ʲô��naive bayes
���ر�Ҷ˹ naive bayes,��һ�ָ�����Ļ���ѧϰ�㷨,��Ҫ���ڽ����������
Ϊʲô����Ϊ���ر�Ҷ˹?
Ϊʲô����Ϊ����,�ѵ���������Ϊ��Ҷ˹��������?ʵ��������Ϊ,���ر�Ҷ˹�������������֮����к�ǿ�ĵĶ����ԡ�����ģ���е��������Ա˴�֮�䶼�Ƕ�����,�ı�һ�����Ե�ֵ,����ֱ��Ӱ���ı��㷨�����������Ե�ֵ
��Ҷ˹����
�˽����ر�Ҷ˹֮ǰ,��Ҫ����һЩ����ſɼ���
- ��������
Conditional probability:����һ���¼��Ѿ������������,����һ��ʱ�䷢���ĸ��ʡ���,�ڶ�������,����ĸ����Ƕ���? ����һ���������� - ���ϸ���
Joint Probability:�������������¼�ͬʱ�����Ŀ����� - �߽����
Marginal Probability:�¼������ĸ���,����һ�������Ľ���� - ����
Proportionality - ��Ҷ˹����
Bayes' Theorem:���ʵĹ�ʽ;��Ҷ˹������ָ���ݿ������¼�����������������¼��ĺ������
�߽����
�߽������ָ�¼������ĸ���,������Ϊ�����������ʡ�������һ���¼�Ϊ����;�ù�ʽ��ʾΪ P ( X ) P(X) P(X) ��:�鵽�����Ǻ�ɫ�ĸ����� P ( r e d ) = 0.5 P(red) = 0.5 P(red)=0.5 ;
���ϸ���
���ϸ�����ָ�����¼���ͬһʱ��㷢���Ŀ�����,��ʽ���Ա�ʾΪ P ( A �� B ) P(A \cap B) P(A��B)
A �� B ��������ͬ���¼���ͬ�ཻ, P ( A ? �� ? B ) P(A\ ��\ B) P(A?��?B) , P ( A , B ) P(A,B) P(A,B) = A �� B �����ϸ���
�������ڴ����¼����������Ŀ����ԡ���������Ϊ���� 0 �� 1 ֮�������,���� 0 ��ʾ�����ܷ����Ļ���,1 ��ʾ�¼���һ�������
��,��һ�����г鵽һ�ź��Ƶĸ����� 1 2 \frac{1}{2} 21?������ζ�ų鵽��ɫ�ͳ鵽��ɫ�ĸ�����ͬ;��Ϊһ��������52����,���� 26 ���Ǻ�ɫ��,26 ���Ǻ�ɫ��,���Գ鵽һ�ź�����鵽һ�ź��Ƶĸ����� 50%��
�����ϸ����ǶԲ���ͬʱ�����������¼�,ֻ��Ӧ���ڿ���ͬʱ����������������,��һ��52�����˿���,����һ�ż��Ǻ�ɫ����6���Ƶ����ϸ����� P ( 6 �� r e d ) = 2 52 = 1 26 P(6\cap red) = \frac{2}{52} = \frac{1}{26} P(6��red)=522?=261? ;�������ô�õ�����?��Ϊ�鵽��ɫ�ĸ���Ϊ50%,��һ��������������ɫ6(����6,��Ƭ6),��6����ɫ�����������ĸ���,��ô���㹫ʽ��Ϊ: P ( 6 �� r e d ) = P ( 6 ) �� P ( r e d ) = 4 52 �� 26 52 = 1 26 P(6 \cap red) = P(6) \times P(red) = \frac{4}{52} \times \frac{26}{52} = \frac{1}{26} P(6��red)=P(6)��P(red)=524?��5226?=261?
�����ϸ����� $ \cap $ ��Ϊ����,���¼� A �� �¼� B �����ĸ��ʵ��ཻ��,ͨ��ͼ����ʾΪ:����Բ���ཻ��,��6�ͺ�ɫ�ƹ�ͬ�IJ���
��������
����������ָ�¼������Ŀ�����,���������¼��Ľ���ķ����˺����¼������������,����,�����ѧ��ͨ����Ϊ80%,������ṩ��60%ѧ��ʹ��,��ô����˱���ѧ¼ȡ���ṩ����ĸ����Ƕ���?
P ( a c c e p t ? a n d ? g e t ? d o r m ) = P ( A c c e p t �O D o r m ) = P ( A c c e p t ) �� P ( D o r m ) = 0.8 �� 0.6 = 0.48 P(accept\ and\ get\ dorm) = P(Accept|Dorm) = P(Accept) \times P(Dorm) = 0.8 \times 0.6 = 0.48 P(accept?and?get?dorm)=P(Accept�ODorm)=P(Accept)��P(Dorm)=0.8��0.6=0.48
�������ʽ��ῼ�������¼�֮��Ĺ�ϵ,�����㱻��ѧ¼ȡ�ĸ���, �Լ�Ϊ���ṩ����ĸ���;���������еĹؼ���:
- ��һ���¼������������,����·����ļ���
- ��ʾΪ,���� B �ĸ��� A �����ĸ���,�ù�ʽ��ʾΪ: P ( A �O B ) P(A|B) P(A�OB),���� A ȡ���� B �����ĸ���
ͨ�������˽���������
�����������˽��:��������ȡ������ǰ�Ľ��,��ôͨ��������������Ϥ��������
��1:�������к�ɫ,��ɫ,��ɫ���Ų�����,ÿ�ֱ��õ��ĸ������,��ô������ɫ֮����������ɫ�����������Ƕ���?
- ������Ҫ�ȵõ�������ɫ�ĸ���: P ( B l u e ) = 1 3 P(Blue) = \frac{1}{3} P(Blue)=31? ��Ϊֻ�����ֿ�����
- ���ڻ�ʣ�����Ų����� ��ɫ����ɫ,��ô������ɫ�ĸ���Ϊ: P ( R e d ) = 1 2 P(Red) = \frac{1}{2} P(Red)=21? ��Ϊֻ�����ֿ�����
- ��ô�Ѿ�������ɫ��������ɫ�ĸ���Ϊ P ( R e d �O B l u e ) = 1 3 �� 1 2 = 1 6 P(Red|Blue) = \frac{1}{3} \times \frac{1}{2} = \frac{1}{6} P(Red�OBlue)=31?��21?=61?
��2:ɫ��ҡ��5�ĸ���Ϊ 1 6 \frac{1}{6} 61? ��ô�ڽ����������ҡ��5 ��ô���ܾ��� 1 3 \frac{1}{3} 31?,������������������һ������,��Ϊֻ��3������,����һ����5,��ô��������,�׳�5�ĸ��ʾ��� 1 3 \frac{1}{3} 31?��
ͨ��������Ϣ��֪,B ��Ϊ������������ A �����ĸ���,��Ϊ���� B ,A ����������,�� P ( A �O B ) P(A|B) P(A�OB) ��ʾ����ô���Եij�:
- ����A,B�����ĸ���Ϊ,A��B�ķ��������ų���A�ĸ���,��
- P ( B �O A ) = P ( A �� B ) P ( A ) P(B|A) = \frac{P(A \cap B)}{P(A)} P(B�OA)=P(A)P(A��B)?
���ϸ��ʺ��������ʵ�����
����������һ���¼�����һ���¼�����������µĸ���: P ( X ? g i v e n ? Y ) P(X\ given\ Y) P(X?given?Y) ��ʽΪ: P ( X �O Y ) P(X�OY) P(X�OY);��һ���¼������ĸ���ȡ������һ�¼��ķ���;��:��һ������,������鵽һ�ź���,��ô�鵽6�ĸ����� 1 13 \frac{1}{13} 131?;��Ϊ26�ź����н�������Ϊ6,�ù�ʽ��ʾ: P ( 6 �O r e d ) = 2 26 P(6|red) = \frac{2}{26} P(6�Ored)=262?
���ϸ��������������¼������Ŀ�����,�Ա����������ʿ����ڼ������ϸ���: P ( X �� Y ) = P ( X �O Y ) �� P ( Y ) P(X \cap Y) = P(X|Y) \times P(Y) P(X��Y)=P(X�OY)��P(Y)
ͨ���ϲ��������ӵõ�,ͬʱ�鵽6�ͺ�ɫ�ĸ���Ϊ: 1 26 \frac{1}{26} 261?
��Ҷ˹����
��Ҷ˹������ȷ���������ʵ���ѧ��ʽ����Ҷ˹����������������ʷֲ��Լ��������ʡ�
������ʺ��������
- �������
prior probability:���ռ�������֮ǰ�����¼��ĸ��� - �������
posterior probability:�õ��µ�����������֮ǰ�¼������ĸ���;���仰˵��������������¼� B �Ѿ������������,�¼� A �����ĸ�����
��,��һ��52 �����г�ȡһ����,��ô��������K�ĸ����� 4 52 \frac{4}{52} 524? , ��Ϊһ��������4��K;������е�����һ��������,��ô�鵽��K�ĸ������� 4 12 \frac{4}{12} 124?;��Ϊһ��������12�������ơ���ô��Ҷ˹�����Ĺ�ʽΪ:
-
P
(
A
�O
B
)
=
P
(
A
��
B
)
P
(
B
)
P(A|B) = \frac{P(A \cap B)}{P(B)}
P(A�OB)=P(B)P(A��B)?,
P
(
B
�O
A
)
=
P
(
B
��
A
)
P
(
A
)
P(B|A) = \frac{P(B \cap A)}{P(A)}
P(B�OA)=P(A)P(B��A)?
- P ( A �� B ) P(A \cap B) P(A��B), P ( B �� A ) P(B \cap A) P(B��A) A��Bͬʱ������B��Aͬʱ����ʱ��ȵ�
- P ( B �� A ) = P ( B �O A ) �� P ( A ) P(B \cap A) = P(B|A) \times P(A) P(B��A)=P(B�OA)��P(A)
- P ( A �� B ) = P ( A �O B ) �� P ( B ) P(A \cap B) = P(A|B) \times P(B) P(A��B)=P(A�OB)��P(B)
- ��ô��������Ĺ�ʽ,��֪
P
(
A
��
B
)
=
P
(
B
��
A
)
P(A \cap B) = P(B \cap A)
P(A��B)=P(B��A) ���Ƶ�����ʽ:
- ��Ϊ P ( B �� A ) = P ( A �� B ) P(B \cap A) = P(A \cap B) P(B��A)=P(A��B) ,��ô P ( B �O A ) �� P ( A ) = P ( A �O B ) �� P ( B ) P(B|A) \times P(A) = P(A|B) \times P(B) P(B�OA)��P(A)=P(A�OB)��P(B)
- ��ô�� P ( A ) P(A) P(A) ���õ�ʽ�ұ� P ( B �O A ) = P ( A �O B ) �� P ( B ) P ( A ) P(B|A) = \frac{P(A|B) \times P(B)}{P(A)} P(B�OA)=P(A)P(A�OB)��P(B)?
- ����
Formula for BayesΪ P ( B �O A ) = P ( A �O B ) �� P ( B ) P ( A ) P(B|A) = \frac{P(A|B) \times P(B)}{P(A)} P(B�OA)=P(A)P(A�OB)��P(B)?
����:
-
P ( A ) P(A) P(A):A �ı߽����
-
P ( B ) P(B) P(B):B �ı߽����
-
P ( A �O B ) P(A|B) P(A�OB) :��������,��֪ B,A �ĸ���
-
P ( B �O A ) P(B|A) P(B�OA) :��������,��֪ A,B �ĸ���
-
P ( B �� A ) P(B \cap A) P(B��A):���ϸ��� B �� A ͬʱ�����ĸ���
һ���ĸ���������ܻ���:ę́�ɼ��µ��ĸ����Ƕ���?��������ͨ��ѯ������������һ��:����A��ƽ��ָ���µ�,ę́�ɼ��µ��ĸ����Ƕ���? ���� B �Ѿ������������� A �ĸ��ʿ��Ա�ʾΪ:
P ( M a o �O A S ) = P ( M a o �� A S ) P ( A S ) P(Mao|AS) = \frac{P(Mao \cap AS)}{P(AS)} P(Mao�OAS)=P(AS)P(Mao��AS)?
P ( M a o �� A S ) P(Mao \cap AS) P(Mao��AS) �� A �� B ͬʱ�����ĸ���,�� A ����������� B Ҳ�����ĸ��� �� A �����ĸ�����ȱ�ʾΪ: P ( M a o ) �� P ( A S �O M a o ) P(Mao) \times P(AS|Mao) P(Mao)��P(AS�OMao);����������ʽ���,Ҳ���DZ�Ҷ˹����,���Ա�ʾΪ:
- ���, P ( M a o �� A S ) = P ( M a o ) �� P ( A S �O M a o ) P(Mao \cap AS) = P(Mao) \times P(AS|Mao) P(Mao��AS)=P(Mao)��P(AS�OMao)
- ��ô, P ( M a o �O A S ) = P ( M a o ) �� P ( A S �O M a o ) P ( A S ) P(Mao|AS) = \frac{P(Mao) \times P(AS|Mao)}{P(AS)} P(Mao�OAS)=P(AS)P(Mao)��P(AS�OMao)?
P ( M a o ) P(Mao) P(Mao) �� P ( A S ) P(AS) P(AS) �ֱ�Ϊę́��A�ɵ��µ�����,�˴˼�û�й�ϵ
һ�������,������ x (����) y (���) �ں�����,���� x = A S x=AS x=AS , y = M A O y=MAO y=MAO ��ô�������ʽ�о� P ( Y �O X ) = P ( X �O Y ) �� P ( Y ) P ( X ) P(Y|X) = \frac{P(X|Y) \times P(Y)}{P(X)} P(Y�OX)=P(X)P(X�OY)��P(Y)?
���ر�Ҷ˹�㷨
���ر�Ҷ˹����һ�����㷨,����һ���㷨,������Щ�㷨������һ����ͬ��ԭ��,��ÿһ�Ա������������������������ر�Ҷ˹��һ�������ı�Ҷ˹�ƺ�,���������㷨�ļ���:����ʽ Multinomial�� ��Ŭ�� Bernoulli����˹ Gaussian��
��Ŭ��
��Ŭ�����ر�Ҷ˹,�ֽ�������ʽ,ֻ���ܶ�����ֵ,�����֮,�ڲ�Ŭ���б������ÿ��ֵ�Ķ����Ƴ�������,��һ�����������������ĵ��С�
ͨ����˵,��Ŭ������������Ľ��: N B = { P ( X = 1 ) ? = ? q P ( X = 0 ) ? = ? 1 ? q NB=\begin{cases} P(X=1)\ = \ q\\ P(X=0)\ = \ 1-q\\ \end{cases} NB={P(X=1)?=?qP(X=0)?=?1?q? ,�ڲ�Ŭ����,�����ж������,��ÿ������������Ϊ�Ƕ����Ƶı���,���,��Ҫ��������ʾΪ������������
��ô��չ���Ĺ�ʽΪ: P ( A �O B ) = P ( B �O A ) �� P ( A ) P ( A ) �� P ( B �O A ) + P ( n o t A ) �� P ( B �O n o t A ) P(A|B) = \frac{P(B|A) \times P(A)}{P(A) \times P(B|A) + P(not A) \times P(B|not A)} P(A�OB)=P(A)��P(B�OA)+P(notA)��P(B�OnotA)P(B�OA)��P(A)?
����:����COVID-19���Բ���ȷ,��**95%**�����ڸ�Ⱦʱ���Գ�����(������),�����ζ��������˲�δ��Ⱦ�ĸ�������ͬ��(������);��:���Jeovanna���Ϊ����,��ô����ȾCOVID-19�ĸ����Ƕ���?
�����Ժ���������ҽѧ����;������,���˲�����Եı���,������,�Dz��˲������Եı���
һ�������û�и������Ϣ��ȷ��Jeovanna�Ƿ��Ⱦ,��פ������,�Ƿ���,ɥʧζ���ȡ�����Ҫ�������Ϣ������Jeovanna��Ⱦ��,����Ԥ��Jeovanna��Ⱦ��Ϊ1%,��1%����������ʡ�
��ʱ��100000�˵IJ�������,Ԥ��1000�˸�Ⱦ(����1%),��ô����99000Ϊ��Ⱦ,����Ϊ���Ծ��� 95% �������Ժ� 95% ��������,������� 1000��95% �� 99000��5% �����ԡ�����һ������
| Has COVID-19 | Do not Has COVID-19 | count | |
|---|---|---|---|
| ���� | 950 | 4950 | 5900 |
| ���� | 50 | 94050 | 94100 |
��ô���Կ���,���Ե��˲���ȾCOVID-19�ĸ�����, 950 5900 = 16 % \frac{950}{5900} = 16\% 5900950?=16% ;��ôҲ����Jeovanna��16%�����Ǹ�Ⱦ COVID-19��
��ʱ�������������Ϊ16%,��ô����˿��COVID-19�Ŀ�����Ϊ:
P ( B �O A ) P(B|A) P(B�OA) :��95%�ɹ���������ֻ��������
P ( A ) P(A) P(A):���Եļ��ɹ���
��֪, P ( B �O A ) = 0.16 P(B|A) = 0.16 P(B�OA)=0.16 , P ( A ) = 0.95 P(A) = 0.95 P(A)=0.95
P ( A �O B ) = P ( B �O A ) �� P ( A ) P ( A ) �� P ( B �O A ) + P ( n o t A ) �� P ( B �O n o t A ) = 0.16 �� 0.95 0.95 �� 0.16 + ( 1 ? 0.95 ) �� ( 1 ? 0.16 ) = 0.152 0.194 = 0.7835 = 78.35 % P(A|B) = \frac{P(B|A) \times P(A)}{P(A) \times P(B|A) + P(not A) \times P(B|not A)} = \frac{0.16\times0.95}{0.95\times 0.16 + (1-0.95)\times(1-0.16)}= \frac{0.152}{0.194} = 0.7835 = 78.35\% P(A�OB)=P(A)��P(B�OA)+P(notA)��P(B�OnotA)P(B�OA)��P(A)?=0.95��0.16+(1?0.95)��(1?0.16)0.16��0.95?=0.1940.152?=0.7835=78.35%
��ô�Ϳ��Ե�֪,����������¸�ȾCOVID-19�������,��ȥ������78%��������
����ʽ
����ʽ���ر�Ҷ˹�ǻ��ڶ���ֲ�������Ҷ��˹,���������ı�,���� d d d �� c c c �еĸ��ʼ�������:
P ( c �O d ) ? �� P ( c ) �� i = 1 n ? P ( t k �O c ) P(c|d) \ \propto P(c) \prod_{i=1}^n\ P(t_k|c) P(c�Od)?��P(c)��i=1n??P(tk?�Oc)
ͨ����˵���Ƕ���ʽ��һ������,�Ǽ�������ͬ��ʵ��
P ( t k �O c ) P(t_k|c) P(tk?�Oc) �� t k t_k tk? �� ��������,���������ݼ� c c c ��, P ( t k �O c ) P(t_k|c) P(tk?�Oc) ����Ϊ t k t_k tk? �ж���֤�ݱ��� c c c ����ȷ��; P ( c ) P(c) P(c) ���������� t 1.. ? t 2.. ? t 3.. ? t n d t1..\ t2..\ t3..\ tn_d t1..?t2..?t3..?tnd? �еı�� d d d,�������������ڷ���Ĵʻ����һ����, n d n_d nd? �� ��� d d d ��������
����:��Peking and Taipei join the WTO��, < P e k i n g , ? T a i p e i , ? j o i n , ? W T O > <Peking,\ Taipei,\ join,\ WTO> <Peking,?Taipei,?join,?WTO> ,��ô n d = 4 n_d = 4 nd?=4
��ô���Լ�Ϊ,
P ( c = x �O d = c k ) = P ( c 1 = x 1 . . , ? c 2 = x 2 . . , ? c n = x n �O d = c k ) = �� i = 1 n ( c i �O d ) x i + ( 1 ? P ( c i �O d ) ) ( 1 ? x i ) P(c=x|d=c_k) = P(c^1=x^1..,\ c^2=x^2..,\ c^n=x^n|d=c_k) = \prod_{i=1}^n(c^i|d)x^i + (1-P(c^i|d)) (1-x^i) P(c=x�Od=ck?)=P(c1=x1..,?c2=x2..,?cn=xn�Od=ck?)=��i=1n?(ci�Od)xi+(1?P(ci�Od))(1?xi)
�� i = 1 n \prod_{i=1}^n ��i=1n? ���˻�,�����±���˵��ϱ�
���ر�Ҷ˹ʵ��
���Ƚ����ر�Ҷ˹Ϊ 5 ������:
- ����
- ���ݼ�����
- ������������
- ��˹�ܶȺ���
- �������
����
��������������������������ݵĸ���,����ν�Ļ����ʡ�
�ȴ���һ���ֵ����,����ÿ����������ֵ,Ȼ���������м�¼���б���Ϊ�ֵ��е�ֵ��
����ÿ���е����һ�������͡�
# ���������ݼ�,���ؽṹ��һ���ʵ�
def separate_by_class(dataset):
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1] # dataset���һ�������
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
��һЩ���ݼ�
X1 X2 Class
3.393533211 2.331273381 0
3.110073483 1.781539638 0
7.423436942 4.696522875 1
1.343808831 3.368360954 0
3.582294042 4.67917911 0
9.172168622 2.511101045 1
7.792783481 3.424088941 1
2.280362439 2.866990263 0
5.745051997 3.533989803 1
7.939820817 0.791637231 1
���Է��ຯ���Ĺ���
def separate_by_class(dataset):
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
# �������ݼ�
dataset = [
[3.393533211,2.331273381,0],
[3.110073483,1.781539638,0],
[1.343808831,3.368360954,0],
[7.423436942,4.696522875,1],
[3.582294042,4.67917911,0],
[9.172168622,2.511101045,1],
[7.792783481,3.424088941,1],
[2.280362439,2.866990263,0],
[5.745051997,3.533989803,1],
[7.939820817,0.791637231,1]
]
separated = separate_by_class(dataset)
for label in separated:
print(label)
for row in separated[label]:
print(row)
���Կ��������dzɹ���
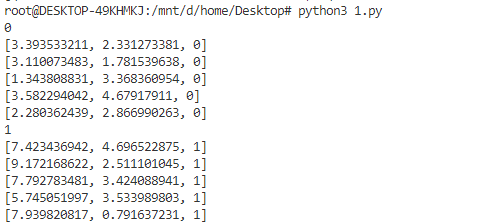
���ݼ�����
������Ҫ�Ը������ݼ����������ݽ���ͳ��,��ζ�ָ�����ݼ������ʼ���?��Ҫ���¼���
�������ݼ��������ݵ�ƽ��ֵ�ͱ���
ƽ��ֵΪ: s u m ( x ) n �� c o u n t ( x ) \frac{sum(x)}{n} \times count(x) nsum(x)?��count(x) ;���� x x x Ϊ���ڲ���ֵ���б�
mean�������ڼ���ƽ��ֵ
def mean(numbers):
return sum(numbers) / float(len(numbers))
��������ļ��㷽ʽΪƽ��ֵ��ƽ�����ʽ����Ϊ sqrt((sum i to N (x_i �C mean(x))^2) / N-1)
������������
from math import sqrt
# Calculate the standard deviation of a list of numbers
def stdev(numbers):
avg = mean(numbers) # ƽ��ֵ
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1)
return sqrt(variance)
����Ҫ��ÿ�����ݵ�ÿһ�м���ƽ��ֵ�ͱ�ƫ��ͳ������ͨ����ÿ�е�����ֵ�ռ���һ���б��в�������б���ƽ��ֵ�ͱ��������ɺ�,��ͳ����Ϣ�ռ������ݻ��ܵ��б���Ԫ���С�Ȼ��,�����ݼ��е�ÿһ���ظ��˲���������ͳ��Ԫ���б���
������ ���ݻ��ܵĺ��� summarise_dataset()����ͳ��ÿ���б���ƽ��ֵ�ͱ���
from math import sqrt
# ����ƽ����
def mean(numbers):
return sum(numbers)/float(len(numbers))
# �������
def stdev(numbers): # ����
avg = mean(numbers) # ����ƽ��ֵ
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) # �������е�ƽ��
return sqrt(variance)
# ���ݻ���
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1]) # ��Ϊ�����Ҫ���ԡ�ɾ������������
return summaries
# Test summarizing a dataset
dataset = [
[3.393533211,2.331273381,0],
[3.110073483,1.781539638,0],
[1.343808831,3.368360954,0],
[3.582294042,4.67917911,0],
[2.280362439,2.866990263,0],
[7.423436942,4.696522875,1],
[5.745051997,3.533989803,1],
[9.172168622,2.511101045,1],
[7.792783481,3.424088941,1],
[7.939820817,0.791637231,1]]
summary = summarize_dataset(dataset)
print(summary)
����ʹ�õ���zip() ����,��ÿ����Ϊ�ṩ�IJ�����ʹ�� * ��Ϊλ�ú���,�˽����ݼ����ݸ� zip() ,�������Ὣÿһ�еķָ�Ϊ�����б���Ȼ��zip() ����ÿһ�е�ÿ��Ԫ��,����һ����Ϊ�����б���
Ȼ�����ÿ���е�ƽ�����������������ɾ������Ҫ����(����������е�ƽ����,���������)
���Կ���
[
(5.178333386499999, 2.7665845055177263, 10),
(2.9984683241, 1.218556343617447, 10)
]
��������������
separate_by_class() �ǽ����ݷֳ���,����Ҫ��дһ�� summarise_dataset();���ȼ���ÿ�е�ͳ�ƻ�����Ϣ,Ȼ���ڰ����Ӽ�����(X1,X2)
# ���������ݼ�
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
���������Ĵ���
from math import sqrt
# ����ƽ����
def mean(numbers):
return sum(numbers)/float(len(numbers))
# �������
def stdev(numbers): # ����
avg = mean(numbers) # ����ƽ��ֵ
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) # �������е�ƽ��
return sqrt(variance)
# ���ݻ���
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1]) # ��Ϊ�����Ҫ���ԡ�ɾ������������
return summaries
# ����������ݻ���
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
# �������ݼ�
dataset = [
[3.393533211,2.331273381,0],
[3.110073483,1.781539638,0],
[1.343808831,3.368360954,0],
[3.582294042,4.67917911,0],
[2.280362439,2.866990263,0],
[7.423436942,4.696522875,1],
[5.745051997,3.533989803,1],
[9.172168622,2.511101045,1],
[7.792783481,3.424088941,1],
[7.939820817,0.791637231,1]]
summary = summarize_by_class(dataset)
for label in summary:
print(label)
for row in summary[label]:
print(row)
���շ���,��ÿ�м���ƽ��ֵ�ͱ���

��˹�ֲ�
��˹�ֲ� Gaussian distribution ��������������������,��˹�ֲ��Ǿ��жԳƵ����εķֲ�,���������Ҳ������ľ���,�����µ������������,���������֮�͵���1��
��˹�ֲ��еĴ������������ֵ������Χ�ƾ�ֵ�ۼ�,ֵ���ֵԽԶ,��ô�������Ŀ����Ծ�ԽС���ӽ�����δ��ȫ����x �ᡣ
��˹�ֲ��ɾ�ֵ�ͱ�����������������,�κε� (x) ������ͨ����ʽ z = x ? m e a n s t a n d a r d ? d e v i a t i o n z = \frac{x-mean}{standard\ deviation} z=standard?deviationx?mean? ������
Reference
ͨ����һ��,�Ϳ���֪���Ϳ��Լ���������ĸ���,��ʽΪ:
P ( x i �O Y ) = 1 2 �� �� y 2 e x p ( ? ( ( x i ? �� y ) 2 2 �� y 2 ) P({x_i}|Y) = \frac{1}{\sqrt2\pi\sigma_y^2}exp(-(\frac{(x_i-\mu_y)^2}{2\sigma_y^2}) P(xi?�OY)=2?����y2?1?exp(?(2��y2?(xi??��y?)2?)
����, �� \sigma �� Ϊ����, �� \mu �� Ϊƽ��ֵ,��ôת��Ϊ�ɶ����Ĺ�ʽΪ:
f ( x ) = 1 ( 2 �� p i ) �� s i g m a �� e x p ( ? ( ( x ? m e a n ) 2 ( 2 �� s i g m a ) 2 ) ) f(x) = \frac{1}{\sqrt{(2 \times pi )}\times sigma} \times exp(-(\frac{(x-mean)^2}{(2 \times sigma)^2})) f(x)=(2��pi)?��sigma1?��exp(?((2��sigma)2(x?mean)2?))
����,sigma�� x �ı���,mean �� x ��ƽ��ֵ,PI�� ����
��
\pi
�� math.pi ��ֵ��
��ô��ת����python�еĴ���Ϊ:
f(x) = (1 / sqrt(2 * PI) * sigma) * exp(-((x-mean)^2 / (2 * sigma^2)))
��ô��pythonʵ��һ������,��ʵ�ָ�˹��ʽ
# �����˹�ֲ��ĺ���,��Ҫ��������,x ƽ��ֵ,����
def calculate_probability(x, mean, stdev):
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
����ͨ������������������,(0,1,1), (1,1,1),(2,1,1)
from math import sqrt
from math import pi
from math import exp
# �����˹�ֲ��ĺ���,��Ҫ��������,x ƽ��ֵ,����
def calculate_probability(x, mean, stdev):
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
print(calculate_probability(1.0, 1.0, 1.0))
print(calculate_probability(2.0, 1.0, 1.0))
print(calculate_probability(0.0, 1.0, 1.0))

������Կ������,(1,1,1) �ĸ��������(����ֵ���������ζ���)
�������
������,���Գ���ͨ������������ͳ�������ݵĸ���,����ÿ�����ĸ��ʶ��ǵ��������,���ォ���ʼ��㹫ʽ P ( c l a s s �O d a t a ) = P ( d a t a �O c l a s s ) �� P ( c l a s s ) P(class|data) = P(data|class) \times P(class) P(class�Odata)=P(data�Oclass)��P(class);����һ�������ļ�,�⽫��ζ�Ž����Ϊ���ֵ����ļ�����ΪԤ��������Ϊͨ����Ԥ�����Ȥ,�����Ǹ���
������������,����������,������ class=0 �������˵��,��ʽΪ:
P ( c l a s s = 0 �O X 1 , X 2 ) = P ( X 1 �O c l a s s = 0 ) �� P ( X 2 �O c l a s s = 0 ) �� P ( c l a s s = 0 ) P(class=0|X1,X2) = P(X1|class=0) \times P(X2|class=0) \times P(class=0) P(class=0�OX1,X2)=P(X1�Oclass=0)��P(X2�Oclass=0)��P(class=0)
��дһ���ۺϺ���,�������ĸ�������ܴ���,
# Example of calculating class probabilities
from math import sqrt
from math import pi
from math import exp
# ������ݼ�
def separate_by_class(dataset):
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
print(separated)
return separated
# ����ƽ����
def mean(numbers):
return sum(numbers)/float(len(numbers))
# �������
def stdev(numbers):
avg = mean(numbers) # ����ƽ��ֵ
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1) # ����
return sqrt(variance)
# ���ݻ���
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1])
return summaries
# ����������ݻ���
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
# �����˹�ֲ��ĺ���,��Ҫ��������,x ƽ��ֵ,����
def calculate_probability(x, mean, stdev):
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
# ����ÿ������ĸ���
def converge_probabilities(summaries, row):
# �������з���ĸ���
total_rows = sum([summaries[label][0][2] for label in summaries])
probabilities = dict()
for class_value, class_summaries in summaries.items():
# �������ĸ���,������������ܷ�������ʶ���
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
for i in range(len(class_summaries)):
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
return probabilities
# �������ݼ�
dataset = [
[3.393533211,2.331273381,0],
[3.110073483,1.781539638,0],
[1.343808831,3.368360954,0],
[3.582294042,4.67917911,0],
[2.280362439,2.866990263,0],
[7.423436942,4.696522875,1],
[5.745051997,3.533989803,1],
[9.172168622,2.511101045,1],
[7.792783481,3.424088941,1],
[7.939820817,0.791637231,1]]
summaries = summarize_by_class(dataset)
probabilities = converge_probabilities(summaries, dataset[0])
print(probabilities)
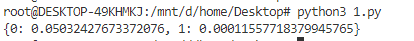
�ɽ�����Ե�֪,dataset[0] X1 �ĸ���(0.0503)Ҫ���� X2 �ĸ���(0.0001),���Կ�����ȷ���жϳ� dataset[0] ���� X1 ����
��(Iris)����
�β������,��ģʽʶ���зdz�������һ�����ݿ�,��Ҫ�Ƚ���������:
ʵ�ֿ�ʼ
ʵ���Ǹ�������ʵ��IJ���,�����ر�Ҷ˹�㷨Ӧ�����β�����ݼ���,�β�����ݼ���ʵ��Ҳ����Ҫ��ͬ�IJ���,ֻ�����������ݼ��е����ݻ���ҪһЩ�����IJ���,���¿ɷ�Ϊ���¼��ֲ���:
- ���ݵ�Ԥ����
- ���ļ��ж�ȡ����
- ����������ת��Ϊ����������ʵ�������(
float) - ����ʵ����ת��Ϊ����
int
- ����
- ���ݼ�����
- ������������
- ��˹�ܶȺ���
- �������
from csv import reader
from random import seed
from random import randrange
from math import sqrt
from math import exp
from math import pi
# ��ȡ���ݼ�
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# ��ÿ�е�����ת��Ϊfloat
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# ����ʵ����ת��Ϊ����,�����±�
def str_column_to_int(dataset, column):
'''
:param dataset: list, ���ݼ�
:param column: string,��Ϊ���͵���Ҫ����
:return: None
'''
# ͨ��ѭ���õ����з���
class_values = [row[column] for row in dataset]
# �Է�����ȥ��
unique = set(class_values)
lookup = dict()
# �õ�����ֵ��key �±�
for i, value in enumerate(unique):
lookup[value] = i
# �Ѷ�Ӧ���±�����滻
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# �����ݵ�һ������Ϊѵ������
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for _ in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# ����ȷ��
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# ���㷨���ݽ�������
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
"""
:param dataset:list, ԭʼ���ݼ�
:param algorithm:function,�㷨����
:param n_folds:int,ȡ����������Ϊѵ����
:param args:options ,����
:return: None
"""
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
# �ϲ���һ������
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None # �����һ�������ֶ�����ΪNone
predicted = algorithm(train_set, test_set, *args)
# ��ʵ������
actual = [row[-1] for row in fold]
# ��ȷ�ķ���,����һ��������ȷ��
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
print(scores)
return scores
# ���շ�����
def separate_by_class(dataset):
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
# ������һϵ�е�ƽ��ֵ
def mean(numbers):
return sum(numbers)/float(len(numbers))
# ����һϵ�����ֵı���
def stdev(numbers):
avg = mean(numbers)
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1)
return sqrt(variance)
# �������ݼ���ÿ�е�ƽ��ֵ ���� ����
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1])
return summaries
# ���շ�������ݼ�
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
# ����x�ĸ�˹����
def calculate_probability(x, mean, stdev):
"""
:param x:float, �������ֵ�ĸ�˹����
:param mean:float,x��ƽ��ֵ
:param stdev:float,x�ı���
:return: None
"""
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
# ����ÿ�еĸ���
def converge_probabilities(summaries, row):
# �������з���ĸ���
total_rows = sum([summaries[label][0][2] for label in summaries])
probabilities = dict()
for class_value, class_summaries in summaries.items():
# �������ĸ���,������������ܷ�������ʶ���
# ��ʽ�е�P(class)
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
# ͨ����ʽ P(X1|class=0) * P(X2|class=0) * P(class=0) �����˹����
for i in range(len(class_summaries)):
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
return probabilities
# ͨ�����������ֵ,Ԥ��û������ĸ�Ʒ��,ȡ��˹��������ֵ
def predict(summaries, row):
probabilities = converge_probabilities(summaries, row)
best_label, best_prob = None, -1
for class_value, probability in probabilities.items():
if best_label is None or probability > best_prob:
best_prob = probability
best_label = class_value
return best_label
# Naive Bayes Algorithm
def naive_bayes(train, test):
# ѵ�����ݰ������������
summarize = summarize_by_class(train)
predictions = list()
for row in test:
output = predict(summarize, row)
predictions.append(output)
print(predictions)
return(predictions)
# ����
if __name__ == '__main__':
seed(1)
filename = 'iris.csv'
dataset = load_csv(filename)
# ת����ֵΪfloat
for i in range(len(dataset[0])-1):
str_column_to_float(dataset, i)
# ������ת��Ϊ����
str_column_to_int(dataset, len(dataset[0])-1)
# �����ݷ�λ�������ݺ�ѵ������,foldsΪ��������Ϊѵ������
n_folds = 5
scores = evaluate_algorithm(dataset, naive_bayes, n_folds)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))

���Կ������н��,���β�����ݼ���Ԥ����ȷ��,ƽ��Ϊ95.333%
���ڶ� main ���ֽ�����,ʹ��ȫ�����ݼ���Ϊѵ��,������¼��ΪԤ��
# �����������ݼ�����
model = summarize_by_class(dataset)
# �¼�һ��Ԥ������
row = [5.3,3.9,3.2,2.3]
# ����ѵ�������ж�����Ԥ��
label = predict(model, row)
print('Data=%s, Predicted: %s' % (row, label))
�����Ĺ��Ĵ�������:
from csv import reader
from random import seed
from random import randrange
from math import sqrt
from math import exp
from math import pi
# ��ȡ���ݼ�
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# ��ÿ�е�����ת��Ϊfloat
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# ����ʵ����ת��Ϊ����,�����±�
def str_column_to_int(dataset, column):
'''
:param dataset: list, ���ݼ�
:param column: string,��Ϊ���͵���Ҫ����
:return: None
'''
# ͨ��ѭ���õ����з���
class_values = [row[column] for row in dataset]
# �Է�����ȥ��
unique = set(class_values)
lookup = dict()
# �õ�����ֵ��key �±�
for i, value in enumerate(unique):
lookup[value] = i
# ����һ��,����ʾ�±����ʵ���ƶ�Ӧ������
print(lookup)
# �Ѷ�Ӧ���±�����滻
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# �����ݵ�һ������Ϊѵ������
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for _ in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# ����ȷ��
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# ���㷨���ݽ�������
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
"""
:param dataset:list, ԭʼ���ݼ�
:param algorithm:function,�㷨����
:param n_folds:int,ȡ����������Ϊѵ����
:param args:options ,����
:return: None
"""
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
# �ϲ���һ������
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None # �����һ�������ֶ�����ΪNone
predicted = algorithm(train_set, test_set, *args)
# ��ʵ������
actual = [row[-1] for row in fold]
# ��ȷ�ķ���,����һ��������ȷ��
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
print(scores)
return scores
# ���շ�����
def separate_by_class(dataset):
"""
:param dataset:list, ������õ��б�
:return: dict, ÿ�������ÿ��(����)��ƽ��ֵ,����,����
"""
separated = dict()
for i in range(len(dataset)):
vector = dataset[i]
class_value = vector[-1]
if (class_value not in separated):
separated[class_value] = list()
separated[class_value].append(vector)
return separated
# ������һϵ�е�ƽ��ֵ
def mean(numbers):
return sum(numbers)/float(len(numbers))
# ����һϵ�����ֵı���
def stdev(numbers):
avg = mean(numbers)
variance = sum([(x-avg)**2 for x in numbers]) / float(len(numbers)-1)
return sqrt(variance)
# �������ݼ���ÿ�е�ƽ��ֵ ���� ����
def summarize_dataset(dataset):
summaries = [(mean(column), stdev(column), len(column)) for column in zip(*dataset)]
del(summaries[-1])
return summaries
# ���շ�������ݼ�
def summarize_by_class(dataset):
separated = separate_by_class(dataset)
summaries = dict()
for class_value, rows in separated.items():
summaries[class_value] = summarize_dataset(rows)
return summaries
# ����x�ĸ�˹����
def calculate_probability(x, mean, stdev):
"""
:param x:float, �������ֵ�ĸ�˹����
:param mean:float,x��ƽ��ֵ
:param stdev:float,x�ı���
:return: None
"""
exponent = exp(-((x-mean)**2 / (2 * stdev**2 )))
return (1 / (sqrt(2 * pi) * stdev)) * exponent
# ����ÿ�еĸ���
def converge_probabilities(summaries, row):
# �������з���ĸ���
total_rows = sum([summaries[label][0][2] for label in summaries])
probabilities = dict()
for class_value, class_summaries in summaries.items():
# �������ĸ���,������������ܷ�������ʶ���
# ��ʽ�е�P(class)
probabilities[class_value] = summaries[class_value][0][2]/float(total_rows)
# ͨ����ʽ P(X1|class=0) * P(X2|class=0) * P(class=0) �����˹����
for i in range(len(class_summaries)):
mean, stdev, _ = class_summaries[i]
probabilities[class_value] *= calculate_probability(row[i], mean, stdev)
return probabilities
# ͨ�����������ֵ,Ԥ��û������ĸ�Ʒ��,ȡ��˹��������ֵ
def predict(summaries, row):
probabilities = converge_probabilities(summaries, row)
best_label, best_prob = None, -1
for class_value, probability in probabilities.items():
if best_label is None or probability > best_prob:
best_prob = probability
best_label = class_value
return best_label
# Naive Bayes Algorithm
def naive_bayes(train, test):
# ѵ�����ݰ������������
summarize = summarize_by_class(train)
predictions = list()
for row in test:
output = predict(summarize, row)
predictions.append(output)
print(predictions)
return(predictions)
# ����
if __name__ == '__main__':
seed(1)
filename = 'iris.csv'
dataset = load_csv(filename)
# ת����ֵΪfloat
for i in range(len(dataset[0])-1):
str_column_to_float(dataset, i)
# ������ת��Ϊ����
str_column_to_int(dataset, len(dataset[0])-1)
# �����������ݼ�����
model = summarize_by_class(dataset)
# �¼�һ��Ԥ������
row = [5.3,3.9,3.2,2.3]
# ����ѵ�������ж�����Ԥ��
label = predict(model, row)
print('Data=%s, Predicted: %s' % (row, label))

���Կ��������ݼ� [5.3,3.9,3.2,2.3] Ԥ��Ϊ versicolor,�ǽ�������Ϊ,[2.3,0.9,0.2,1.3] Ԥ����Ϊ setosa

����һЩС����û�и�����,Ϊʲôʵ��ʱ��Ҫʡ�Ե�����
Reference

