1 背景
在参加了一次论坛之后,偶然听到了关于离线深度强化学习的一个算法叫AWAC。AWAC提出的初衷是为了让深度强化学习能够像BERT那样,实现离线预训练在线调整,从而提高强化学习算法本身的训练效率。然而,由于离线数据集与在线交互获得的数据集之间存在着分布偏差(Distribution Shift),使得离线训练的智能体策略并不能直接在线调整。为了解决这个问题,本文作者提出了AWAC (advantaged weighted actor critic)算法,使得深度强化学习模型能够像BERT一样预训练后再finetuning。遗憾的是,本文投稿ICLR未被接受,却以arxiv的形式流传下来。
论文原文:https://arxiv.org/abs/2006.09359
代码仓库:https://github.com/rail-berkeley/rlkit/tree/master/examples/awac
2 模型结构
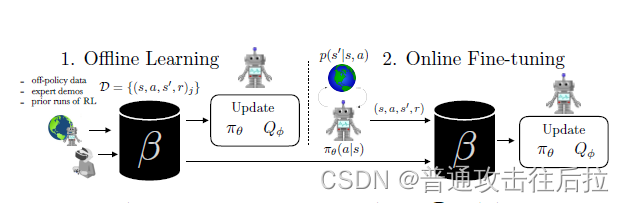
如上图所示,作者想做的事情其实和BERT很像。但是由于分布偏移问题的存在,作者只能改变训练的策略。
文章这部分的介绍其实比较难懂,首先,我们需要明白分布偏移问题offline RL本身就有,哪怕没有在线的调整,在线的测试其实也是在‘新的数据集’上进行。Offline RL解决分布偏移的方法是:

相比于正常的RL,其实就多了后面的约束,要求在线的策略和离线的策略不能差距太大。
同样,本文作者也采用和这种思想类似的方式,约束两个分布下策略的差距:
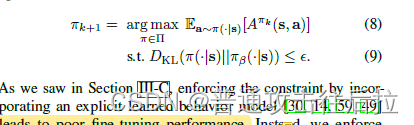
接着,通过KKT条件、拉格朗日数乘法、以及正向的KL-divergence等相关优化方法(里面涉及内容比较多,不过都很清晰),最后转化为如下的参数迭代问题:

这样,作者就通过理论方法推导除了策略迭代过程中的更新公式。
作者整体的训练算法选择的Actor-Critic架构,与其实验室是SAC的提出者有关系,也与推出来的策略迭代需要AC架构有关系。在AC架构下,Q值的更新还是使用TD方法,并且完全使用离线数据进行更新;而只有策略的更新才会用到在线交互获得的数据。
训练算法表示为:

里面很多参数很难用代码表示,于是作者在实现的过程中对公式做了一些合理的简化。
3 实验
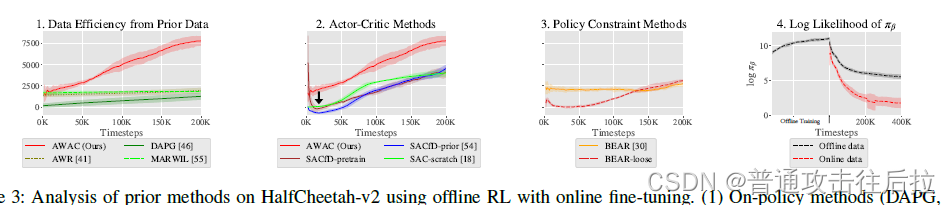 首先,作者发现off-policy的算法一般tuning起来比on-policy的好,此外,off-policy算法本身其实预训练之后再调整效果都会下降。
首先,作者发现off-policy的算法一般tuning起来比on-policy的好,此外,off-policy算法本身其实预训练之后再调整效果都会下降。
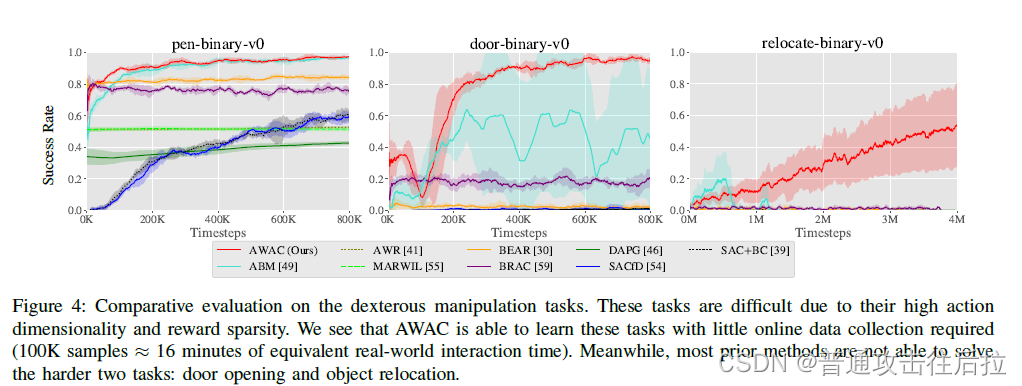
此外,作者主要从训练效率上说明了AWAC的优势
4 特点总结
文章对于一种新的DRL使用模式,即离线预训练在线调整的模式,从理论研究到实验证明给出了一套不错的解决方案。虽然很像AWR的一些工作,但是其整体设计还是有一些区别的。

