����Ŀ¼
- ch6 - ceres��g2o��
- ǰ��
- 1.G2o
- 2.Ceres
- --1.1.������
- --1.2. �����Ż�����
- 2.Ceres ���������ܽ�
- --2.1 �����Ż���������ʧ�˺���
- --2.2 ��problem�����Ӳ�����- **`AddParameterBlock`**���ع���
- **----2.2 �����䡿**:
- ���ӳ���-from F-LOAM
- --2.3 ���Ӳв��
- [����]ICP-slamʮ�Ľ� �Զ���ʵ��(q t �ֿ�)
- [����]����loam-livox ��ICP��ceres �Զ���ʵ��:
- [����] ICPslamʮ�Ľ�������-se3(qt�ϳ�7ά):
- [����]������,���ſ˱�:�����֤��������ȷ����???
- --2.4 ������Ա����
- --2.5 ���
- 3. ��Ʒ����
ch6 - ceres��g2o��

ǰ��
����һ��ܽ�;���ġ� G2o��Ceres Ҳ��ϣ����������Զ��ͽ��������ķ���(g2o:���ߡ�˫�ߡ���� ; Ceres:�Ż�������Ⱥ������IJ�ͬ��ʾ���в�����Զ���ģ����ͽ������ſ˱ȵ��Ƶ���)ϣ�����걾������,�ܶԴ������������
ǰ�Բ���,����������ɡ�ֻ��һ���˵�����������ѡ�
����С�����,�о�����ʱ���һ��һ��ȥ���ٷ��̳̻��߲�ѯ�ٷ����ֲᡢ��Ӧ����֮��ġ� Eigen Opencv PCL Ceres�ȵȿⶼһ��,wiki����ٿƹ���Ҳ�ܰ���
һЩ�����ע��Ҳ�����ѧ�߶��,����copy����Ĵ���IDE��ȥ��,����ע�Ϳ�������Щ
- ��Щ����Ҳ����֮ǰѧϰ���ܽ�������,���ھ�����ʱ��ԭ��,û��ô�Ű�ֱ�ӵ����ˡ����ܻᷢ�ֺ���,�Ű����,Ҳ����,�Ͼ������ҵ�ѧϰ����,һ�¶϶���������ɾ�IJ顣 ��������,������ȥ��Ceres�ٷ�ָ���ֲ� ;g2o�Ļ��е����,ֱ���Ķ�Դ���뼴��,��������Ϳ��,��ɶ��ת��ȥ�����С� ����Ҳ�ṩ��һЩ����,�����Ӿ�slamʮ�Ľ���,�ȵȡ�
- �ڶ�������:Ϊɶ�Լ��о�д���û��ϴ�������?�����á��������ۡ���? �����Щ������������,��Ҫ̸��Ϊɶ�ϴ��ij����ˡ��ܵ�ҵ�ڴ�ţ,�����ǵĽ̵�,Ҳ�ܵ����ǵ�˼�롰Ѭ�ա�:֪ʶ�����������ġ�����Ŀǰ�ҵ���������,д�ĺ���,���������һ���ҵ�ѧϰ������������֮���,����Ŀǰ���ҵ����������Է��������ҵ,��˵��������Ҫѧϰ��������ǰ����˵��һ�仰,������Խ��,�ᷢ���Լ�Խ��֪�����Ҷ�ijһ����ѧ�˸���ŵ�ʱ��,�ͻ�մմ��ϲ,���ڿ������л���С����ѧϰ����,�һᷢ�������С��ܴ������ռ䡱������Ҳ�ڼ�������ط��������,����֪ʶ,ѧ��ֹ���ɡ�
��ƫ��,Ŀ��Ҳ������:1.�����Լ���ѧϰ����,�յ�����ָ���Լ���ͬʱ,�ܶ��������С����,���±�һ����Ҳ�ǿ��Ե� ; 2.���Ǽ�¼���Լ��Ľ�����ѧ��,�����������ᾫ�����,��������,ȥ�����ɡ� - ��Ŀǰ����һ��ѧ��,�ҽ���Ҳ���ҹ�����һ��,�кܶ��ҵ�ѧϰ�����Ϳ�֮�����Ҫ����,������ʱ��;����� ���ڸ��Ӱѡ���2022.10�µ�,�ȹ�������֮��,���ܽᡶ�Ӿ�slamʮ�Ľ��������ݺͿκ���(�����е����µIJ��ִ�)��VIO slam ���ۺʹ����ѧϰ(����VINS)������slam(LOAM A-LOAM F-LOAM LeGo-LOAM )�Լ�LIO-SAM��LVI-SAM�ȿ�Դ�������ġ��������ݡ������ѧϰ�� ��Щ���Ҷ�����������ɢɢ�ıʼǺ�˼ά��ͼ������ͼ��,��Ҫȥ����,��������Ӻܴ�
- Ϊɶʱ��;���������?���ֲ��ǹ�����,ѧ��ʱ�仹��ȱ��?�Ҹ�������͵���,��������С���Ӧ��Ҳ�ид�,Ϊ��һ����Щ�IJ����ͷ���,��Ҫ���������¡� ��Ŀǰ�Ľξʹ��ڼ���Ҫ������ܽ����ۡ�����Ҫȥ�����Ŀ���ݡ�����Ҫ��������Ҫ��ˢ��֮��ġ�����֮ǰ��ɶ��?Ϊɶ����ǰ��������Щ����?ǰ����Ҹ�����,��,�տ�ʼѧSLAM,������ʦ�ִ����Ӿ�slam,��Ȼ�����ڿ��ܶԺܶණ��������Ϥ��ֻ��˵һ������һ���ε�ѧϰ����,�������ľ��Ǿ������Ч��,ѹ�����������ѵ�ʱ���ͬʱ��֤������
- һ���ͳ�Զ��,Ϊɶ������?���ܸ������������,��Ŀ���Ƕഫ����slam��λ,���߶������ѧϰDL����ҽ��,��е������,����һ����û�С�ȷʵ,û�����۵ġ� ����Ҫ�����������൱,���ܷ���һ��,һ��ѧϰ��Ҳ���ѡ����˵���,��������Ҫѧϰ�����ݺܶ�,û��̫��ʱ��ȥ������ǵġ� ÿ����ѧϰ��һ���µĽ�,�ͷ��ֺ��滹�кܶ���Ҫѧϰ�����ݺ�֪ʶ����Ȼѡ��ǰ�����ʺ��ҵ��ǿ϶���,�ܶ����۷dz�����,����֮����ѧ����֪�����ۼ��ɡ�
1.G2o
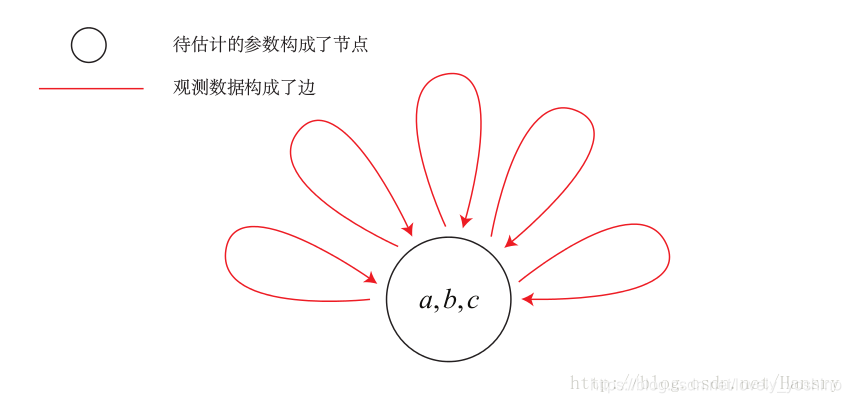
? ͼ�Ż�,�ǰ��Ż�������ֳ�ͼ��һ�ַ�ʽ,�����ͼ��ͼ�������ϵ�ͼ��һ��ͼ�����ɸ�����,�Լ�������Щ����ı������������,�����ö����ʾ�Ż�����,���ñ߱�ʾ����
1.1 ���� :��G2o: exp(ax^2+bx+c)��
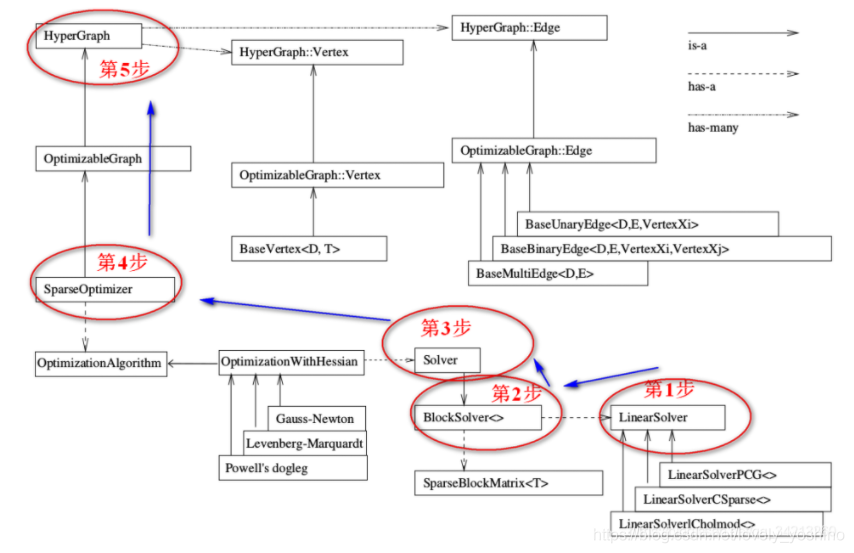
����ͼ�Ż�,���趨g2o - ά�ȡ���������͡��Ż�ѡ��-GN��LM��Dogleg�ȡ�����ͼ�Ż��ĺ���-ϡ���Ż���(SparseOptimizer optimizer)
������ͼ�Ķ���ͱ�,�����ӵ�SparseOptimizer�� ��
���Ӷ���: (�����������Ҫ�Լ�����);setEstimate setId��
���ӱ�:(��ͬ��,Ҳ��Ҫ�Լ���������-���-�ſ˱�����);setId��setVertex��setMeasurement��setInformation��
ִ���Ż�:
optimizer.initializeOptimization(); //�ȳ�ʼ��
optimizer.optimize(����);�������ֵ: Ҳ���Ƕ���
1.2 ����-ԭ������:
Ceres����ͨ�õ���С������������,�����Ż�����,����һЩѡ��,��ͨ��Ceres��⡣
G2O����ѧ����Ҫ��Ϊ�ĸ���ⲽ��:

1.3 G2O������������
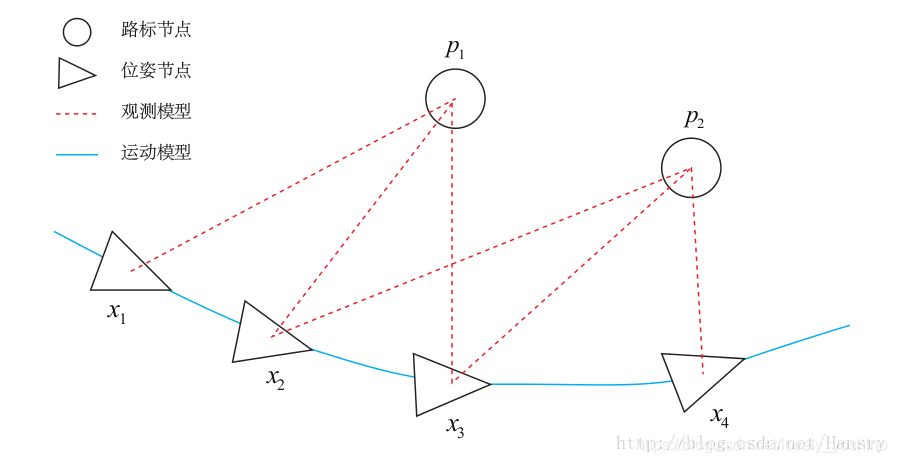
����ͼ��ʾ,���ͼ��Ӧ��������ǰ�������
�����Լ�����������ͼ�ϵ�дд����,��ͼ���硣
�ڵ�ͱߵIJ���,��;ͬ��,�Լ�������ɶ�ü���,ͼ�еIJ����д���,�����ο���
��g2o��ʱ��,�����һ�ͼȥ����,�Ƚ�g2o��ͼ�ܲ��ɷ֡����Լ����ij�ͼ,�Ͳ��ó����׳��ˡ�ֻ����ȥ���ֻ���,ȥ�Ƶ���,ȥ����ʵ����,����ܷ����Լ��IJ�������۶̰塣��仰�������Լ���

1.3.1 ѡ��ͬ����ⷽʽ��������Է���,g2o���ṩ����ⷽʽ��Ҫ��:
| LinearSolverCholmod | ʹ��sparse cholesky�ֽⷨ���̳���LinearSolverCCS |
| LinearSolverCSparse | ʹ��CSparse�����̳���LinearSolverCCS |
| LinearSolverDense | ʹ��dense cholesky�ֽⷨ���̳���LinearSolver |
| LinearSolverEigen | ������ֻ��eigen,ʹ��eigen��sparse Cholesky ���,��˱���ú���Է�����������ط�ʹ��,���ܺ�CSparse��ࡣ�̳���LinearSolver |
| LinearSolverPCG | ʹ��preconditioned conjugate gradient ��,�̳���LinearSolver |
1.3.2 ����BlockSolver���������涨��������������ʼ��
? BlockSolver �ڲ����� LinearSolver,���������Ƕ�������������LinearSolver����ʼ�������Ķ����������ļ�����:
g2o/g2o/core/block_solver.h
template<int p, int l>
using BlockSolverPL = BlockSolver< BlockSolverTraits<p, l> >;
//variable size solver
using BlockSolverX = BlockSolverPL<Eigen::Dynamic, Eigen::Dynamic>;
// solver for BA/3D SLAM
using BlockSolver_6_3 = BlockSolverPL<6, 3>;
// solver fo BA with scale
using BlockSolver_7_3 = BlockSolverPL<7, 3>;
// 2Dof landmarks 3Dof poses
using BlockSolver_3_2 = BlockSolverPL<3, 2>;
block_solver.h�����,Ԥ�����˱Ƚϳ��õļ�������
BlockSolver_6_3 :��ʾpose ��6ά,�۲����3ά������3D SLAM�е�BA
BlockSolver_7_3:��BlockSolver_6_3 �Ļ����϶���һ��scale
BlockSolver_3_2:��ʾpose ��3ά,�۲����2ά
1.3.3 �����������solver������GN, LM, DogLeg ��ѡһ��,���������������BlockSolver��ʼ��
g2o::OptimizationAlgorithmGaussNewton
g2o::OptimizationAlgorithmLevenberg
g2o::OptimizationAlgorithmDogleg
eg:
auto solver = new g2o::OptimizationAlgorithmLevenberg( // LM����
g2o::make_unique<BlockSolverType>(
g2o::make_unique<LinearSolverType>()));
1.3.4 �����ռ���boss ϡ���Ż���(SparseOptimizer),�����Ѷ����������Ϊ��ⷽ��
����ϡ���Ż���
g2o::SparseOptimizer optimizer; //ϡ�������
optimizer.setAlgorithm(solver); // ���������
optimizer.setVerbose(true); // �������
��1.3.5 ����ͼ�Ķ���ͱߡ������ӵ�SparseOptimizer�С� ���ؼ���
? ��g2o�ж���Vertex��һ��ͨ�õ���ģ��:BaseVertex���ڽṹ��ͼ�п��Կ�������λ�þ���HyperGraph�̳еĸ�Դ��
- D ��int ����,��ʾvertex����Сά��,����3D�ռ�����ת��3ά��,��
D = 3 - T �Ǵ�����vertex����������,��������Ԫ��������ά��ת,�� T ����Quaternion ����
/**
* \brief Templatized BaseVertex
*
* Templatized BaseVertex
* D : minimal dimension of the vertex, e.g., 3 for rotation in 3D
* T : internal type to represent the estimate, e.g., Quaternion for rotation in 3D
*/
template <int D, typename T>
class BaseVertex : public OptimizableGraph::Vertex
��ζ����Լ���Vertex
�����Ƕ��ֶ����Լ���Vertex֮ǰ,�����ȿ���g2o�����Ѿ�������һЩ���õĶ�������:
VertexSE2 : public BaseVertex<3, SE2> //2D pose Vertex, (x,y,theta)
VertexSE3 : public BaseVertex<6, Isometry3> //Isometry3ʹŷʽ�任����T,ʵ����4*4����//6d vector (x,y,z,qx,qy,qz) (note that we leave out the w part of the quaternion)
VertexPointXY : public BaseVertex<2, Vector2>
VertexPointXYZ : public BaseVertex<3, Vector3>
VertexSBAPointXYZ : public BaseVertex<3, Vector3>// SE3 Vertex parameterized internally with a transformation matrix and externally with its exponential map
VertexSE3Expmap : public BaseVertex<6, SE3Quat>// SBACam Vertex, (x,y,z,qw,qx,qy,qz),(x,y,z,qx,qy,qz) (note that we leave out the w part of the quaternion.// qw is assumed to be positive, otherwise there is an ambiguity in qx,qy,qz as a rotation
VertexCam : public BaseVertex<6, SBACam>// Sim3 Vertex, (x,y,z,qw,qx,qy,qz),7d vector,(x,y,z,qx,qy,qz) (note that we leave out the w part of the quaternion.
VertexSim3Expmap : public BaseVertex<7, Sim3>
����!�����ʹ���з���û�����ǿ���ֱ��ʹ�õ�Vertex,�Ǿ���Ҫ�Լ��������ˡ�һ����˵����Vertex��Ҫ��д�⼸������(ע��ע��):
virtual bool read(std::istream& is);
virtual bool write(std::ostream& os) const;// �ֱ��Ƕ��̡����̺���,һ������²���Ҫ���ж�/д�����Ļ�,��������һ�¾Ϳ���
virtual void oplusImpl(const number_t* update);//������º��������¡�
virtual void setToOriginImpl(); //�������ú���,�趨���Ż�������ԭʼֵ����ֵ
���������ĸ��������Եõ����嶥��Ļ�����ʽ:
class myVertex: public g2o::BaseVertex<Dim, Type>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
myVertex(){}
virtual void read(std::istream& is) {}
virtual void write(std::ostream& os) const {}
virtual void setOriginImpl()
{
_estimate = Type();
}
virtual void oplusImpl(const double* update) override
{
_estimate += update;
}
}
///eg1 ��дλ�˽ڵ�///
class myVertexPose: public g2o::BaseVertex<6, SE3>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
virtual void setToOriginImpl() override { _estimate = SE3(); }
virtual void oplusImpl(const double* update) override
{
Vec6 update_eigen;
update_eigen << update[0], update[1], update[2], update[3], update[4], update[5];
_estimate = SE3::exp(update_eigen) * _estimate; // ��˸��� SE3 - ��ת����R
}
virtual bool read(std::istream& in) override {return true;}
virtual bool write(std::ostream& out) const override {return true;}
}
eg2 ��д·���ڵ� /
//new: ���ӿռ��Ϊ�Ż�����
class VertexPoint3 : public g2o::BaseVertex<3, Eigen::Vector3d> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
virtual void setToOriginImpl() override {
_estimate = Eigen::Vector3d::Zero();
}
virtual void oplusImpl(const double *update) override {
_estimate += Eigen::Vector3d( update[0],update[1],update[2] );
}
virtual bool read(istream &in) override {}
virtual bool write(ostream &out) const override {}
};
����ֵ��ע�����,�Ż��������²���������ʱ��������������һ��ֱ�� += �Ϳ���,��Ҫ���Ż�����ʹ�õ�����(�Ƿ�Լӷ����)��
��ͼ�����Ӷ���
�������涨����Ķ���,���ǰ������ӵ�ͼ��:
CurveFittingVertex* v = new CurveFittingVertex();
v->setEstimate( Eigen::Vector3d(0,0,0) ); // �趨��ʼֵ
v->setId(0); // ����ڵ���
optimizer.addVertex( v ); // �ѽڵ����ӵ�ͼ��
// ָ������ǰ�,����д��
if ( i == 0)
v->setFixed( true ); // ��һ����̶�Ϊ��
/*********************/
g2o::VertexSE3Expmap *vertex_pose = new g2o::VertexSE3Expmap(); // camera vertex_pose
vertex_pose->setId(0);
vertex_pose->setEstimate(g2o::SE3Quat()); // ���ó�ʼֵ,��Ԫ��
optimizer.addVertex(vertex_pose);
/********************/
// vertex2 p3d��
for (size_t i = 0; i < points_3d.size(); i++)
{
g2o::VertexSBAPointXYZ *vertex_point = new g2o::VertexSBAPointXYZ();
vertex_point->setId(i + 1);
vertex_point->setMarginalized(true);
vertex_point->setEstimate(points_3d[i]); //Eigen::Vector3d
optimizer.addVertex(vertex_point);
}
ͼ�Ż��еı�:BaseUnaryEdge,BaseBinaryEdge,BaseMultiEdge �ֱ��ʾһԪ��,��Ԫ��,��Ԫ�ߡ�
����˼��,һԪ����������Ϊһ����ֻ����һ������,��Ԫ������Ϊһ����������������(����),��Ԫ������Ϊһ���߿������Ӷ��(3������)���㡣
������Ķ�Ԫ��Ϊ������һ�����ǵIJ���:D, E, VertexXi, VertexXj:
- D �� int ��,��ʾ����ֵ��ά�� (dimension)
- E ��ʾ����ֵ����������
- VertexXi,VertexXj �ֱ��ʾ��ͬ���������
BaseBinaryEdge<2, Vector2D, VertexSBAPointXYZ, VertexSE3Expmap>
? �������д����ʾ��Ԫ��,����1��˵����ֵ��2ά��;����2��Ӧ����ֵ��������Vector2D,����3��4��ʾ��������Ҳ�����Ż������ֱ�����ά�� VertexSBAPointXYZ,����Ⱥλ��VertexSE3Expmap��
�����ıߵ�����
g2o::EdgeSE3ProjectXYZOnlyPose // һԪ��
g2o::EdgeProjectXYZ2UV* // ��Ԫ��
g2o::EdgeSE3ProjectXYZ* // �����ڲ�k:fx cx�ȱ���
����ֶ�����һ����
�����������ж������,��Ҫ��дһЩ��Ҫ�ij�Ա����:
virtual bool read(std::istream& is);
virtual bool write(std::ostream& os) const;// �ֱ��Ƕ��̡����̺���,һ������²���Ҫ���ж�/д�����Ļ�,��������һ�¾Ϳ���virtual
void computeError();// �dz���Ҫ,��ʹ�õ�ǰ����ֵ����IJ���ֵ����ʵ����ֵ֮������
virtual void linearizeOplus();// �dz���Ҫ,���ڵ�ǰ�����ֵ��,�������Ż�������ƫ����,Ҳ����Jacobian����
���������ĸ�����,���м�����Ҫ�ij�Ա�����Լ�����:
_measurement; // �洢�۲�ֵ
_error; // �洢computeError() ������������
_vertices[]; // �洢������Ϣ,�����Ԫ��,
_vertices[]��СΪ2//�洢˳��͵���setVertex(int, vertex) ���趨��int�й�(0��1)
setId(int); // ����ߵı��(��������H�����е�λ��)
setMeasurement(type); // ����۲�ֵ
setVertex(int, vertex); // ���嶥��
setInformation(); // ��������������
����������Щ��Ҫ�ij�Ա�����ͳ�Ա����,�Ϳ�����������һ����[һԪ����Ԫ����Ԫ]��:
class myEdge: public g2o::BaseBinaryEdge<errorDim, errorType, Vertex1Type, Vertex2Type>
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
myEdge(){}
virtual bool read(istream& in) {}
virtual bool write(ostream& out) const {}
virtual void computeError() override
{
// ... _error = _measurement - Something;
}
virtual void linearizeOplus() override { // �������Ż�������ƫ����,�ſ˱Ⱦ���
_jacobianOplusXi(pos, pos) = something;
// ...
_jocobianOplusXj(pos, pos) = something;
}
private:
data
}
/*********************eg1 ��дһԪ�� ICP**********************/
/// g2o edge
class EdgeProjectXYZRGBDPoseOnly : public g2o::BaseUnaryEdge<3, Eigen::Vector3d, VertexPose> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
EdgeProjectXYZRGBDPoseOnly(const Eigen::Vector3d &point) : _point(point) {}
virtual void computeError() override {
const VertexPose *pose = static_cast<const VertexPose *> ( _vertices[0] );
_error = _measurement - pose->estimate() * _point;
}
virtual void linearizeOplus() override {
VertexPose *pose = static_cast<VertexPose *>(_vertices[0]);
Sophus::SE3d T = pose->estimate();
Eigen::Vector3d xyz_trans = T * _point;
_jacobianOplusXi.block<3, 3>(0, 0) = -Eigen::Matrix3d::Identity();
_jacobianOplusXi.block<3, 3>(0, 3) = Sophus::SO3d::hat(xyz_trans);
}
bool read(istream &in) {}
bool write(ostream &out) const {}
protected:
Eigen::Vector3d _point;
};
/*****************eg1 ��д��Ԫ�� ICP����********************/
# define Jacobian_handle 1
/// g2o edge:new ��Ԫ��
class EdgeProjectXYZPose : public g2o::BaseBinaryEdge<3, Eigen::Vector3d, VertexPoint3 ,VertexPose> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
EdgeProjectXYZPose(){}
virtual void computeError() override {
const VertexPoint3 *point3 = static_cast<const VertexPoint3 *>(_vertices[0]);
const VertexPose *pose = static_cast<const VertexPose *>(_vertices[1]);
_error = _measurement - pose->estimate() * point3->estimate();
}
#if Jacobian_handle==1
// �ſ˱���,������g2o�Զ���
virtual void linearizeOplus() override {
VertexPoint3 *point3 = static_cast< VertexPoint3 *>(_vertices[0]);
VertexPose *pose = static_cast< VertexPose *>(_vertices[1]);
Eigen::Vector3d _point = point3->estimate();
Sophus::SE3d T = pose->estimate();
_jacobianOplusXi.block<3, 3>(0, 0) = -(T.matrix()).block<3, 3>(0, 0);
Eigen::Vector3d xyz_trans = T * _point;
_jacobianOplusXj.block<3, 3>(0, 0) = -Eigen::Matrix3d::Identity();
_jacobianOplusXj.block<3, 3>(0, 3) = Sophus::SO3d::hat(xyz_trans);
cout<<"Jacobian_handle==1 "<<endl;
}
#endif
bool read(istream &in) {}
bool write(ostream &out) const {}
protected:
// Eigen::Vector3d _point;
};
��ͼ�����ӱ�
�����ӵ���һ������,����������һԪ��:
// ��ͼ�����ӱ�
for ( int i=0; i<N; i++ )
{
CurveFittingEdge* edge = new CurveFittingEdge( x_data[i] );
edge->setId(i);
edge->setVertex( 0, v ); // �������ӵĶ���
edge->setMeasurement( y_data[i] ); // �۲���ֵ
edge->setInformation( Eigen::Matrix<double,1,1>::Identity()*1/(w_sigma*w_sigma) ); // ��Ϣ����:Э�������֮��
edge->setRobustKernel(new g2o::RobustKernelHuber);
optimizer.addEdge( edge );
/**************************************///[����]
for (size_t i = 0; i < points_2d.size(); ++i) // �۲ⷽ��
{
auto p3d = points_3d[i];
g2o::EdgeSE3ProjectXYZOnlyPose *edge = new g2o::EdgeSE3ProjectXYZOnlyPose();
edge->setId(i);
edge->setVertex(0,vertex_pose);
edge->setMeasurement(points_2d[i]);
edge->setInformation(Eigen::Matrix2d::Identity());
edge->Xw = p3d;
edge->fx = K.at<double>(0, 0);
edge->fy = K.at<double>(1, 1);
edge->cx = K.at<double>(0, 2);
edge->cy = K.at<double>(1, 2);
optimizer.addEdge(edge);
}
����SLAM�����Ǿ���Ҫʹ�õ���Ԫ��(ǰ������λ��),��ô��ʱ:
// ����Ԫ��: 2d�㡿
index = 1;
for ( const Point2f p:points_2d ){
g2o::EdgeProjectXYZ2UV* edge = new g2o::EdgeProjectXYZ2UV();
edge->setId ( index ); // �ߵ�b���
edge->setVertex ( 0, dynamic_cast<g2o::VertexSBAPointXYZ*> ( optimizer.vertex ( index ) ) );
edge->setVertex ( 1, pose );
edge->setMeasurement ( Eigen::Vector2d ( p.x, p.y ) ); // ���ù۲��������ͼ������
edge->setParameterId ( 0,0 );
edge->setInformation ( Eigen::Matrix2d::Identity() );
edge->setRobustKernel(new g2o::RobustKernelHuber);
optimizer.addEdge ( edge );
index++;
//��6�� ��������ڲ� [����IJ���]
edge->fx = fx; // ����Ԫ���õ��ĸ�������
edge->fy = fy;
edge->cx = cx;
edge->cy = cy;
}
/**************/ // ����Ԫ�� 3d�� ��
g2o::EdgeStereoSE3ProjectXYZ *edge = new g2o::EdgeStereoSE3ProjectXYZ();
**1.3.6 �����Ż�����,��ʼִ���Ż� **
����SparseOptimizer�ij�ʼ���������������������ȡ�
��ʼ��
SparseOptimizer::initializeOptimization(HyperGraph::EdgeSet& eset)
���õ�������,Ȼ��Ϳ�ʼִ��ͼ�Ż��ˡ�
SparseOptimizer::optimize(int iterations, bool online)
һ����Ԫ�ߵ�����:
/**
* BA Example
* Author: Xiang Gao
* Date: 2016.3
* Email: gaoxiang12@mails.tsinghua.edu.cn
*
* �����������,���Ƕ�ȡ����ͼ��,��������ƥ�䡣Ȼ�����ƥ��õ�������,��������˶��Լ��������λ�á�����һ�����͵�Bundle Adjustment,������g2o�����Ż���
*/
// for std
#include <iostream>
// for opencv
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <boost/concept_check.hpp>
// for g2o
#include <g2o/core/sparse_optimizer.h>
#include <g2o/core/block_solver.h>
#include <g2o/core/robust_kernel.h>
#include <g2o/core/robust_kernel_impl.h>
#include <g2o/core/optimization_algorithm_levenberg.h>
#include <g2o/solvers/cholmod/linear_solver_cholmod.h>
#include <g2o/types/slam3d/se3quat.h>
#include <g2o/types/sba/types_six_dof_expmap.h>
using namespace std;
// Ѱ������ͼ���еĶ�Ӧ��,��������ϵ
// ����:img1, img2 ����ͼ��
// ���:points1, points2, �����Ӧ��2D��
int findCorrespondingPoints( const cv::Mat& img1, const cv::Mat& img2, vector<cv::Point2f>& points1, vector<cv::Point2f>& points2 );
// ����ڲ�
double cx = 325.5;
double cy = 253.5;
double fx = 518.0;
double fy = 519.0;
int main( int argc, char** argv )
{
// ���ø�ʽ:���� [��һ��ͼ] [�ڶ���ͼ]
if (argc != 3)
{
cout<<"Usage: ba_example img1, img2"<<endl;
exit(1);
}
// ��ȡͼ��
cv::Mat img1 = cv::imread( argv[1] );
cv::Mat img2 = cv::imread( argv[2] );
// �ҵ���Ӧ��
vector<cv::Point2f> pts1, pts2;
if ( findCorrespondingPoints( img1, img2, pts1, pts2 ) == false )
{
cout<<"ƥ��㲻��!"<<endl;
return 0;
}
cout<<"�ҵ���"<<pts1.size()<<"���Ӧ�����㡣"<<endl;
// ����g2o�е�ͼ
// �ȹ��������
g2o::SparseOptimizer optimizer;
// ʹ��Cholmod�е����Է��������
g2o::BlockSolver_6_3::LinearSolverType* linearSolver = new g2o::LinearSolverCholmod<g2o::BlockSolver_6_3::PoseMatrixType> ();
// 6*3 �IJ���
g2o::BlockSolver_6_3* block_solver = new g2o::BlockSolver_6_3( linearSolver );
// L-M �½�
g2o::OptimizationAlgorithmLevenberg* algorithm = new g2o::OptimizationAlgorithmLevenberg( block_solver );
optimizer.setAlgorithm( algorithm );
optimizer.setVerbose( false );
// ���ӽڵ�
// ����λ�˽ڵ�
for ( int i=0; i<2; i++ )
{
g2o::VertexSE3Expmap* v = new g2o::VertexSE3Expmap();
v->setId(i);
if ( i == 0)
v->setFixed( true ); // ��һ����̶�Ϊ��
// Ԥ��ֵΪ��λPose,��Ϊ���Dz�֪���κ���Ϣ
v->setEstimate( g2o::SE3Quat() );
optimizer.addVertex( v );
}
// �ܶ��������Ľڵ�
// �Ե�һ֡Ϊ
for ( size_t i=0; i<pts1.size(); i++ )
{
g2o::VertexSBAPointXYZ* v = new g2o::VertexSBAPointXYZ();
v->setId( 2 + i );
// ������Ȳ�֪��,ֻ�ܰ��������Ϊ1��
double z = 1;
double x = ( pts1[i].x - cx ) * z / fx;
double y = ( pts1[i].y - cy ) * z / fy;
v->setMarginalized(true);
v->setEstimate( Eigen::Vector3d(x,y,z) );
optimizer.addVertex( v );
}
// ���������
g2o::CameraParameters* camera = new g2o::CameraParameters( fx, Eigen::Vector2d(cx, cy), 0 );
camera->setId(0);
optimizer.addParameter( camera );
// ����
// ��һ֡
vector<g2o::EdgeProjectXYZ2UV*> edges;
for ( size_t i=0; i<pts1.size(); i++ )
{
g2o::EdgeProjectXYZ2UV* edge = new g2o::EdgeProjectXYZ2UV();
edge->setVertex( 0, dynamic_cast<g2o::VertexSBAPointXYZ*> (optimizer.vertex(i+2)) );
edge->setVertex( 1, dynamic_cast<g2o::VertexSE3Expmap*> (optimizer.vertex(0)) );
edge->setMeasurement( Eigen::Vector2d(pts1[i].x, pts1[i].y ) );
edge->setInformation( Eigen::Matrix2d::Identity() );
edge->setParameterId(0, 0);
// �˺���
edge->setRobustKernel( new g2o::RobustKernelHuber() );
optimizer.addEdge( edge );
edges.push_back(edge);
}
// �ڶ�֡
for ( size_t i=0; i<pts2.size(); i++ )
{
g2o::EdgeProjectXYZ2UV* edge = new g2o::EdgeProjectXYZ2UV();
edge->setVertex( 0, dynamic_cast<g2o::VertexSBAPointXYZ*> (optimizer.vertex(i+2)) );
edge->setVertex( 1, dynamic_cast<g2o::VertexSE3Expmap*> (optimizer.vertex(1)) );
edge->setMeasurement( Eigen::Vector2d(pts2[i].x, pts2[i].y ) );
edge->setInformation( Eigen::Matrix2d::Identity() );
edge->setParameterId(0,0);
// �˺���
edge->setRobustKernel( new g2o::RobustKernelHuber() );
optimizer.addEdge( edge );
edges.push_back(edge);
}
cout<<"��ʼ�Ż�"<<endl;
optimizer.setVerbose(true);
optimizer.initializeOptimization();
optimizer.optimize(10);
cout<<"�Ż����"<<endl;
//���DZȽϹ�����֮֡��ı任����
g2o::VertexSE3Expmap* v = dynamic_cast<g2o::VertexSE3Expmap*>( optimizer.vertex(1) );
Eigen::Isometry3d pose = v->estimate();
cout<<"Pose="<<endl<<pose.matrix()<<endl;
// �Լ������������λ��
for ( size_t i=0; i<pts1.size(); i++ )
{
g2o::VertexSBAPointXYZ* v = dynamic_cast<g2o::VertexSBAPointXYZ*> (optimizer.vertex(i+2));
cout<<"vertex id "<<i+2<<", pos = ";
Eigen::Vector3d pos = v->estimate();
cout<<pos(0)<<","<<pos(1)<<","<<pos(2)<<endl;
}
// ����inlier�ĸ���
int inliers = 0;
for ( auto e:edges )
{
e->computeError();
// chi2 ���� error*\Omega*error, ���������ܴ�,˵���˱ߵ�ֵ�������ߺܲ����
if ( e->chi2() > 1 )
{
cout<<"error = "<<e->chi2()<<endl;
}
else
{
inliers++;
}
}
cout<<"inliers in total points: "<<inliers<<"/"<<pts1.size()+pts2.size()<<endl;
optimizer.save("ba.g2o");
return 0;
}
int findCorrespondingPoints( const cv::Mat& img1, const cv::Mat& img2, vector<cv::Point2f>& points1, vector<cv::Point2f>& points2 )
{
cv::ORB orb;
vector<cv::KeyPoint> kp1, kp2;
cv::Mat desp1, desp2;
orb( img1, cv::Mat(), kp1, desp1 );
orb( img2, cv::Mat(), kp2, desp2 );
cout<<"�ֱ��ҵ���"<<kp1.size()<<"��"<<kp2.size()<<"��������"<<endl;
cv::Ptr<cv::DescriptorMatcher> matcher = cv::DescriptorMatcher::create( "BruteForce-Hamming");
double knn_match_ratio=0.8;
vector< vector<cv::DMatch> > matches_knn;
matcher->knnMatch( desp1, desp2, matches_knn, 2 );
vector< cv::DMatch > matches;
for ( size_t i=0; i<matches_knn.size(); i++ )
{
if (matches_knn[i][0].distance < knn_match_ratio * matches_knn[i][1].distance )
matches.push_back( matches_knn[i][0] );
}
if (matches.size() <= 20) //ƥ���̫��
return false;
for ( auto m:matches )
{
points1.push_back( kp1[m.queryIdx].pt );
points2.push_back( kp2[m.trainIdx].pt );
}
return true;
}
{����}�������ά&��άת��
g2o::SE3Quat SE2ToSE3(const g2o::SE2& _se2)
{
SE3Quat ret;
ret.setTranslation(Eigen::Vector3d(_se2.translation()(0), _se2.translation()(1), 0));
ret.setRotation(Eigen::Quaterniond(AngleAxisd(_se2.rotation().angle(), Vector3d::UnitZ())));
return ret;
}
g2o::SE2 SE3ToSE2(const SE3Quat &_se3)
{
Eigen::Vector3d eulers = g2o::internal::toEuler(_se3.rotation().matrix());
return g2o::SE2(_se3.translation()(0), _se3.translation()(1), eulers(2));
}
2.Ceres
? ������Ceres�������ڼ���SLAM��V-SLAM���Ż��о����Ŵ�����Ӧ�á��������ߴ�Ceres��Ϊ����,������дSLAM����ͷ,�������λ�����Ŀ�����
? ĿǰBundle Adjustment �䱾�ʻ����벻����С����ԭ��(���������Ż������䱾�ʶ�����С����),ĿǰBundle Adjustment �Ż������Ϊ��������Ceres solver��G2O(������Ҫ����ceres solver)��
? Ceres�е��Ż���Ҫ�IJ�,�����Ż��IJв��,�����Ż�����,��ÿ�λ�ȡ�����ݺ����Ӳв��,�����Ż���
��Ceres: ����: exp(ax^2+bx+c) ��
����������:
AddParameterBlock - ���Ӳ�����
AddResidualBlock - �Զ���ģ�������������͵ȡ�
���������:ѡ���ܼ�����cholesky
ceres::Solve(options, &problem, &summary); ִ���Ż�
// ****************������******************
// ���ۺ����ļ���ģ�� :f(x) = e || ��1.����в�����/�ṹ�塿
struct CURVE_FITTING_COST {
CURVE_FITTING_COST(double x, double y) : _x(x), _y(y) {}
// �в�ļ���
template<typename T>
bool operator()(
const T *const abc, // ģ�Ͳ���,��3ά
T *residual) const {
residual[0] = T(_y) - ceres::exp(abc[0] * T(_x) * T(_x) + abc[1] * T(_x) + abc[2]); // y-exp(ax^2+bx+c)
return true;
}
const double _x, _y; // x,y����
};
// ****************NO.1******************
double abc[3] = {ae, be, ce};
// ��������������
ceres::Problem problem;
for (int i = 0; i < N; i++) { //����Ҫ����:����-ǰ�õ�����
problem.AddResidualBlock( // �����������������
// ʹ���Զ���,ģ�����:��������͡�,���ά��,����ά��,ά��Ҫ��ǰ��struct��һ��
new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3>(
new CURVE_FITTING_COST(x_data[i], y_data[i]) // ���ۺ��� f(x) = e || ������()�����,���ۺ������
),
nullptr, // �˺���,���ﲻʹ��,Ϊ��
abc // �����Ʋ��� || ������
);
}
// ****************NO.2******************
ceres::Solver::Options options; // �����кܶ������������
options.linear_solver_type = ceres::DENSE_NORMAL_CHOLESKY; // �ܼ�����cholesky||��������������
options.minimizer_progress_to_stdout = true; // �����cout
// ****************NO.3******************
ceres::Solver::Summary summary; // �Ż���Ϣ
ceres::Solve(options, &problem, &summary); // ��ʼ�Ż� || ����-��С��������-�Ż���Ϣ
// ������
cout << summary.BriefReport() << endl;
cout << "estimated a,b,c = ";
for (auto a:abc) cout << a << " ";
cout << endl;
�C1.1.������
//�������ۺ����ṹ��,residual Ϊ�в
//last_point_a_Ϊ��һ֡�еĵ�a,curr_point_b_Ϊ��a��ת�����һ֡������ĵ�
//curr_point_c_Ϊ��bͬ�����ߺŵĵ�,curr_point_d_Ϊ��b���ߺŵĵ�
//b,c,d��a����벻����3m
//plane_normΪ��������bc��bd����ķ�����
struct CURVE_FITTING_COST
{
//���ƹ��캯��
CURVE_FITTING_COST(Eigen::Vector3d _curr_point_a_, Eigen::Vector3d _last_point_b_,
Eigen::Vector3d _last_point_c_, Eigen::Vector3d _last_point_d_):
curr_point_a_(_curr_point_a_),last_point_b_(_last_point_b_),
last_point_c_(_last_point_c_),last_point_d_(_last_point_d_)
{
plane_norm = (last_point_d_ - last_point_b_).cross(last_point_c_ - last_point_b_);
plane_norm.normalize();
}
template <typename T>
//plane_norm�������abΪa�����bcd�ľ���,���в�
bool operator()(const T* q,const T* t,T* residual)const
{
Eigen::Matrix<T, 3, 1> p_a_curr{T(curr_point_a_.x()), T(curr_point_a_.y()), T(curr_point_a_.z())};
Eigen::Matrix<T, 3, 1> p_b_last{T(last_point_b_.x()), T(last_point_b_.y()), T(last_point_b_.z())};
Eigen::Quaternion<T> rot_q{q[3], q[0], q[1], q[2]};
Eigen::Matrix<T, 3, 1> rot_t{t[0], t[1], t[2]};
Eigen::Matrix<T, 3, 1> p_a_last;
p_a_last=rot_q * p_a_curr + rot_t;
residual[0]=abs((p_a_last - p_b_last).dot(plane_norm));
return true;
}
const Eigen::Vector3d curr_point_a_,last_point_b_,last_point_c_,last_point_d_;
Eigen::Vector3d plane_norm;
};
�C1.2. �����Ż�����
//�Ż������
ceres::LossFunction *loss_function = new ceres::HuberLoss(0.1);
ceres::LocalParameterization *q_parameterization = new ceres::EigenQuaternionParameterization();
ceres::Problem::Options problem_options;
ceres::Problem problem(problem_options);
problem.AddParameterBlock(para_q, 4, q_parameterization);
problem.AddParameterBlock(para_t, 3);
ÿ�����abcd���,�����ǵ����깹����Eigen::Vector3d����,���Ӳв��:
Eigen::Vector3d curr_point_a(laserCloudIn_plane.points[i].x,
laserCloudIn_plane.points[i].y,
laserCloudIn_plane.points[i].z);
Eigen::Vector3d last_point_b(laserCloudIn_plane_last.points[closestPointInd].x,laserCloudIn_plane_last.points[closestPointInd].y,laserCloudIn_plane_last.points[closestPointInd].z);
Eigen::Vector3d last_point_c(laserCloudIn_plane_last.points[minPointInd2].x,
laserCloudIn_plane_last.points[minPointInd2].y,
laserCloudIn_plane_last.points[minPointInd2].z);
Eigen::Vector3d last_point_d(laserCloudIn_plane_last.points[minPointInd3].x,
laserCloudIn_plane_last.points[minPointInd3].y,
laserCloudIn_plane_last.points[minPointInd3].z);
problem.AddResidualBlock(new ceres::AutoDiffCostFunction<CURVE_FITTING_COST,1,4,3>
(new CURVE_FITTING_COST(last_point_a,curr_point_b,
curr_point_c,curr_point_d)),loss_function,para_q,para_t);
���������е�a���,�Ϳ����Ż�����ˡ�
//����ǰһ֡��ĵ㶼��a���������,�����Ż�
ceres::Solver::Options options;
options.linear_solver_type = ceres::DENSE_QR;
//������
options.max_num_iterations = 5;
//�����Ƿ�STDOUT
options.minimizer_progress_to_stdout = false;
ceres::Solver::Summary summary;
ceres::Solve(options, &problem, &summary);
����V-SLAM��Ceres���õĸ���,���ǿ��Կ������������
double para_Pose[7];
para_Pose[0] = 0.0;
para_Pose[1] = 0.0;
para_Pose[2] = 0.0;
para_Pose[6] = 1.0;
para_Pose[3] = 0.0;
para_Pose[4] = 0.0;
para_Pose[5] = 0.0;
int kNumObservations = cur_pts.size();
double invDepth[kNumObservations][1];
ceres::LossFunction *loss_function;
//loss_function = new ceres::HuberLoss(1.0);
loss_function = new ceres::CauchyLoss(1.0);// �����˺���
ceres::LocalParameterization *local_parameterizationP = new PoseLocalParameterization();
problem.AddParameterBlock(para_Pose, 7, local_parameterizationP);//��Pose���²�����
for (int i = 0; i < kNumObservations; ++i) {
invDepth[i][0] = 1;
problem.AddParameterBlock(invDepth[i], 1); //��������²�����
if (!invdepths.empty()&&invdepths[i]>0){
// cout << "depth observations "<< 1./invdepths[i] <<" "<< invdepths[i] <<endl;
invDepth[i][0] = invdepths[i];
problem.SetParameterBlockConstant(invDepth[i]);//���κβ�������Ϊ����,����ʹ��SetParameterBlockVariable()��������һ����
ceres::CostFunction *f_d;
//�Զ�����,AutoDiffCostFunction
f_d = new ceres::AutoDiffCostFunction<autoIvDepthFactor, 1,1>(
new autoIvDepthFactor(invdepths[i]) );
problem.AddResidualBlock(f_d, loss_function, invDepth[i]);
}
ceres::CostFunction *f;
f = new ceres::AutoDiffCostFunction<autoMonoFactor, 3,7,1>(
new autoMonoFactor(Vector3d(un_prev_pts[i].x, un_prev_pts[i].y, 1),Vector3d(un_cur_pts[i].x, un_cur_pts[i].y, 1)) );
problem.AddResidualBlock(f, loss_function, para_Pose,invDepth[i]);
}
ceres::Solver::Options options;
// options.max_num_iterations = 7;
options.linear_solver_type = ceres::DENSE_SCHUR;
options.trust_region_strategy_type = ceres::DOGLEG;
options.minimizer_progress_to_stdout = false;
ceres::Solver::Summary summary;
TicToc solveTime;
ceres::Solve(options, &problem, &summary);
2.Ceres ���������ܽ�
�C2.1 �����Ż���������ʧ�˺���
? ���ڴ��������к���Ұֵ�����,�����������Թ��Ƶ�Ӱ��,���ò�������HuberLoss��CauchyLoss��;�ò�������ȡNULL��nullptr,��ʱ��ʧ����Ϊ��λ������
ceres::Problem problem;
ceres::LossFunction *loss_function; // ��ʧ�˺���
//loss_function = new ceres::HuberLoss(1.0); //huber�˺���
loss_function = new ceres::CauchyLoss(1.0); // �����˺���
�C2.2 ��problem�����Ӳ�����- AddParameterBlock���ع���
? (�ú������õ�����������)�û��ڵ��� AddResidualBlock( ) ʱ��ʵ�Ѿ���ʽ����Problem�����˲���ģ��,����һЩ�����,��Ҫ�û���ʽ����Problem�������ģ��(ͨ����������Ҫ���Ż������������²����������)��Ceres�ṩ��**Problem::AddParameterBlock( )**���������û���ʽ���ݲ���ģ��:
void AddParameterBlock(double* values, int size);
void AddParameterBlock(double* values,
int size,
LocalParameterization* local_parameterization);
ע:
values��ʾ�Ż�����,size��ʾ�Ż�������ά�ȡ�
����,��һ�ֺ���ԭ�ͳ��˻�����һЩ����IJ������֮��,�����Ϻ���ʽ���ݲ�����û��̫�����𡣵ڶ��ֺ���ԭ���������LocalParameterization����,�����ع��Ż�������ά����
LocalParameterization�����Ż�Manifold(����)�ϵı���ʱ��Ҫ���ǵ�,Manifold�ϱ����ǹ�������,��Manifold�ϱ�����ά�ȴ��������ɶȡ���ᵼ��Manifold�ϱ���������֮�����Լ��,���ֱ�Ӷ���Щ�����Ż�,��ô�����һ����Լ�����Ż�,ʵ�����ѡ�Ϊ�˽���������,����ѧ�϶�Manifold�ڵ�ǰ����ֵ���γɵ��пռ���,���пռ����Ż�,���ͶӰ��Manifold������ֹ������ά�� > �����ɶȰ���
����SLAM����,�㷺������Manifold����ת,��ת����Ҫ3����,��ʵ���������漰������������,�ڸ���ά�ռ������ת,��Ԫ��������ά��4����3�����ɶȵ���ά�ռ����ת��
�����û�к����⡿bool ComputeJacobian()����õ�һ��4*3�ľ���(global_to_local),������Manifold�ϱ�����Tangent Space�ϱ����ĵ���,��ceres::CostFunction���ṩresiduals��Manifold�ϱ����ĵ���,�����������,֮���ͱ���˶�Tangent Space�ϱ����ĵ�����
//�汾1.0 : q t�ֿ�����, ����Ceres�Ŀ�,����Ҫ�ع�
double para_q[4] = {0,0,0,1};
double para_t[3] = {0,0,0};
ceres::LocalParameterization *q_parameterization = new ceres::EigenQuaternionParameterization();
problem.AddParameterBlock(para_q, 4, q_parameterization);
problem.AddParameterBlock(para_t, 3);
/ �����ǵ��� || �������ع�se3
// �汾2.0: se3 ���� q t �ֿ��� || ��д�ſ˱�
double parameters[7] = {0,0,0,1,0,0,0};
problem.AddParameterBlock(parameters, 7, new PoseSE3Parameterization());
----2.2 �����䡿:
LocalParameterization��������ǽ���������Ż��е������������⡣��ν��������,�����Ż�������ʵ�����ɶ�С�ڲ������������ɶȡ�������SLAM��,��������Ԫ����ʾλ��ʱ,������Ԫ��������Լ��(ģ��Ϊ1),ʵ�ʵ����ɶ�Ϊ3����4����ʱ,��ֱ�Ӵ�����Ԫ�������Ż�,�����ά�������������Դ���˷�,��Ҫʹ��CeresԤ�ȶ����QuaternionParameterization���Ż����������ع�:
problem.AddParameterBlock(quaternion, 4);// ֱ�Ӵ���4ά����
// QuaternionParameterization �̳��� LocalParameterization
ceres::LocalParameterization* local_param = new ceres::QuaternionParameterization(); // EigenQuaternionParameterization
problem.AddParameterBlock(quaternion, 4, local_param)//�ع�����,�Ż�ʱʵ��ʹ�õ���3ά�ĵ�Ч��תʸ��
��Ԫ����ʹ������:
��Ԫ����ʾ����һ��SO3,��Ԫ����ʾ�����������һ�����������ɶȵĶ���,Ȼ����Ԫ��ȴ����άҲ�����ĸ����ɶ�,����Ȼ�Dz�������,����Ҳ�Ͳ�����һ����λ��Ԫ����ôһ������,��λ��Ԫ������˼�� ����˵��Ԫ�����ĸ����Ķ�������1.�����ʵ��һ��Լ��,���Լ����Լ������Ԫ����һ�����ɶ�,������ʵ��Ԫ����ֻʣ���������ɶ������÷���һ��SO3��ά����
Ȼ����ceres����,���ʹ�õ����Զ���,Ȼ���ٽ����ɽ��,��ôÿ�������ж������һ����ά��delta(����������,�ο�LM���㷨),��ô���ݳ������ɽ��,�����ͽ�����Ҫ�� ԭ��Ԫ�������ϡ��������������delta���ܹ��õ��µ���Ԫ����,�������������,ֱ�Ӽ����Ժ������Ԫ���Ͳ�����һ����λ��Ԫ����,��û��������,����ǵ���ô�õĻ��͵�ÿ�ε������������Ԫ������һ����һ��������
�������:
������Ԫ��������ת��������ʹ�ù���������ʾ��ת�ķ�ʽ,������**��֧�ֹ���ļӷ�**(��Ϊʹ����ͨ�ļӷ��ͻ������ constraint,������ת�������ת����õ��ľͲ�������ת����),����������ʹ��ceres�������
�������µ�ʱ�����Ҫ�Զ�������·�ʽ��,�����������ʵ��һ��**�������ػ�**������,��Ҫ�̳���`LocalParameterization`,`LocalParameterization`�Ǵ�����,�������Ǽ̳е�ʱ��Ҫ�����еĴ��麯����ʵ��һ�����ʹ�ø������ɶ���.
���˲�֧�ֹ���ӷ�Ҫ�Զ���������ػ���������,�����Ҫ���Ż�������һЩ����Ҳ�����編����,����ceres��slam2d example�жԽǶȷ�Χ����������.
**�Զ��� LocalParameterization **
LocalParameterization������һ�������,��ϸ�������¡��û��������ж����Լ���Ҫʹ�õ�����,��ʹ��CeresԤ�ȶ���õ����ࡣ
class LocalParameterization {
public:
virtual ~LocalParameterization() {}
//
virtual bool Plus(const double* x,
const double* delta,
double* x_plus_delta) const = 0;//�������пռ��ϵĸ��º���
virtual bool ComputeJacobian(const double* x, double* jacobian) const = 0; //�ſ˱Ⱦ���
virtual bool MultiplyByJacobian(const double* x,
const int num_rows,
const double* global_matrix,
double* local_matrix) const;//һ�㲻��
virtual int GlobalSize() const = 0; // ������ʵ��ά��
virtual int LocalSize() const = 0; // ���пռ��ϵIJ���ά��
};
������Ա������,��Ҫ���Ǹ�д����ҪΪ
Plus(const double* x,const double* delta,double* x_plus_delta):��������ļӷ�(����ο���������)ComputeJacobian():x��delta���ſ˱Ⱦ���GlobalSize():�����ʵ�ʲ�����ά��LocalSize():����ʵ�ʵ�ά��(���ɶ�)
����:QuaternionParameterization����
����������ceresԤ�ȶ���õ�QuaternionParameterizationΪ������˵��LocalParameterization�÷�,����������:
ע�⡣
�� ceres Դ����û����ȷ˵��֮������Ϊ���� raw memory �洢��ʽ�� Row Major ��,���� Eigen Ĭ�ϵ� Col Major ���෴�ġ�
ceres Ĭ�ϵ� Quaternion raw memory �洢��ʽ�� w, x, y, z,�� Eigen Quaternion �Ĵ洢��ʽ�� x, y, z, w,��͵����� ceres �����г�
ceres::QuaternionParameterization֮���ceres::EigenQuaternionParameterization��Eigen Quaternionָ����eigen���еĺ���
Eigen::Quaternion(w,x,y,z)������,ʵ��w����;����ʵ���������ڲ��洢˳����[x y z w],������ʵ�ʱ�����һ��Ԫ�ز���w�����������ڲ��洢˳���ܽ�
ceres::QuaternionParameterization:�ڲ��洢˳��Ϊ(w,x,y,z)
ceres::EigenQuaternionParameterization:�ڲ��洢˳��Ϊ(x,y,z,w)
Eigen::Quaternion(w,x,y,z):�ڲ��洢˳��Ϊ(x,y,z,w)(�빹�캯��û�б���һ��)ceres �� Quaternion �� Hamilton Quaternion,��ѭ Hamilton �˷�����
class CERES_EXPORT QuaternionParameterization : public LocalParameterization {
public:
virtual ~QuaternionParameterization() {}
//���ص�Plus������������Ԫ���ĸ��·���,���ܲ����ֱ�Ϊ�Ż�ǰ����Ԫ����x��,����תʸ����ʾ��������delta��,�Լ����º����Ԫ����x_plus_delta����
//�������Ƚ�������delta������תʸ��ת��Ϊ��Ԫ��,�����ñ���Ԫ���˷�����Ԫ�����и��¡�
virtual bool Plus(const double* x,
const double* delta,
double* x_plus_delta) const;
virtual bool ComputeJacobian(const double* x,
double* jacobian) const;
//GlobalSize ����ֵΪ4,����Ԫ��������ʵ��ά�����������ڲ��Ż�ʱ,ceres���õ�����תʸ��,ά��Ϊ3,���LocalSize()�ķ���ֵΪ3��
//GlobalSize ���DZ�ʾ��������ά����һ��4ά�� || �������q+t=7��
virtual int GlobalSize() const { return 4; }
//LocalSize�Ǹ���Ceres����ʾ�Ķ�����һ����ά�� ||�������q+t=6��
virtual int LocalSize() const { return 3; }
};
//============================================================================= [ʵ���Ĵ���]
virtual bool Plus(const double *x,
const double *delta,
double *x_plus_delta) const //�������пռ��ϵĸ��º���
{
// Eigen::Map<const Eigen::Quaterniond> quater(x); // �����µ���Ԫ��
// Eigen::Map<const Eigen::Vector3d> delta_so3(delta); // delta ֵ,ʹ������ so3 ����
// Eigen::Quaterniond delta_quater = Sophus::SO3d::exp(delta_so3).unit_quaternion(); // so3 ת��λ delta_p ��Ԫ��
// Eigen::Map<Eigen::Quaterniond> quter_plus(x_plus_delta); // ���º����Ԫ��
// // ��ת���¹�ʽ
// quter_plus = (delta_quater * quater).normalized();
Eigen::Quaterniond delta_q;
getTransformFromSo3(Eigen::Map<const Eigen::Matrix<double, 3, 1>>(delta), delta_q); // ��F-LOAM�еġ�
Eigen::Map<const Eigen::Quaterniond> quater(x); // �Ż�ǰ����Ԫ��
Eigen::Map<Eigen::Quaterniond> quater_plus(x_plus_delta); // �Ż������Ԫ��
quater_plus = (delta_q * quater).normalize();
return true;
}
//=============================================================================���ٷ�-�ο��Ĵ��롿
//���ص�Plus������������Ԫ���ĸ��·���,���ܲ����ֱ�Ϊ�Ż�ǰ����Ԫ����x��,����תʸ����ʾ��������delta��,�Լ����º����Ԫ����x_plus_delta����
//�������Ƚ�������delta������תʸ��ת��Ϊ��Ԫ��,�����ñ���Ԫ���˷�����Ԫ�����и��¡�
bool QuaternionParameterization::Plus(const double* x,
const double* delta,
double* x_plus_delta) const {
// ����תʸ��ת��Ϊ��Ԫ����ʽ
const double norm_delta =
sqrt(delta[0] * delta[0] + delta[1] * delta[1] + delta[2] * delta[2]);
if (norm_delta > 0.0) {
const double sin_delta_by_delta = (sin(norm_delta) / norm_delta);
double q_delta[4];
q_delta[0] = cos(norm_delta);
q_delta[1] = sin_delta_by_delta * delta[0];
q_delta[2] = sin_delta_by_delta * delta[1];
q_delta[3] = sin_delta_by_delta * delta[2];
// ������Ԫ���˷�����
QuaternionProduct(q_delta, x, x_plus_delta);
} else {
for (int i = 0; i < 4; ++i) {
x_plus_delta[i] = x[i];
}
}
return true;
}
//=============================================================================
Plus()
ʵ�����Ż������ĸ���,��ʹ��GN���õ��� $ \Delta \tilde{\mathbf{x}}^{} ��x~ �� �� ԭ �� �� �� �� �� ����ԭ���Ż����� ����ԭ���������� x �� \check{\mathbf{x}} x��$,ʹ�õ��� ? ����ӷ������.
x $ = x ? �� �� x ~ ? \mathbf{x}^{}=\breve{\mathbf{x}} \oplus \Delta \tilde{\mathbf{x}}^{*} x?=x?����x~$
?�����,���Ƚ���Ԫ������������(����ת�������һ��ϵ��)���һ����������Ԫ��(������Ԫ����ָ��),���õ���������������,Ȼ������Ӧ�õ������Ʊ�����.
ComputeJacobian ������������Ԫ���������תʸ�����ſ˱Ⱦ�����㷽��, ��:
J 4 �� 3 = d q / d v = d [ q w , q x , q y , q z ] T / d [ [ x , y , z ] $\boldsymbol{J}{4 \times 3}=d \boldsymbol{q} / d \boldsymbol{v}=d\left[q{w}, q_{x}, q_{y}, q_{z}\right]^{T} / d[x, y, z] $
��ӦJacobianά��Ϊ4��3��,�洢��ʽΪ������

virtual bool ComputeJacobian(const double* x, double* jacobian) const // ��Ԫ����so3��ƫ����
{
// jacobian[0] = -x[1]; jacobian[1] = -x[2]; jacobian[2] = -x[3]; // NOLINT
// jacobian[3] = x[0]; jacobian[4] = x[3]; jacobian[5] = -x[2]; // NOLINT
// jacobian[6] = -x[3]; jacobian[7] = x[0]; jacobian[8] = x[1]; // NOLINT
// jacobian[9] = x[2]; jacobian[10] = -x[1]; jacobian[11] = x[0]; // NOLINT
Eigen::Map<Eigen::Matrix<double, 4, 3, Eigen::RowMajor>> j(jacobian); // �Ż������Ԫ��
(j.topRows(3)).setIdentity();
(j.bottomRows(1)).setZero();
return true;
}
���ӳ���-from F-LOAM
skew �� getTransformFromSe3
template <typename T>
Eigen::Matrix<T,3,3> skew(Eigen::Matrix<T,3,1>& mat_in){
Eigen::Matrix<T,3,3> skew_mat;
skew_mat.setZero();
skew_mat(0,1) = -mat_in(2);
skew_mat(0,2) = mat_in(1);
skew_mat(1,2) = -mat_in(0);
skew_mat(1,0) = mat_in(2);
skew_mat(2,0) = -mat_in(1);
skew_mat(2,1) = mat_in(0);
return skew_mat;
};
void getTransformFromSe3(const Eigen::Matrix<double,6,1>& se3, Eigen::Quaterniond& q, Eigen::Vector3d& t){
Eigen::Vector3d omega(se3.data());
Eigen::Vector3d upsilon(se3.data()+3);
Eigen::Matrix3d Omega = skew(omega);
double theta = omega.norm();
double half_theta = 0.5*theta;
double imag_factor;
double real_factor = cos(half_theta);
if(theta<1e-10)
{
double theta_sq = theta*theta;
double theta_po4 = theta_sq*theta_sq;
imag_factor = 0.5-0.0208333*theta_sq+0.000260417*theta_po4;
}
else
{
double sin_half_theta = sin(half_theta);
imag_factor = sin_half_theta/theta;
}
q = Eigen::Quaterniond(real_factor, imag_factor*omega.x(), imag_factor*omega.y(), imag_factor*omega.z());
Eigen::Matrix3d J;
if (theta<1e-10)
{
J = q.matrix();
}
else
{
Eigen::Matrix3d Omega2 = Omega*Omega;
J = (Eigen::Matrix3d::Identity() + (1-cos(theta))/(theta*theta)*Omega + (theta-sin(theta))/(pow(theta,3))*Omega2);
}
t = J*upsilon;
}
�C2.3 ���Ӳв��
? һ���Ż�������Կ���ͨ������������һ��Ѹ��ָ����IJв����С,���,�в���ṩ��������Ҫ��,һ���в�Ĺ����벻���в����ѧ�����Լ������IJ���,ceres���Ӳв��ͨ�� AddResidualBlock() ��� , ����������ò����Ϊ����
template <typename... Ts>
ResidualBlockId AddResidualBlock(CostFunction* cost_function, // �в�
LossFunction* loss_function, //��ʧ����-�˺���
double* x0, //���Ż����� - double || �в�������ı���
Ts*... xs)
ResidualBlockId AddResidualBlock(
CostFunction* cost_function,
LossFunction* loss_function,
const std::vector<double*>& parameter_blocks); // -vector����
? Ҳ������Ҫ�ṩ���ֲ��� ���� cost_function����³���˺������� �òв�Ĺ������� ��
���ۺ���:�����˲���ģ���ά����Ϣ,�ڲ�ʹ�÷º������������ļ��㷽ʽ��AddResidualBlock( )���������IJ���ģ���Ƿ�ʹ��ۺ���ģ���ж����ά��һ��,ά�Ȳ�һ��ʱ�����ǿ���˳������ۺ���ģ������μ�Ceres���(��) CostFunction��
��ʧ����:���ڴ��������к���Ұֵ�����,�����������Թ��Ƶ�Ӱ��,���ò�������HuberLoss��CauchyLoss��(�����IJ����б��μ�Ceres API�ĵ�);�ò�������ȡNULL��nullptr,��ʱ��ʧ����Ϊ��λ������
����ģ��:���Ż��IJ���,��һ���Դ�������������ָ������vector<double*>�����δ������в�����ָ��double*</double*>��
�����ص���cost_function����ĸ���,�������ֳ������ṩ��ʽ:
- �Զ�����(AutoDiffCostFunction):��ceres���о��������ļ��㷽ʽ,��õ���ʽ������ģ�廯�ɲ�����
template <typename CostFunctor,
int kNumResiduals, // Number of residuals, or ceres::DYNAMIC. || �в��ά��
int... Ns> // Size of each parameter block || ���������
class AutoDiffCostFunction : public
SizedCostFunction<kNumResiduals, Ns> {
public:
AutoDiffCostFunction(CostFunctor* functor, ownership = TAKE_OWNERSHIP);
// Ignore the template parameter kNumResiduals and use
// num_residuals instead.
AutoDiffCostFunction(CostFunctor* functor,
int num_residuals, // �в�num
ownership = TAKE_OWNERSHIP); //����size
};
- ��ֵ����(NumericDiffCostFunction):���û��ֶ���д��������ֵ�����ʽ,ͨ���ڲв���ļ���ʹ����ֱ�ӵ��ÿ⺯��,���µ���AutoDiffCostFunction���ʱʹ��;���ֶ���д�ľ��Ⱥͼ���Ч�ʲ���ģ����,��˲���������,�ٷ���������ʹ�ø÷�����
��ֵ�� NumericDiffCostFunction
template <typename CostFunctor,
NumericDiffMethodType method = CENTRAL,
int kNumResiduals, // Number of residuals, or ceres::DYNAMIC.
int... Ns> // Size of each parameter block.
class NumericDiffCostFunction : public
SizedCostFunction<kNumResiduals, Ns> {
};
��Ҫ����CostFunctor,��Ҫ����һ������operator()����в��(����)���ࡣ���ӱ��뽫����ֵд�����һ������(Ψһ�ķDz���const)������true��ָʾ�ɹ���
struct ScalarFunctor {
public:
bool operator()(const double* const x1, // ����в�
const double* const x2,
double* residuals) const;
}
//eg ����: e=k-x'y ; ����x��y�Ƕ�ά����������,Ʋ�ű�ʾת��,��k��һ��������
class MyScalarCostFunctor {
MyScalarCostFunctor(double k): k_(k) {}
bool operator()(const double* const x,
const double* const y,
double* residuals) const {
residuals[0] = k_ - x[0] * y[0] + x[1] * y[1];
return true;
}
private:
double k_;
};
��ע��,��operator()������� ��������, xandy�ȳ���,������Ϊ const ָ�봫�ݸ�doubles �����顣����������������,��ô����������������� ֮��y�����ʼ�������һ������,Ҳ��ָ�������ָ�롣�������������,�в���һ������,����ֻresiduals[0]�����ˡ�
CostFunction���ڼ��㵼���ľ������IJ�ֵ���ֵ�ֿ��Թ������¡�
CostFunction* cost_function
= new NumericDiffCostFunction<MyScalarCostFunctor, CENTRAL, 1, 2, 2>(
new MyScalarCostFunctor(1.0)); ^ ^ ^ ^
| | | |
Finite Differencing Scheme -+ | | |
Dimension of residual ------------+ | |
Dimension of x ----------------------+ |
Dimension of y -------------------------+
//eg ��Ӧ��������� || MyScalarCostFunctor�������ʵ������,, ֮���ģ����� ���º�������Ϊ��������ά��������һά�����1, 2, 2
CostFunction* cost_function
= new NumericDiffCostFunction<MyScalarCostFunctor, CENTRAL, DYNAMIC, 2, 2>(
new CostFunctorWithDynamicNumResiduals(1.0), ^ ^ ^
TAKE_OWNERSHIP, | | |
runtime_number_of_residuals); <----+ | | |
| | | |
| | | |
Actual number of residuals ------+ | | |
Indicate dynamic number of residuals --------------------+ | |
Dimension of x ------------------------------------------------+ |
Dimension of y ---------------------------------------------------+
������ֵ�ַ���:
-
��ַ�
FORWARD,������f��(x) ͨ������f(x+h)?f(x)h, �ټ���һ�γɱ�����x+h. ����������ȷ�ķ����� -
��ǰ�������,
CENTRAL��ַ�����ȷ,�����Ǻ�����������������,����f��(x)ͨ������ f(x+h)?f(x?h)2h. -
��ַ���[Ridders]_ ��һ������Ӧ����,��
RIDDERSͨ���ڲ�ͬ�߶���ִ�ж�����IJ�������Ƶ�����������˵,���㷨��ij���ض�λ�ÿ�ʼh�������ŵ����Ĺ���,���������С��Ϊ�˱��溯���������Ƶ������,�÷����ڲ��Բ���֮��ִ������ɭ���ơ����㷨���ֳ��൱�ߵ�ȷ��,��ͨ���Գɱ������Ķ���������������һ��������ʹ��
CENTRAL���쿪ʼ�����ݽ��,Ҫô����ǰ��������������,Ҫô���� Ridders �ķ��������ȷ�ԡ�
warnning: ����ʹ��ʱ,��ѧ�ߵ�һ����������
NumericDiffCostFunction�dzߴ�����ر���,�����ڽ�ģ���������Ϊ(�в��ά��,����������),������Ϊÿ����������һ��ά�Ȳ������������ʾ����,�⽫��,��ȱ�����һ�� ���������óߴ����ʱ��ע�⡣<MyScalarCostFunctor, 1, 2>``2
- ��������(AnalyticDerivatives):���������ڱպϽ�����ʽʱʹ��,���ڿɻ���CostFunciton�������б�д;��������Ҫ���й����в���ſ˱Ⱦ���,���DZպϽ���о������Եľ��Ⱥ�Ч������,����ͬ��������ʹ�á�
[����]ICP-slamʮ�Ľ� �Զ���ʵ��(q t �ֿ�)
/***********������ + ��**********/
//�汾1.0 : q t�ֿ�����, ����Ceres�Ŀ�,����Ҫ�ع�
double para_q[4] = {0,0,0,1};
double para_t[3] = {0,0,0};
ceres::LocalParameterization *q_parameterization = new ceres::EigenQuaternionParameterization();
problem.AddParameterBlock(para_q, 4, q_parameterization);
problem.AddParameterBlock(para_t, 3);
ceres::CostFunction *cost_function = VisualP3d_2d::Create(points_3d[i], points_2d[i], K_eigen);
problem.AddResidualBlock(cost_function, nullptr, para_q, para_t);
/***********�ṹ�� [ע��:��Ҫģ�庯��,�ڲ�ȫ��ģ���������]**********/
struct VisualP3d_2d
{
// �汾1.0: q t�ֿ�,�Զ���
VisualP3d_2d(Eigen::Vector3d p3d_, Eigen::Vector2d p2d_, Eigen::Matrix3d K_) : P3d(p3d_), P2d(p2d_), K(K_) {}
template <typename T>
bool operator()(const T *q, const T *t, T *residual) const
{
Eigen::Quaternion<T> para_q{q[3], q[0], q[1], q[2]};
Eigen::Matrix<T, 3, 1> para_t{t[0], t[1], t[2]};
Eigen::Matrix<T, 3, 1> TP3d{T(P3d[0]),T(P3d[1]),T(P3d[2])};
Eigen::Matrix<T, 3, 3> TK;
TK << T(K(0, 0)), T(K(0, 1)), T(K(0, 2)),
T(K(1, 0)), T(K(1, 1)), T(K(1, 2)),
T(K(2, 0)), T(K(2, 1)), T(K(2, 2));
Eigen::Matrix<T, 3, 1> p2d_p3d;
p2d_p3d = TK * (para_q * TP3d + para_t);
p2d_p3d /= p2d_p3d[2];
residual[0] = T(P2d[0]) - T(p2d_p3d(0)); //
residual[1] = T(P2d[1]) - T(p2d_p3d(1)); //
return true;
}
static ceres::CostFunction *Create(const Eigen::Vector3d p3d_,const Eigen::Vector2d p2d_,const Eigen::Matrix3d K_ ){
return (new ceres::AutoDiffCostFunction<VisualP3d_2d, 2,4,3>(
new VisualP3d_2d(p3d_, p2d_, K_)));
}
Eigen::Matrix3d K;
Eigen::Vector3d P3d;
Eigen::Vector2d P2d;
};
[����]����loam-livox ��ICP��ceres �Զ���ʵ��:
// p2p with motion deblur ��-�� ICP
template <typename _T>
struct ceres_icp_point2point_mb
{
Eigen::Matrix<_T, 3, 1> m_current_pt; // ��ǰ�ĵ�
Eigen::Matrix<_T, 3, 1> m_closest_pt; // ����ĵ�
_T m_motion_blur_s; // ���ڻ���ȥ��
// ��һ�α任
Eigen::Matrix<_T, 4, 1> m_q_last;
Eigen::Matrix<_T, 3, 1> m_t_last;
_T m_weigh;
ceres_icp_point2point_mb( const Eigen::Matrix<_T, 3, 1> current_pt,
const Eigen::Matrix<_T, 3, 1> closest_pt,
const _T &motion_blur_s = 1.0,
Eigen::Matrix<_T, 4, 1> q_s = Eigen::Matrix<_T, 4, 1>( 1, 0, 0, 0 ),
Eigen::Matrix<_T, 3, 1> t_s = Eigen::Matrix<_T, 3, 1>( 0, 0, 0 ) ) : m_current_pt( current_pt ),
m_closest_pt( closest_pt ),
m_motion_blur_s( motion_blur_s ),
m_q_last( q_s ),
m_t_last( t_s )
{
m_weigh = 1.0;
};
// operator() ���ؼ���в�,ͨ������IJ���,������
template <typename T>
bool operator()( const T *_q, const T *_t, T *residual ) const
{
// ��һ�εı任
Eigen::Quaternion<T> q_last{ ( T ) m_q_last( 0 ), ( T ) m_q_last( 1 ), ( T ) m_q_last( 2 ), ( T ) m_q_last( 3 ) };
Eigen::Matrix<T, 3, 1> t_last = m_t_last.template cast<T>();
// ����ȥ��
Eigen::Quaternion<T> q_incre{ _q[ 3 ], _q[ 0 ], _q[ 1 ], _q[ 2 ] };
Eigen::Matrix<T, 3, 1> t_incre{ _t[ 0 ], _t[ 1 ], _t[ 2 ] };
Eigen::Quaternion<T> q_interpolate = Eigen::Quaternion<T>::Identity().slerp( ( T ) m_motion_blur_s, q_incre );
Eigen::Matrix<T, 3, 1> t_interpolate = t_incre * T( m_motion_blur_s );
// ��ǰ�ĵ�
Eigen::Matrix<T, 3, 1> pt{ T( m_current_pt( 0 ) ), T( m_current_pt( 1 ) ), T( m_current_pt( 2 ) ) };
// ��ǰ�㾭���任���λ��
Eigen::Matrix<T, 3, 1> pt_transfromed;
pt_transfromed = q_last * ( q_interpolate * pt + t_interpolate ) + t_last;
residual[ 0 ] = ( pt_transfromed( 0 ) - T( m_closest_pt( 0 ) ) ) * T( m_weigh );
residual[ 1 ] = ( pt_transfromed( 1 ) - T( m_closest_pt( 1 ) ) ) * T( m_weigh );
residual[ 2 ] = ( pt_transfromed( 2 ) - T( m_closest_pt( 2 ) ) ) * T( m_weigh );
return true;
};
static ceres::CostFunction *Create( const Eigen::Matrix<_T, 3, 1> current_pt,
const Eigen::Matrix<_T, 3, 1> closest_pt,
const _T motion_blur_s = 1.0,
Eigen::Matrix<_T, 4, 1> q_s = Eigen::Matrix<_T, 4, 1>( 1, 0, 0, 0 ),
Eigen::Matrix<_T, 3, 1> t_s = Eigen::Matrix<_T, 3, 1>( 0, 0, 0 ) )
{
return ( new ceres::AutoDiffCostFunction< // �Զ���
ceres_icp_point2point_mb, 3, 4, 3>( // ��Ӧ����operator�е�ά��
new ceres_icp_point2point_mb( current_pt, closest_pt, motion_blur_s ) ) );
}
};
? �������ز�����()(����)������()��һ��ģ�巽��,����ֵΪbool��,���ܲ�������Ϊ���Ż������Ͳв����,�Ҵ��Ż������Ĵ��뷽ʽӦ��Problem::AddResidualBlock()һ�¡�
[����] ICPslamʮ�Ľ�������-se3(qt�ϳ�7ά):
ע��:����ſ˱ȵ�ʱ��,������F-LOAM���ع�,q��ǰ,t�ں� ; �Լ�q��˳������ȡ�
��Ҫ�������롣
/******************������ + ��*******************/
// �汾2.0: se3 ���� q t �ֿ��� || ��д�ſ˱�
double parameters[7] = {0,0,0,1,0,0,0};
problem.AddParameterBlock(parameters, 7, new PoseSE3Parameterization());
ceres::CostFunction *cost_function = new VisualP3d2d_hand(points_3d[i], points_2d[i], K_eigen);
problem.AddResidualBlock(cost_function, nullptr, parameters);
/******************������ + ��*******************/
class VisualP3d2d_hand : public ceres::SizedCostFunction<2, 7> {
public:
VisualP3d2d_hand(Eigen::Vector3d p3d_, Eigen::Vector2d p2d_, Eigen::Matrix3d K_) : P3d(p3d_), P2d(p2d_), K(K_) {}
virtual ~VisualP3d2d_hand() {}
virtual bool Evaluate(double const *const *parameters, double *residuals, double **jacobians) const{
Eigen::Map<const Eigen::Quaterniond> q(parameters[0]);
Eigen::Map<const Eigen::Vector3d> t(parameters[0] + 4);
Eigen::Vector3d p2d_p3d = q * P3d + t;
p2d_p3d = K * p2d_p3d;
p2d_p3d /= p2d_p3d[2];
residuals[0] = P2d[0] - p2d_p3d(0);
residuals[1] = P2d[1] - p2d_p3d(1);
if (jacobians != NULL)
{
if (jacobians[0] != NULL)
{
Eigen::Vector3d pos_cam = q * P3d + t;
double fx = K(0, 0);
double fy = K(1, 1);
double cx = K(0, 2);
double cy = K(1, 2);
double X = pos_cam[0];
double Y = pos_cam[1];
double Z = pos_cam[2];
double Z2 = Z * Z;
Eigen::Matrix<double, 2, 3> parte_P;
parte_P << -fx / Z, 0, fx * X / Z2,
0, -fy / Z, fy * Y / Z2;
Eigen::Matrix3d partP_I = Eigen::Matrix3d::Identity();
Eigen::Matrix3d partP_qt;
partP_qt = -skew(pos_cam);
Eigen::Map<Eigen::Matrix<double, 2, 7, Eigen::RowMajor>> J_se3(jacobians[0]);
J_se3.setZero();
J_se3.block<2, 3>(0, 0) << parte_P * partP_qt;
J_se3.block<2, 3>(0, 3) << parte_P * partP_I;
}
}
return true;
}
Eigen::Matrix3d K;
Eigen::Vector3d P3d;
Eigen::Vector2d P2d;
};
[����]������,���ſ˱�:�����֤��������ȷ����???
F-LOAM���ֶ���������
ceres::CostFunction *factor_analytic_edge = new EdgeAnalyticCostFunction(
source,
target_x, target_y,
ratio
);
// #endif
problem_.AddResidualBlock(
factor_analytic_edge,
config_.loss_function_ptr,
param_.q, param_.t
);
class EdgeAnalyticCostFunction : public ceres::SizedCostFunction<1, 4, 3>
{ // �Ż�����ά��:1 ����ά�� : q : 4 t : 3
public:
double s;
Eigen::Vector3d curr_point, last_point_a, last_point_b;
EdgeAnalyticCostFunction(const Eigen::Vector3d curr_point_, const Eigen::Vector3d last_point_a_,
const Eigen::Vector3d last_point_b_, const double s_)
: curr_point(curr_point_), last_point_a(last_point_a_), last_point_b(last_point_b_), s(s_) {}
virtual bool Evaluate(double const *const *parameters,
double *residuals,
double **jacobians) const // ����в�ģ��
{
Eigen::Map<const Eigen::Quaterniond> q_last_curr(parameters[0]); // ��� w x y z
Eigen::Map<const Eigen::Vector3d> t_last_curr(parameters[1]);
Eigen::Vector3d lp; // line point
Eigen::Vector3d lp_r;
lp_r = q_last_curr * curr_point;
lp = q_last_curr * curr_point + t_last_curr; // new point
Eigen::Vector3d nu = (lp - last_point_a).cross(lp - last_point_b);
Eigen::Vector3d de = last_point_a - last_point_b;
residuals[0] = nu.norm() / de.norm(); // �߲в�
// ��һ��λ��
nu.normalize();
if (jacobians != NULL)
{
if (jacobians[0] != NULL)
{
Eigen::Vector3d re = last_point_b - last_point_a;
Eigen::Matrix3d skew_re = skew(re);
Eigen::Matrix3d skew_de = skew(de);
// J_so3_Rotation
Eigen::Matrix3d skew_lp_r = skew(lp_r);
Eigen::Matrix3d dp_by_dr;
dp_by_dr.block<3, 3>(0, 0) = -skew_lp_r;
Eigen::Map<Eigen::Matrix<double, 1, 4, Eigen::RowMajor>> J_so3_r(jacobians[0]);
J_so3_r.setZero();
J_so3_r.block<1, 3>(0, 0) = nu.transpose() * skew_de * dp_by_dr / (de.norm() * nu.norm());
// J_so3_Translation
Eigen::Matrix3d dp_by_dt;
(dp_by_dt.block<3, 3>(0, 0)).setIdentity();
Eigen::Map<Eigen::Matrix<double, 1, 3, Eigen::RowMajor>> J_so3_t(jacobians[1]);
J_so3_t.setZero();
J_so3_t.block<1, 3>(0, 0) = nu.transpose() * skew_de / (de.norm() * nu.norm());
}
}
return true;
}
};
class PlaneAnalyticCostFunction : public ceres::SizedCostFunction<1, 4, 3>
{
public:
Eigen::Vector3d curr_point, last_point_j, last_point_l, last_point_m;
Eigen::Vector3d ljm_norm;
double s;
PlaneAnalyticCostFunction(Eigen::Vector3d curr_point_, Eigen::Vector3d last_point_j_,
Eigen::Vector3d last_point_l_, Eigen::Vector3d last_point_m_, double s_)
: curr_point(curr_point_), last_point_j(last_point_j_), last_point_l(last_point_l_), last_point_m(last_point_m_), s(s_) {}
virtual bool Evaluate(double const *const *parameters,
double *residuals,
double **jacobians) const
{ // ����в�ģ��
// �������, j,l,m ���������ɵ�ƽ���ı����(��)����ĵ�λ������(����)
Eigen::Vector3d ljm_norm = (last_point_j - last_point_l).cross(last_point_j - last_point_m);
ljm_norm.normalize(); // �������
Eigen::Map<const Eigen::Quaterniond> q_last_curr(parameters[0]);
Eigen::Map<const Eigen::Vector3d> t_last_curr(parameters[1]);
Eigen::Vector3d lp; // ���ӵ�ǰ��ĵ�ǰ�㡱 ����ת������ת��������һ���ͬ��������㡱
Eigen::Vector3d lp_r = q_last_curr * curr_point; // for compute jacobian o rotation L: dp_dr
lp = q_last_curr * curr_point + t_last_curr;
// ��
double phi1 = (lp - last_point_j).dot(ljm_norm);
residuals[0] = std::fabs(phi1);
if (jacobians != NULL)
{
if (jacobians[0] != NULL)
{
phi1 = phi1 / residuals[0];
// Rotation
Eigen::Matrix3d skew_lp_r = skew(lp_r);
Eigen::Matrix3d dp_dr;
dp_dr.block<3, 3>(0, 0) = -skew_lp_r;
Eigen::Map<Eigen::Matrix<double, 1, 4, Eigen::RowMajor>> J_so3_r(jacobians[0]);
J_so3_r.setZero();
J_so3_r.block<1, 3>(0, 0) = phi1 * ljm_norm.transpose() * (dp_dr);
Eigen::Map<Eigen::Matrix<double, 1, 3, Eigen::RowMajor>> J_so3_t(jacobians[1]);
J_so3_t.block<1, 3>(0, 0) = phi1 * ljm_norm.transpose();
}
}
return true;
}
};
�C2.4 ������Ա����
// �趨��Ӧ�IJ���ģ�����Ż������б��ֲ���
void Problem::SetParameterBlockConstant(double *values)
// �趨��Ӧ�IJ���ģ�����Ż������пɱ�
void Problem::SetParameterBlockVariable(double *values)
// �趨�Ż��½�
void Problem::SetParameterLowerBound(double *values, int index, double lower_bound)
// �趨�Ż��Ͻ�
void Problem::SetParameterUpperBound(double *values, int index, double upper_bound)
// �ú��������ڲ�����ֵ��,�ڸ����IJ���λ�����Problem,������ǰλ�ô���cost���ݶ��Լ�Jacobian����;
bool Problem::Evaluate(const Problem::EvaluateOptions &options,
double *cost, vector<double>* residuals,
vector<double> *gradient, CRSMatrix *jacobian)
�C2.5 ���
// ���������
ceres::Solver::Options options; // �����кܶ������������
options.linear_solver_type = ceres::DENSE_NORMAL_CHOLESKY; // �ܼ�����cholesky||��������������
options.minimizer_progress_to_stdout = true; // �����cout
ceres::Solver::Summary summary; // �Ż���Ϣ
ceres::Solve(options, &problem, &summary); // ��ʼ�Ż� || ����-��С��������-�Ż���Ϣ
ceres::Solver::Options options;
// options.max_num_iterations = 7;
options.linear_solver_type = ceres::DENSE_SCHUR; // ���������
options.trust_region_strategy_type = ceres::DOGLEG; // ���ȷ�
options.minimizer_progress_to_stdout = false;
ceres::Solver::Summary summary;
TicToc solveTime;
ceres::Solve(options, &problem, &summary);
ceres::Solve(options, &problem, &summary);
3. ��Ʒ����
#include <iostream>
#include <opencv2/core/core.hpp>
#include <ceres/ceres.h>
#include <chrono>
using namespace std;
// ���ۺ����ļ���ģ��
struct CURVE_FITTING_COST {
CURVE_FITTING_COST(double x, double y) : _x(x), _y(y) {}
// �в�ļ���
template<typename T>
bool operator()(
const T *const abc, // ģ�Ͳ���,���Ż��IJ���,��3ά
T *residual) const {
residual[0] = T(_y) - ceres::exp(abc[0] * T(_x) * T(_x) + abc[1] * T(_x) + abc[2]); // y-exp(ax^2+bx+c) //�в�,Ҳ���Ǵ��ۺ��������
return true;
}
const double _x, _y; // x,y����
};
int main(int argc, char **argv) {
double ar = 1.0, br = 2.0, cr = 1.0; // ��ʵ����ֵ
double ae = 2.0, be = -1.0, ce = 5.0; // ���Ʋ���ֵ
int N = 100; // ���ݵ�
double w_sigma = 1.0; // ����Sigmaֵ
double inv_sigma = 1.0 / w_sigma;
cv::RNG rng; // OpenCV�����������
vector<double> x_data, y_data; // ����
for (int i = 0; i < N; i++) {
double x = i / 100.0;
x_data.push_back(x);
y_data.push_back(exp(ar * x * x + br * x + cr) + rng.gaussian(w_sigma * w_sigma));
}
double abc[3] = {ae, be, ce};
// ��������������
ceres::Problem problem;
for (int i = 0; i < N; i++) {
problem.AddResidualBlock( // �����������������
// ʹ���Զ���,������Ĵ��ۺ����ṹ�崫�롣ģ�����:�������,���ά�ȼ��в��ά��,����ά�ȼ��Ż�������ά��,ά��Ҫ��ǰ��struct��һ��
new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3>(
new CURVE_FITTING_COST(x_data[i], y_data[i])
),
nullptr, // �˺���,���ﲻʹ��,Ϊ��
abc // �����Ʋ���
);
}
// ���������
ceres::Solver::Options options; // �����кܶ������������
options.linear_solver_type = ceres::DENSE_NORMAL_CHOLESKY; // ��������������
//options.linear_solver_type = ceres::DENSE_QR;
options.minimizer_progress_to_stdout = true; // �����cout
ceres::Solver::Summary summary; // �Ż���Ϣ
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
ceres::Solve(options, &problem, &summary); // ��ʼ�Ż�,���
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "solve time cost = " << time_used.count() << " seconds. " << endl;
// ������
cout << summary.BriefReport() << endl; //����Ż��ļ�Ҫ��Ϣ
cout << "estimated a,b,c = ";
for (auto a:abc) cout << a << " ";
cout << endl;
return 0;
}
cmakelists.txt:
cmake_minimum_required(VERSION 2.8)
project(gaussnewton)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11")
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
find_package(Ceres REQUIRED)
include_directories(${CERES_INCLUDE_DIRS})
include_directories("/usr/include/eigen3")
set(SOURCE_FILES main.cpp)
add_executable(gaussnewton ${SOURCE_FILES})
target_link_libraries(gaussnewton ${OpenCV_LIBS})
target_link_libraries(gaussnewton ${CERES_LIBRARIES})

