����������ʵ��
ժҪ: �ڴ˴�ʵ����,�ȳ������Լ��ֶ����һ�� CNN ������������ķ���ʵ��,��������ѵ���ٶ���ȷ�ʵ͵�ȱ�㡣���Գ���ʹ�����е�ģ��(resnet-18)��Ԥѵ���IJ�������Ǩ��ѧϰ,����������ֱ�ӰѾ��������Ϊ�̶�������ȡ���� Fine-tuning �ķ���,��������ѵ���ٶ������ս����ȷ�ʡ�
����Ŀ¼
��Ŀ����
����һ���������ݼ�,���а���1999����ʵ����, 1999�����������������500����ʵ������500�����������Ϊѵ����,������Ϊ���Լ���
���ݸ������ݼ�ѵ��ѵ��һ��������������,�ü�������ʾ���һ���������������Ҫ������Pytorch����������һ��������ģ�ͽ��з���,����ȷ��Խ��Խ��(����ȷ�ʺ͵÷ֲ����)��
ֱ��ѵ��һ�����������������
���Ľ��ᵽ,����ֱ��ѵ��������,���ǻ�������Ǩ��ѧϰ(transfer learning)�ķ�ʽ�������ѵ����������
���ǽ���˳��ִ�����²���:
- ��������
- ����һ������������ (CNN)
- ���� loss function
- ����ѵ�����ݶ��������ѵ��
- �ڲ��������ϲ�������
1. ���ز��淶������
���ǽ���Ҫ�����������ѵ��һ��ģ����������ʵ����������ٵ�������
������Ҫ��Ϊѵ���������Լ�����֤������֤���������Ҳ���
ͨ����������ű����ѽ�ʦ�����������������:
# ���ݼ�����.py
# ����һ���������ݼ�,���а���1999����ʵ����,1999�����������
# ������500����ʵ������500�����������Ϊѵ����,������Ϊ���Լ���
import os, random, shutil
def eachFile(filepath):
pathDir = os.listdir(filepath)
return pathDir
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def divideTrainValiTest(source, dist):
print("��ʼ�������ݼ�...")
print(eachFile(source))
for c in eachFile(source):
pic_name = eachFile(os.path.join(source, c))
random.shuffle(pic_name) # �������
train_list = pic_name[0:1499]
validation_list = pic_name[1499:]
test_list = []
mkdir(dist+ 'train/'+c+'/')
mkdir(dist+ 'validation/'+c+'/')
mkdir(dist+ 'test/'+c+'/')
for train_pic in train_list:
shutil.copy(os.path.join(source, c, train_pic),
dist+ 'train/'+c+'/'+train_pic)
for validation_pic in validation_list:
shutil.copy(os.path.join(source, c, validation_pic),
dist+ 'validation/'+c+'/'+validation_pic)
for test_pic in test_list:
shutil.copy(os.path.join(source, c, test_pic),
dist + 'test/'+c+'/'+test_pic)
return
if __name__ == '__main__':
filepath = r'./CNN_synth_testset/'
dist = r'./CNN_synth_testset_divided/'
divideTrainValiTest(filepath, dist)
# ---------------- End of ���ݼ�����.py ----------------
���ǽ�ʹ��torchvision��torch.utils.data���ڼ������ݵİ���
import torch
import torchvision
from torchvision import datasets, models, transforms
import os
�������¹淶���IJ���ѡ���ԭ��ο�: https://blog.csdn.net/KaelCui/article/details/106175313
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'validation': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
batch_size = 16
data_dir = './CNN_synth_testset_divided/'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'validation']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size,
shuffle=True, num_workers=8)
for x in ['train', 'validation']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'validation']}
class_names = image_datasets['train'].classes
trainloader = dataloaders['train']
testloader = dataloaders['validation']
չʾһЩѵ��ͼƬ
import matplotlib.pyplot as plt
import numpy as np
def my_imgs_plot(image, labels, preds=None):
cnt = 0
plt.figure(figsize=(16,16))
for j in range(len(image)):
cnt += 1
plt.subplot(1,len(image),cnt)
plt.xticks([], [])
plt.yticks([], [])
if preds is not None:
plt.title(f"pred: {class_names[preds[j]]}\n true: {class_names[labels[j]]}"
,color='green' if preds[j] == labels[j] else 'red')
else:
plt.title("{}".format(class_names[labels[j]]), fontsize=15, color='green')
inp = image[j].numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
plt.show()
for _ in range(1):
dataiter = iter(trainloader)
images, labels = dataiter.next()
my_imgs_plot(images, labels)
?
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-S7Mdah3f-1651737589813)(����Ϣ�����ݰ�ȫ��ʵ���:����������ʵ��/fakeFace_classifier_5_0.png)]
2. ����һ������������
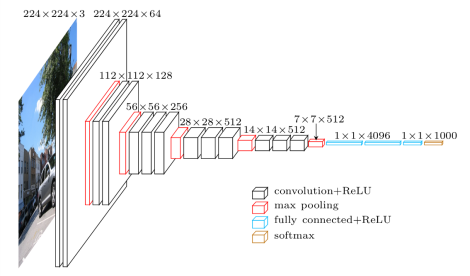
��ͼ��VGG�IJο��ṹ����������������㶨��һ��CNN���ԡ�
import torch.nn as nn
import torch.nn.functional as F
## my
class myNet(nn.Module):
def __init__(self,in_size = 224, in_channels = 3, num_classes=2):
super(myNet,self).__init__() # RGB 3*32*32
self.conv1 = nn.Conv2d( in_channels, 15,3) # ����3ͨ��,���15ͨ��,������Ϊ3*3
self.conv2 = nn.Conv2d(15, 75,4) # ����15ͨ��,���75ͨ��,������Ϊ4*4
self.conv3 = nn.Conv2d(75,150,3) # ����75ͨ��,���150ͨ��,������Ϊ3*3
self.conv4 = nn.Conv2d(150,300,3) # ����75ͨ��,���300ͨ��,������Ϊ3*3
self.conv5 = nn.Conv2d(300,300,3) # ����300ͨ��,���300ͨ��,������Ϊ3*3
self.fc1 = nn.Linear(7500,400) # ����10800,���400
self.fc2 = nn.Linear(400,120) # ����400,���120
self.fc3 = nn.Linear(120, num_classes) # ����120,���2
def forward(self,x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2) # 3*224*224 -> 150*222*222 -> 15*111*111
x = F.max_pool2d(F.relu(self.conv2(x)), 2) # 15*111*111 -> 75*108*108 -> 75*54*54
x = F.max_pool2d(F.relu(self.conv3(x)), 2) # 75*54*54 -> 150*52*52 -> 150*26*26
x = F.max_pool2d(F.relu(self.conv4(x)), 2) # 150*26*26 -> 300*24*24 -> 300*12*12
x = F.max_pool2d(F.relu(self.conv5(x)), 2) # 300*12*12 -> 300*10*10 -> 300*5*5
x = x.view(x.size()[0],-1) # ��300*5*5��tensor��ƽ��1ά,7500
x = F.relu(self.fc1(x)) # ȫ���Ӳ� 10800 -> 400
x = F.relu(self.fc2(x)) # ȫ���Ӳ� 400 -> 120
x = self.fc3(x) # ȫ���Ӳ� 84 -> 10
return x
# �Զ�ѡ�� GPU �� CPU
use_cuda = True
print("CUDA Available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")
net = VGG11(3,num_classes=2).to(device)
# net = VGGbase().to(device)
net = myNet().to(device)
CUDA Available: True
3. ������ʧ�������Ż���
������ʹ�÷��ཻ������ʧ(Classification Cross-Entropy)�ʹ�������SGD(SGD with momentum)��
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
4. ѵ������
����ֻ�������ݵ�������ѭ��,���������ṩ��������Ż�,�Ϳ��Կ�ʼѵ����������
from tqdm import tqdm
loss_plot = []
net.train()
l = tqdm(range(192))
for epoch in l: # �����ݼ���ѭ�����
# gc.collect()
# torch.cuda.empty_cache()
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# ��ȡ����;������[���롢��ǩ]���б�
inputs, labels = data[0].to(device), data[1].to(device)
# �������ݶȹ���
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# ��ӡͳ������
running_loss += loss.item()
if i % 100 ==99: # print every 100 mini-batches
loss_plot.append(running_loss / 100)
running_loss = 0.0
# print(f'epoch {epoch + 1} loss: {loss_plot[-1]}')
l.set_description(f'current loss: {loss_plot[-1]}')
print('Finished Training')
plt.plot(loss_plot)
current loss: 0.017697893029380792: 100%|��������������������| 192/192 [1:07:41<00:00, 21.15s/it]
Finished Training
?
[<matplotlib.lines.Line2D at 0x7fdadd729820>]
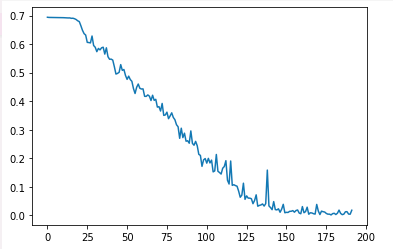
��ʵ����,���ʼ����loss���߲��½�,ģ��train������,����ͼ���ߵ��ʼ��ƽ̹�ĵط���ʾ����һ�Ȼ�����ʲô�ط�����,����������epoch��������̫���ˡ�
������Ա���һ��ѵ�õ�ģ��:
PATH = './fakeFace_{}.pth'.format(net.__class__.__name__)
torch.save(net.state_dict(), PATH)
5. �ڲ��������ϲ�������
�����Ѿ�ͨ��ѵ�����ݼ������������ѵ������������Ҫ��������Ƿ�ѧ�����κζ�����
��һ������������ʾһ�����Բ��Լ�������:
dataiter = iter(testloader)
images, labels = dataiter.next()
my_imgs_plot(images, labels)

ʹ��ѵ���õ��������ж����������Ǽ���:
# net = VGG11(3,num_classes=2).to(device)
# net.load_state_dict(torch.load(PATH))
net.to('cpu')
outputs = net(images)
# �����2����� energy ��һ����� energy Խ��,�����Խ����Ϊͼ�����ض����ġ�
# ��ô,�����ǵõ���� energy ��ָ��:
_, predicted = torch.max(outputs, 1)
my_imgs_plot(images, labels,predicted)
?

���ֶ�Ԥ����ȷ��(����ȷ�Ļ���),����ƺ��൱������
�����ǿ����������������Լ��ϵı���:
correct = 0
total = 0
net.eval()
# ��Ϊ���Dz���ѵ��,�������Dz���Ҫ����������ݶ�
with torch.no_grad():
for data in tqdm(testloader):
images, labels = data
# calculate outputs by running images through the network
outputs = net(images)
# the class with the highest energy is what we choose as prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {100 * correct // total} %')
100%|��������������������| 63/63 [00:15<00:00, 4.20it/s]
Accuracy of the network on the 10000 test images: 99.7 %
�⿴���������ѡ��Ҫ�õö�,���ѡ���ȷ��Ϊ50%,�����ǵ�ģ�ʹﵽ��99.7 %��
���ſ��������������,������ֲ���:
# prepare to count predictions for each class
correct_pred = {classname: 0 for classname in class_names}
total_pred = {classname: 0 for classname in class_names}
# ͬ��,����Ҫ�ݶ�
with torch.no_grad():
for data in tqdm(testloader):
images, labels = data
outputs = net(images)
_, predictions = torch.max(outputs, 1)
# collect the correct predictions for each class
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[class_names[label]] += 1
total_pred[class_names[label]] += 1
# ��ӡÿһ�����ȷ��
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')
100%|��������������������| 63/63 [00:15<00:00, 3.97it/s]
Accuracy for class: 0_real is 100.0 %
Accuracy for class: 1_fake is 99.4 %
����ͨ��GPU��������һ��Сʱ��ѵ��ʱ��Ҳ̫����,99.7 %��ȷ��Ҳ��������,��û�и��õķ�����?
������������Ǩ��ѧϰ
���ڲο�:Transfer Learning for Computer Vision Tutorial �� PyTorch Tutorials 1.11.0+cu102 documentation
ʵ����,��������ѵ���������������ͷ��ʼ(�����ʼ��),��Ϊ�������㹻������ݼ����෴,���Ǻܳ������ڷdz�������ݼ���Ԥѵ��ConvNet(����,ImageNet ����120����ͼ��(����1000�����),Ȼ��ʹ�� ConvNet ������Ϊһ����ʼ����̶��Ĺ�����ȡ����
��������Ҫ��Ǩ��ѧϰ����������ʾ:
- ConvNet ��Ϊ�̶�������ȡ��:������,���ǽ�����Ȩ�ض�����������,����������ȫ���ӵ���������һ����ȫ���ӵIJ㽫�滻Ϊ�²�ʹ�����Ȩ��,ֻ�Ըò����ѵ����
- �� ConvNet:���Dz��������ʼ��,������Ԥ��ѵ���õ������ʼ������,������imagenet 1000���ݼ��Ͻ�����ѵ��ʣ�µ�ѵ��������Ҳһ��ͨ����
from __future__ import print_function, division
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import torch.backends.cudnn as cudnn
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
cudnn.benchmark = True
plt.ion() # interactive mode
<matplotlib.pyplot._IonContext at 0x7fd0cccd90a0>
1. ��ȡ����
��������һ��������ͬ.
ͨ��,����һ���dz����ӵ�����������㿪ʼѵ��,�Ϳ��Զ�С���ݼ����и������Դ��������ʹ��Ǩ��ѧϰ,����Ӧ���ܹ������ظ�����
# Data augmentation and normalization for training
# Just normalization for validation
# https://blog.csdn.net/KaelCui/article/details/106175313
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'validation': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
batch_size = 4
data_dir = './CNN_synth_testset_divided/'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'validation']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size,
shuffle=True, num_workers=4)
for x in ['train', 'validation']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'validation']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
���ӻ�һЩͼ��
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
def my_imgs_plot(image, labels, preds=None):
cnt = 0
plt.figure(figsize=(16,16))
for j in range(len(image)):
cnt += 1
plt.subplot(1,len(image),cnt)
plt.xticks([], [])
plt.yticks([], [])
if preds is not None:
plt.title(f"predicted: {class_names[preds[j]]}, true: {class_names[labels[j]]}\n"
,color='green' if preds[j] == labels[j] else 'red')
else:
plt.title("{}".format(class_names[labels[j]]), fontsize=15, color='green')
inp = image[j].numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
plt.show()
# Get a batch of training data
inputs, classes = next(iter(dataloaders['train']))
my_imgs_plot(inputs, classes)
?

2. ѵ��ģ��
����,�����DZ�дһ��ͨ�ú�����ѵ��һ��ģ�͡�
�������ʾ����,����scheduler�����Ե�LR scheduler����torch.optim.lr_scheduler��
from tqdm import tqdm
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
loss_plot = []
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in tqdm(range(num_epochs)):
print(f'Epoch {epoch}/{num_epochs - 1}:',end=' ')
# ÿ�� epoch ����һ����ѵ����֤��
for phase in ['train', 'validation']:
if phase == 'train':
model.train() # ��ģ������Ϊѵ��ģʽ
else:
model.eval() # ��ģ������Ϊ����ģʽ
running_loss = 0.0
running_corrects = 0
# �������ݡ�
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# �������ݶȹ���
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
# print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
loss_plot.append(epoch_loss)
# deep copy the model
if phase == 'validation' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print(f'Training complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')
print(f'Best val Acc: {best_acc:4f}')
plt.plot(loss_plot)
# load best model weights
model.load_state_dict(best_model_wts)
return model
���ӻ�ģ�͵�Ԥ��
������ʾһЩͼ��Ԥ��ĺ���
def visualize_model(model, num_images=8):
was_training = model.training
model.eval()
images_so_far = 0
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['validation']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
my_imgs_plot(inputs.cpu(),labels, preds)
images_so_far += batch_size
# for j in range(inputs.size()[0]):
# plt.figure(figsize=(12,12))
# images_so_far += 1
# ax = plt.subplot(num_images//2, 2, images_so_far)
# ax.axis('off')
# ax.set_title(f"predicted: {class_names[preds[j]]}, true: {class_names[labels[j]]},{'success' if preds[j] == labels[j] else 'failure'}")
# imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
3. ConvNet ��Ϊ�̶�������ȡ��
������,������Ҫ��������һ��������������硣������ҪҪ����requires_grad = False�������,�Ա���backward()�в������ݶȡ�
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
# Parameters of newly constructed modules have requires_grad=True by default
num_ftrs = model_conv.fc.in_features
model_conv.fc = nn.Linear(num_ftrs, 2)
model_conv = model_conv.to(device)
criterion = nn.CrossEntropyLoss()
# ע��ֻ�����һ��IJ��������Ż�,������֮ǰ��
optimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)
ѵ��������
��CPU��,��֮ǰ�ij������,�⽫���Ѵ�Լһ���ʱ�䡣����Ԥ�ڵ�,��Ϊ���������²���Ҫ�����ݶ�,Ȼ��,forward ȷʵ��Ҫ���㡣
model_conv = train_model(model_conv, criterion, optimizer_conv,
exp_lr_scheduler, num_epochs=25)
PATH = './fakeFace_tf_{}.pth'.format(model_conv.__class__.__name__)
torch.save(model_conv.state_dict(), PATH)
100%|��������������������| 25/25 [07:15<00:00, 17.42s/it]
validation Loss: 0.3544 Acc: 0.8430
Training complete in 7m 15s
Best val Acc: 0.880000
?
visualize_model(model_conv)
plt.ioff()
plt.show()
?


���ֽ�ѵ��ȫ���Ӳ�Ļ�Ч����̫��,���������Զ����в��� Fine-tuning �ķ�����
4. Fine-tuning - ������
����Ԥѵ��ģ�Ͳ�����������ȫ���ӵIJ㡣
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# ����,ÿ����������Ĵ�С����Ϊ2��
# ����,�������ƹ㵽 nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
ѵ��������
��GPU��,ֻ�費��10����
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=15)
100%|��������������������| 15/15 [10:20<00:00, 41.38s/it]
validation Loss: 0.0028 Acc: 1.0000
Training complete in 10m 21s
Best val Acc: 1.000000
?
���Է�����ȷ�ʴﵽ��100%��
visualize_model(model_ft)
?


�ο�
Autograd mechanics �� PyTorch master documentation
Transfer Learning for Computer Vision Tutorial �� PyTorch Tutorials 1.11.0+cu102 documentation

