题目:
一、实验内容:
现有一个手机评论数据Mobile_new.csv文件,该文件的数据列包括手机品牌、价格和评分,请完成数据分析任务并将结果可视化,部分数据如下:

(1) 按手机品牌统计各评分个数。
(2) 完成绘制各品牌评分的*散点图、*折线图、'BlackBerry’评分柱状图、'ZTE’评分饼图的任务。
import pandas as pd
data=pd.read_csv("p:/data/Mobile.csv",header=None)
D:\anconda\lib\site-packages\IPython\core\interactiveshell.py:3165: DtypeWarning: Columns (4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19) have mixed types.Specify dtype option on import or set low_memory=False.
has_raised = await self.run_ast_nodes(code_ast.body, cell_name,
data
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Samsung | 199.99 | 5 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | Samsung | 199.99 | 4 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | Samsung | 199.99 | 4 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | Samsung | 199.99 | 1 | 1 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | Samsung | 199.99 | 2 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 327587 | Samsung | 79.95 | 5 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 327588 | Samsung | 79.95 | 3 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 327589 | Samsung | 79.95 | 5 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 327590 | Samsung | 79.95 | 3 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 327591 | Samsung | 79.95 | 4 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
327592 rows × 21 columns
data_test=data.iloc[:,:3]
data_test
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | Samsung | 199.99 | 5 |
| 1 | Samsung | 199.99 | 4 |
| 2 | Samsung | 199.99 | 4 |
| 3 | Samsung | 199.99 | 1 |
| 4 | Samsung | 199.99 | 2 |
| ... | ... | ... | ... |
| 327587 | Samsung | 79.95 | 5 |
| 327588 | Samsung | 79.95 | 3 |
| 327589 | Samsung | 79.95 | 5 |
| 327590 | Samsung | 79.95 | 3 |
| 327591 | Samsung | 79.95 | 4 |
327592 rows × 3 columns
data_test.columns
Int64Index([0, 1, 2], dtype='int64')
data_test.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 327592 entries, 0 to 327591
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 327592 non-null object
1 1 327592 non-null float64
2 2 327592 non-null int64
dtypes: float64(1), int64(1), object(1)
memory usage: 7.5+ MB
data_test[(data_test[0]=='BlackBerry') & (data_test[1]==106.85) & (data_test[2]==4)]
| 0 | 1 | 2 | |
|---|---|---|---|
| 66854 | BlackBerry | 106.85 | 4 |
| 66861 | BlackBerry | 106.85 | 4 |
| 66867 | BlackBerry | 106.85 | 4 |
| 66882 | BlackBerry | 106.85 | 4 |
| 66886 | BlackBerry | 106.85 | 4 |
| ... | ... | ... | ... |
| 67504 | BlackBerry | 106.85 | 4 |
| 67509 | BlackBerry | 106.85 | 4 |
| 67519 | BlackBerry | 106.85 | 4 |
| 67530 | BlackBerry | 106.85 | 4 |
| 67537 | BlackBerry | 106.85 | 4 |
92 rows × 3 columns
data_samsung=data_test.iloc[0:6,]
data_samsung
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | Samsung | 199.99 | 5 |
| 1 | Samsung | 199.99 | 4 |
| 2 | Samsung | 199.99 | 4 |
| 3 | Samsung | 199.99 | 1 |
| 4 | Samsung | 199.99 | 2 |
| 5 | Samsung | 199.99 | 2 |
data_BlackBerry=data_test.iloc[66854]
print(data_BlackBerry)
0 BlackBerry
1 106.85
2 4
Name: 66854, dtype: object
data_all=data_samsung.append(data_BlackBerry)
data_all=data_all.append(data_test.iloc[66861])
data_all
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | Samsung | 199.99 | 5 |
| 1 | Samsung | 199.99 | 4 |
| 2 | Samsung | 199.99 | 4 |
| 3 | Samsung | 199.99 | 1 |
| 4 | Samsung | 199.99 | 2 |
| 5 | Samsung | 199.99 | 2 |
| 66854 | BlackBerry | 106.85 | 4 |
| 66861 | BlackBerry | 106.85 | 4 |
-----------------START---------------------
import pandas as pd
import matplotlib.pyplot as plt
data_new=pd.read_csv("p:/data/Mobile_new.csv",header=None)
data_new=data_new.iloc[:,0:3]
data_new.columns=["品牌","价格","评分"]
data_new["品牌"]=pd.DataFrame(data_new["品牌"]) #转化为DataFrame类型
data_new["品牌"].value_counts()
BlackBerry 57
ZTE 55
Samsung 13
Huawei 10
Name: 品牌, dtype: int64
data_new.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 135 entries, 0 to 134
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 品牌 135 non-null object
1 价格 135 non-null float64
2 评分 135 non-null int64
dtypes: float64(1), int64(1), object(1)
memory usage: 3.3+ KB
# data_new["评分"]=data_new["评分"].astype(str)
data_sam=data_new[(data_new["品牌"]=="Samsung")]
# data_sam=data_new[(data_new["品牌"]=="Samsung")&(data_new["评分"]=="5")]
data_sam=data_sam["评分"].value_counts(sort=False)
print("Samsung的各评分个数为:\n",data_sam)
data_BlackBerry=data_new[(data_new["品牌"]=="BlackBerry")]
data_BlackBerry=data_BlackBerry["评分"].value_counts(sort=False)
print("BlackBerry的各评分个数为:\n",data_BlackBerry)
data_ZTE=data_new[(data_new["品牌"]=="ZTE")]
data_ZTE=data_ZTE["评分"].value_counts(sort=False)
print("ZTE的各评分个数为:\n",data_ZTE)
data_Huawei=data_new[(data_new["品牌"]=="Huawei")]
data_Huawei=data_Huawei["评分"].value_counts(sort=False)
print("Huawei的各评分个数为:\n",data_Huawei)
Samsung的各评分个数为:
1 2
2 2
3 1
4 2
5 6
Name: 评分, dtype: int64
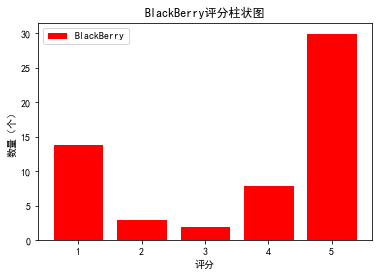
BlackBerry的各评分个数为:
1 14
2 3
3 2
4 8
5 30
Name: 评分, dtype: int64
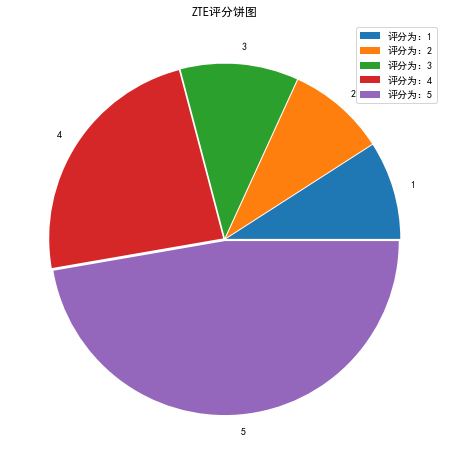
ZTE的各评分个数为:
1 5
2 5
3 6
4 13
5 26
Name: 评分, dtype: int64
Huawei的各评分个数为:
1 1
3 2
5 7
Name: 评分, dtype: int64
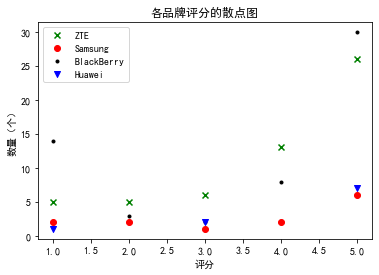
绘制各品牌评分散点图 折线图
data_samy=data_sam.tolist()
data_samx=data_sam.index.tolist()
data_BlackBerryy=data_BlackBerry.tolist()
data_BlackBerryx=data_BlackBerry.index.tolist()
data_ZTEy=data_ZTE.tolist()
data_ZTEx=data_ZTE.index.tolist()
data_Huaweiy=data_Huawei.tolist()
data_Huaweix=data_Huawei.index.tolist()
plt.rcParams['font.sans-serif']=['SimHei'] #用黑体显示中文
plt.rcParams['axes.unicode_minus']=False #正常显示负号
plt.figure()
plt.title("各品牌评分的散点图")
plt.xlabel('评分')
plt.ylabel('数量(个)')
plt.scatter(data_ZTEx,data_ZTEy,c='g',marker='x')
plt.scatter(data_samx,data_samy,c='r',marker='o')
plt.scatter(data_BlackBerryx,data_BlackBerryy,c='black',marker='.')
plt.scatter(data_Huaweix,data_Huaweiy,c='b',marker='v')
plt.legend(["ZTE","Samsung","BlackBerry","Huawei"])
plt.show()
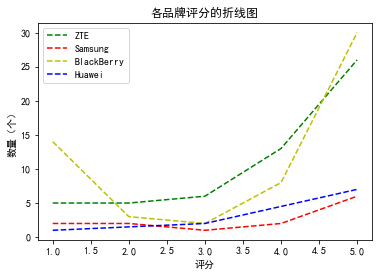
plt.figure()
plt.title("各品牌评分的折线图")
plt.xlabel('评分')
plt.ylabel('数量(个)')
plt.plot(data_ZTEx,data_ZTEy,"g--")
plt.plot(data_samx,data_samy,"r--")
plt.plot(data_BlackBerryx,data_BlackBerryy,"y--")
plt.plot(data_Huaweix,data_Huaweiy,"b--")
plt.legend(["ZTE","Samsung","BlackBerry","Huawei"])
plt.show()
'BlackBerry’评分柱状图
plt.figure()
plt.title("BlackBerry评分柱状图")
plt.xlabel('评分')
plt.ylabel('数量(个)')
plt.bar(data_BlackBerryx,data_BlackBerryy,color="red",edgecolor="white")
plt.legend(["BlackBerry"])
plt.show()
'ZTE’评分饼图
plt.figure(figsize=(8,8))
plt.title("ZTE评分饼图")
label=["1","2","3","4","5"]
plt.pie(data_ZTEy,explode=[0.01,0.01,0.01,0.01,0.01],labels=label)
plt.legend(["评分为:1","评分为:2","评分为:3","评分为:4","评分为:5"])
plt.show()
?
?

