��Ŀ:TransGate: Knowledge Graph Embedding with Shared Gate Structure
1 ����
Ŀǰ��ģ��,��ǰ��ģ��ͨ��רע�ڴ�Խ��Խ���ӵ����������������ض��ڹ�ϵ����Ϣ���Ľ�Ƕ��,������Щģ�����Ĵ�����ʱ��Ϳռ�,������ЧӦ������ʵ������������ݡ����������߲��ò�������,�ܹ�ѧϰ���������,���ٲ�������ģ���Ӹ��ӡ�����Gateģʽ���TransGate,���ò���Gate��˼�빹��ģ��,���������ģ�ͽ����ع����ٲ���,��ȻЧ����û�м��TransGate,Ҫ��һЩ,�������ܳ���������baselineģ��,���������ȷ�ʡ�
ĿǰһЩģ�ʹ��ڵ�����:
- ������,ģ�͵�ʮ���Ӵ�,����ѵ��
- ����embeddingά��ȥ����embeddingЧ��
- ���ڲ�������,����Ԥѵ����������,�Լ���ģ��ͬʱѵ����ʱ�䡣
2 ģ��
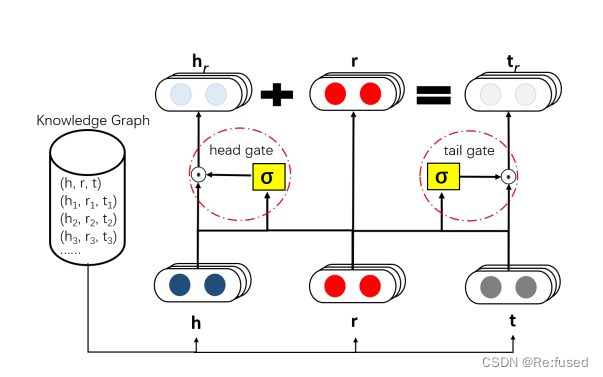
2.1 ģ��ͼ
2.2 ���ִ������
- Ƕ��entity��relation��һ��������ά����ͬ�Ŀռ�
- ������ͼ�е�һ��Ȧ, TransGate����head entity��tail entity�ֱ�����һ��Gate.
- ����head entity,��head embedding ��relation embedding ����һ��Gate�����IJ��� W h \mathbb W_h Wh?, ����������sigmoid,��ʵҲ�����൱�ڲ���һ�������š�
- ��ʵ�ֵ�Gate����֮��Ľ����������Ӧ�ĵ�head embedding ����tail embedding���,��ȡHadamard product����ʽ��
- �����������TransE��ģ��,ʵ�ִ�ֺ�����
2.3 ��ʽ
TransGate��Ϊ�����汾,������ϲ��,ֻ��������Gate�������÷�����ڲ���,һ���������汾�������ӽ���ConvE,����һ���Dz��������,�ֱ���TransGate(fc)��TransGate(wv)��
��������
h
,
r
,
t
��
R
m
\mathit{h,r, t} \in \mathbb R^m
h,r,t��Rm
2.3.1 TransGate(fc)
h
r
=
h
��
��
(
W
h
?
[
h
,
r
]
+
b
h
)
h_r = h \odot \sigma(W_h\cdot[h, r]+b_h)
hr?=h����(Wh??[h,r]+bh?)
t
r
=
t
��
��
(
W
t
?
[
t
,
r
]
+
b
t
)
t_r = t \odot \sigma(W_t\cdot[t, r]+b_t)
tr?=t����(Wt??[t,r]+bt?)
����
W
h
,
W
t
��
R
m
��
2
m
,
b
t
,
b
h
��
R
m
,
��
W_h, W_t \in \mathbb R^{m\times 2m}, b_t, b_h \in\mathbb R^m,\sigma
Wh?,Wt?��Rm��2m,bt?,bh?��Rm,��Ϊ����������ݵ�ȡֵ��Χ��(0, 1)֮��
2.3.2 TransGate(wv)
h
r
=
h
��
��
(
V
h
��
h
+
V
r
h
��
r
+
b
h
)
h_r = h \odot \sigma(V_h\odot h+V_{rh} \odot r+b_h)
hr?=h����(Vh?��h+Vrh?��r+bh?)
t
r
=
t
��
��
(
V
t
��
t
+
V
r
t
��
r
+
b
t
)
t_r = t \odot \sigma(V_t\odot t+V_{rt} \odot r+b_t)
tr?=t����(Vt?��t+Vrt?��r+bt?)
����
V
h
,
V
t
,
V
r
h
,
V
r
t
��
R
m
V_h, V_t, V_{rh}, V_{rt} \in \mathbb R^m
Vh?,Vt?,Vrh?,Vrt?��Rm
2.3.3 �����Ա�
m��Ϊentity embedding ά��,��n��Ϊrelation embeddingά��,
N
e
,
N
r
N_e, N_r
Ne?,Nr?�ֱ���ʵ�������ϵ������
�����ĸ��ӶȶԱ�:
fc�汾����Ϊ
O
(
4
m
2
+
2
m
)
O(4m^2+2m)
O(4m2+2m)
wv�汾����Ϊ
O
(
4
m
+
2
n
)
O(4m+2n)
O(4m+2n)
Ƕ��ռ��������һ��:
O
(
N
e
m
+
N
r
n
)
O(N_em+N_rn)
O(Ne?m+Nr?n)
2.3.4 ���ֺ���
���ֺ�����TransE�����ֺ�����һ�µ�,������ȷ����Ԫ��÷ֱȴ������Ԫ��÷ֵ͡�
f
r
=
�O
�O
h
r
+
r
?
t
r
�O
�O
L
1
/
L
2
f_r = || h_r+r-t_r||_{L_1/L_2}
fr?=�O�Ohr?+r?tr?�O�OL1?/L2??
3 ��ʧ����
��ʧ����Ϊmargin-based ranking criterion,��ʽ����:
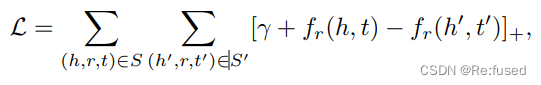
����
[
x
]
+
?
m
a
x
(
0
,
x
)
,
��
>
0
[x]_+\triangleq max(0, x), \gamma > 0
[x]+??max(0,x),��>0��margin�ij�����
4 ʵ����
4.1 ���Ӷ�
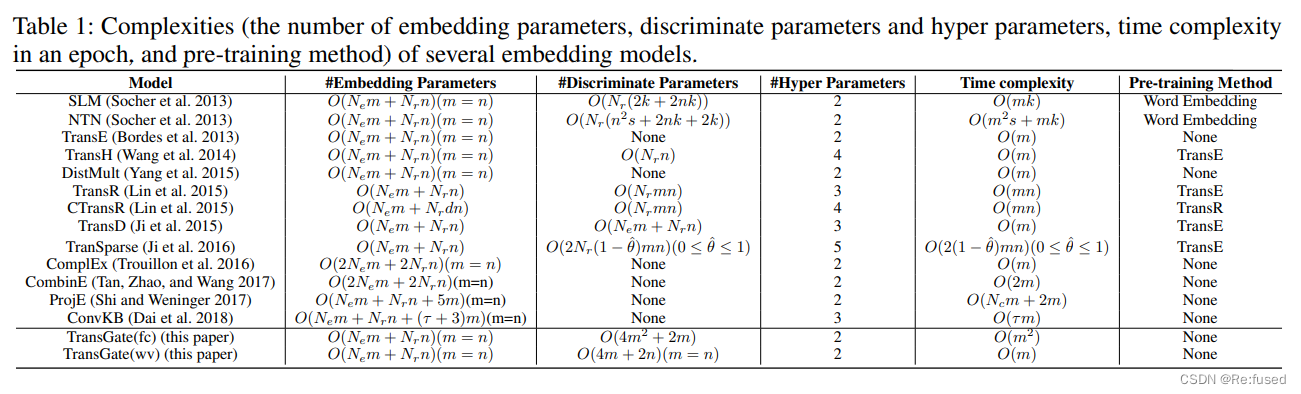
4.2 ģ��Ч���Ա�
����FB15k��FB15k-237����ģ��Ч�����ȽϺ�,����fc�汾��Ч����������wv�汾��Ч��,���Ƕ��ߵ�Ч��������baseline�汾��Ч��,������WN18RR����Ч���Ͳ������⡣