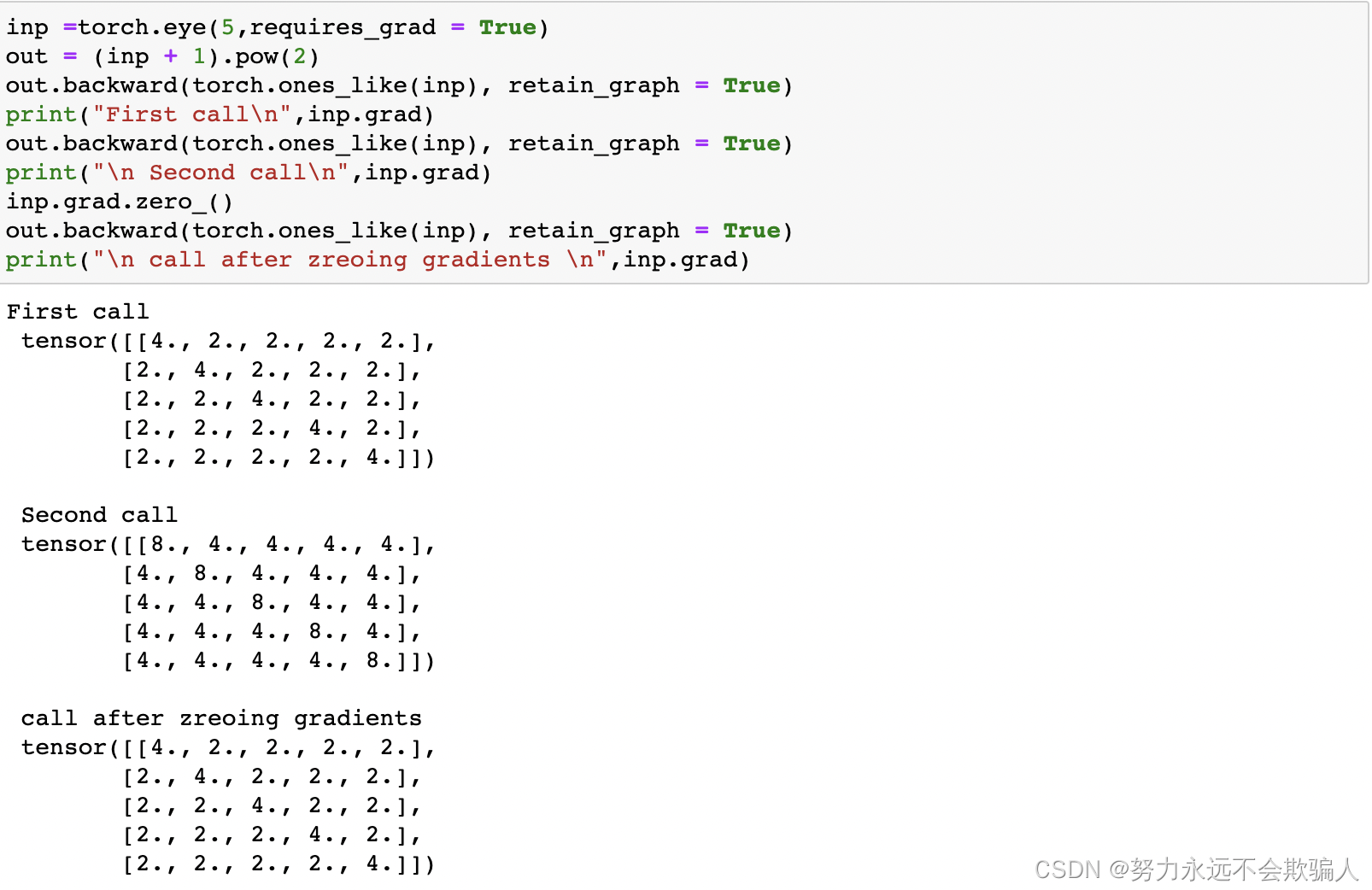
请注意,当我们第二次以相同的参数调用后向时,梯度的值是不同的。这是因为在进行向后传播时,PyTorch会累积梯度,也就是说,计算出的梯度值会加到计算图的所有叶子节点的梯度属性中。如果你想计算正确的梯度,你需要在计算梯度之前将梯度属性清零。在真实的训练中,优化器可以帮助我们做到这一点。
注意:之前我们在调用backward()函数的时候是不带参数的。这基本上等同于调用backward(torch.tensor(1.0)),这是在标量值函数的情况下计算梯度的有效方法,比如神经网络训练中的损失。
1、8 优化模型参数
现在,我们有了一个模型和数据,是时候通过在数据上优化模型的参数来训练、验证和测试我们的模型了。训练模型是一个迭代的过程;在每个迭代中(称为epoch),模型对输出进行猜测,计算其猜测的误差(损失),收集误差相对于其参数的导数(正如我们在上一节看到的),并使用梯度下降优化这些参数。
1、8、1 先决条件代码
我们从前面关于数据集和数据加载器以及建立模型的章节中载入代码。
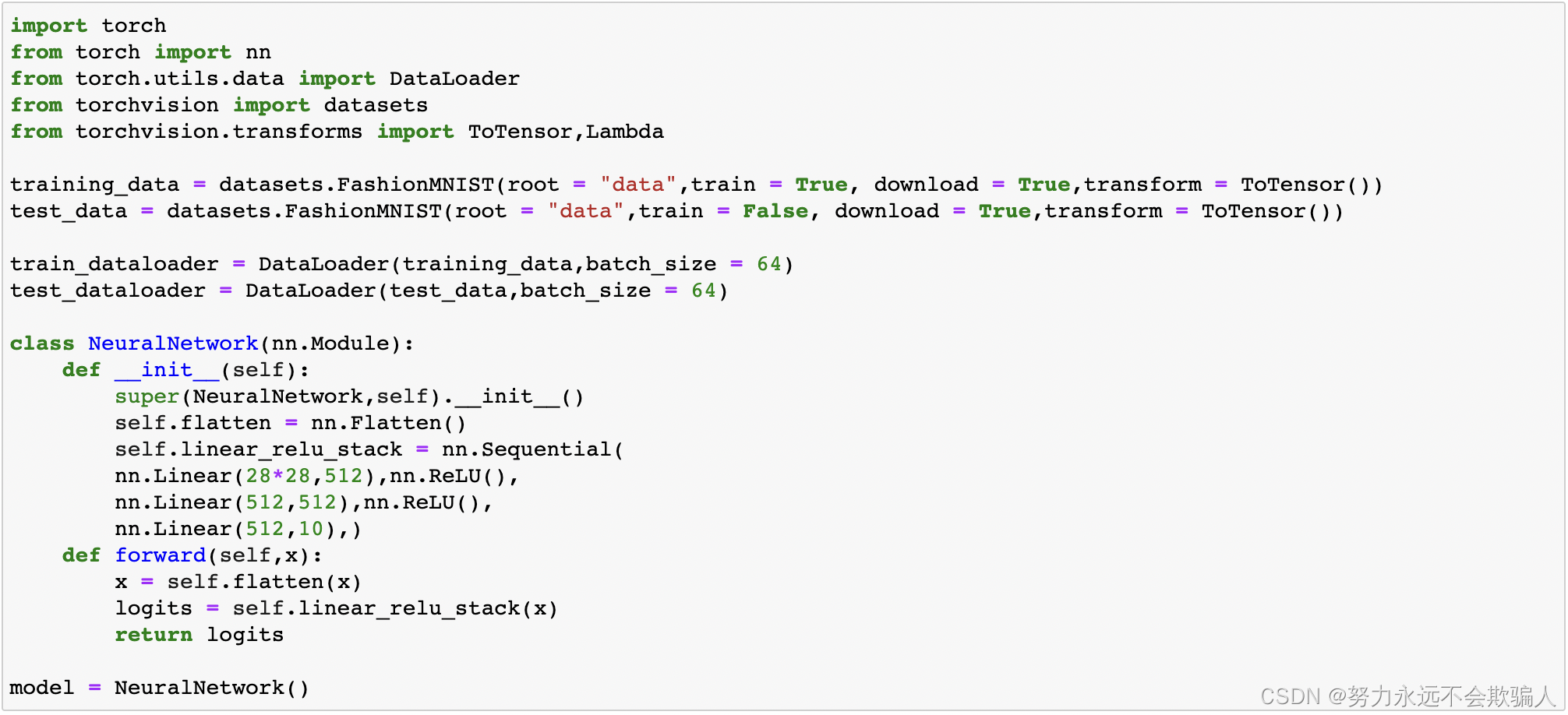
1、8、2 超参数
超参数是可调整的参数,让你控制模型优化过程。不同的超参数值会影响模型的训练和收敛率
我们为训练定义了以下超参数:
- epoch数 - 在数据集上迭代的次数
- 批量大小--在更新参数之前,通过网络传播的数据样本的数量。
- 学习率--在每个批次/epoch更新模型参数的程度。较小的值产生缓慢的学习速度,而较大的值可能会导致训练期间的不可预测的行为。

1、8、3 优化Loop
一旦我们设定了超参数,我们就可以通过优化Loop来训练和优化我们的模型。优化循环的每一次迭代被称为一个epoch。
每个epoch由两个主要部分组成。
- 训练loop--在训练数据集上迭代,试图收敛到最佳参数。
- 验证/测试循环--迭代测试数据集,以检查模型性能是否在提高。
让我们简单地熟悉一下训练loop中使用的一些概念。
损失函数
当遇到一些训练数据时,我们未经训练的网络很可能不会给出正确的答案。损失函数衡量的是获得的结果与目标值的不相似程度,它是我们在训练期间想要最小化的损失函数。为了计算损失,我们使用给定数据样本的输入进行预测,并与真实数据标签值进行比较。
常见的损失函数包括用于回归任务的nn.MSELoss(均方误差)和用于分类的nn.NLLLoss(负对数似然)。nn.CrossEntropyLoss结合了nn.LogSoftmax和nn.NLLLoss。
我们将模型的输出对数传递给 nn.CrossEntropyLoss,它将对对数进行标准化处理并计算预测误差。

优化器
优化是在每个训练步骤中调整模型参数以减少模型误差的过程。优化算法定义了这个过程是如何进行的(在这个例子中,我们使用随机梯度下降法)。所有的优化逻辑都被封装在优化器对象中。在这里,我们使用SGD优化器;此外,PyTorch中还有许多不同的优化器,如Adam和RMSProp,它们对不同类型的模型和数据有更好的效果。
我们通过注册需要训练的模型参数来初始化优化器,并传入学习率超参数。
在训练loop中,优化分三步进行。
- 调用optimizer.zero_grad()来重置模型参数的梯度。梯度默认为累加;为了防止重复计算,我们在每次迭代中明确地将其归零。
- 通过调用loss.backwards()对预测损失进行反向传播。PyTorch将损失的梯度与每个参数联系在一起。
- 一旦我们有了梯度,我们就可以调用optimizer.step()来根据向后传递中收集的梯度调整参数。
1、8、4 执行
我们定义了train_loop和test_loop,train_loop负责循环我们的优化代码,test_loop负责根据测试数据评估模型的性能。

我们初始化损失函数和优化器,并将其传递给train_loop和test_loop。随意增加epochs的数量,以跟踪模型的改进性能。

Epoch 1 ----------------------- loss: 2.168861 [ 0/60000] loss: 2.146761 [ 6400/60000] loss: 2.093971 [12800/60000] loss: 2.110697 [19200/60000] loss: 2.065134 [25600/60000] loss: 2.005016 [32000/60000] loss: 2.029867 [38400/60000] loss: 1.951983 [44800/60000] loss: 1.961464 [51200/60000] loss: 1.883326 [57600/60000] Test Error: Accuracy: 57.46%, Avg loss: 1.878828 Epoch 2 ----------------------- loss: 1.922104 [ 0/60000] loss: 1.871734 [ 6400/60000] loss: 1.761671 [12800/60000] loss: 1.804912 [19200/60000] loss: 1.698126 [25600/60000] loss: 1.651132 [32000/60000] loss: 1.672112 [38400/60000] loss: 1.571551 [44800/60000] loss: 1.603593 [51200/60000] loss: 1.496997 [57600/60000] Test Error: Accuracy: 61.82%, Avg loss: 1.507805 Epoch 3 ----------------------- loss: 1.584862 [ 0/60000] loss: 1.530016 [ 6400/60000] loss: 1.385492 [12800/60000] loss: 1.460753 [19200/60000] loss: 1.349629 [25600/60000] loss: 1.343053 [32000/60000] loss: 1.354734 [38400/60000] loss: 1.275000 [44800/60000] loss: 1.315254 [51200/60000] loss: 1.223894 [57600/60000] Test Error: Accuracy: 64.05%, Avg loss: 1.239179 Epoch 4 ----------------------- loss: 1.323101 [ 0/60000] loss: 1.290080 [ 6400/60000] loss: 1.126477 [12800/60000] loss: 1.236029 [19200/60000] loss: 1.121515 [25600/60000] loss: 1.143464 [32000/60000] loss: 1.159743 [38400/60000] loss: 1.092417 [44800/60000] loss: 1.135134 [51200/60000] loss: 1.064984 [57600/60000] Test Error: Accuracy: 64.88000000000001%, Avg loss: 1.074610 Epoch 5 ----------------------- loss: 1.149753 [ 0/60000] loss: 1.141478 [ 6400/60000] loss: 0.959462 [12800/60000] loss: 1.097030 [19200/60000] loss: 0.985131 [25600/60000] loss: 1.012667 [32000/60000] loss: 1.040925 [38400/60000] loss: 0.980155 [44800/60000] loss: 1.021059 [51200/60000] loss: 0.966461 [57600/60000] Test Error: Accuracy: 65.77%, Avg loss: 0.970976 Done!
1、9 保存和载入模型
在本节中,我们将研究如何通过保存、加载和运行模型预测来保持模型状态

1、9、1 保存和载入模型的权重
PyTorch模型将学习到的参数存储在内部状态字典中,称为state_dict。
可以通过torch.save 方法保存:torch.save(model.state_dict(),model_path)
加载模型分为两步:
????????1、先加载模型中的state_dict参数,state_dict=torch.load(model_path)
? ? ? ??2、然后加载state_dict到定义好的模型,
? ? ? ? model.load_state_dict(state_dict,strict=True/False),strict表示是否严格加载模型参数,?load_state_dict()会返回missing_keys和unexpected_keys两个参数


VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
1、9、2 保存和载入模型的形状
在加载模型权重时,我们需要先将模型类实例化,因为该类定义了网络的结构。我们可能想把这个类的结构和模型一起保存,在这种情况下,我们可以把模型(而不是model.state_dict())传给保存函数。
 然后我们可以像这样加载模型。
然后我们可以像这样加载模型。

这种方法在序列化模型时使用Python的pickle模块,所以它在加载模型时,依赖于实际的可用的类定义。
1、9、3 将模型导出为ONNX
PyTorch也有内置的ONNX导出支持。然而,由于PyTorch执行图的动态性质,导出过程必须遍历执行图以产生持久的ONNX模型。出于这个原因,应该向导出程序传递一个适当大小的测试变量(在我们的例子中,将创建一个正确形状且值为零的tensor)。
 你可以用ONNX模型做很多事情,包括在不同平台和不同编程语言中运行推理。关于更多细节,我们建议访问ONNX教程。
你可以用ONNX模型做很多事情,包括在不同平台和不同编程语言中运行推理。关于更多细节,我们建议访问ONNX教程。
恭喜!您已经完成了PyTorch的初级教程! 请尝试重新浏览第一页,再次查看该教程的全部内容。我们希望本教程能够帮助您开始在PyTorch上进行深度学习。祝您好运!

