语义分割Mask R-CNN–潘登同学的深度学习笔记
上采样
-
repeat,行列填充,先看每一行(用上边填充),再看每一列(用左边填充)

-
Resize,如双线性插值直接缩放,类似于图像缩放
-
Deconvolution,也叫 Transposed Convolution
双线性插值
又称为双线性内插。在数学上,双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值;
如图,已知 Q12,Q22,Q11,Q21,但是要插值的点为 P 点,这就要用双线性插值了,首先在 x 轴方向上,对 R1 和 R2 两个点进行插值,这个很简单,然后根据 R1 和 R2 对 P 点进行插值,这就是所谓的双线性插值。在数学上,双线性插值是有两个变量的插值函数的线性插值扩展,其核心思想是在两个方向分别进行一次线性插值

用数学公式表示
f
(
x
,
y
)
=
Q
11
(
x
2
?
x
1
)
(
y
2
?
y
1
)
(
x
2
?
x
)
(
y
2
?
y
)
+
Q
21
(
x
2
?
x
1
)
(
y
2
?
y
1
)
(
x
?
x
1
)
(
y
2
?
y
)
+
Q
12
(
x
2
?
x
1
)
(
y
2
?
y
1
)
(
x
2
?
x
)
(
y
?
y
1
)
+
Q
22
(
x
2
?
x
1
)
(
y
2
?
y
1
)
(
x
?
x
1
)
(
y
?
y
1
)
f(x,y) = \frac{Q_{11}}{(x_2-x_1)(y_2-y_1)}(x_2-x)(y_2-y) + \frac{Q_{21}}{(x_2-x_1)(y_2-y_1)}(x-x_1)(y_2-y) + \frac{Q_{12}}{(x_2-x_1)(y_2-y_1)}(x_2-x)(y-y_1) + \frac{Q_{22}}{(x_2-x_1)(y_2-y_1)}(x-x_1)(y-y_1)
f(x,y)=(x2??x1?)(y2??y1?)Q11??(x2??x)(y2??y)+(x2??x1?)(y2??y1?)Q21??(x?x1?)(y2??y)+(x2??x1?)(y2??y1?)Q12??(x2??x)(y?y1?)+(x2??x1?)(y2??y1?)Q22??(x?x1?)(y?y1?)
如果选择一个坐标系统使得 f 的四个已知点坐标分别为 (0, 0)、(0, 1)、(1, 0) 和 (1,1),那么插值公式就可以化简为
f
(
x
,
y
)
=
f
(
0
,
0
)
(
1
?
x
)
(
1
?
y
)
+
f
(
1
,
0
)
x
(
1
?
y
)
+
f
(
0
,
1
)
(
1
?
x
)
y
+
f
(
1
,
1
)
x
y
f(x,y) = f(0,0)(1-x)(1-y) + f(1,0)x(1-y) +f(0,1)(1-x)y + f(1,1)xy
f(x,y)=f(0,0)(1?x)(1?y)+f(1,0)x(1?y)+f(0,1)(1?x)y+f(1,1)xy
表述为矩阵运算为
f
(
x
,
y
)
=
[
1
?
x
x
]
[
f
(
0
,
0
)
f
(
0
,
1
)
f
(
1
,
0
)
f
(
1
,
1
)
]
[
1
?
y
y
]
f(x,y) = \begin{bmatrix} 1-x & x \end{bmatrix} \begin{bmatrix} f(0,0) & f(0,1) \\ f(1,0) & f(1,1) \\ \end{bmatrix} \begin{bmatrix} 1-y \\ y \\ \end{bmatrix}
f(x,y)=[1?x?x?][f(0,0)f(1,0)?f(0,1)f(1,1)?][1?yy?]
转置卷积
从数学上,反卷积不是转置卷积,反卷积是卷积的逆运算;从工程上,大家一般将转置卷积称为反卷积;
- 既然反卷积是卷积的逆运算,那为什么不直接少做几次卷积,还要做反卷积呢?
因为语义分割最后要做的是基于像素点的分类,要将前景的像素与背景的像素分类出来,所以要先提高阶特征,再反卷积回到原图大小
tf的API

filter: [kernel_size,kernel_size, output_channels, input_channels] 这里的转置卷积核和正向卷积核有区别,在于通道数参数的放置位置,因为转置卷积是正向卷积的逆过程(工程上),所以放置的位置相反
实现过程
(其实就是将输入扩充后进行卷积)
可以看下面的动图加深理解,先填充后卷积,本质和普通卷积没设么区别 。
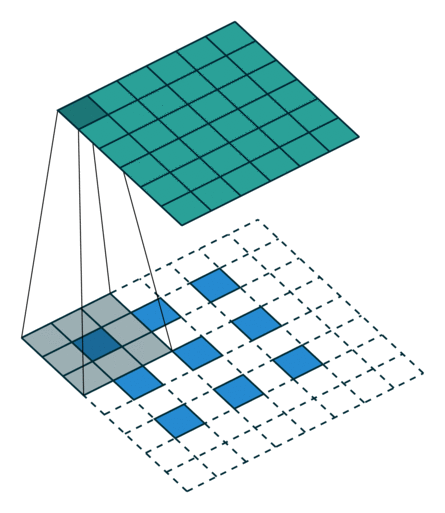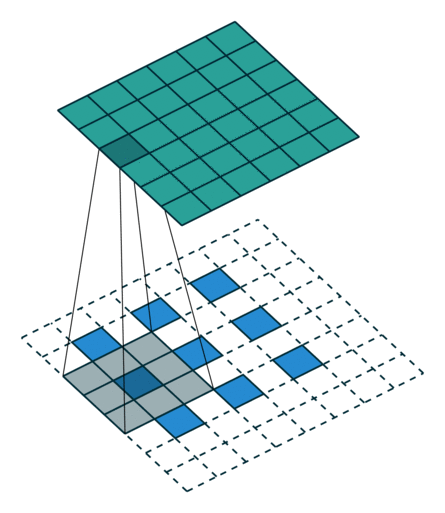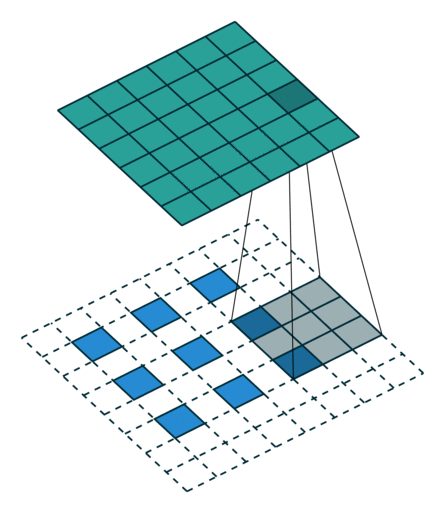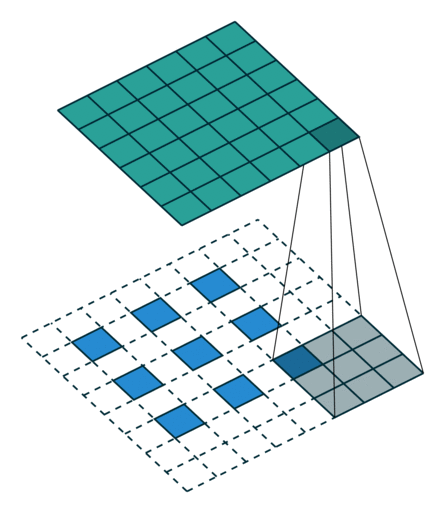
- Step 1 扩充: 将 inputs 进行填充扩大,扩大的倍数与 strides 有关(strides 倍)。扩大的方式是在元素之间插[ strides - 1 ]个 0。padding="VALID"时,在插完值后继续在周围填充的宽度为[ kenel_size - 1 ],填充值为 0;padding = "SAME"时,在插完值后根据 output 尺寸进行填充,填充值为 0。
- Step 2 卷积: 对扩充变大的矩阵,用大小为 kernel_size 卷积核做卷积操作,这样的卷积核有 filters个 ,并且这里的步长为 1(与参数 strides 无关,一定是 1)
注意 : conv2d_transpose会计算output_shape能否通过给定的filter,strides,padding计算出inputs的维度,如果不能,则报错。也就是说,conv2d_transpose中的filter,strides,padding参数,与反过程中的conv2d的参数相同
代码实现

将双线性插值与转置卷积结合

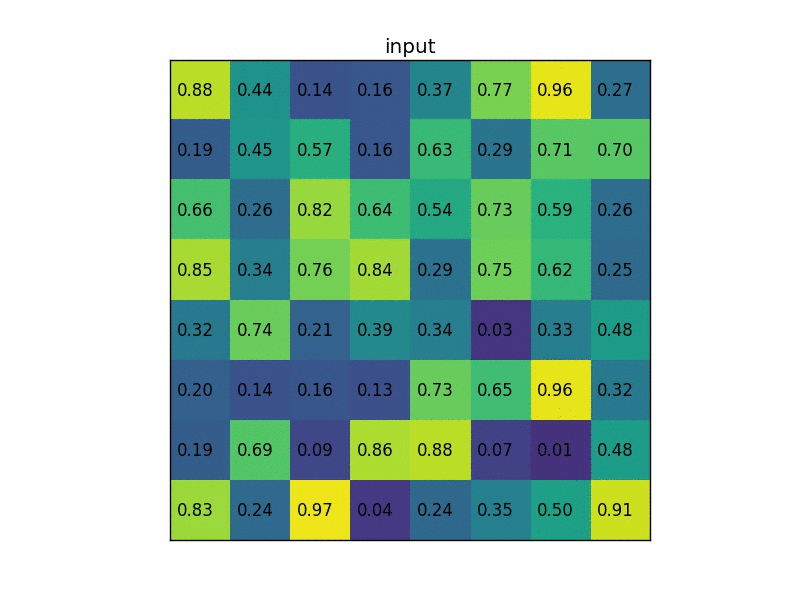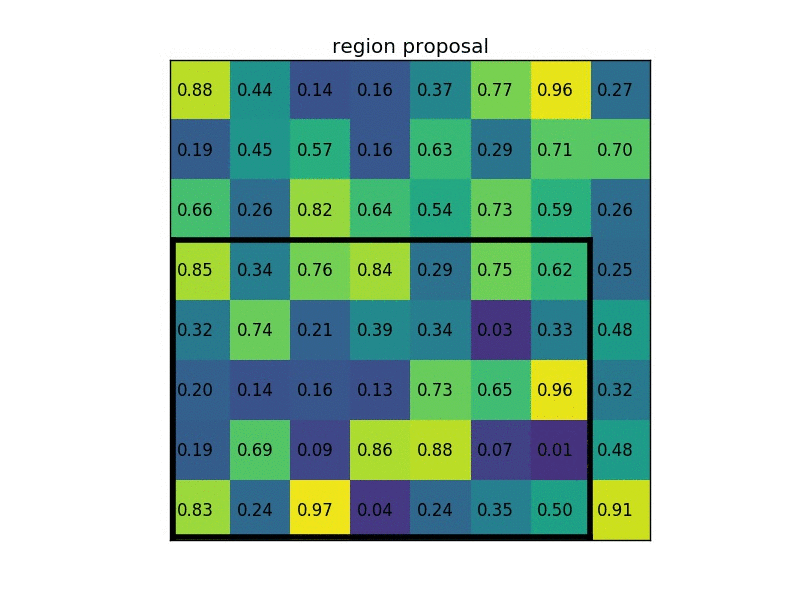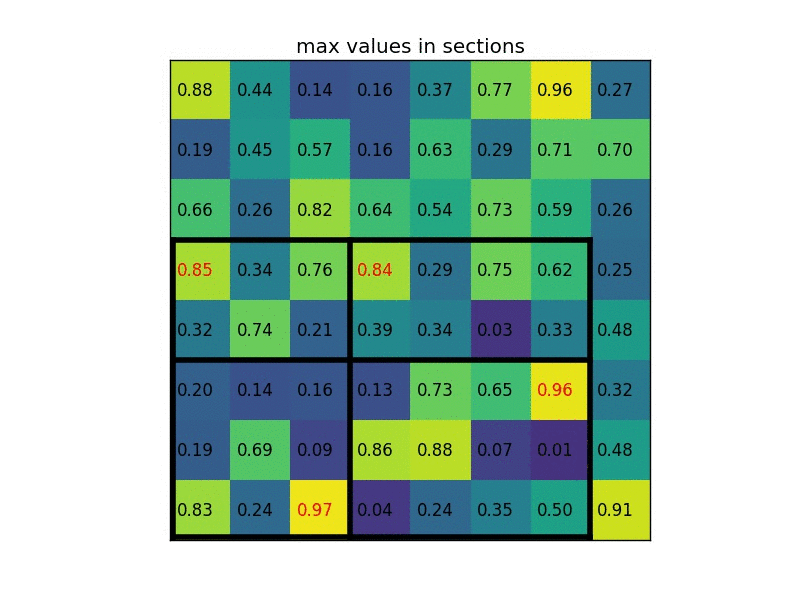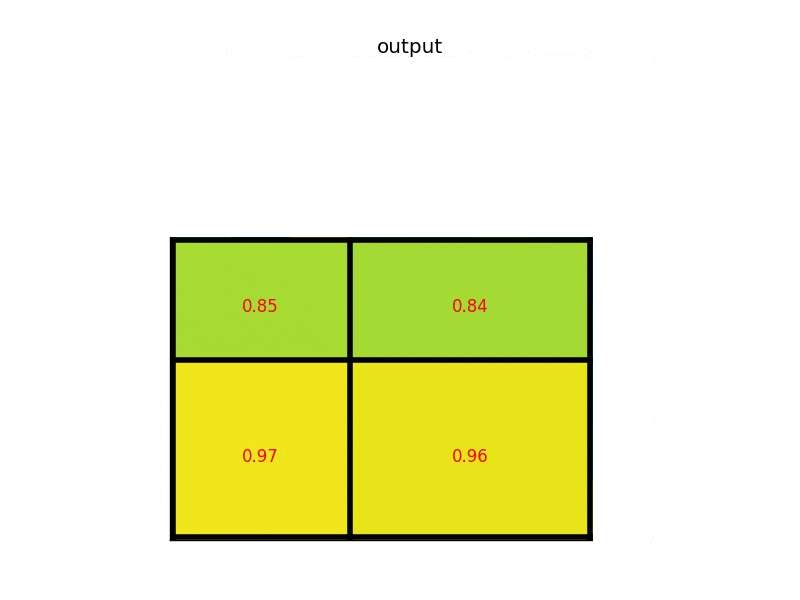
ROI Align
RoI Pooling
RoI Pooling的特点是输入特征图尺寸不固定,但是输出特征图尺寸固定;
在该网络中假设使用的骨架网络中的 feat stride=16(VGG16),假设测试图像中的一个边界框的大小为 400? 300。
- 首先计算对应featuremap上图的大小,那么在特征图上的大小就是 400 / 16 ? 300 / 16 = 25 ? 18.75 400/16 ? 300/16=25?18.75 400/16?300/16=25?18.75,注意这个时候出现小数了。那么就需要对其进行第一次量化操作,得到的特征图上大小为 25 ? 18 25? 18 25?18;
- 得到 Pooling 结果。假设最后的 RoI Pooling 的输出是固定的为 7 ? 7 7? 7 7?7,那么就要对这个特征图进行划分,那么划分出来的每一块的大小就是 25 / 7 ? 18 / 7 = 3.57 ? 2.57 25/7? 18/7=3.57? 2.57 25/7?18/7=3.57?2.57,小数又来了,那么取整吧,这是第二次量化操作,块的区域就变成了 3 ? 2 3? 2 3?2,然后再在这个区域上做 max pooling 得到最后的结果;
所以很大的误差是来自于量化过程,量化误差不断积累就变得很大了
下图是ROI Align的一种示意:
RoIWrap Pooling
该 Pooling 方法比前面提到的 Pooling 方法稍微好一些。对于一个选出来的预测框,它的对应的 RoI 区域可以通过 feat stride 算出来(crop 操作)
- crop操作(与上面一样): 首先计算对应featuremap上图的大小,那么在特征图上的大小就是 400 / 16 ? 300 / 16 = 25 ? 18.75 400/16 ? 300/16=25?18.75 400/16?300/16=25?18.75,注意这个时候出现小数了。那么就需要对其进行第一次量化操作,得到的特征图上大小为 25 ? 18 25? 18 25?18;
- warp 操作: 这里使用的是双线性差值算法,使 corp 操作的特征图变化到固定的尺度上去,比如 14 ? 14 14? 14 14?14,这样再去做 Pooling 得到固定的输出。这里的坐标就是连续的了,不会存在量化误差;
ROIAlign Pooling
这种 Pooling 方法是在 Mask RCNN 中被采用的,这相比之前的方法其内部完全去掉
了量化操作,取而代之的线性操作,使得网络特征图中的点都是连续的。从而提升了检测的精确度。
ROI-Align 取消了所有的量化操作,不再进行 4 舍 5 入,如下图所示比较清晰,图中虚线代表特征图,其中黑框代表 object 的位置,可见 object 的位置不再是整数,而可能在中间,然后进行 2*2 的 align-pooling,图中的采样点的数量为 4,所以可以计算出 4 个位置(是通过邻近的四个角的点进行双线性插值得到,邻近四个角的点也是通过邻近四个像素点的双线性插值得到);采样点的数量可以自己设置,默认是设置 4 个点。

FPN思想
图像金字塔(Featurized image pyramid)
图像金字塔的目的: 提取特征不仅要提取原始图像的,还有可能要提取其图像金字塔的图像特征
有两种类型的金字塔经常出现在文献和应用当中:
- 高斯金字塔(Gaussian pyramid): 用来向下采样(主要)
- 拉普拉斯金字塔(Laplacian pyramid): 用来从金字塔低层图像重建上层未采样图像,可以对图像进行最大程度的还原,配合高斯金字塔一起使用
高斯金字塔
高斯金字塔是最基本的图像塔。首先将原图像作为最底层图像G0(高斯金字塔的第0层),利用高斯核(5*5)对其进行卷积,然后对卷积后的图像进行下采样(去除偶数行和列)得到上一层图像G1,将此图像作为输入,重复卷积和下采样操作得到更上一层图像,反复迭代多次,形成一个金字塔形的图像数据结构,即高斯金字塔。

拉普拉斯金字塔
在高斯金字塔的运算过程中,图像经过卷积和下采样操作会丢失部分高频细节信息。为描述这些高频信息,人们定义了拉普拉斯金字塔(Laplacian Pyramid, LP)。用高斯金字塔的每一层图像减去其上一层图像上采样并高斯卷积之后的预测图像,得到一系列的差值图像即为 LP 分解图像。

注意卷积核前面的数值不再是 1 256 \frac{1}{256} 2561?,而是4
SSD
SSD 通过多个特征图完成检测。但是,最底层不会被选择执行目标检测。它们的分辨
率高但是语义值不够,导致速度显著下降而不能被使用

SSD 只使用较上层执行目标检测,因此对于小的物体的检测性能较差
特征金字塔
检测不同尺度的目标很有挑战性,尤其是小目标的检测。特征金字塔网络(FPN)是一种旨在提高准确率和速度的特征提取器。它取代了检测器(如 Faster R-CNN)中的特征提取器,并生成更高质量的特征图金字塔;

FPN 由自下而上和自上而下路径组成。其中自下而上的路径是用于特征提取的常用卷积网络。空间分辨率自下而上地下降。当检测到更高层的结构,每层的语义值增加
(SSD)虽然该重建层的语义较强,但在经过所有的上采样和下采样之后,目标的位置不精确。(FPN)在重建层和相应的特征图之间添加横向连接可以使位置侦测更加准确

FPN 结合 Fast R-CNN 或 Faster R-CNN
在 FPN 中,我们生成了一个特征图的金字塔,基于 ROI 的大小,我们选择最合适尺寸的特征图层来提取特征块。

上面公式应与下图结合来看

k= { 1 , 2 , 3 , 4 } \{1,2,3,4\} {1,2,3,4}的值与FPN网络的 { P 2 , P 3 , P 4 , P 5 } \{P_2,P_3,P_4,P_5\} {P2?,P3?,P4?,P5?}一一对应,如计算 k = 3 k=3 k=3那么应该选择 P 4 P_4 P4?作为ROI pooling的feature map(这与后面的yolo-v3有所不同)
语义分割
图像语义分割(Semantic Segmentation)是图像处理和是机器视觉技术中关于图像理解的重要一环,也是 AI 领域中一个重要的分支。语义分割即是对图像中每一个像素点进行分类,确定每个点的类别(如属于背景、人或车等),从而进行区域划分。目前,语义分割已经被广泛应用于自动驾驶、无人机落点判定等场景中;

- 语义分割(semantic segmentation):对图像中逐像素进行分类。
- 实例分割(instance segmentation):对图像中的 object 进行检测,并对检测到的 object 进行分割
- 全景分割(panoptic segmentation):对图像中的所有物体进行描述
与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。图像语义分割是像素级别的!但是由于 CNN 在进行 convolution 和 pooling 过程中丢失了图像细节,即 feature map size 逐渐变小,所以不能很好地指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
FCN
Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN 已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来;

在 FCN 网络中的作用,明显可以看到经过上采样后恢复了较大的 pixelwise feature map(其中最后一个层 21-dim 是因为 PACSAL 数据集有 20 个类别+Background)。这其实相当于一个 Encode-Decode 的过程;
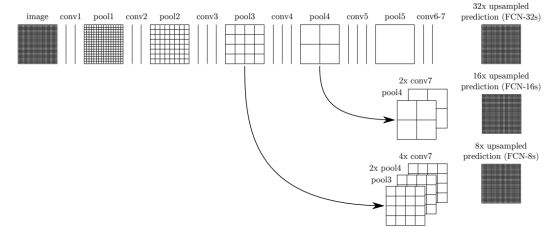
三种FCN网络的对比
- 对于 FCN-32s,直接对 pool5 feature 进行 32 倍上采样获得 32x upsampled feature,再对 32x upsampled feature 每个点做 softmax prediction 获得 32x upsampled feature prediction(即分割图);
- 对于 FCN-16s,首先对 pool5 feature 进行 2 倍上采样获得 2x upsampled feature,再把 pool4 feature 和 2x upsampled feature 逐点相加,然后对相加的 feature 进行 16 倍上采样,并 softmax prediction,获得 16x upsampled feature prediction;
- 对于FCN-8s,首先进行pool4+2xupsampledfeature逐点相加,然后又进行pool3+2x upsampled 逐点相加,即进行更多次特征融合。具体过程与 16s 类似,不再赘述;

UNet
U-Net 是原作者参加 ISBI Challenge 提出的一种分割网络,能够适应很小的训练集(大约 30 张图)。U-Net 与 FCN 都是很小的分割网络,既没有使用空洞卷积,也没有后接 CRF,结构简单;

整个 U-Net 网络结构如图,类似于一个大大的 U 字母:首先进行 Conv+Pooling 下采样;然后 Deconv 反卷积进行上采样,crop 之前的低层 feature map,进行融合;然后再次上采样。重复这个过程,直到获得输出 388x388x2 的 feature map,最后经过 softmax 获得 output segment map。总体来说与 FCN 思路非常类似;
Mask R-CNN
Mask R-CNN 是 He Kaiming 大神 2017 年的力作,其在进行目标检测的同时进行实例分割,取得了出色的效果,其在没有任何 trick 的情况下,取得了 COCO 2016 比赛的冠军。其网络的设计也比较简单,在 Faster R-CNN 基础上,在原本的两个分支上(分类+坐标回归)增加了一个分支进行语义分割,如下图所示:


网络结构

- 首先实例分割(instance segmentation)的难点在于:需要同时检测出目标的位置并且对目标进行分割,所以这就需要融合目标检测(框出目标的位置)以及语义分割(对像素进行分类,分割出目标)方法。在 Mask R-CNN 之前,Faster R-CNN 在目标检测领域表现较好,同时 FCN 在语义分割领域表现较好。所以很自然的方法是将 Faster R-CNN 与 FCN相结合嘛,作者也是这么干的,只是作者采用了一个如此巧妙的方法进行结合,并且取得了amazing 的结果。
- Mask R-CNN 是建立在 Faster R-CNN 基础上的,那么我们首先回顾一下 Faster R-CNN,Faster R-CNN 是典型的 two stage 的目标检测方法,首先生成 RPN 候选区域, 然后候选区域经过 Roi Pooling 进行目标检测(包括目标分类以及坐标回归),分类与回归共享前面的网络。
- Mask R-CNN 做了哪些改进?Mask R-CNN 同样是 two stage 的,生成 RPN 部分与Faster R-CNN 相同,然后,Mask R-CNN 在 Faster R-CNN 的基础上,增加了第三个支路,输出每个 ROI 的 Mask(这里是区别于传统方法的最大的不同,传统方法一般是先利用算法生成 mask 然后再进行分类,这里平行进行),自然而然,这变成一个多任务问题。
将mask映射回原图
因为Mask R-CNN是基于ROI的Mask,所以最终mask输出的固定大小的分类结果(如: 7*7),那么可以根据特定的数学公式(或者上采样公式),映射回原图的框中;
主干网络–ResNet

Loss函数
Mask R-CNN 的损失函数为:
L
o
s
s
=
L
c
l
s
+
L
b
o
x
+
L
m
a
s
k
Loss = L_{cls} + L_{box} + L_{mask}
Loss=Lcls?+Lbox?+Lmask?
Loss mask 是对每个像素进行分类,其含有
K
?
m
?
m
K ? m ? m
K?m?m维度的输出,K 代表类别的数量,
m
?
m
m*m
m?m 是提取的 ROI 图像的大小。L mask 被定义为 average binary cross-entropy loss(平均二值交叉熵损失函数);
这里解释一下是如何计算的,首先分割层会输出 channel 为 K 的 Mask,每个 Mask对应一个类别,利用 sigmoid 函数进行二分类,判断是否是这个类别,然后在计算 loss 的时候,假如 ROI 对应的 ground-truth 的类别是 K i K_i Ki?,则计算第 K i K_i Ki? 个 mask(在K的那个维度取 K i K_i Ki?这一层 m ? m ? 1 m*m*1 m?m?1) 对应的 loss,其他的 mask 对这个 loss 没有贡献;
训练过程
这里其实跟 Faster R CNN 基本一致,IOU > 0.5 的是正样本,并且 L mask 只在正样本的时候才计算,图像变换到短边 800, 正负样本比例 1:3 , RPN 采用 5 个 scale(Faster R-CNN是三个) 以及 3 个 aspect ratio(Faster R-CNN是三个);
Inference细节
采用 ResNet 作为 backbone 的 Mask R-CNN 产生 300 个候选区域进行分类回归,采用 FPN 方法的生成 1000 个候选区域进行分类回归,然后进行非极大值抑制操作,最后检测分数前 100 的区域进行 mask 检测,这里没有使用跟训练一样的并行操作,作者解释说是可以提高精度和效率,然后 mask 分支可以预测 k 个类别的 mask,但是这里根据分类的结果,选取对应的第 k 个类别,得到对应的 mask 后,再 resize 到 ROI 的大小, 然后利用阈值 0.5 进行二值化即可。(这里由于 resize 需要插值操作,mask 最后并不是 ROI大小,而是一个相对较小的图, 所以需要进行 resize 操作。)
溶解实验
实验的图就不贴了,讲一下相关结论
- 网络越深,效果越深,用FPN比不用FPN好
- sigmoid比softmax效果好
- ROI-Align(相比RoIPool与RoIWarp)相关有提升,特别是AP75提升最明显,说明对精度提升很有用
- mask banch采用FCN效果最好(相比全连接)
另外作者实验,mask 分支采用不同的方法
方法一:对每个类别预测一个 mask ;
方法二:所有的都预测一个 mask,实验结果每个类预测一个 mask 别会好一些 30.3 vs 29.7 ;
对比下表,可见,在预测的时候即使不使用 mask 分支,结果精度也是很高的,下图中 Faster R CNN, ROI Align 是使用 ROI Align,而不使用 ROI Pooling 的结果,较 ROI Pooling的结果高了约 0.9 个点,但是比 MaskR-CNN 还是低了 0.9 个点,这个提升,作者将其归结为多任务训练的提升,由于加入了 mask 分支,带来的 loss 改变,间接影响了主干网络的效果;

Mask R-CNN用于人体关键点检测
网络结构如下,只是在最后多接了一个关键点检测的分支

- 人体关键点检测,作者对最后 m*m 的 mask 进行 one-hot 编码,并且,mask 中只有一个像素点是 foreground 其他的都是 background。
- 人体关键点检测,最后的输出是 softmax, 不再是 Sigmoid,作者解释说,这有利于单独一个点的检测。
- 人体关键点检测, 最后的 mask 分辨率是 56*56,不再是 28*28,作者解释,较高的分辨率有利于人体关键点的检测
MS-R-CNN
MS-R-CNN是mask R-CNN的一个改进,是由中科院出的一个改进,主要就是在Mask后面接了一个MaskIoU的评估指标,改进了Loss


