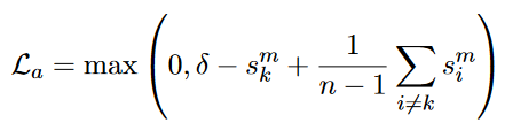1.对比学习一般泛式

其中x+是和x相似的正样本,x-是和x不相似的负样本
score是一个度量函数,来衡量样本间的相似度。
如果用向量内积来计算两个样本的相似度,则对比学习的损失函数可以表示成:
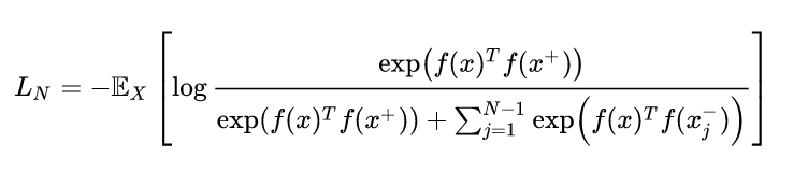
其中对应样本x有1个正样本和N-1个负样本。可以发现,这个形式类似于交叉熵损失函数,学习的目标就是让x的特征和正样本的特征更相似,同时和N-1个负样本的特征更不相似。
2.对比学习分类
「有监督对比学习」:通过将监督样本中的相同label的样本作为正样本,不同label的样本作为负样本,来进行对比学习;
正样本:同类型数据
负样本:不同类型数据
「无监督对比学习」:由于没有监督信号(label),此时,我们对同一个样本构造两个view,让同一样本构造的两个view互为正样本,而其他样本构造的view则全部为负样本,以此来进行对比学习。而由同一个样本构造两个view,又是数据扩增的过程,所以也可以称作是数据扩展对比学习。而不管那种范式,通常对比学习都是在batch内进行。
正样本:同一数据产生的增强数据
负样本:不同数据产生的增强数据
3.用于微调阶段的有监督的对比学习(SCL)
《Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning》
 在多分类任务(使用交叉熵损失)中:
在多分类任务(使用交叉熵损失)中:
①交叉熵损失导致泛化性能较差。
②对有噪声的标签或对抗样本缺乏鲁棒性。
使用了监督对比学习的思路,额外添加了一个loss,目的是使同一类样本尽可能离得近,不同类样本尽可能离得远。
使得模型对微调训练数据中的不同程度的噪声具有更强的鲁棒性,并且可以更好地推广到具有有限标签数据的相关任务。
对于具有C个类的多类分类问题,我们使用一批大小为N的训练示例
分子:每一对同类型样本;分母:与i、j不同类型的全部样本。
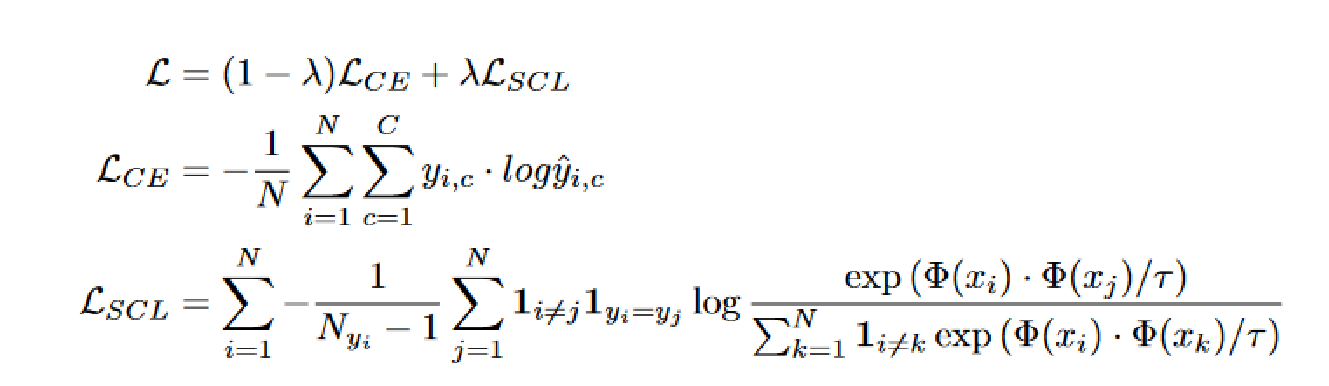
较低的温度增加了较难分离的例子的影响,有效地产生了较难分离的负样本。
实验-小样本
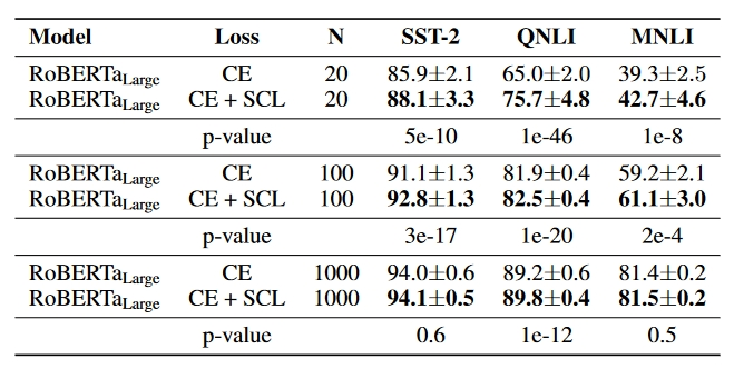
实验-噪声
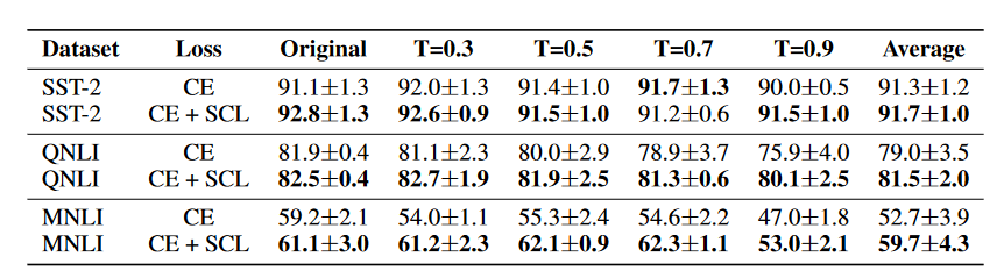
实验-全量

消融实验
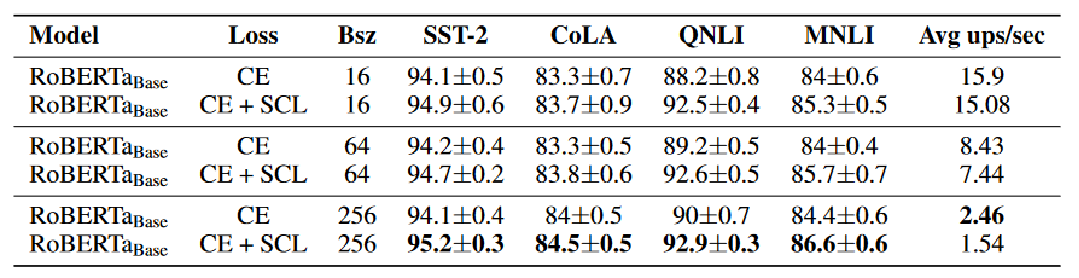
针对不同batchsize的训练速度-平均每秒更新(Avg Ups/sec)
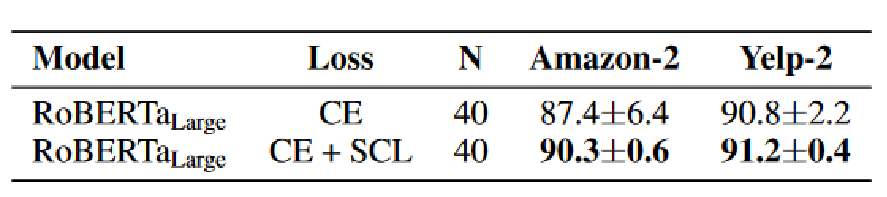
实验-泛化性
将使用完整的SST-2训练集进行微调后的模型推广到相关任务(Amazon-2,Yelp-2)
4.负监督下的文本分类
Text Classification with Negative Supervision

文本分类中的对抗样本问题:
当类别标注的标准与语义相似度不一致时,由于语义相似度的过度影响,分类容易出错。

提出了使用负样本提高文本分类模型的方法,这里的负样本类比对比学习的负样本
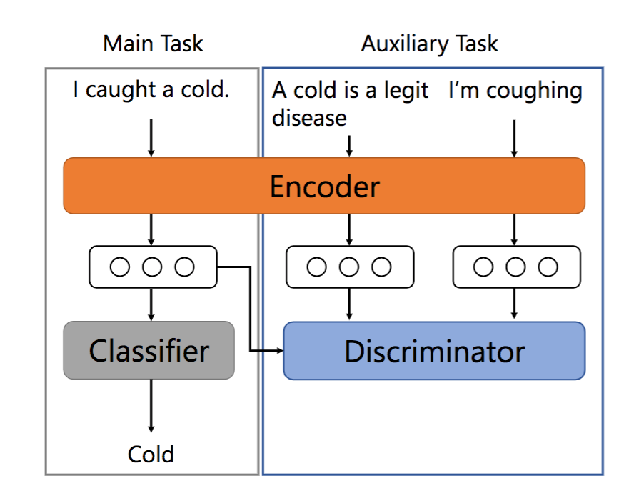
1.将分类任务作为主任务,另外加一个辨别性的学习任务作为辅助任务,主任务与辅助任务共享一个编码层;
2.主任务负责分类模型的训练,辅助任务在负样本的监督下,促使text encoder学习出更多相对label的差异性信息,使反例具有较小的余弦相似性。
每个batch中loss的计算:
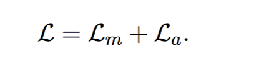
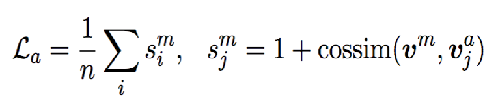

实验-全量
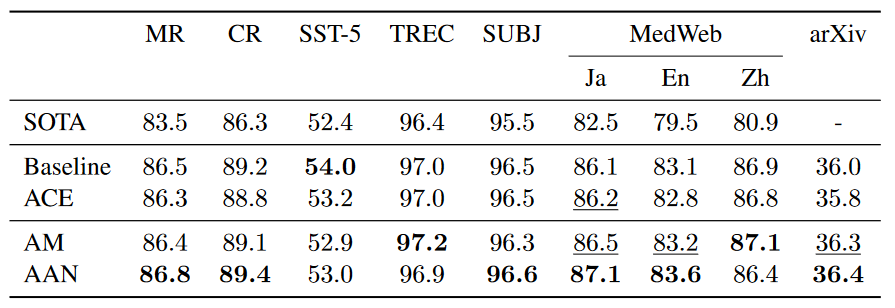
・ ACE (the auxiliary task with cross entropy loss) 证明提高效果的是负例而不是多任务学习。
・ AAN(the auxiliary task using all negative examples)上文提到的方法
・ AM (the auxiliary task with the margin-based loss) 第k个样本作为正例,类似于第一篇文章