了解如何使用space实现定制的信息提取管道,并在Neo4j中存储结果
信息提取 (IE) 管道从文本等非结构化数据中提取结构化数据。互联网以各种文章和其他内容格式的形式提供了丰富的信息。但是,虽然您可能会阅读新闻或订阅多个播客,但几乎不可能跟踪每天发布的所有新信息。即使您可以手动阅读所有最新的报告和文章,构建数据以便您可以轻松地使用您喜欢的工具查询和汇总数据也将是非常乏味和劳动密集型的。我绝对不想将其作为我的工作。
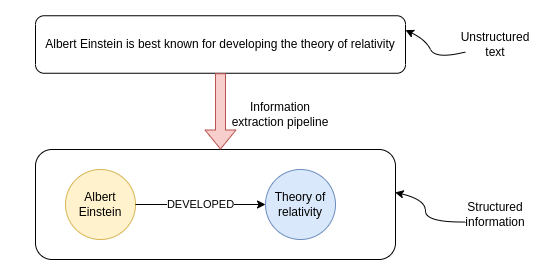
信息提取管道的目标是从非结构化文本中提取结构化信息
?虽然我已经实现并撰写了有关 IE 管道的文章,但我注意到开源 NLP 模型的许多新进展,尤其是在spaCy 方面。后来我了解到,我将在这篇文章中使用的大多数模型都只是简单地包装为 spaCy 组件,如果您愿意,可以使用其他库。然而,由于 spaCy 是我玩过的第一个 NLP 库,我决定在 spaCy 中实现 IE 管道,以感谢开发人员制作了如此出色且易于上手的工具。
我如何看待 IE 管道中的步骤随着时间的推移保持不变。
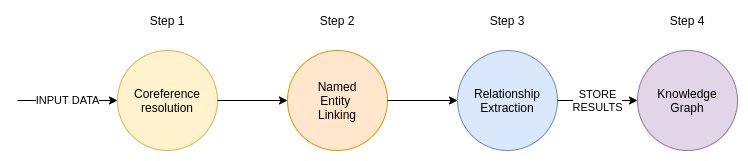
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?信息提取管道中的步骤。
IE 管道的输入是文本。该文本可以来自文章或内部业务文档。如果您处理 PDF 或图像,您可以使用计算机视觉来提取文本。此外,我们可以使用 voice2text 模型将录音转换为文本。准备好输入文本后,我们首先通过共指解析模型运行它。共指解析将代词转换为被指实体。大多数情况下,共指解析的示例是人称代词,例如,模型将代词替换为被提及的人的姓名。
下一步是识别文本中的实体。我们想要识别哪些实体完全取决于我们正在处理的用例,并且可能因域而异。例如,您经常会看到经过训练的 NLP 模型可以识别人员、组织和位置。然而,在生物医学领域,我们可能想要识别基因、疾病等概念。我还看到了一些示例,其中正在处理企业的内部文档以构建一个知识库,该知识库可以指向包含以下内容的文档回答用户可能拥有甚至为聊天机器人提供动力。在文本中识别实体的过程称为命名实体识别。
识别文本中的相关实体是一步,但您几乎总是需要对实体进行标准化。例如,假设文本引用了相对论和相对论。这两个实体指的是同一个概念,这似乎很明显。但是,尽管对您来说很简单,但我们希望尽可能避免手工劳动。并且机器不会自动将两个引用识别为相同的概念。这是命名?实体消歧或实体链接的地方发挥作用。命名实体消歧和实体链接的目标都是为文本中的所有实体分配一个唯一的 id。通过实体链接,从文本中提取的实体被映射到目标知识库中相应的唯一 ID。在实践中,您会看到维基百科被大量用作目标知识库。但是,如果您在更具体的领域工作或想要处理内部业务文档,那么维基百科可能不是最佳的目标知识库。请记住,实体必须存在于目标知识库中,实体链接过程才能将实体从文本映射到它。如果文本中提到了您和您的经理,并且你们俩都不在维基百科上,那么在实体链接过程中使用维基百科作为目标知识库是没有意义的。
最后,IE 管道然后使用关系提取模型来识别文本中提到的文本之间的任何关系。如果我们继续使用经理示例,假设我们有以下文本。
Alicia 是 Zach 的经理。
理想情况下,我们希望关系提取模型能够识别两个实体之间的关系。
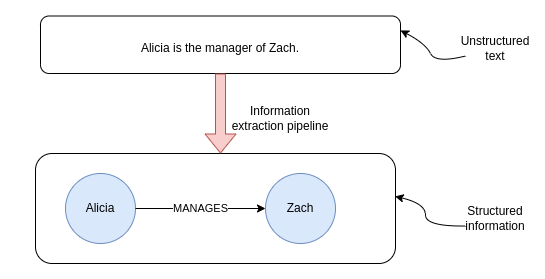
提取实体之间的关系
大多数关系抽取模型都经过训练,可以识别多种类型的关系,使信息抽取尽可能的丰富。
现在我们快速回顾了理论,我们可以跳到实际示例。
在 spaCy 中开发 IE 管道
在过去的几周里,围绕 spaCy 有了很大的发展,所以我决定尝试新的插件并使用它们来构建信息提取管道。
与往常一样,所有代码都可以在Github上找到。
共指解析
首先,我们将使用David Berenstein为 spaCy?Universe贡献的新的跨语言共指模型。SpaCy Universe 是 spaCy 的开源插件或插件的集合。spaCy Universe 项目最酷的地方在于,可以直接将模型添加到我们的管道中。
从Releases ・ Pandora-Intelligence/crosslingual-coreference ・ GitHub下载tar.gz文件,直接
pip install crosslingual-coreference会出错,
?

