🎀
Dataset:SST-2
Model:bert-base-cased
?
Transformers实战――使用Trainer类训练和评估自己的数据和模型
从在线库中载入SST2数据集
from datasets import load_dataset
dataset = load_dataset('glue','sst2')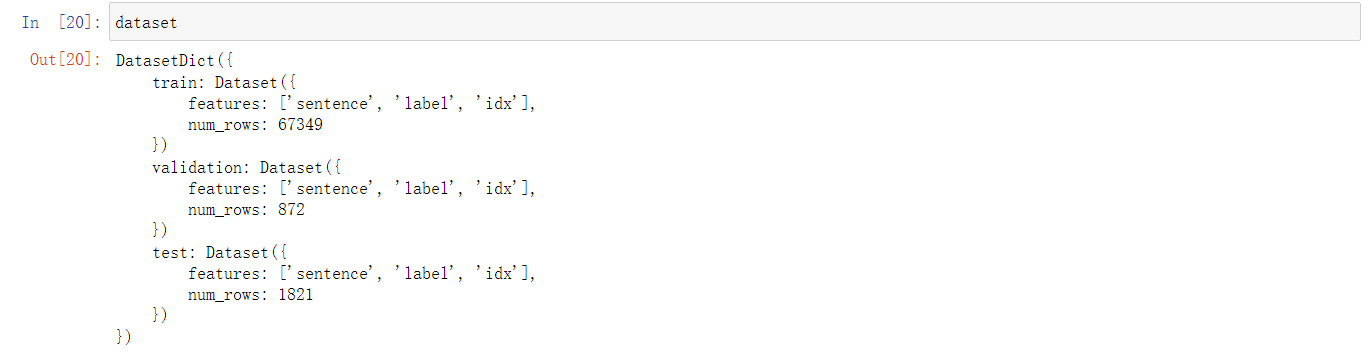
Tokenizer:将input转换为模型可以处理的格式。
from_pretrained方法让你快速加载任何架构的预训练模型,这样你就不必投入时间和资源从头开始训练一个模型。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
return tokenizer(examples["sentence"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
tokenized_datasets删除其中的sentence列,idx列;然后把label列,列名改为labels。这都是按照bert模型需要的处理的。
tokenized_datasets = tokenized_datasets.remove_columns(["sentence","idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")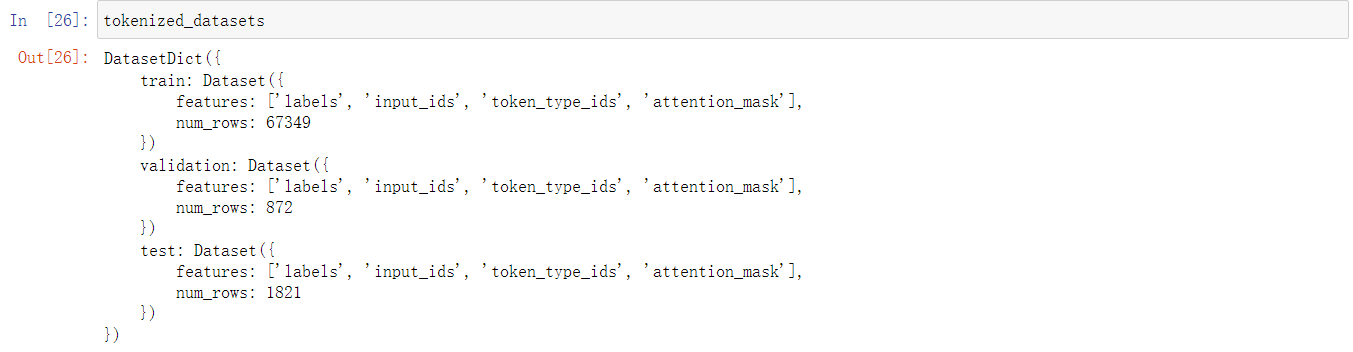
取子集,训练集取1000个,测试集取200个,充分打散。
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(200))

把数据集装入DataLoader
from torch.utils.data import DataLoader
train_dataloader = DataLoader(small_train_dataset, shuffle=True, batch_size=1)
eval_dataloader = DataLoader(small_eval_dataset, batch_size=1)载入预训练好的序列分类模型
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=2)
在初始化BertForSequenceClassification时,没有使用bert-base-cased的模型检查点的一些权重。['cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.predictions.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.predictions.transform.LayerNorm.bias',' cls.predictions.transform.LayerNorm.weight' ]
- 如果你从另一个任务或另一个架构上训练的模型的检查点初始化 BertForSequenceClassification,这是预期的(例如,从 BertForPreTraining 模型初始化 BertForSequenceClassification 模型)。
- 如果你从一个你期望完全相同的模型的检查点初始化BertForSequenceClassification(从一个BertForSequenceClassification模型初始化一个BertForSequenceClassification模型),这是不可能的。
BertForSequenceClassification的一些权重没有从bert-base-cased的模型检查点初始化,而是被新初始化。['分类器.权重', '分类器.偏置']
你可能应该在一个下游任务上训练这个模型,以便能够使用它进行预测和推理。
载入预训练好的训练参数
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="test_trainer",
per_device_train_batch_size=1, # batch size per device during training
per_device_eval_batch_size=1, # batch size for evaluation
)这个时候如果实例化一个Trainer
from transformers import Trainer
trainer = Trainer(
model = model,
args = training_args,
train_dataset= small_train_dataset,
eval_dataset=small_eval_dataset
)然后训练(因为用了预训练的参数和模型,所以这叫微调)
训练模型使用trainer对象的train方法
trainer.train()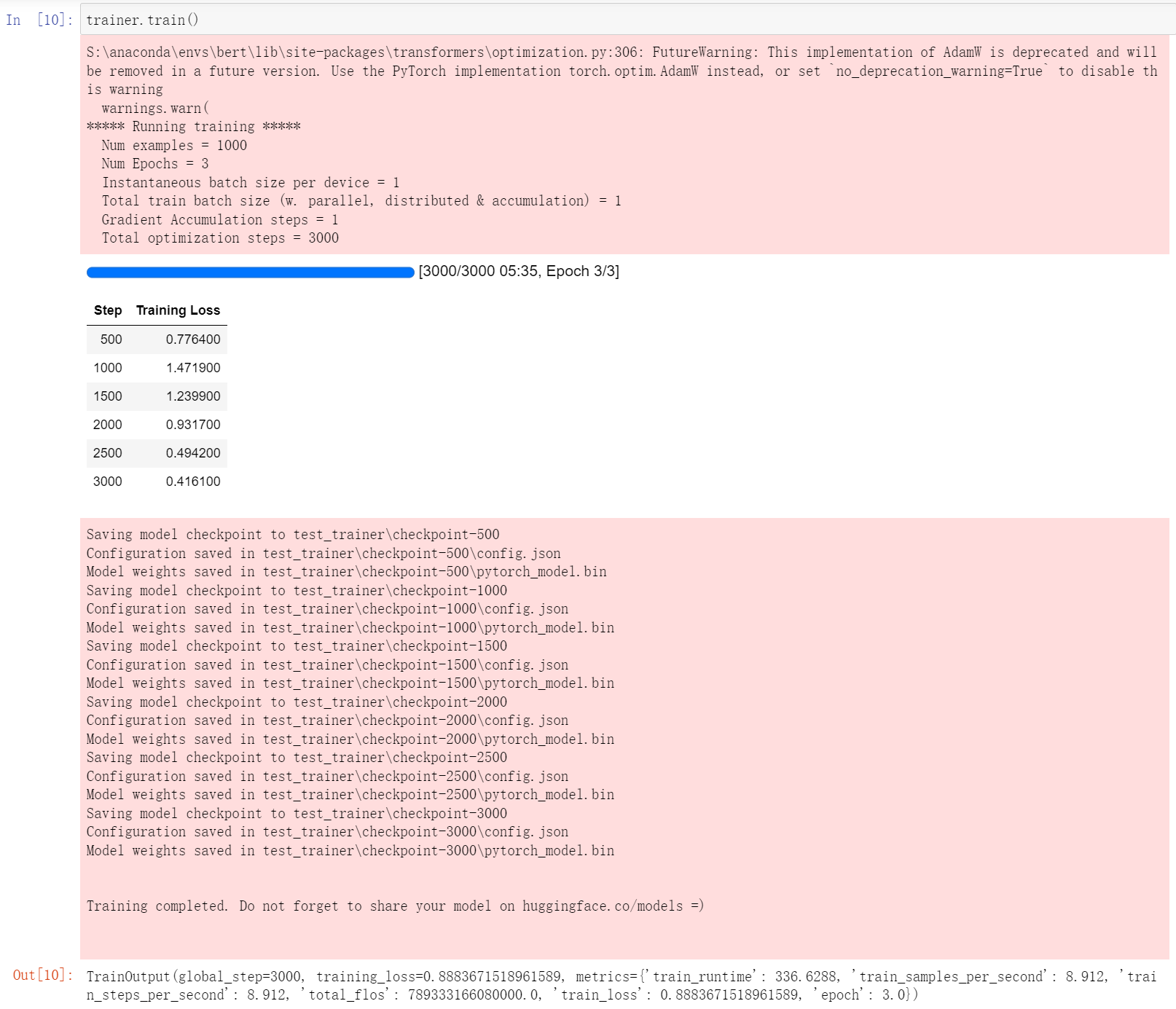
load_metric的作用是使模型能在训练期间进行模型评估。该函数接收“预测的标签”和“真实的标签”。
import numpy as np
from datasets import load_metric
metric = load_metric("accuracy")
def compute_metric(eval_pred):
logits,labels = eval_pred
predictions = np.argmax(logits,axis=-1)
return metric.compute(predictions = predictions,references = labels)
评估模型
评估模型使用trainer对象的evaluate方法
trainer = Trainer(
model = model,
args = training_args,
train_dataset= small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics = compute_metric,
)
trainer.evaluate()

