ФПТМ
ВЙГфжЊЪЖЕу:pandasПтжаЕФreplace()КЏЪ§
ВЙГфжЊЪЖЕу:ЪЙгУIVжЕЖјВЛжБНгЪЙгУWOEжЕЕФдвђ
6.3.2?ЭГМЦИїИіЗжЯфЕФбљБОзмЪ§ЁЂЛЕбљБОЪ§КЭКУбљБОЪ§
6.3.3?ЭГМЦИїЗжЯфЕФЛЕбљБОБШТЪКЭКУбљБОБШТЪ
6.4?АИР§:ПЭЛЇСїЪЇдЄОЏФЃаЭЕФIVжЕМЦЫу
1 МђНщ
дкЪЕМЪЙЄзїжаЛёШЁЕНЕФЪ§ОнЭљЭљВЛФЧУДРэЯы,ПЩФмЛсДцдкЗЧЪ§жЕРраЭЕФЮФБОЪ§ОнЁЂжиИДжЕЁЂШБЪЇжЕЁЂвьГЃжЕМАЪ§ОнЗжВМВЛОљКтЕШЮЪЬт,вђДЫ,дкНјааЪ§бЇНЈФЃЧАЛЙашвЊЖдетаЉЮЪЬтНјааДІРэ,етЯюЙЄзїГЦЮЊЬиеїЙЄГЬЁЃ
ЬиеїЙЄГЬЭЈГЃЗжЮЊЬиеїЪЙгУЗНАИЁЂЬиеїЛёШЁЗНАИЁЂЬиеїДІРэЁЂЬиеїМрПиМИДѓВПЗж,ЦфжаЬиеїДІРэЪЧЬиеїЙЄГЬЕФКЫаФФкШн,гаЪБГЦЮЊЪ§ОндЄДІРэЁЃ

2 ЗЧЪ§жЕРраЭЪ§ОнДІРэ
ЛњЦїбЇЯАНЈФЃЪБДІРэЕФЖМЪЧЪ§жЕРраЭЕФЪ§Он,ШЛЖјЪЕМЪЙЄзїжаЛёШЁЕФЪ§ОнЭљЭљЛсАќКЌЗЧЪ§жЕРраЭЕФЪ§Он,ЦфжазюГЃМћЕФОЭЪЧЮФБОРраЭЕФЪ§Он,Р§Шч,адБ№жаЕФЁАФаЁБКЭЁАХЎЁБ,ДІРэЪБПЩвдгУВщевЁЂЬцЛЛЕФЫМТЗ,ЗжБ№зЊЛЛЮЊЪ§зж1КЭ0ЁЃЕЋШчЙћРрБ№гаКмЖр,гжИУШчКЮДІРэФи?
НщЩмPythonжаСНжжГЃгУЕФЗЧЪ§жЕРраЭЪ§ОнДІРэЗНЗЈЁЊЁЊGet_dummiesбЦБфСПДІРэКЭLabel EncodingБрКХДІРэЁЃ
2.1 Get_dummiesбЦБфСПДІРэ
бЦБфСПвВНаащФтБфСП,ЭЈГЃШЁжЕЮЊ0Лђ1,ЩЯУцЬсЕНЕФНЋадБ№жаЕФЁАФаЁБКЭЁАХЎЁБЗжБ№зЊЛЛГЩЪ§зж1КЭ0ОЭЪЧбЦБфСПзюОЕфЕФгІгУЁЃ
дкPythonжа,ЭЈГЃРћгУpandasПтжаЕФget_dummies()КЏЪ§НјаабЦБфСПДІРэ,ЫќВЛНіПЩвдДІРэЁАФаЁБКЭЁАХЎЁБетжжжЛгаСНИіЗжРрЕФМђЕЅЮЪЬт,ЛЙПЩвдДІРэКЌгаЖрИіЗжРрЕФЮЪЬтЁЃ
ЯТУцЭЈЙ§СНИіЪОР§бнЪОget_dummies()КЏЪ§ЕФЛљБОгУЗЈЁЃ
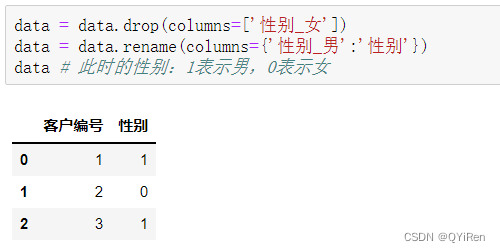
1.МђЕЅЕФЪОР§:ЁАФаЁБКЭЁАХЎЁБЕФЪ§жЕзЊЛЛ
ГѕЪМЪ§ОнШчЯТЫљЪО:

НгзХгУget_dummies()КЏЪ§ЖдЮФБОРраЭЕФЪ§ОнНјааДІРэ:

ЛёЕУЕФаТЪ§ОнЕФФкШнМћЩЯБэЁЃПЩвдПДЕН,дРДЕФЁАадБ№ЁБСаБфЮЊЁАадБ№_ХЎЁБКЭЁАадБ№_ФаЁБСНСа,етСНСажаЕФЪ§зж1БэЪОЗћКЯСаУћ,Ъ§зж0БэЪОВЛЗћКЯСаУћЁЃ
ЕЅЖРПДЁАадБ№_ХЎЁБетвЛСаОЭЪЧ:Ъ§зж0ДњБэФа,Ъ§зж1ДњБэХЎЁЃ
ЕЅЖРПДЁАадБ№_ФаЁБетвЛСаОЭЪЧ:Ъ§зж0ДњБэХЎ,Ъ§зж1ДњБэФаЁЃ
ЫљвджЎКѓашвЊЕФВйзїОЭЪЧЩОГ§ЦфжавЛСаВЂжиУќУћСэвЛСа:
2.ЩдИДдгЕФЪОР§:ЗПЮнГЏЯђЕФЪ§жЕзЊЛЛ
ЗПЮнГЏЯђЕФЪ§жЕзЊЛЛЁЃЯШЭЈЙ§ШчЯТДњТыЙЙдьбнЪОЪ§ОнЁЃ

гУget_dummies()КЏЪ§ЙЙдьбЦБфСП,ДњТыШчЯТЁЃ

ЭЌбљДцдкЖржиЙВЯпад(МДИљОн3ИіГЏЯђЕФЪ§зжОЭФмХаЖЯЕк4ИіГЏЯђЕФЪ§зжЪЧ0ЛЙЪЧ1),вђДЫашвЊДгаТЙЙдьГіРДЕФ4ИібЦБфСПжаЩОШЅ1Иі,МйЩшЩОШЅЁАГЏЯђ_ЮїЁБСа,ДњТыШчЯТЁЃ

етбљБуЭЈЙ§бЦБфСПДІРэНЋЗжРрБфСПзЊЛЏЮЊЪ§жЕБфСП,ЮЊКѓајЙЙНЈФЃаЭДђКУСЫЛљДЁЁЃЙЙдьбЦБфСПШнвзВњЩњИпЮЌЪ§Он,вђДЫ,бЦБфСПГЃКЭPCA(жїГЩЗжЗжЮі)вЛЦ№ЪЙгУ,МДЙЙдьбЦБфСПВњЩњИпЮЌЪ§ОнКѓВЩгУPCAНјааНЕЮЌЁЃ
2.2?Label EncodingБрКХДІРэ
Г§СЫЪЙгУget_dummies()КЏЪ§НјааЗЧЪ§жЕРраЭЪ§ОнДІРэЭт,ЛЙПЩвдЪЙгУLabelEncodingНјааБрКХДІРэ,ОпЬхРДЫЕ,ЪЧЪЙгУLabelEncoder()КЏЪ§НЋЮФБОРраЭЕФЪ§ОнзЊЛЛГЩЪ§зжЁЃ
ЪОР§:

ЭЈЙ§ШчЯТДњТыМДПЩНЋЁАГЧЪаЁБСаЕФЮФБОФкШнзЊЛЛЮЊВЛЭЌЕФЪ§зжЁЃ

ПЩвдПДЕН,ЁАББОЉЁББЛзЊЛЛГЩЪ§зж1,ЁАЩЯКЃЁББЛзЊЛЛГЩЪ§зж0,ЁАЙужнЁББЛзЊЛЛГЩЪ§зж2,ЁАЩюлкЁББЛзЊЛЛГЩЪ§зж3ЁЃ
ЭЈЙ§ШчЯТДњТыПЩвдгУзЊЛЛНсЙћЬцЛЛдРДЕФСаФкШнЁЃ

ЩЯЪіЪОР§жаЪЙгУLabel EncodingДІРэКѓВњЩњСЫвЛИіЦцЙжЕФЯжЯѓ:ЩЯКЃКЭЙужнЕФЦНОљжЕЪЧББОЉ,етИіЯжЯѓЦфЪЕЪЧУЛгаЯжЪЕвтвхЕФ,етвВЪЧLabel EncodingЕФвЛИіШБЕуЁЊЁЊПЩФмЛсВњЩњвЛаЉУЛгавтвхЕФЙиЯЕЁЃВЛЙ§ЪїФЃаЭ(ШчОіВпЪїЁЂЫцЛњЩСжМАXGBoostЕШМЏГЩЫуЗЈ)ФмКмКУЕиДІРэетжжзЊЛЏ,вђДЫЖдгкЪїФЃаЭРДЫЕ,етжжЦцЙжЕФЯжЯѓЪЧВЛЛсгАЯьНсЙћЕФЁЃ
ВЙГфжЊЪЖЕу:pandasПтжаЕФreplace()КЏЪ§
LabelEncoder()КЏЪ§ЩњГЩЕФЪ§зжЪЧЫцЛњЕФ,ШчЙћЯыАДЬиЖЈФкШнНјааЬцЛЛ,ПЩвдЪЙгУreplace()КЏЪ§ЁЃетСНжжДІРэЗНЪНЖдгкНЈФЃаЇЙћВЛЛсгаЬЋДѓгАЯьЁЃ

дкЪЙгУreplace()КЏЪ§жЎЧА,ЯШРћгУvalue_counts()КЏЪ§ВщПДЁАГЧЪаЁБСагаФФаЉФкШнашвЊЬцЛЛ(вђЮЊгаЪБЪ§ОнСПКмДѓ,ЭЈЙ§ШЫблХаЖЯПЩФмЛсвХТЉФГаЉФкШн),ДњТыШчЯТЁЃ

гУreplace()КЏЪ§АДЁАББЩЯЙуЩюЁБЕФЫГађНјааЪ§зжБрКХ,ДњТыШчЯТЁЃ

ПЩвдПДЕН,LabelEncoder()КЏЪ§ЪЧЖдЮФБОФкШнНјааЫцЛњБрКХ,ЖјгУreplace()КЏЪ§ПЩНЋЮФБОФкШнЬцЛЛГЩздЖЈвхЕФжЕЁЃВЛЙ§ЕБЗжРрНЯЖрЪБ,ЛЙашвЊЯШгУvalue_counts()КЏЪ§ЛёШЁУПИіЗжРрЕФУћГЦ,ВНжшЛсЩдЮЂЗГЫівЛаЉЁЃ
змНс:
змНсРДЫЕ,Get_dummiesЕФгХЕуЪЧЫќЕФжЕжЛга0КЭ1,ШБЕуЪЧЕБРрБ№ЕФЪ§СПКмЖрЪБ,ЬиеїЮЌЖШЛсКмИп,ДЫЪБПЩвдХфКЯЪЙгУPCA(жїГЩЗжЗжЮі)РДМѕЩйЮЌЖШЁЃШчЙћРрБ№Ъ§СПВЛЖр,ПЩвдгХЯШПМТЧЪЙгУGet_dummies,ЦфДЮПМТЧЪЙгУLabel EncodingЛђreplace()КЏЪ§;ЕЋШчЙћЪЧЛљгкЪїФЃаЭЕФЛњЦїбЇЯАФЃаЭ,гУLabelEncodingвВУЛгаЬЋДѓЙиЯЕЁЃ
3?жиИДжЕЁЂШБЪЇжЕМАвьГЃжЕДІРэ
3.1?жиИДжЕДІРэ
ГѕЪМЪ§Он:

жиИДжЕЯрЙиВйзї:
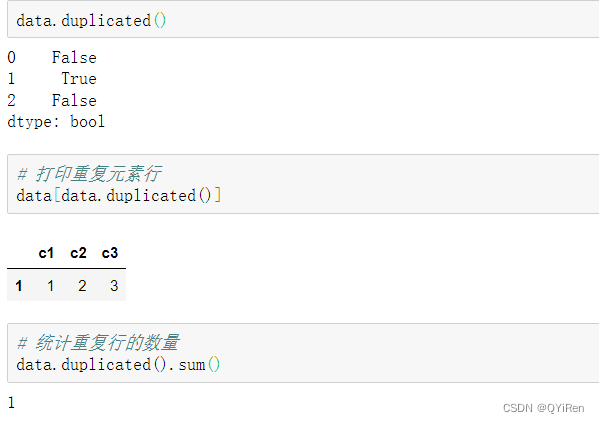
ЩОГ§жиИДаа,зЂвт,drop_duplicates()КЏЪ§ВЂВЛИФБфдБэИёНсЙЙ,ЫљвдашвЊНјаажиаТИГжЕ,ЛђепдкЦфжаЩшжУinplaceВЮЪ§ЮЊTrueЁЃ

3.2?ШБЪЇжЕДІРэ
ГѕЪМЪ§Он:
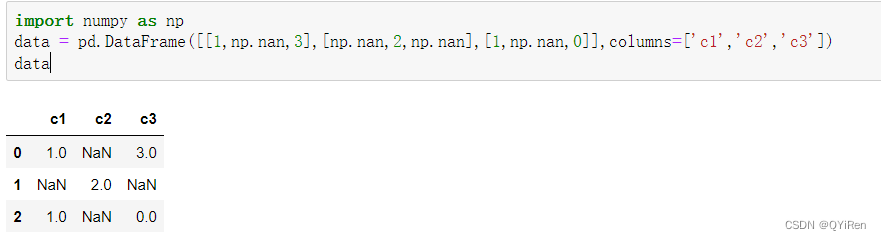
гУisnull()КЏЪ§Лђisna()КЏЪ§(СНепзїгУРрЫЦ)РДВщПДПежЕ,ДњТыШчЯТЁЃ

ЖдЕЅСаВщПДПежЕ,ДњТыШчЯТЁЃ

ШчЙћЪ§ОнСПНЯДѓ,ПЩвдЭЈЙ§ШчЯТДњТыЩИбЁГіФГСажаФкШнЮЊПежЕЕФааЁЃ
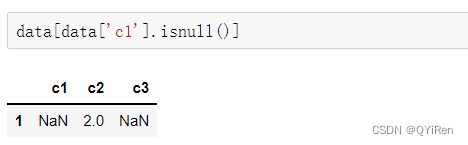
ЖдгкПежЕгаСНжжГЃМћЕФДІРэЗНЪН:ЩОГ§ПежЕКЭЬюВЙПежЕЁЃ
гУdropna()КЏЪ§ПЩвдЩОГ§ПежЕ,ДњТыШчЯТЁЃ

етжжЩОГ§ЗНЗЈЪЧжЛвЊКЌгаПежЕЕФааЖМЛсБЛЩОГ§ЁЃдЫааНсЙћШчЯТ,ПЩвдПДЕН,вђЮЊУПааЖМгаПежЕ,ЫљвдЖМБЛЩОГ§СЫЁЃ
ПЩвдЩшжУthreshВЮЪ§,Р§ШчНЋЦфЩшжУЮЊn,БэЪОШчЙћвЛаажаЕФЗЧПежЕЩйгкnИідђЩОГ§ИУаа,бнЪОДњТыШчЯТЁЃ

ИУДњТыЕФКЌвхЪЧ:ШчЙћвЛаажаЕФЗЧПежЕЩйгк2ИідђЩОГ§ИУааЁЃЙЙдьЕФбнЪОЪ§Онжа,Ек1ааКЭЕк3ааЖМга2ИіЗЧПежЕ,вђДЫВЛЛсБЛЩОГ§,ЖјЕк2аажЛга1ИіЗЧПежЕ,Щйгк2Иі,вђДЫЛсБЛЩОГ§ЁЃ
гУfillna()КЏЪ§ПЩвдЬюВЙПежЕ,бнЪОДњТыШчЯТЁЃетРяВЩгУЕФЪЧОљжЕЬюВЙЗЈ,гУУПСаЕФОљжЕЖдИУСаЕФПежЕНјааЬцЛЛ,вВПЩвдАбЦфжаЕФdata.mean()ЛЛГЩdata.median(),БфЮЊжаЮЛЪ§ЬюВЙЁЃ

ПежЕЬюВЙЛЙПЩвдВЩШЁгУПежЕЩЯЗНЛђЯТЗНЕФжЕЬцЛЛПежЕЕФЗНЪН,бнЪОДњТыШчЯТЁЃ
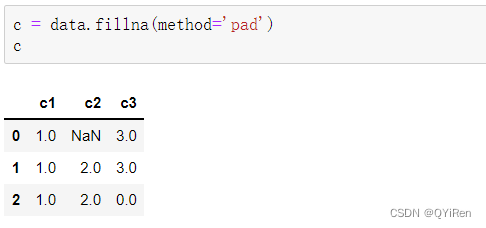
ДЫДІЕФmethod='pad'БэЪОгУПежЕЩЯЗНЕФжЕРДЬцЛЛПежЕ,ШчЙћЩЯЗНЕФжЕВЛДцдкЛђвВЮЊПежЕ,дђВЛЬцЛЛЁЃ
ЛЙПЩвдЩшжУmethod='backfill'Лђmethod='bfill'(СНепаЇЙћвЛбљ),БэЪОгУПежЕЯТЗНЕФжЕРДЬцЛЛПежЕ,ШчЙћЯТЗНЕФжЕВЛДцдкЛђвВЮЊПежЕ,дђВЛЬцЛЛ,ДњТыШчЯТЁЃ
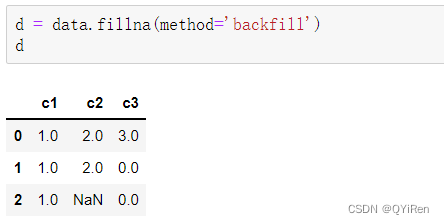
3.3?вьГЃжЕДІРэ
ГѕЪМЪ§Он:
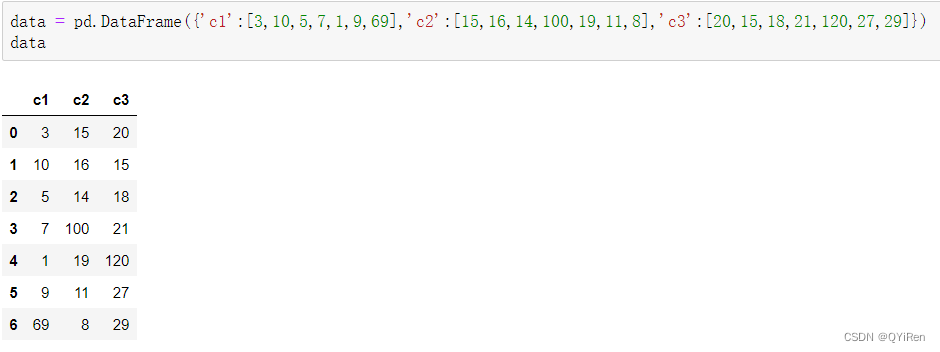
ПЩвдПДЕН,Ек1СаЕФЪ§зж69ЁЂЕк2СаЕФЪ§зж100ЁЂЕк3СаЕФЪ§зж120ЮЊБШНЯУїЯдЕФвьГЃжЕ,ФЧУДИУШчКЮРћгУPythonМьВтвьГЃжЕФи?
НщЩмСНжжМьВтЗНЗЈЁЊЁЊРћгУЯфЬхЭМЙлВьКЭРћгУБъзМВюМьВтЁЃ
1.РћгУЯфЬхЭМЙлВь
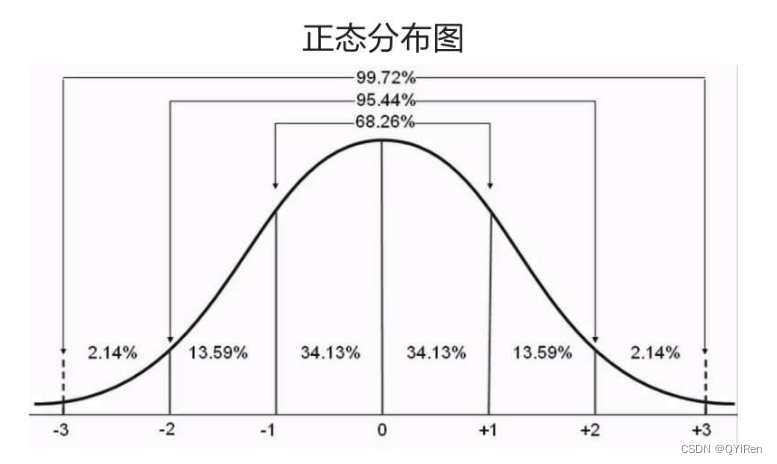
ЯфЬхЭМЪЧвЛжжгУгкЯдЪОвЛзщЪ§ОнЗжЩЂЧщПізЪСЯЕФЭГМЦЭМ,ПЩвдЭЈЙ§ЩшЖЈБъзМ,НЋДѓгкЛђаЁгкЯфЬхЭМЩЯЯТНчЕФЪ§жЕЪЖБ№ЮЊвьГЃжЕЁЃ
ШчЯТЭМЫљЪО,НЋЪ§ОнЕФЯТЫФЗжЮЛЪ§МЧЮЊQ1,МДбљБОжаНіга25%ЕФЪ§ОнаЁгкQ1;НЋЪ§ОнЕФЩЯЫФЗжЮЛЪ§МЧЮЊQ3,МДбљБОжаНіга25%ЕФЪ§ОнДѓгкQ3;НЋЩЯЫФЗжЮЛЪ§КЭЯТЫФЗжЮЛЪ§ЕФВюжЕМЧЮЊIQR,МДIQR=Q3-Q1;СюЯфЬхЭМЩЯНчЮЊQ3+1.5ЁСIQR,ЯТНчЮЊQ1-1.5ЁСIQRЁЃ

дкPythonжаПЩвдгУDataFrameЕФboxplot()КЏЪ§ЛцжЦЯфЬхЭМ,ДњТыШчЯТЁЃ
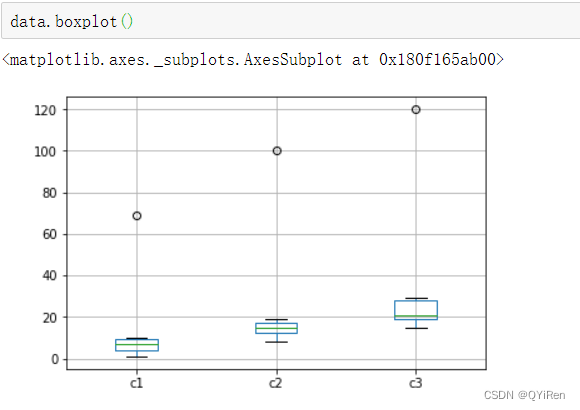
ПЩвдУїЯдПДЕНУПСаЪ§ОнИїгавЛИівьГЃжЕЁЃ
2.РћгУБъзМВюМьВт
ЕБЪ§ОнЗўДгБъзМе§ЬЌЗжВМЪБ,99%ЕФЪ§жЕгыОљжЕЕФОрРыгІИУдк3ИіБъзМВюжЎФк,95%ЕФЪ§жЕгыОљжЕЕФОрРыгІИУдк2ИіБъзМВюжЎФк,ШчЯТЭМЫљЪОЁЃвђЮЊ3ИіБъзМВюЙ§гкбЯИё,ДЫДІНЋуажЕЩшЖЈЮЊ2ИіБъзМВю,МДШЯЮЊЕБЪ§жЕгыОљжЕЕФОрРыГЌГі2ИіБъзМВю,дђПЩвдШЯЮЊЫќЪЧвьГЃжЕЁЃ
ИљОнБъзМВюМьВтвьГЃжЕЕФДњТыШчЯТЁЃ

Ек1ааДњТыНЈСЂвЛИіПеDataFrame;
Ек2ааДњТыЭЈЙ§forбЛЗвРДЮЖдЪ§ОнЕФУПСаНјааВйзї;
Ек3ааДњТыгУmean()КЏЪ§(ЛёШЁОљжЕ)КЭstd()КЏЪ§(ЛёШЁБъзМВю)НЋУПСаЪ§ОнНјааZ-scoreБъзМЛЏ;
Ек4ааДњТыНјааТпМХаЖЯ,ШчЙћZ-scoreБъзМЛЏКѓЕФЪ§жЕДѓгкБъзМе§ЬЌЗжВМЕФБъзМВю1ЕФ2БЖ,ФЧУДИУЪ§жЕЮЊвьГЃжЕ,ЗЕЛиВМЖћжЕTrue,ЗёдђЗЕЛиВМЖћжЕFalseЁЃ
Z-scoreБъзМЛЏЙЋЪНШчЯТЁЃ
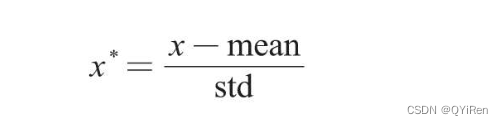
МьВтЕНвьГЃжЕКѓ,ШчЙћвьГЃжЕНЯЩйЛђгАЯьВЛДѓ,вВПЩвдВЛДІРэЁЃШчЙћашвЊДІРэ,ПЩвдВЩгУШчЯТМИжжГЃМћЕФЗНЪН:
ЁЄЩОГ§КЌгавьГЃжЕЕФМЧТМ;
ЁЄНЋвьГЃжЕЪгЮЊШБЪЇжЕ;
ЁЄРћгУЕк5НкНВНтЕФЪ§ОнЗжЯфЗНЗЈНјааДІРэЁЃ
4?Ъ§ОнБъзМЛЏ
Ъ§ОнБъзМЛЏ(вВГЦЮЊЪ§ОнЙщвЛЛЏ),ЫќЕФжївЊФПЕФЪЧЯћГ§ВЛЭЌЬиеїБфСПСПИйМЖБ№ЯрВюЬЋДѓдьГЩЕФВЛРћгАЯьЁЃ
ЖдгквдЬиеїОрРыЮЊЫуЗЈЛљДЁЕФЛњЦїбЇЯАЫуЗЈ(ШчKНќСкЫуЗЈ),Ъ§ОнБъзМЛЏгШЮЊживЊЁЃ
4.1?min-maxБъзМЛЏ
min-maxБъзМЛЏ(Min-Max Normalization)вВГЦРыВюБъзМЛЏ,ЫќРћгУдЪМЪ§ОнЕФзюДѓжЕКЭзюаЁжЕАбдЪМЪ§ОнзЊЛЛЕН[0,1]ЧјМфФк,зЊЛЛЙЋЪНШчЯТЁЃ
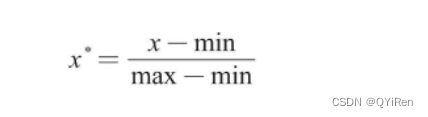
ЦфжаxЁЂx*ЗжБ№ЮЊзЊЛЛЧАКЭзЊЛЛКѓЕФжЕ,maxЁЂminЗжБ№ЮЊдЪМЪ§ОнЕФзюДѓжЕКЭзюаЁжЕЁЃ
Р§Шч,вЛИібљБОМЏжазюДѓжЕЮЊ100,зюаЁжЕЮЊ40,ШєДЫЪБxЮЊ50,дђmin-maxБъзМЛЏКѓЕФжЕШчЯТЁЃ
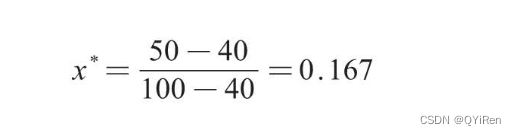
ДњТыбнЪО:

ЦфжаЕк1СаЮЊЁАОЦОЋКЌСПЁББъзМЛЏКѓЕФжЕ,Ек2СаЮЊЁАЦЛЙћЫсКЌСПЁББъзМЛЏКѓЕФжЕ,ПЩвдПДЕНЫќУЧЖМдк[0,1]ЧјМфФкЁЃ
дкЪЕМЪгІгУжа,ЭЈГЃНЋЫљгаЪ§ОнЖМБъзМЛЏКѓ,дйНјаабЕСЗМЏКЭВтЪдМЏЛЎЗжЁЃ
4.2 Z-scoreБъзМЛЏ
Z-scoreБъзМЛЏ(Mean Normaliztion)вВГЦОљжЕЙщвЛЛЏ,ЭЈЙ§дЪМЪ§ОнЕФОљжЕ(mean)КЭБъзМВю(standard deviation)ЖдЪ§ОнНјааБъзМЛЏЁЃБъзМЛЏКѓЕФЪ§ОнЗћКЯБъзМе§ЬЌЗжВМ,МДОљжЕЮЊ0,БъзМВюЮЊ1ЁЃзЊЛЛЙЋЪНШчЯТЁЃ
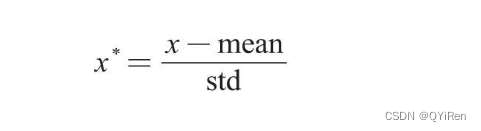
ЦфжаxКЭx*ЗжБ№ЮЊзЊЛЛЧАКЭзЊЛЛКѓЕФжЕ,meanЮЊдЪМЪ§ОнЕФОљжЕ,stdЮЊдЪМЪ§ОнЕФБъзМВюЁЃ
ДњТыбнЪО:

ЦфжаЕк1СаЮЊЁАОЦОЋКЌСПЁББъзМЛЏКѓЕФжЕ,Ек2СаЮЊЁАЦЛЙћЫсКЌСПЁББъзМЛЏКѓЕФжЕ,ДЫЪБЫќУЧЪЧОљжЕЮЊ0ЁЂБъзМВюЮЊ1ЕФБъзМе§ЬЌЗжВМЁЃ
змНсРДЫЕ,Ъ§ОнБъзМЛЏВЂВЛИДдг,СНШ§ааДњТыОЭФмБмУтКмЖрЮЪЬт,вђДЫ,ЖдвЛаЉСПИйЯрВюНЯДѓЕФЬиеїБфСП,ЪЕеНжаЭЈГЃЛсЯШНјааЪ§ОнБъзМЛЏ,дйНјаабЕСЗМЏКЭВтЪдМЏЛЎЗжЁЃ
Г§СЫKНќСкЫуЗЈФЃаЭ,ЛЙгавЛаЉФЃаЭвВЪЧЛљгкОрРыЕФ,ЫљвдСПИйЖдФЃаЭгАЯьНЯДѓ,ОЭашвЊНјааЪ§ОнБъзМЛЏ,ШчжЇГжЯђСПЛњФЃаЭЁЂKMeansОлРрЗжЮіЁЂPCA(жїГЩЗжЗжЮі)ЕШЁЃДЫЭт,ЖдгквЛаЉЯпадФЃаЭ,ШчЯпадЛиЙщФЃаЭКЭТпМЛиЙщФЃаЭ,гаЪБвВашвЊНјааЪ§ОнБъзМЛЏДІРэЁЃ
ЖдгкЪїФЃаЭдђЮоаызіЪ§ОнБъзМЛЏДІРэ,вђЮЊЪ§жЕЫѕЗХВЛгАЯьЗжСбЕуЮЛжУ,ЖдЪїФЃаЭЕФНсЙЙВЛдьГЩгАЯьЁЃвђДЫ,ОіВпЪїФЃаЭМАЛљгкОіВпЪїФЃаЭЕФЫцЛњЩСжФЃаЭЁЂAdaBoostФЃаЭЁЂGBDTФЃаЭЁЂXGBoostФЃаЭЁЂLightGBMФЃаЭЭЈГЃЖМВЛашвЊНјааЪ§ОнБъзМЛЏДІРэ,вђЮЊЫќУЧВЛЙиаФБфСПЕФжЕ,ЖјЪЧЙиаФБфСПЕФЗжВМКЭБфСПжЎМфЕФЬѕМўИХТЪЁЃ
дкЪЕМЪЙЄзїжа,ШчЙћВЛШЗЖЈЪЧЗёвЊзіЪ§ОнБъзМЛЏ,ПЩвдЯШГЂЪдзівЛзіЪ§ОнБъзМЛЏ,ПДПДФЃаЭдЄВтзМШЗЖШЪЧЗёгаЬсЩ§,ШчЙћЬсЩ§НЯУїЯд,дђЭЦМіНјааЪ§ОнБъзМЛЏЁЃ
5?Ъ§ОнЗжЯф
Ъ§ОнЗжЯфОЭЪЧНЋвЛИіСЌајаЭБфСПРыЩЂЛЏ,ПЩЗжЮЊЕШПэЗжЯфКЭЕШЩюЗжЯфЁЃ
ЕШПэЗжЯфЪЧжИУПИіЗжЯфЕФВюжЕЯрЕШ,вдЁАФъСфЁБетвЛСЌајаЭЬиеїБфСПЮЊР§,ЦфШЁжЕЗЖЮЇЮЊ0~100ЕФСЌајЪ§жЕ,ПЩвдНЋЁАФъСфЁБЗжЮЊ0~20ЁЂ20~40ЁЂ40~60ЁЂ60~80ЁЂ80~100ЙВ5ИіЗжЯф,ет5ИіЗжЯфОЭПЩвдЕБГЩРыЩЂЕФЗжРрБфСП,УПИіЗжЯфЕФФъСфВюЯрЕШ(ЖМЯрВю20Ыъ)ЁЃ
ЕШЩюЗжЯфЪЧжИУПИіЗжЯфжаЕФбљБОЪ§вЛжТ,ЭЌбљАДЁАФъСфЁБетвЛЬиеїБфСПНјааЗжЯф,Р§Шч,500ИібљБОЗжГЩ5Яф,ФЧУДУПИіЗжЯфжаЖМЪЧ100ШЫ,ДЫЪБЖдгІЕФ5ИіЗжЯфПЩФмОЭЪЧ0~20ЁЂ20~25ЁЂ25~30ЁЂ30~50ЁЂ50~100,ШЗБЃУПИіЗжЯфжаЕФШЫЪ§вЛжТЁЃ
ЕШПэЗжЯф,ЪЙгУpandasжаЕФcutКЏЪ§:

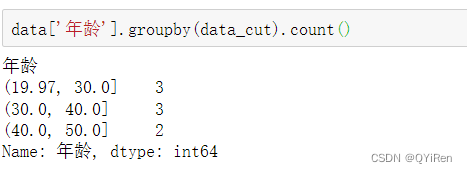
ЁАФъСфЁБСажаЪ§ОнЕФЗЖЮЇЪЧ20~50Ыъ,ЗжЮЊ3зщЧЁКУЮЊ20~30Ыъ(19.97НќЫЦЮЊ20)ЁЂ30~40ЫъЁЂ40~50Ыъ,ПЩвдПДЕН,УПИіЗжЯфЕФФъСфВюЖМЪЧ10Ыъ,етОЭЪЧЕШПэЗжЯфЁЃ
гУgroupby()КЏЪ§НјааЗжзщ,гУcount()КЏЪ§НјааМЦЪ§,ПЩвдЛёШЁУПИіЗжЯфжаЕФбљБОЪ§,ДњТыШчЯТЁЃ
ЖдЬиеїБфСПФъСфНјааРыЩЂЛЏПЩвдЪЙНЈСЂЕФФЃаЭИќЮШЖЈ,Р§Шч,НЋ20~30ЫъзїЮЊвЛИіРрБ№,ШчЙћПЭЛЇДг25ЫъдіГЄЮЊ26Ыъ,вВВЛЛсвђДЫГЩЮЊЭъШЋВЛЭЌРрБ№ЕФШЫЁЃЕЋЪЧ,ФъСфЮЛгкРрБ№ЧјМфБпНчЕуЕФПЭЛЇдђЛсвђЮЊдіГЄ1ЫъЖјБЛЗжЕНСэвЛИіРрБ№,вђДЫ,дкЗжЯфЪБвЊНїЩїбЁШЁРрБ№МфЕФНчЯоЁЃ
Ъ§ОнЗжЯфЛЙгавЛИіКУДІОЭЪЧПЩвдЬоГ§вьГЃжЕЕФгАЯь,вВЪЧвьГЃжЕДІРэЕФвЛИіЪжЖЮЁЃ
6?ЬиеїЩИбЁ:WOEжЕгыIVжЕ
дкЪЙгУТпМЛиЙщЁЂОіВпЪїЕШФЃаЭЫуЗЈЙЙНЈЗжРрФЃаЭЪБ,ОГЃашвЊЖдЬиеїБфСПНјааЩИбЁЁЃвђЮЊгаЪБПЩФмЛсЛёЕУ100ЖрИіКђбЁЬиеїБфСП,ЭЈГЃВЛЛсжБНгАбетаЉЬиеїБфСПЗХЕНФЃаЭжаШЅНјааФтКЯбЕСЗ,ЖјЪЧДгетаЉЬиеїБфСПжаЬєбЁвЛаЉЗХНјФЃаЭ,ЙЙГЩШыФЃБфСПСаБэЁЃФЧУДИУШчКЮЬєбЁШыФЃБфСПФи?
ЬєбЁШыФЃБфСПашвЊПМТЧКмЖрвђЫи,ШчБфСПЕФдЄВтФмСІЁЂМђЕЅад(ШнвзЩњГЩКЭЪЙгУ)ЁЂПЩНтЪЭадЕШЁЃЦфжазюжївЊЕФКтСПБъзМЪЧБфСПЕФдЄВтФмСІ,ЖдЗжРрФЃаЭРДЫЕ,МДЯЃЭћБфСПОпгаНЯКУЕФЬиеїЧјЗжЖШ,ПЩвдНЯзМШЗЕиНЋбљБОНјааЗжРрЁЃ
WOEжЕКЭIVжЕОЭЪЧетбљЕФжИБъ,ЫќУЧПЩвдгУРДКтСПЬиеїБфСПЕФдЄВтФмСІ,ЛђепЫЕЬиеїБфСПЕФЬиеїЧјЗжЖШ,РрЫЦЕФжИБъЛЙгаЛљФсЯЕЪ§КЭаХЯЂдівцЁЃЖдгкОіВпЪїЕШЪїФЃаЭРДЫЕ,ПЩвдЭЈЙ§ЛљФсЯЕЪ§ЛђаХЯЂдівцРДКтСПБфСПЕФЬиеїЧјЗжЖШ,ЖјЖдгкТпМЛиЙщЕШУЛгаЛљФсЯЕЪ§ЕШжИБъЕФФЃаЭЖјбд,ПЩвдЭЈЙ§WOEжЕКЭIVжЕНјааБфСПбЁдёЁЃ
IVжЕЕФМЦЫуЪЧвдWOEжЕЮЊЛљДЁЕФ,ЖјвЊМЦЫувЛИіБфСПЕФWOEжЕ,ашвЊЯШгУЩЯвЛНкЫљНВЕФжЊЪЖЖдетИіБфСПНјааЗжЯфДІРэЁЃ
6.1?WOEжЕЕФЖЈвхгыМЦЫу
WOEЪЧWeight of Evidence(жЄОнШЈжи)ЕФЫѕаД,ЦфЗДгГСЫФГвЛБфСПЕФЬиеїЧјЗжЖШЁЃ
вЊМЦЫувЛИіБфСПЕФWOEжЕ,ашвЊЯШЖдетИіБфСПНјааЗжЯфДІРэЁЃ
ЗжЯфКѓ,ЕкiИіЗжЯфФкЪ§ОнЕФWOEжЕЕФМЦЫуЙЋЪНШчЯТЁЃ

вдПЭЛЇЮЅдМдЄВтФЃаЭ(дЄВтПЭЛЇЪЧЗёЛсЮЅдМ)ЮЊР§РДНтЪЭИїИіБфСПЕФКЌвх:
ЪЧЕкiИіЗжЯфжаЮЅдМПЭЛЇ(МДФЃаЭжаФПБъБфСПЁАЪЧЗёЮЅдМЁБШЁжЕЮЊ1ЕФИіЬх)еМећИібљБОжаЫљгаЮЅдМПЭЛЇЕФБШР§;
ЪЧЕкiИіЗжЯфжаЮДЮЅдМПЭЛЇ(МДФЃаЭжаФПБъБфСПЁАЪЧЗёЮЅдМЁБШЁжЕЮЊ0ЕФИіЬх)еМећИібљБОжаЫљгаЮДЮЅдМПЭЛЇЕФБШР§;
yiЪЧЕкiИіЗжЯфжаЮЅдМПЭЛЇЕФЪ§СП;
yTЪЧећИібљБОжаЫљгаЮЅдМПЭЛЇЕФЪ§СП;
niЪЧЕкiИіЗжЯфжаЮДЮЅдМПЭЛЇЕФЪ§СП;
nTЪЧећИібљБОжаЫљгаЮДЮЅдМПЭЛЇЕФЪ§СПЁЃ
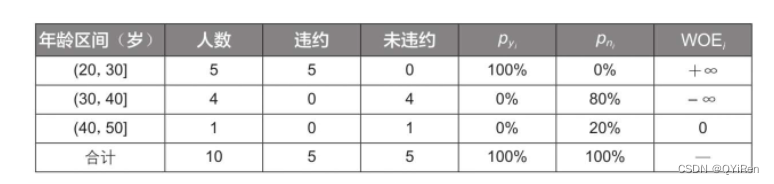
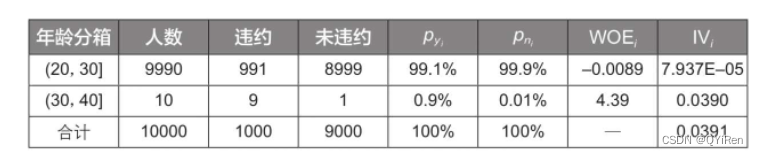
МйЩшећИібљБОжаЙВга10ИіЮЅдМПЭЛЇ(yT)ЁЂ10ИіЮДЮЅдМПЭЛЇ(nT),ШЛКѓИљОнЬиеїБфСПЁАФъСфЁБНЋећИібљБОЗжГЩ4ИіЗжЯф,ЦфжаЕк1ИіЗжЯфРяга2ИіЮЅдМПЭЛЇЁЂ2ИіЮДЮЅдМПЭЛЇ,вђДЫ,
=2/10=0.2,
=2/10=0.2,ФЧУДИУЗжЯфЕФWOEжЕЮЊln(0.2/0.2)=ln(1)=0ЁЃ
ЛЙПЩвдЖдЙЋЪННјааБфЛЛ,ЕУЕНШчЯТЙЋЪНЁЃ
БфЛЛвдКѓ,WOEжЕвВПЩвдРэНтЮЊ:ЗжЯфКѓЕкiИіЗжЯфжаЮЅдМПЭЛЇКЭЮДЮЅдМПЭЛЇЕФБШжЕгыећИібљБОжаИУБШжЕЕФВювьЁЃЦфжаећИібљБОЕФЮЅдМПЭЛЇКЭЮДЮЅдМПЭЛЇЕФБШжЕyT/nTЪЧвЛИіЙЬЖЈжЕ,ЫљвдWOEжЕЗДгГЕФОЭЪЧЗжЯфКѓЕкiИіЗжЯфжаЮЅдМПЭЛЇКЭЮДЮЅдМПЭЛЇЕФБШжЕyi/ni,етЦфЪЕОЭЗДгГСЫЬиеїЧјЗжЖШЁЃ
НЋЯТБэжаЕФЁАФъСфЁБетвЛЬиеїБфСПЗжГЩ3ИіЗжЯфКѓ,УПИіЗжЯфЕФWOEжЕЕФОјЖджЕЖМКмДѓ,ФЧУДЫЕУїЁАФъСфЁБетвЛЬиеїБфСПЕФЬиеїЧјЗжЖШКмИп,ФмКмКУЕиЧјЗжЮЅдМгыЮДЮЅдМПЭЛЇ,вђДЫетРрЮЪЬтгІИУжиЕуПМТЧЁАФъСфЁБетвЛЬиеїБфСПЁЃ
ЪЕМЪгІгУжа,вђЮЊЪ§ОнСПЭЈГЃНЯДѓ,ЫљвдВЛЬЋПЩФмГіЯжWOEжЕЮЊ+ЁоЛђ-ЁоЕФЧщПі,ШчЙћГіЯжСЫЮоЧюДѓЕФWOEжЕ,вВЪЧВЛЯЃЭћПДЕНЕФ,етбљЛсЕМжТЛљгкWOEжЕЕФIVжЕвВБфГЩЮоЧюДѓ,ВЛРћгкНјааЬиеїЩИбЁЁЃДЫЪБЕФДІРэЗНЗЈгаСНжж:ЕквЛжжЗНЗЈЪЧЖдЪ§ОнжиаТНјааИќКЯРэЕФЗжЯф,ЪЙИїИіЗжЯфЕФWOEжЕВЛдйЮоЧюДѓ;ЕкЖўжжЗНЗЈЪЧКіТдетаЉЮоЧюДѓЕФжЕ,жБНгШУЫќБфЮЊ0ЁЃ
6.2?IVжЕЕФЖЈвхгыМЦЫу
IVЪЧInformation Value(аХЯЂСП)ЕФЫѕаДЁЃ
дкНјааЬиеїЩИбЁЪБ,IVжЕФмНЯКУЕиЗДгГЬиеїБфСПЕФдЄВтФмСІ,ЬиеїБфСПЖддЄВтНсЙћЕФЙБЯздНДѓ,ЦфМлжЕОЭдНДѓ,ЖдгІЕФIVжЕОЭдНДѓ,вђДЫ,ПЩИљОнIVжЕЕФДѓаЁЩИбЁГіашвЊЕФЬиеїБфСПЁЃ
МЦЫувЛИіЬиеїБфСПЕФIVжЕЧА,ашвЊЯШМЦЫуИУБфСПИїИіЗжЯфЕФIVжЕ,МЦЫуЙЋЪНШчЯТЁЃ

ЖдИїИіЗжЯфЕФIVжЕНјааМђЕЅЧѓКЭ,ОЭЕУЕНетИіЬиеїБфСПЕФIVжЕ,МЦЫуЙЋЪНШчЯТЁЃ
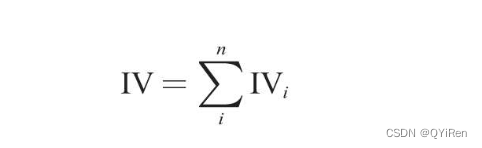
ЦфжаiЮЊЗжЯфКХ,nЮЊЗжЯфЕФзмЪ§ЁЃ
ШдШЛЪЙгУЩЯвЛаЁНкЕФбнЪОЪ§ОнЁЃЯШИљОнЩЯвЛаЁНкЕФМЦЫуНсЙћМЦЫуИїИіЗжЯфЕФIVжЕ,МЦЫуЙ§ГЬШчЯТЁЃ
гаСЫИїИіЗжЯфЕФIVжЕ,ОЭПЩвдМЦЫуГіЁАФъСфЁБетвЛЬиеїБфСПЕФIVжЕ,МЦЫуЙ§ГЬШчЯТЁЃ
ЛузмЫљгаЪ§Он,ПЩвдЕУЕНЯТБэЁЃ

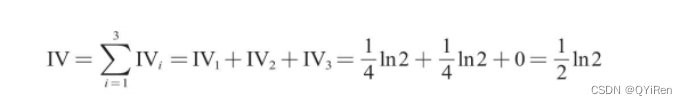

ЭЈЙ§етжжЗНЪНЖдбљБОЪ§ОнЕФУПИіЬиеїБфСПНјааIVжЕМЦЫуВЂХХађКѓ,ОЭПЩвдЛёЕУЬиеїБфСПЕФОіВпФмСІЧПШѕаХЯЂЁЃ
ВЙГфжЊЪЖЕу:ЪЙгУIVжЕЖјВЛжБНгЪЙгУWOEжЕЕФдвђ
ПЩФмЛсгавЩЮЪ:МШШЛвбОгаСЫWOEжЕ,ЮЊЪВУДЛЙвЊДДдьвЛИіIVжЕФи?жївЊдвђгаСНЗНУцЁЃ
двђ1:ШЫУЧЯАЙпгУвЛИіДѓгкЕШгк0ЕФЪ§жЕШЅКтСПдЄВтФмСІ,ЖјWOEжЕЪЧгаПЩФмЮЊИКжЕЕФЁЃ
дкМЦЫуIVжЕЪБЭЈЙ§ГЫвд![]() ,БЃжЄСЫIVжЕвЛЖЈДѓгк0ЁЃ
,БЃжЄСЫIVжЕвЛЖЈДѓгк0ЁЃ
ЖјЗжзщЕФWOEжЕЧЁКУЮЊ0ЪБ,![]() ШЁжЕвВЮЊ0,етбљОЭБЃжЄСЫIVжЕгРдЖЗЧИКЁЃ
ШЁжЕвВЮЊ0,етбљОЭБЃжЄСЫIVжЕгРдЖЗЧИКЁЃ
двђ2:ШчЙћЪЧвђЮЊЪ§жЕе§ИКЕФЮЪЬт,ФЧУДЮЊЪВУДВЛПЩвдНЋИїИіЗжЯфЕФWOEжЕЕФОјЖджЕЯрМг,зїЮЊИУЬиеїБфСПЕФећЬхWOEжЕРДКтСПдЄВтФмСІФи?етЪЧвђЮЊвд![]() зїЮЊШЈживђзгПЩвдЬхЯжЗжЯфЕФЪ§ОнСПеМећЬхЕФБШР§,ИќОЋШЗЕиЬхЯжБфСПЕФдЄВтФмСІЁЃ
зїЮЊШЈживђзгПЩвдЬхЯжЗжЯфЕФЪ§ОнСПеМећЬхЕФБШР§,ИќОЋШЗЕиЬхЯжБфСПЕФдЄВтФмСІЁЃ
Жддвђ2НјвЛВННтЪЭ:
ДгЩЯБэПЩвдПДГі,Ек1ИіЗжЯфЕФWOEжЕКмЕЭ,Ек2ИіЗжЯфЕФWOEжЕКмИп,ШчЙћНЋет2ИіWOEжЕЕФОјЖджЕЯрМг,ећЬхЕФWOEжЕЮЊ4.4,ШдШЛКмИп,етжївЊЪЧгЩЕк2ИіЗжЯфЕФWOEжЕКмИпЕМжТЕФЁЃЕЋЪЧашвЊзЂвтЕФЪЧ,Ек2ИіЗжЯфЕФзмШЫЪ§ВХ10ШЫ,еМ10000ИізмбљБОЕФБШР§жЛга0.1%,ПЩМћбљБОЪ§ОнТфдкЕк2ИіЗжЯфЕФИХТЪБОЩэОЭБШНЯЕЭ,ЫљвдЖдгкећЬхбљБОРДЫЕ,БфСПЕФдЄВтФмСІВЂУЛгаФЧУДЧПЁЃ
ЖјдкWOEжЕЕФЧАУцГЫЩЯ![]() Кѓ,ЦфЖдгІЕФIVжЕБфЕУКмЕЭ,ЯрЕБгкГЫЩЯСЫвЛИіШЈжиЯЕЪ§,МДПМТЧСЫЗжЯфЕФЪ§ОнСПеМећЬхЕФБШР§,вђДЫ,IVжЕКмКУЕиЬхЯжСЫЗжЯфБШР§ЕФгАЯьЁЃ
Кѓ,ЦфЖдгІЕФIVжЕБфЕУКмЕЭ,ЯрЕБгкГЫЩЯСЫвЛИіШЈжиЯЕЪ§,МДПМТЧСЫЗжЯфЕФЪ§ОнСПеМећЬхЕФБШР§,вђДЫ,IVжЕКмКУЕиЬхЯжСЫЗжЯфБШР§ЕФгАЯьЁЃ
вЛИіЬиеїБфСПЕФIVжЕдНИп,ЫЕУїИУЬиеїБфСПдНОпгаЧјЗжЖШЁЃВЛЙ§IVжЕвВВЛЪЧдНДѓдНКУ,ШчЙћвЛИіЬиеїБфСПЕФIVжЕДѓгк0.5,гаЪБашвЊЖдетИіЬиеїБфСПГжгавЩЮЪ,вђЮЊЫќгаЕуЙ§КУЖјЯдЕУВЛЙЛецЪЕЁЃЭЈГЃЛсбЁдёIVжЕдк0.1~0.5етИіЗЖЮЇФкЕФЬиеїБфСПЁЃВЛЭЌгІгУГЁОАЕФШЁжЕвВЛсгаЫљВЛЭЌ,Р§Шч,гааЉЗчПиЭХЖгЛсНЋIVжЕДѓгк0.5ЕФЬиеїБфСПвВФЩШыПМСП,етИіЦфЪЕвВашвЊИљОнЪЕМЪЕФНЈФЃаЇЙћРДзіНјвЛВНХаЖЯЁЃ
6.3?WOEжЕгыIVжЕЕФДњТыЪЕЯж
6.3.1?Ъ§ОнЗжЯф

6.3.2?ЭГМЦИїИіЗжЯфЕФбљБОзмЪ§ЁЂЛЕбљБОЪ§КЭКУбљБОЪ§

6.3.3?ЭГМЦИїЗжЯфЕФЛЕбљБОБШТЪКЭКУбљБОБШТЪ

6.3.4?МЦЫуWOEжЕ
РћгУЩЯЪіЙЋЪНМЦЫуЁЃ

6.3.5?МЦЫуIVжЕ

ЖдИїИіЗжЯфЕФIVжЕНјааЧѓКЭ,ЕУЕНетвЛЬиеїБфСПЕФIVжЕ:
дкЪЕМЪгІгУжа,ЭЈЙ§РрЫЦЩЯУцЕФДњТыМЦЫуГіИїИіЬиеїБфСПЕФIVжЕ,ШЛКѓИљОнIVжЕДгИпЕНЕЭХХађ,МДПЩЩИбЁГіашвЊЕФЬиеїБфСПЁЃ
6.4?АИР§:ПЭЛЇСїЪЇдЄОЏФЃаЭЕФIVжЕМЦЫу
ЮЊСЫЬсИпДњТыЕФЭЈгУад,етРяНЋЩЯвЛНкЕФДњТыЩдМгаоИФ,аДГЩШчЯТЕФздЖЈвхКЏЪ§аЮЪНЁЃИУКЏЪ§ЙВга4ИіВЮЪ§:data(дЪМЪ§ОнМЏ)ЁЂcut_num(Ъ§ОнЗжЯфВНжшжаЗжЯфЕФИіЪ§)ЁЂfeature(ашвЊМЦЫуIVжЕЕФЬиеїБфСПУћГЦ)ЁЂtarget(ФПБъБфСПУћГЦ)ЁЃгаСЫетИіКЏЪ§,ОЭФмЗНБуЕиЖдШЮвтвЛИіЪ§ОнМЏМЦЫуИїИіЬиеїБфСПЕФIVжЕЁЃ
import numpy as np
import pandas as pd
def cal_iv(data,cut_num,feature,target):
# 1.Ъ§ОнЗжЯф
data_cut = pd.cut(data[feature],cut_num)
# 2.ЭГМЦИїИіЗжЯфЕФзмбљБОЪ§,ЛЕбљБОЪ§,КУбљБОЪ§
cut_group_all = data[target].groupby(data_cut).count()
cut_y = data[target].groupby(data_cut).sum()
cut_n = cut_group_all - cut_y
df = pd.DataFrame()
df['змЪ§'] = cut_group_all
df['ЛЕбљБО'] = cut_y
df['КУбљБО'] = cut_n
# 3.ЭГМЦбљБОБШТЪ
df['ЛЕбљБО%'] = df['ЛЕбљБО'] / df['ЛЕбљБО'].sum() # pyi
df['КУбљБО%'] = df['КУбљБО'] / df['КУбљБО'].sum() # pni
# 4.МЦЫуWOEжЕ
df['WOE'] = np.log(df['ЛЕбљБО%'] / df['КУбљБО%'])
df = df.replace({'WOE':{np.inf:0,-np.inf:0}})
# 5.МЦЫуИїИіЗжЯфЕФIVжЕ
df['IV'] = (df['ЛЕбљБО%'] - df['КУбљБО%']) * df['WOE']
# 6.МЦЫузмIVжЕ
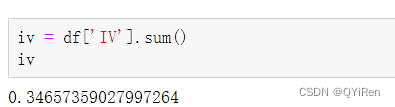
iv = df['IV'].sum()
print(iv) ЭЈЙ§ШчЯТДњТыЖСШЁПЭЛЇСїЪЇдЄОЏФЃаЭЕФЯрЙиЪ§ОнЁЃ
ДЫЪБЕФdataШчЯТЭМЫљЪО,ЁАЪЧЗёСїЪЇЁБСаЮЊФПБъБфСП,ЦфгрСаЮЊЬиеїБфСПЁЃЮЊСЫМђЛЏЮЪЬт,етРяЩОГ§СЫЁАРлМЦНЛвзгЖН№(дЊ)ЁБСаЁЃ
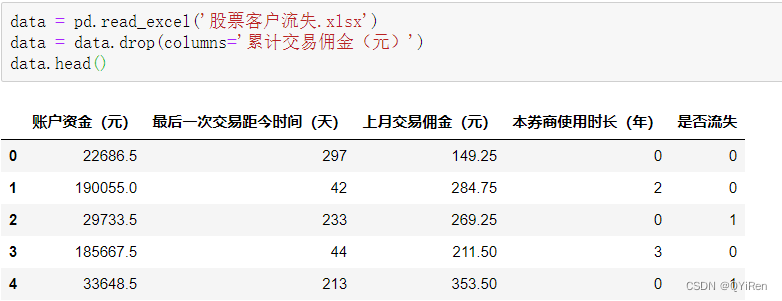
ЭЈЙ§forбЛЗПЩвдПьЫйМЦЫуГіЫљгаЬиеїБфСПЕФIVжЕ,ДњТыШчЯТЁЃ
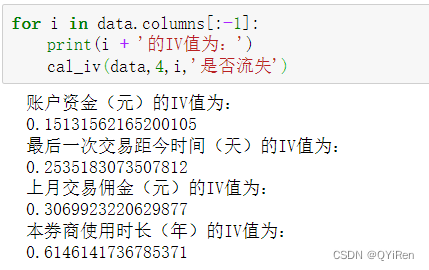
НЋЩЯЪіIVжЕДгИпЕНЕЭХХађ,НсЙћЮЊ:БОШЏЩЬЪЙгУЪБГЄ(Фъ)>ЩЯдТНЛвзгЖН№(дЊ)>зюКѓвЛДЮНЛвзОрНёЪБМф(Ьь)>еЫЛЇзЪН№(дЊ)ЁЃПЩЕУГіНсТл:ЁАБОШЏЩЬЪЙгУЪБГЄ(Фъ)ЁБЕФаХЯЂСПзюДѓ,ЖјЁАеЫЛЇзЪН№(дЊ)ЁБЕФаХЯЂСПзюаЁ,дЄВтФмСІзюЕЭЁЃетЦфЪЕвВЪЧДюНЈТпМЛиЙщФЃаЭЪБХаЖЯЬиеїживЊадЕФвЛИіЗНЪНЁЃ
7?ЖржиЙВЯпадЕФЗжЮігыДІРэ
7.1?ЖржиЙВЯпадЕФЖЈвх
ЖдЖрдЊЯпадЛиЙщФЃаЭY=k0+k1X1+k2X2+Ё+knXnЖјбд,ШчЙћЬиеїБфСПX1ЁЂX2ЁЂX3ЁжЎМфДцдкИпЖШЯпадЯрЙиЙиЯЕ,дђГЦЮЊЖржиЙВЯпад(multicollinearity)ЁЃР§Шч,X1=1-X2(Шч:адБ№_Фа=1-адБ№_ХЎ),ДЫЪБX1гыX2ДцдкИпЖШЕФЯпадЯрЙиЙиЯЕ,дђШЯЮЊИУФЃаЭДцдкЖржиЙВЯпад,ашвЊЩОШЅX1КЭX2жаЕФвЛИіБфСПЁЃ
ЩЯУцЪЧгУ2ИіЬиеїБфСПОйР§,ШчЙћЪЧЖрИіЬиеїБфСП,дђЖржиЙВЯпадПЩвдБэЪОГЩШчЯТЙЋЪНЁЃa1X1+a2X2+Ё+anXn=0
ШчЙћДцдкaiВЛШЋЮЊ0,МДФГИіЬиеїБфСППЩвдгУЦфЫћЬиеїБфСПЕФЯпадзщКЯБэЪО,дђГЦЬиеїБфСПМфДцдкЭъШЋЙВЯпадЁЃвЛИіМЋЖЫЕФР§згЪЧШУЫљгаaiЖМЮЊ1,дђX1=-(X2+X3+Ё+Xn),ДЫЪББуШЯЮЊЬиеїБфСПМфДцдкЭъШЋЙВЯпадЁЃ
Г§СЫЭъШЋЙВЯпад,ЛЙДцдкНќЫЦЙВЯпад,ЫќвВЪЧЖржиЙВЯпадЕФвЛжжЧщПі,ЦфЙЋЪНШчЯТЁЃa1X1+a2X2+Ё+anXn+v=0ЁЃШчЙћДцдкaiВЛШЋЮЊ0,vЮЊЮѓВюЫцЛњЯю,дђГЦЬиеїБфСПМфДцдкНќЫЦЙВЯпадЁЃвЛИіМЋЖЫЕФР§згЪЧШУЫљгаaiЖМЮЊ1,vЮЊ-1,ФЧУДX1=1-(X2+X3+Ё+Xn),ДЫЪББуШЯЮЊЬиеїБфСПМфДцдкНќЫЦЙВЯпад,ШчЙћnЮЊ2,ФЧУДОЭЪЧжЎЧАЬсЕНЕФX1=1-X2ЁЃ
змЬхРДЫЕ,дкЪЕМЪгІгУжа,ЖржиЙВЯпадЛсДјРДШчЯТВЛРћгАЯь:
ЁЄЯпадЛиЙщЙРМЦЪНБфЕУВЛШЗЖЈЛђВЛОЋШЗ;
ЁЄЯпадЛиЙщЙРМЦЪНЗНВюБфЕУКмДѓ,БъзМЮѓВюдіДѓ;
ЁЄЕБЖржиЙВЯпадбЯжиЪБ,ЩѕжСПЩФмЪЙЙРМЦЕФЛиЙщЯЕЪ§ЗћКХЯрЗД,ЕУГіДэЮѓЕФНсТл;
ЁЄЯїШѕЬиеїБфСПЕФЬиеїживЊадЁЃ
7.2?ЖржиЙВЯпадЕФЗжЮігыМьбщ
МгдиЪ§Он:

заЯИЙлВьПЩвдЗЂЯж,X2СажаОјДѓВПЗжЪ§ОнЪЧX1СажаЪ§ОнЕФ2БЖЁЃ
ЖдЪ§ОнМЏЛЎЗжЬиеїБфСПКЭФПБъБфСП,ДњТыШчЯТЁЃ
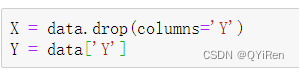
ЦфжаYСаЮЊФПБъБфСП(МДвђБфСП),X1ЁЂX2ЁЂX3СаЮЊЬиеїБфСП(МДздБфСП)ЁЃ
ЯТУцРДЗжЮігыМьбщЬиеїБфСПX1ЁЂX2ЁЂX3МфЪЧЗёДцдкЖржиЙВЯпадЁЃ
етРяжївЊНВНтСНжжХаБ№ЗНЗЈЁЊЁЊЯрЙиЯЕЪ§ХаЖЯКЭЗНВюХђеЭЯЕЪ§ЗЈ(VIFМьбщ)ЁЃ
1.ЯрЙиЯЕЪ§ХаЖЯ
ЖржиЙВЯпадЪЧжИВЛЭЌЬиеїБфСПМфДцдкЯпадЯрЙиЙиЯЕ,дкPythonжагУcorr()КЏЪ§(ЦЄЖћбЗЯрЙиЯЕЪ§)ПЩвдПьЫйМЦЫуВЛЭЌБфСПМфЕФЯрЙиЯЕЪ§,ДњТыШчЯТЁЃ
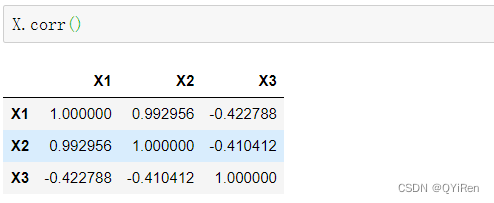
ЦфжаЕкiааЕкjСаЕФФкШнБэЪОЕкiИіЬиеїБфСПКЭЕкjИіЬиеїБфСПЕФЯрЙиЯЕЪ§ЁЃ
Р§Шч,Ек1ааЕк2СаЕФЯрЙиЯЕЪ§0.99,БэЪОЕФОЭЪЧЬиеїБфСПX1КЭЬиеїБфСПX2ЕФЯрЙиЯЕЪ§,ПЩвдПДЕНЫќУЧЕФЯрЙиадЛЙЪЧЗЧГЃЧПЕФ,гаРэгЩЯраХЫќУЧЛсЕМжТЖржиЙВЯпад,вђДЫашвЊЩОШЅЦфжавЛИіЬиеїБфСПЁЃашвЊЫЕУїЕФЪЧ,ДгзѓЩЯНЧжСгвЯТНЧЕФЖдНЧЯпЩЯЕФЯрЙиЯЕЪ§ЖМЮЊ1,етИі1ЦфЪЕУЛгаЪВУДвтвх,вђЮЊЫќБэЪОЕФЪЧЬиеїБфСПздЩэгыздЩэЕФЯрЙиЯЕЪ§,ФЧздШЛЪЧ1СЫЁЃ
ЯрЙиЯЕЪ§ХаЖЯЪЙгУЦ№РДЗЧГЃМђЕЅ,НсТлвВБШНЯЧхЮњ,ВЛЙ§ЫќгавЛИіШБЕу:МђЕЅЯрЙиЯЕЪ§жЛЪЧЖржиЙВЯпадЕФГфЗжЬѕМў,ВЛЪЧБивЊЬѕМўЁЃдкгаЖрИіЬиеїБфСПЪБ,ЯрЙиЯЕЪ§НЯаЁЕФЬиеїБфСПМфвВПЩФмДцдкНЯбЯжиЕФЖржиЙВЯпадЁЃ
ЮЊСЫИќМгбЯНї,ЪЕеНжаЛЙОГЃгУЕНЯТУцвЊНВНтЕФЗНВюХђеЭЯЕЪ§ЗЈ(VIFМьбщ)ЁЃ
2.ЗНВюХђеЭЯЕЪ§ЗЈ(VIFМьбщ)
ЗНВюХђеЭЯЕЪ§(Variance Inflation Factor)ЕФМЦЫуЙЋЪНШчЯТЁЃ
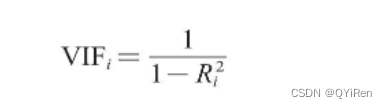
VIFiЪЧКтСПздБфСПXiЪЧЗёгыЦфЫћздБфСПОпгаЖржиЙВЯпадЕФЗНВюХђеЭЯЕЪ§;
![]() ЪЧНЋздБфСПXiзїЮЊвђБфСП,ЦфЫћздБфСПзїЮЊЬиеїБфСПЪБЛиЙщЕФПЩОіЯЕЪ§,МДR-squaredжЕ,ЫќЪЧгУРДКтСПФтКЯГЬЖШЕФЁЃ
ЪЧНЋздБфСПXiзїЮЊвђБфСП,ЦфЫћздБфСПзїЮЊЬиеїБфСПЪБЛиЙщЕФПЩОіЯЕЪ§,МДR-squaredжЕ,ЫќЪЧгУРДКтСПФтКЯГЬЖШЕФЁЃ
![]() дНДѓ,VIFiОЭдНДѓ,БэЪОздБфСПXiгыЦфЫћздБфСПМфЕФЖржиЙВЯпаддНбЯжиЁЃвЛАуШЯЮЊVIFi<10ЪБ,ИУздБфСПгыЦфгрздБфСПжЎМфВЛДцдкЖржиЙВЯпад;ЕБ10ЁмVIFi<100ЪБДцдкНЯЧПЕФЖржиЙВЯпад;ЕБVIFiЁн100ЪБДцдкбЯжиЕФЖржиЙВЯпадЁЃ
дНДѓ,VIFiОЭдНДѓ,БэЪОздБфСПXiгыЦфЫћздБфСПМфЕФЖржиЙВЯпаддНбЯжиЁЃвЛАуШЯЮЊVIFi<10ЪБ,ИУздБфСПгыЦфгрздБфСПжЎМфВЛДцдкЖржиЙВЯпад;ЕБ10ЁмVIFi<100ЪБДцдкНЯЧПЕФЖржиЙВЯпад;ЕБVIFiЁн100ЪБДцдкбЯжиЕФЖржиЙВЯпадЁЃ

вђЮЊЬиеїБфСПX2ЪЧX1ЕФ2БЖ,ЫљвдЪЙгУX1ЖдX2КЭX3ЛиЙщКЭЪЙгУX2ЖдX1КЭX3ЛиЙщЪБЫљЕУЕФЗНВюХђеЭЯЕЪ§ЛсКмДѓ,ДгЩЯЪіМЦЫуНсЙћвВПЩвдПДГі,ЧА2ИіVIFжЕОљДѓгк100,АЕЪОЖржиЙВЯпадЪЎЗжбЯжи,гІИУЩОЕєX1ЛђX2ЁЃ
ЯТУцЩОЕєX2дйНјаавЛДЮЛиЙщКЭVIFМьбщ,ПДПДНсЙћЕФБфЛЏЁЃ

ПЩвдПДЕН,ДЫЪБСНИіЬиеїБфСПЕФЗНВюХђеЭЯЕЪ§ЖМаЁгк10,ЫЕУїЫќУЧжЎМфВЛДцдкЖржиЙВЯпадЁЃ
змНсРДЫЕ,ЖдгкЯпадЛиЙщФЃаЭКЭТпМЛиЙщФЃаЭЕШвдЯпадЗНГЬБэДяЪНЮЊЛљДЁЕФЛњЦїбЇЯАФЃаЭ,ашвЊзЂвтЖржиЙВЯпадЕФгАЯьЁЃШчЙћДцдкЖржиЙВЯпад,дђашвЊНјааЯргІДІРэ,ШчЩОШЅФГИів§Ц№ЖржиЙВЯпадЕФЬиеїБфСПЁЃ
8?Й§ВЩбљКЭЧЗВЩбљ
НЈСЂФЃаЭЪБ,ПЩФмЛсгіЕНе§ИКбљБОБШР§МЋЖШВЛОљКтЕФЧщПіЁЃР§Шч,НЈСЂаХгУЮЅдМФЃаЭЪБ,ЮЅдМбљБОЕФБШР§дЖаЁгкВЛЮЅдМбљБОЕФБШР§,ДЫЪБФЃаЭЛсЛЈИќЖрОЋСІШЅФтКЯВЛЮЅдМбљБО,ЕЋЪЕМЪЩЯевГіЮЅдМбљБОИќЮЊживЊЁЃетЛсЕМжТФЃаЭПЩФмдкбЕСЗМЏЩЯБэЯжСМКУ,ЕЋВтЪдЪББэЯжВЛМбЁЃЮЊСЫИФЩЦбљБОБШР§ВЛОљКтЕФЮЪЬт,ПЩвдЪЙгУЙ§ВЩбљКЭЧЗВЩбљЕФЗНЗЈЁЃМйЩшНЈСЂаХгУЮЅдМФЃаЭЪБ,бљБОЪ§Онжага1000ИіВЛЮЅдМбљБОКЭ100ИіЮЅдМбљБО,ЯТУцЗжБ№НщЩмЙ§ВЩбљКЭЧЗВЩбљЕФЗНЗЈЁЃ
8.1?Й§ВЩбљ
8.1.1?Й§ВЩбљЕФдРэ
(1)ЫцЛњЙ§ВЩбљ
ЫцЛњЙ§ВЩбљЪЧДг100ИіЮЅдМбљБОжаЫцЛњГщШЁОЩбљБОзїЮЊвЛИіаТбљБО,ЙВЗДИДГщШЁ900ДЮ,ШЛКѓКЭдРДЕФ100ИіОЩбљБОзщКЯГЩаТЕФ1000ИіЮЅдМбљБО,КЭ1000ИіВЛЮЅдМбљБОвЛЦ№ЙЙГЩаТЕФбЕСЗМЏЁЃвђЮЊЫцЛњЙ§ВЩбљжиИДЕибЁШЁСЫЮЅдМбљБО,ЫљвдгаПЩФмдьГЩЖдЮЅдМбљБОЕФЙ§ФтКЯЁЃ
(2)SMOTEЙ§ВЩбљ
SMOTEЗЈЙ§ВЩбљМДКЯГЩЩйЪ§РрЙ§ВЩбљММЪѕ,ЫќЪЧвЛжжеыЖдЫцЛњЙ§ВЩбљШнвзЕМжТЙ§ФтКЯЮЪЬтЕФИФНјЗНАИЁЃМйЩшЖдЩйЪ§РрНјаа4БЖЙ§ВЩбљ,ЭЈЙ§ЯТЭМРДНВНтSMOTEЗЈЕФдРэЁЃ

8.1.2?Й§ВЩбљЕФДњТыЪЕЯж
ЪзЯШгУpandasПтЖСШЁаХгУЮЅдМЪ§Он,ДњТыШчЯТЁЃ

ПЩвдПДЕН,ВЛЮЅдМбљБОЪ§ЮЊ1000,дЖдЖДѓгкЮЅдМбљБОЪ§100ЁЃ
ЮЊСЫЗРжЙНЈСЂаХгУЮЅдМФЃаЭЪБ,ФЃаЭзХжиФтКЯВЛЮЅдМбљБО,ЖјЮоЗЈевГіЮЅдМбљБО,ВЩгУЙ§ВЩбљЕФЗНЗЈРДИФЩЦбљБОБШР§ВЛОљКтЕФЮЪЬтЁЃетРяЗжБ№ЖдЫцЛњЙ§ВЩбљКЭSMOTEЗЈЙ§ВЩбљНјааДњТыЪЕЯжЁЃ
1.ЫцЛњЙ§ВЩбљ
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
X_oversampled,y_oversampled = ros.fit_resample(X,y)
Counter(y_oversampled)2.SMOTEЙ§ВЩбљ
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_oversampled,y_oversampled = smote.fit_resample(X,y)
Counter(y_oversampled)8.2?ЧЗВЩбљ
8.2.1?ЧЗВЩбљЕФдРэ
ЧЗВЩбљЪЧДг1000ИіВЛЮЅдМбљБОжаЫцЛњбЁШЁ100ИібљБО,КЭ100ИіЮЅдМбљБОвЛЦ№ЙЙГЩаТЕФбЕСЗМЏЁЃЧЗВЩбљХзЦњСЫДѓВПЗжВЛЮЅдМбљБО,дкДюНЈФЃаЭЪБгаПЩФмВњЩњЧЗФтКЯЁЃ
8.2.2?ЧЗВЩбљЕФДњТыЪЕЯж
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=0)
X_undersampled,y_undersampled = rus.fit_resample(X,y)
Counter(y_undersampled)дкЪЕеНжаДІРэбљБОВЛОљКтЮЪЬтЪБ,ШчЙћбљБОЪ§ОнСПВЛДѓ,ЭЈГЃЪЙгУЙ§ВЩбљ,вђЮЊетбљФмИќКУЕиРћгУЪ§Он,ВЛЛсЯёЧЗВЩбљФЧбљКмЖрЪ§ОнЖМУЛгаЪЙгУЕН;ШчЙћЪ§ОнСПГфзу,дђЙ§ВЩбљКЭЧЗВЩбљЖМПЩвдПМТЧЪЙгУЁЃ
ВЮПМЪщМЎ
ЁЖPythonДѓЪ§ОнЗжЮігыЛњЦїбЇЯАЩЬвЕАИР§ЪЕеНЁЗ

