前面用了keras的c++之后,将deeplabv3训练后用opencv readNetFromTensorflow导入模型报错:layer.add() 不能识别,想不明白为什么,也解决不了,放弃了,要是有大佬解决了求告知。
改为torch了,有现成的liborch库,下面是测试。
环境:
torch 1.11.0
libtorch 1.11.0 windows debug nocuda(和Python训练的torch同版本)
opencv 4.2.0.32
训练模型:https://github.com/bubbliiiing/deeplabv3-plus-pytorch
保存模型:
用上面链接正常训练。保存.pth文件后转换为pt文件
import torch
from nets.deeplabv3_plus import DeepLab
import cv2
import numpy as np
import torch.nn.functional as F
from PIL import Image
# 导入已经训练好的模型
num_classes = 21
backbone = "mobilenet"
pretrained = True
downsample_factor = 16
input_shape = [512, 512]
model = DeepLab(num_classes=num_classes, backbone=backbone, downsample_factor=downsample_factor, pretrained=pretrained)
#保存模型
weight = torch.load('logs/ep001-loss0.709-val_loss0.889.pth')
model.load_state_dict(weight, strict=True)
model = model.eval()
# 注意模型输入的尺寸
example = torch.rand(1, 3, 512, 512)
traced_script_module = torch.jit.trace(model, example)
traced_script_module.save("logs/resout.pt")opencv-python调用:
#读入图片
img_path = r"1.jpg"
save_path = r"logs\1.jpg"
module = torch.jit.load("logs/resout.pt")
image = cv2.imread(img_path)
orininal_h,orininal_w,_ = image.shape
image=cv2.resize(image, (512, 512))
image = image/255.0
image_data = np.expand_dims(np.transpose((np.array(image, np.float32)), (2, 0, 1)), 0)
img_tensor = torch.from_numpy(image_data)
#模型计算以及保存结果
pr = module.forward(img_tensor)[0]
pr = F.softmax(pr.permute(1, 2, 0), dim=-1).cpu().detach().numpy()
pr = cv2.resize(pr, (orininal_w, orininal_h), interpolation=cv2.INTER_LINEAR)
pr = pr.argmax(axis=-1)
colors = [(0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0), (0, 0, 128), (128, 0, 128), (0, 128, 128),
(128, 128, 128), (64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0), (64, 0, 128), (192, 0, 128),
(64, 128, 128), (192, 128, 128), (0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128),
(128, 64, 12)]
seg_img = np.reshape(np.array(colors, np.uint8)[np.reshape(pr, [-1])], [orininal_h, orininal_w, -1])
image = Image.fromarray(np.uint8(seg_img))
image.save(save_path)C++ opencv调用
主要是图像分割模型的输入输出,捣鼓了好久,一个完整的例子。
#include <torch/script.h>
#include <opencv2/opencv.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
#include <memory>
using namespace std;
int main()
{
string model_path = "resout.pt";
string img_path = "1.jpg";
//载入模型
torch::jit::script::Module module;
module = torch::jit::load(model_path);
//输入图像
cv::Mat image = cv::imread(img_path);
int img_h = image.rows;
int img_w = image.cols;
int depth = image.channels();
cv::Mat img_float;
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::resize(image, image, cv::Size(512, 512));
image.convertTo(image, CV_32FC3, 1.0f / 255.0f);
auto img_tensor = torch::from_blob(image.data, { 1, 512, 512, depth });
img_tensor = img_tensor.permute({ 0, 3, 1, 2 });
//模型计算
std::vector<torch::jit::IValue> inputs;
torch::Tensor out;
inputs.push_back(img_tensor);
out = module.forward(std::move(inputs)).toTensor();
//结果处理
out = out[0];
out = out.permute({ 1, 2, 0 }).detach();
out = torch::softmax(out, 2);
out = out.argmax(2);
out = out.mul(10).clamp(0, 255).to(torch::kU8);
out = out.to(torch::kCPU);
//保存图片
int height, width;
height = out.size(0);
width = out.size(1);
cv::Mat resultImg(cv::Size(512, 512), CV_8U, out.data_ptr()); // 将Tensor数据拷贝至Mat
cv::resize(resultImg, resultImg, cv::Size(img_w, img_h));
cv::imwrite("result.jpg", resultImg);
return 0;
}
两个结果一致,还是得用库,唉,库还很大。
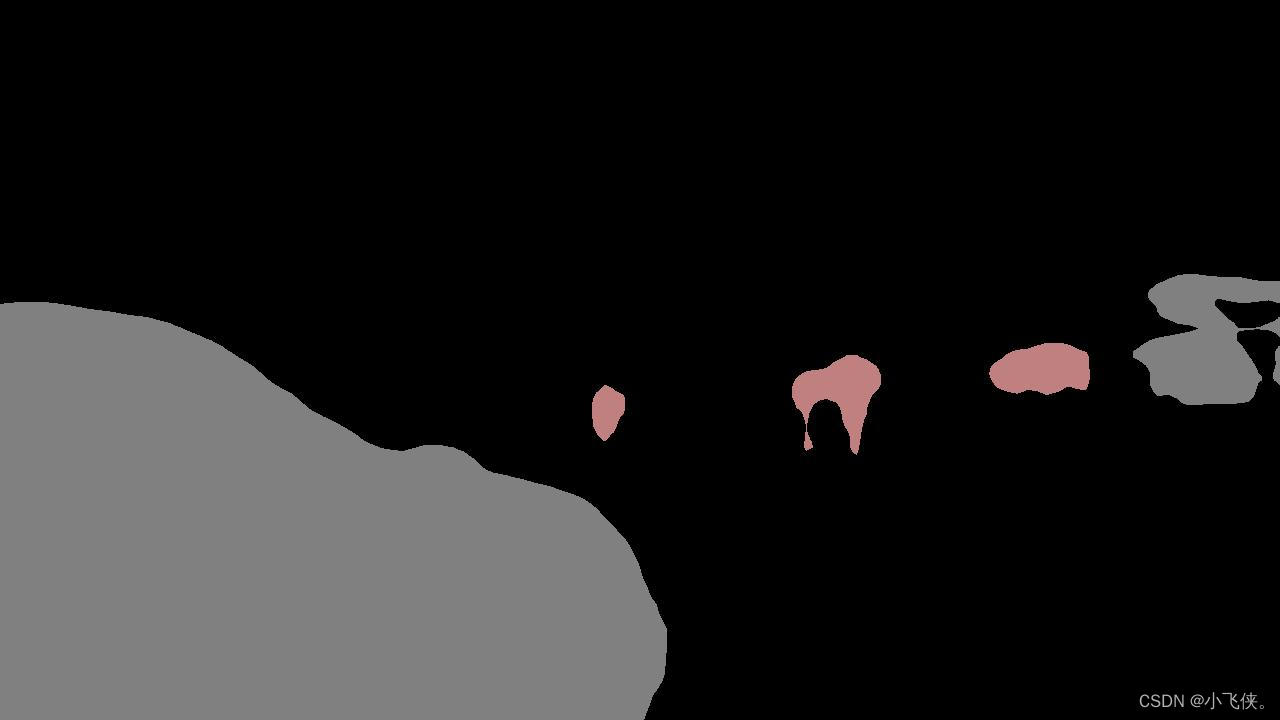
?
放在了这里面:
https://github.com/ziyaoma/Opencv-Tensorflow2.x/tree/main/torch

