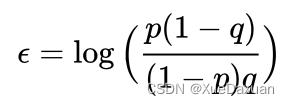???????motivation:众包数据进行训练过程中,容易造成隐私泄漏。
methods:
- 提出的新算法(LATENT)应用了随机响应的属性――LDP设置和算法的层结构可以使得在不同层级进行隐私保护交流
- 设计了一种新的协议,称为效用增强随机化(UER)
(1)首先对优化的一元编码协议(OUE)进行了改进,提出了一种新的LDP协议modified OUE(MOUE),增强了二进制字符串随机化的灵活性。
(2)OUE是一个LDP协议,遵循随机1和0的不同直觉,以提高效用。
(3)MOUE通过引入一个额外的系数α(隐私预算系数)来实现改进的灵活性,该系数在选择随机化概率时提高了灵活性。 - 然后我们遵循MOUE背后的动机,提出了在高灵敏度的长二进制字符串随机化过程中保持效用的UER。
提出了一个LATENT层,位于flattening层之后,通过加入符合差分隐私的操作之后,当成全连接层的输入。卷积神经网络的结构被划分为:(1)卷积模块(2)随机化模块(3)全连接层。
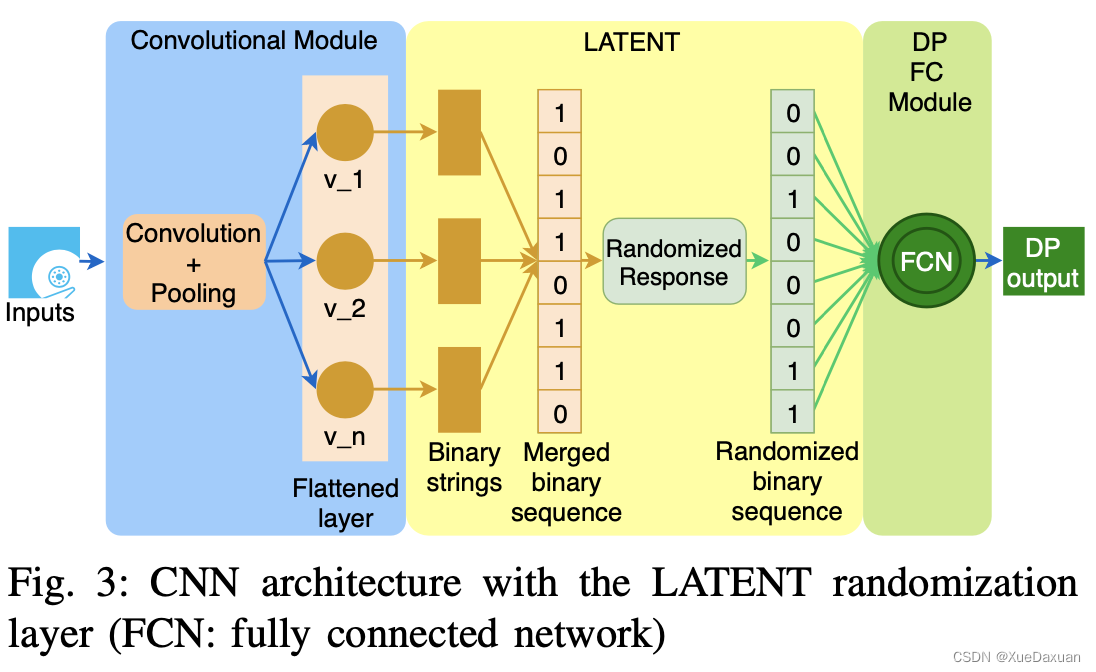
?LATENT方法:

提出了一种新的方法来进一步优化随机化概率的选择,它可以在位串较长时提供增强的效用。
6.使用一元编码提高效用:使用优化一元编码(OUE),OUE分别扰动0和1来减少扰动0到1 (p0→1)的概率,因为输入二进制字符串很长时,需要0比1多。

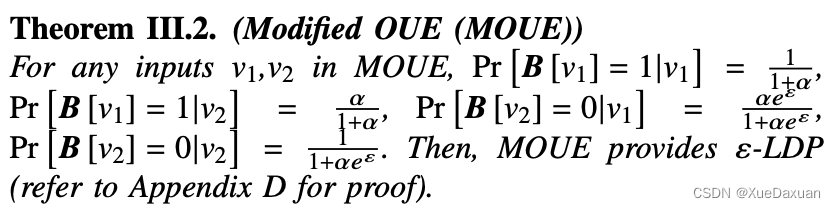

α为MOUE在选择随机概率方面提供了更大的灵活性。通过增加α,我们可以增加0比特在原始状态下传输的概率。
7.提高随机化二进制字符串的效用:虽然MOUE提高了随机输出的效用,但当α较大时,它也可以大量增加1的随机化。根据OUE背后的直觉,通过对1和0进行不同的随机化,MOUE提高了随机化的概率。通过进一步扩展这一思想,我们对二进制字符串的位应用了两个随机化模型,以增强随机化二进制字符串的效用。通过这种方式,我们尝试将位串中的一半随机化,与定理III.4中定义的另一半不同。当α增加时,UER将增加0保持在原始状态的概率。然而,对于字符串的一半,保持1的原始状态的概率增加,而对于字符串的另一半,相应的概率减少。这样,UER将隐私预算维持在ε。

?8.对合并的字符串进行UER:?对合并的二进制字符串的位进行UER: 合并后的二进制串中的每一位都要接受MOUE,如式(6)所示。p越高,二进制串的随机化程度越低。由式(6)可知,ε值越大,l × r值越小,p值越高。在LATENT函数中,l × r是一个比ε大得多的值,而p通常是一个较小的值。MOUE允许LATENT通过校准α微调随机化的概率。通过增加α使其大于5,MOUE降低了干扰0到1的概率。MOUE的这个特性帮助LATENT维护这个实用程序,因为在潜的二进制编码输入中,与1相比,有大量的0。然而,当输入位串中有一半位的输入位为1时,这降低了释放实际位的概率。与RAPPOR相比,LATENT中的二进制字符串有多个1。因此,LATENT可以容忍这种概率损失。因此,UER允许通过改变α,同时保持相同的隐私预算,改变输入位的随机化量。
9.构建模型

随机响应一元编码:对于一个K大小域,每个响应都被编码为K位的长度向量,除了对应于响应方的职业的位置之外,所有位置都为0。在机器学习中,这种表示被称为"one-hot encoding"。
encode- perturb- aggregate:K个长度编码;扰动每一位以确保差分隐私,翻转概率PQ决定了隐私预算epsilon;聚合相加;