ACNet:通过去耦记忆和遗忘的无损CNN剪枝 ?
摘要:ResRep展示了结构重参数化的另一种用途:构造额外结构,为某种花式操作提供空间,以达成我们的某些目的,为模型赋予某些性质。
Abstract?
????????本文提出了一个新颖的方法 ResRep,用于无损的通道剪枝(即滤波器剪枝),它通过降低卷积层的宽度(输出通道的个数)对CNN做剪枝。在神经生物学中,记忆和遗忘是独立的。受此启发,作者提出将CNN重参数化为记忆部分和遗忘部分,前者学习保持模型的性能,后者学习如何剪枝。对前者用标准的 SGD 来训练,但对后者会采用一个新的更新策略,对其梯度做惩罚,这样就可实现结构稀疏性。然后,我们将记忆和遗忘部分等价地融合进原来的结构中,网络层要窄一些。这个方法将 ResRep 和传统的、基于学习的剪枝范式区别开来,它们都是对参数进行惩罚,从而得到稀疏性,但这会抑制记忆部分的参数。在 ImageNet 上,ResRep 将一个标准的 ResNet-50 的 FLOPs 降低了 45 % 45\%45%,但准确率没有下降,仍然是76.15 % 76.15\%76.15%。它是第一个压缩率如此高,而能实现无损剪枝的算法。
1. Introduction
????????压缩和加速CNN的主流方法包含了稀疏化、通道剪枝、量化、知识蒸馏等。通道剪枝(即滤波器裁剪或模型缩减)降低卷积层的宽度(即输出通道数),有效地减少FLOPs个数和内存占用,它可作为其它模型压缩方法的辅助措施,因为它不用特殊的结构或操作就可输出一个轻量版的模型。
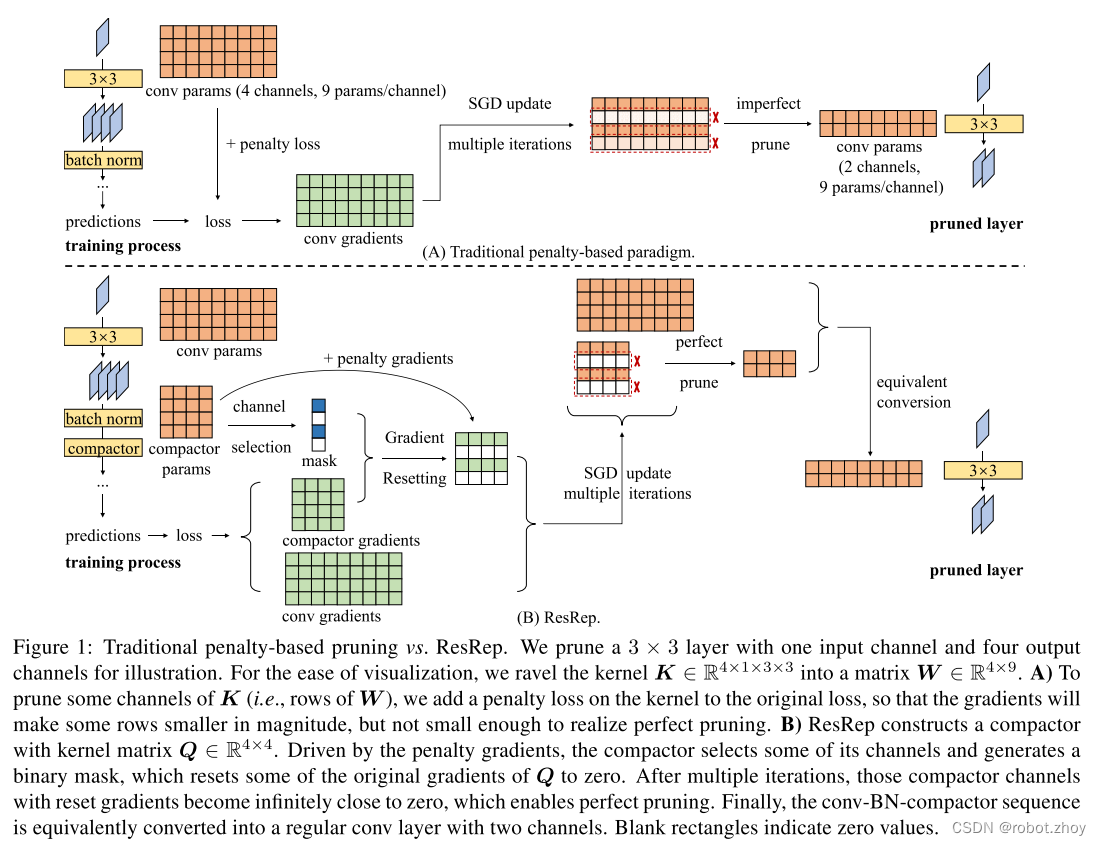
????????但是,CNN 的表征能力取决于卷积层通道的宽度,降低通道宽度而不损失准确率是很难做到的。对于 ResNet-50 这样的网络结构和大规模数据集如 ImageNet,压缩率极高的无损剪枝是非常有挑战性的任务。为了平衡压缩率和模型表现,常见的范式(图1A)会将量级有关的惩罚损失(如 group Lasso)加到卷积核上,产生通道稀疏性,也就是说某些通道参数的量级会变得很小。如果裁剪通道的参数的量级足够小,剪枝后的模型的表现可能就会与剪枝前一样,这就是很完美的剪枝。
????????因为训练和剪枝都会造成模型退化,作者从两个方面来评估基于训练的剪枝方法。1) 抗性。训练阶段会降低准确率(叫做训练引发的损失),因为它会引入一些结构稀疏性,这可能是有害的,因为优化的目的就变了,参数就偏离了最优的。如果一个模型的表现在训练过程中保持的不错,我们就说它有着很强的抗性。2)可裁剪性。训练过后,我们将一个模型剪枝缩小,某些特性(如许多通道的值趋近0)可能会减小剪枝引发的损失。如果模型能够在较高的剪枝率下,而其表现没下降,则说它具有很高的可裁剪性。
????????我们需要抗性和可裁剪性,但是传统的、基于惩罚的范式天然地就需要去平衡抗性-可裁剪性。比如,group Lasso 能实现很高的稀疏性,但会造成训练引发的损失,而惩罚小的话,会保持模型的性能,但稀疏性差,因此造成很高的剪枝引发的损失。3.3节做了详细分析。
????????本文作者受到神经生物学中关于记忆和遗忘研究的启发,提出了 ResRep 来解决上述问题。????????
????????1)记忆需要大脑去增强某些突触而抑制另一些突触,这与CNN的训练过程相似,一些参数会变大,而另一些会变小。
????????2)一个经典的遗忘机制是通过收缩来去除某些突触,可提升生物神经网络对能量与空间的利用效率,这和剪枝类似。神经生物学揭示,记忆和遗忘独立地受到了 Rutabaga 腺苷酸环化酶抑制记忆形成机制和 Rac-调节的脊柱收缩机制控制,这说明通过两个解耦的模块来学习和剪枝更加合理。
????????受此启发,作者提出了将“记忆”和“遗忘”解耦,在传统的范式中,二者是耦合的。卷积参数既包含了“记忆”(目标函数),也包含了“遗忘”(惩罚损失),从而达到平衡状态。传统方法强迫每个通道去“遗忘”,然后去除掉“遗忘得最多的”那些通道。然而本文首先将原始模型重新参数化为“记忆部分”和“遗忘部分”。然后对前者通过“记忆学习”(对原来的目标函数使用标准的SGD)来维持其“记忆”(原始表现),对后者通过“遗忘学习”,从而“去除突触”(将通道值设为0)。
????????ResRep 包含2个关键部分:卷积重参数化(Rep,解耦再等价转换),以及梯度重设置(Res,“遗忘”的更新规则)。在我们想要裁剪的网络层后面,插入一个compactor(一个1 × 1卷积)。训练时,我们只对这个 compactor 施加惩罚梯度,选择 compactor 的一些通道,将它们从目标函数得到的梯度设为0。该训练过程会将 compactors 的一些通道的值变得接近于0,这样去掉它们就不会造成裁剪引起的损失。然后,作者将 compactor 和它前面的那一层卷积层,通过线性变换(等式8和9)等价地转换为单个卷积层。注意,这个方法可以很容易地泛化到常见场景中去,一个卷积层后面跟着一个BN。这时,我们在BN层后添加一个 compactor,然后先将卷积-BN融合为一个带有偏置的卷积层(等式4),再将卷积-BN-compactor序列做转换。最终结果模型与原始模型(没有 compactors)的结构是一样的,但是层要更窄(图1B)。因为从训练时模型等价地转换为剪枝模型依赖于参数的等价转换,ResRep 可以看作为结构重参数化的应用。先前的结构重参数化研究对 VGG 网络、基本的卷积层或者 MLP 构建模块做了改进,但都通过传统的训练过程。而 ResRep 既构建了额外的结构(即 compactors),它可等价地转换回去(Rep),也使用了一个特殊的训练策略(Res)。如4.3节介绍的,Rep 和 Res 都很重要:Rep 为 Res 构建了一些结构,这样不会丢失原始信息;Res 将一些通道设为0,这样 Rep 能将得到的卷积层变得更窄。ResRep 也能对全连接层做剪枝,因为它等价于一个1×1卷积。

????????ResRep 特征:
????????1) 高抗性。为了维持性能,ResRep 没有改变原模型(即卷积-BN部分)的损失函数、更新策略或任何的超参数。
????????2)高可裁剪性。惩罚梯度会驱使 compactors,许多通道的值会很小,从而实现完美的剪枝,即便惩罚的力度比较温和。
????????3)给定我们想要的 FLOPs 全局缩减率,ResRep 无需先验知识,自动找到每一层适合的宽度,这对CNN结构优化来说很有帮助。
????????4)端到端的训练以及实现很容易(算法1)。本文贡献主要有:
????????受到神经生物学启发,提出将“记忆”和“遗忘”解耦来进行剪枝。提出了2项技术,Rep 和 Res,实现高抗性和可裁剪性。它们可以单独使用,合起来用效果最佳。在通用基准上实现了 SOTA 结果,在ImageNet 数据集上对 ResNet-50 做无损剪枝,剪枝率为54.5 % 54.5\%54.5%。
?2. Related Work
????????剪枝就是去除网络中的任意参数或结构。非结构化剪枝能够降低非零参数的个数,但是无法加速常用的计算框架。结构化剪枝能够去除一些整体结构(如全连接层的神经元、2D卷积核、通道),对硬件更友好。通道剪枝尤其有效,因为它不仅可以降低模型大小、实际计算量,也可降低内存占用。剪枝和彩票假设[17]有关联。比如,我们可以用 ResRep 在训练前就找到“胜利”的通道。除了通用的模型剪枝外,某些场景(如数据有限的场景)下的剪枝也吸引了大量关注。
????????通道剪枝方法大致可分为两类。剪枝后微调方法会通过一些手段,找出并剪掉一个训练好的模型中的不重要的通道,这会造成准确率的下降,所以就需要微调。一些方法重复进行“剪枝后微调”,计算各通道重要度,渐进地剪枝。一个主要的缺点就是,剪枝后的模型可能很容易就掉入了糟糕的局部极小值,其准确率和从头开始训练的模型(相同的结构)相比甚至都不在一个层级。这就凸显了完美剪枝的重要性,我们就无需微调了。在这一类方法中,PCAS 与 ResRep 联系最紧密,它通过训练卷积层后的注意力模块来找到无关紧要的通道。与 ResRep 不同,PCAS 不算完美的剪枝,它需要在通道去除后进行微调。此外,PCAS 在训练完成后丢弃了注意力模块,造成结构损失,而 ResRep 使用了一个数学等价的变换,得到最终的模型结构,没造成性能下降。基于学习的剪枝 方法利用了传统的学习过程来降低裁剪引起的损失。该基于惩罚的范式会将某些通道置为0,而另一些方法则通过元学习、对抗学习或将某些滤波器设为相同,来完成剪枝。
3. ResRep for Lossless Channel Pruning
3.1. Formulation and Background
3.2 卷积重参数化
????????显然,我们得先找到等价拆分和等价合并的方式,也就是Rep的具体形式。本文主要考虑通道剪枝(channel pruning, 即filter pruning, 也叫network slimming),采用的实现方式是在要剪的卷积层(记作convA)后加入一个1x1卷积(记作convB,称为compactor)。
????????等价拆分:若convB的kernel为单位矩阵,则整个结构的输出不变(对任意x,convB(convA(x)) == convA(x))。
????????训练(应用我们提出的花式操作,即Res,稍后详细介绍)结束后,假设已经把convB剪成了有D'(D' < D)个输出通道的convP(也就是将compactor的kernel从一个单位矩阵变成行数少于列数的矩阵),如何将convA和convP等价转换为一层呢?
????????等价合并:用convP的kernel来卷convA的kernel,得到convM,(注意要经过适当的转置)则convM和原convA-convP输出相同(对任意x,convM(x) == convP(convA(x)))。直观上也很好理解:由于convP是1x1卷积,它的实质是对输入进行通道之间的线性重组,不涉及空间上的聚合运算,所以convP(convA(x))等价于【先用convP的kernel对convA的kernel进行通道之间的线性重组,然后用重组后的kernel去卷x】。注意,convM的输出通道等于convP的输出通道,所以剪掉compactor的输出通道等价于剪掉合并后的卷积层的输出通道!
?
?

