Ŀ��:�����ļ�data.csv��ij��Ʊ��1997-2017��20���������Ⱥ�������,�ҳ�ʱ�����ݵĹ�������,���ֱ�ͨ��ָ��ƽ�������Իع�ARIMAģ�ͷ���,����ʱ�����ݵ�Ԥ��ģ��,��Ԥ��������ĺ���(bonus)��
data.csv
?ע��:���Ľ�����ѧϰPython��ʱ���������ݵĴ���,���������ڳ��ɾ���!!!
1. ���ذ�
import pandas as pd
import numpy as np
from statsmodels.tsa import holtwinters as hw
from statsmodels.tsa.stattools import adfuller
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
from statsmodels.graphics.gofplots import qqplot
import matplotlib.pyplot as plt
from statsmodels.tsa import arima_model
import warnings
2. ��������
f = open('ʵ��4����.csv')
mydata = pd.read_csv(f)
# print(mydata)
print(mydata.head())
3. ����ʱ�����ݲ���ͼ
ts = pd.period_range('1997/01', periods=len(mydata), freq='Q')
# ����DF�ṹ������,��tsΪ����,��bonusΪ����
bonus_data = pd.DataFrame(mydata['bonus'].values, index=ts, columns=['bonus'])
print(bonus_data.head())
# ��ʾ���еĵ�
bonus_data.plot(style=['+-'], figsize=(16, 9))
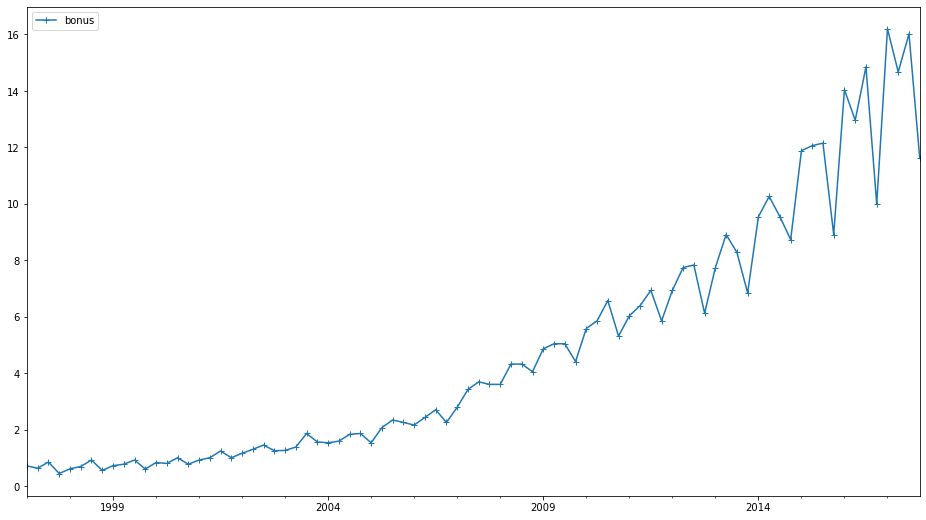
4. ����Ԥ����
- ��������:bonus(��Ʊ����)����ʱ��䶯����������
- ���ڱ䶯:bonus(��Ʊ����)�ڵ��ġ�һ������������,�ڵ���������ֵ�½�,������ʱ��仯,�����Ŵ����
# ���ݶ�����
bonus_log = np.log(bonus_data)
bonus_log.plot(style='+-', figsize=(16, 9))
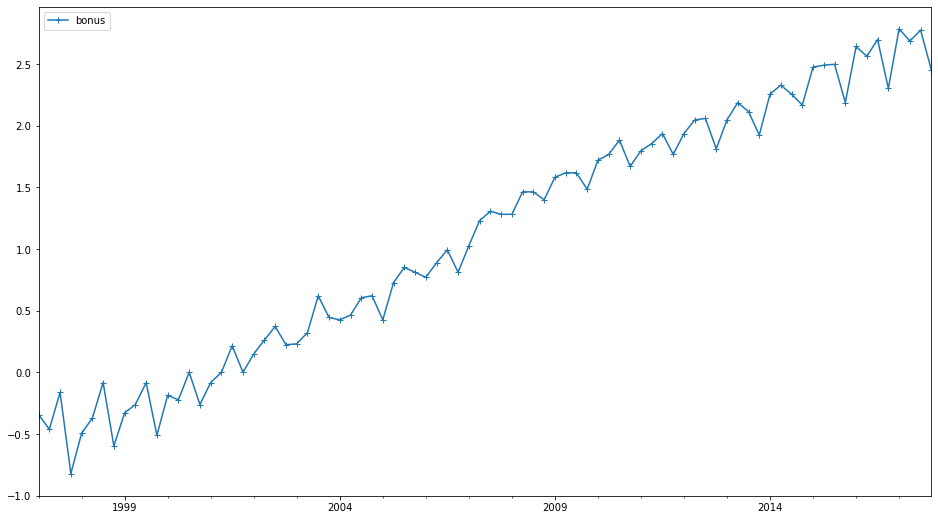
5. ����ģ�ͨC����ָ��ƽ����
һ��ָ��ƽ��:����������û�����ƺͼ���������
����ָ��ƽ��:��������������������������������
����ָ��ƽ��:�����������������������м���������
5.1 ����ģ��
# �������ơ���������:add
# ��������:����
# seasonal_periods:��������Ϊ4,�¶����ݵ�Ϊ12,����������Ϊ7
# trend��seasonalΪadd,��ȡһ��ʱ���,��������Ϊ0
bonus_hw = hw.ExponentialSmoothing(bonus_log, trend='add', seasonal='add', seasonal_periods=4)
hw_fit = bonus_hw.fit()
hw_fit.summary()
bonus_data.plot()
np.exp(hw_fit.fittedvalues).plot(label='fitted_values', legend=True)

5.2 �в�ͼ
plot_acf(hw_fit.resid)

5.3 �в�(Ԥ�����)��ƽ���Լ���(��λ������)
������ڵ�λ��,��ô���Ƿ�ƽ��ʱ������,��ʹ�ع�����д���α�ع�
�ڶ���Ϊpֵ,С��0.05�������ж��в�Ϊƽ������
adfuller(hw_fit.resid)
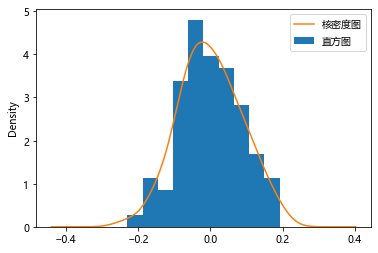
5.4 ֱ��ͼ+���ܶ�ͼ
���ܶ����������ڸ����ܶ�����,�������µ������1,�����y���ϵĵ�λͨ����С��1�ĺ��ܶȷֲ�ֵ��
ʵ����һ�ֶ�ֱ��ͼ�ij�������ͳ��ѧ�е�Ƶ���ֲ�ͼ�����ܶȺ���������
plt.figure()
# ��Ҫע�����:��ֱ��ͼ�Ļ��������Ӻ��ܶ�ͼ,���뽫ֱ��ͼ��Ƶ������ΪƵ��,��density��������ΪTrue��
plt.hist(hw_fit.resid, density=True, label = 'ֱ��ͼ')
hw_fit.resid.plot(kind='kde', label = '���ܶ�ͼ')
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']#������������
plt.legend()# ��ʾͼ��
plt.show()
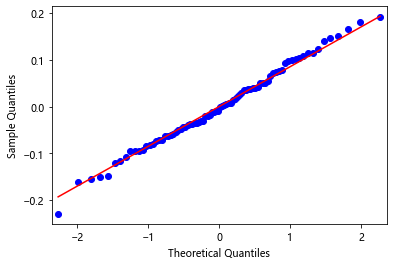
5.5 ��̬qqͼ
qqplot(hw_fit.resid, line='s')
����qqͼ��֪,�в������̬�ֲ�,���С��3
5.6 Ԥ��
bonus_forecast = np.exp(hw_fit.predict(start='2018/1', end='2019/12'))
print(bonus_forecast)
bonus_data.plot()
bonus_forecast.plot(label='forecast', legend=True)
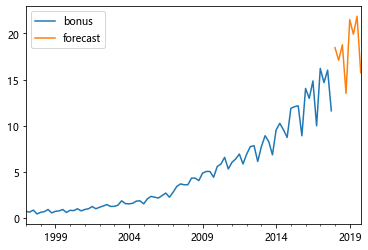
6. �Իع��ƶ�ƽ����
��������ƶ�ƽ���Իع�ģ��(ARIMA) ��ָ����ƽ��ʱ������ת��Ϊƽ��ʱ������,Ȼ����������������ͺ�ֵ�Լ������������ֵ���ͺ�ֵ���лع���������ģ�͡�
ARIMA(p,d,q)��,AR�ǡ��Իع顱,pΪ�Իع�����;MAΪ������ƽ����,qΪ����ƽ������,dΪʹ֮��Ϊƽ�����������IJ�ִ���(����)��
����˼·:
- ����������ʱ��仯����,�ж�Ϊƽ�����л��Ƿ�ƽ������
- ��Ϊ��ƽ������,ʹ�ò��ת��Ϊƽ������,�õ�����d��ȡֵ
- ����ACF��PACFѰ�����Ų���p��q
ƽ������:
�����ϲ��������Ƶ�����,���۲�ֵ��������ij���̶���ˮƽ�ϲ���;�����в���,����������ij�ֹ���,���䲨�����Կ���������ġ�
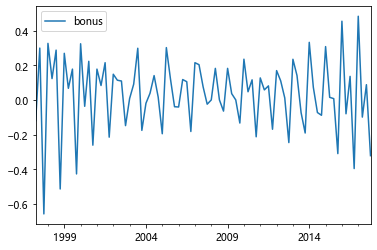
6.1 ���
���,����˵���Ǻ�һʱ����ֵ��ȥ��ǰʱ���,Ҳ���� y t ? y t ? 1 y_{t}-y_{t-1} yt??yt?1?, ÿ��һ�β�־���һ�����ݡ�
# һ�ײ�ֲ�ȥ����ֵ
bonus_log_diff1 = bonus_log.diff().dropna()
bonus_log_diff1.plot()
# ���Կ���ͨ�� 1 �β�������Ѿ�ƽ��
adfuller(bonus_log_diff1['bonus'])
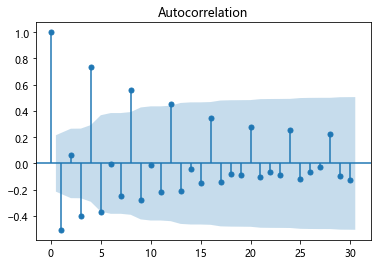
6.2 �����ͼ��ƫ�����ͼ
# �����ͼ ��β
plot_acf(bonus_log_diff1, lags=30)
# ƫ�����ͼ ��β
plot_pacf(bonus_log_diff1, lags=30)
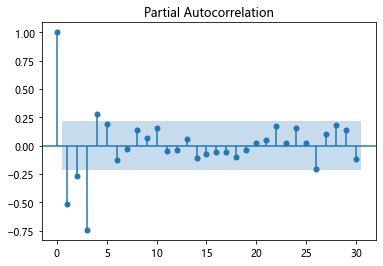
6.3 ȷ��ģ�Ͳ���
aic_values = []
find_index = ()
warnings.filterwarnings('ignore')
for p in range(8):
for q in range(8):
try:
myfit = arima_model.ARIMA(bonus_log, (p,1,q)).fit()
aic_values.append(myfit.aic)
print('(%d:%d,1,%d), AIC:%d' %(find_index, p, q, myfit.aic))
find_index += 1
except:
pass
print(aic_values.index(min(aic_values)), min(aic_values))
arima_fit = arima_model.ARIMA(bonus_log, (3,1,2)).fit()
arima_fit.summary()
6.4 �������
# ƽ���Լ���
# plot_acf(arima_fit.resid)
adfuller(arima_fit.resid)
6.5 QQͼ
qqplot(arima_fit.resid, line='s')
plt.figure()
plt.hist(arima_fit.resid, density=True)
arima_fit.resid.plot(kind='kde')
plt.show()
# �в������̬�ֲ�

6.6 Ԥ��
bonus_forecast = np.exp(arima_fit.forecast(8)[0])
print(bonus_forecast)
plt.figure()
plt.plot(range(len(bonus_data)), bonus_data['bonus'], label='bonus')
plt.plot(range(len(bonus_data), len(bonus_data)+len(bonus_forecast)),
bonus_forecast, label='forecast', color='r')
plt.xlim(0, 100)
plt.ylim(0, 25)
plt.legend()
plt.show()
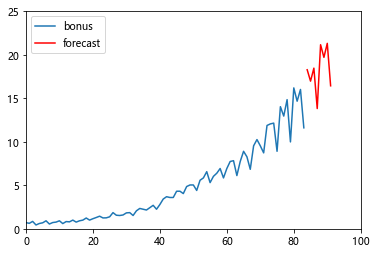
7. �Ƚ�����ģ�͵�����
print('ָ��ƽ����:AIC=%d, SSE=%.2f \n ARIMAģ��:AIC=%d, SSE=%.2f' %(hw_fit.aic, sum(hw_fit.resid**2), arima_fit.aic, sum(arima_fit.resid**2)))

