
1 语音预处理
本章主要内容是基于wave框架进行操作,主要步骤包括:
????????音频数据属性查看
????????音频数据转换矩阵
????????音频频谱
????????音频波形
1.1 音频的基本属性
import wave as we
import numpy as np
from scipy.io import wavfile
import warnings
warnings.filterwarnings("ignore")
fileName = './data/thchs30/train/A2_0.wav'
# 输出信息 (声道,采样宽度,帧速率,帧数,唯一标识,无损)
WAVE = we.open(fileName) # 打开一个音频文件
for item in enumerate(WAVE.getparams()):
print(item)
a = WAVE.getparams().nframes
print('帧总数:',a)
f = WAVE.getparams().framerate
print('采样频率:',f)
sample_time = 1/f
print('采样点的时间间隔:',sample_time)
time = a/f
print('声音信号的长度:',time)
sample_frequency, audio_sequence = wavfile.read(fileName)
print('声音信号每一帧的大小:',audio_sequence,len(audio_sequence ))
x_seq = np.arange(0,time,sample_time)
print(x_seq,len(x_seq))
"""
(0, 1)
(1, 2)
(2, 16000)
(3, 157000)
(4, 'NONE')
(5, 'not compressed')
帧总数: 157000
采样频率: 16000
采样点的时间间隔: 6.25e-05
声音信号的长度: 9.8125
声音信号每一帧的大小: [-296 -424 -392 ... -394 -379 -390] 157000
[0.0000000e+00 6.2500000e-05 1.2500000e-04 ... 9.8123125e+00 9.8123750e+00
?9.8124375e+00] 157000
"""
1.2 波形序列
import wave as we
import matplotlib.pyplot as plt
import numpy as np
from scipy.io import wavfile
import warnings
warnings.filterwarnings("ignore")
fileName = './data/thchs30/train/A2_1.wav'
WAVE = we.open(fileName) # 打开一个音频文件
a = WAVE.getparams().nframes
print('帧总数:',a)
f = WAVE.getparams().framerate
print('采样频率:',f)
sample_time = 1/f
print('采样点的时间间隔:',sample_time)
time = a/f
sample_frequency, audio_sequence = wavfile.read(fileName)
x_seq = np.arange(0,time,sample_time)
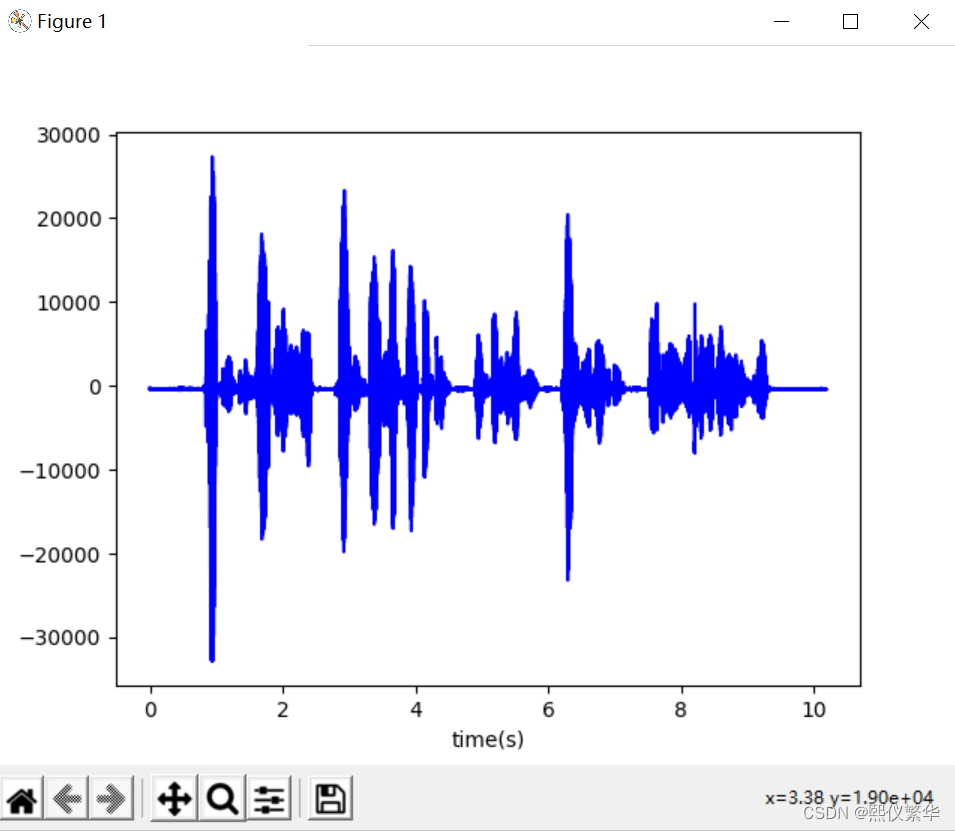
# 查看波形序列
plt.plot(x_seq,audio_sequence,'blue')
plt.xlabel('time(s)')
plt.show()
?1.3 文件信息的获取
import wave as we
import matplotlib.pyplot as plt
import numpy as np
from scipy.io import wavfile
from matplotlib.backend_bases import RendererBase
from scipy import signal
from scipy.io import wavfile
import os
from PIL import Image
from scipy.fftpack import fft
import warnings
warnings.filterwarnings("ignore")
audio_path = './data/train/audio/'
pict_Path = './data/picts/train/'
samples = []
# 验证文件是否存在,若不在这,则创建
if not os.path.exists(pict_Path):
os.makedirs(pict_Path)
subFolderList= []
for x in os.listdir(audio_path): # 遍历audio_path目录下的目录
if os.path.isdir(audio_path+'/'+x): # 判断是否是一个目录,是目录则添加到subFolderList
subFolderList.append(x)
if not os.path.exists(pict_Path + '/' + x): # 判断x目录在pict_Path路径下是否存在
os.mkdir(pict_Path + x) # 不存在则创建
# 查看子文件名称和数量
print('子文件名称:\n',subFolderList)
print('子文件数量:\n',len(subFolderList))1.4 统计每个子文件夹语音文件数量
# 统计每个子文件夹语音文件数量
sample_audio=[]
total=0
for x in subFolderList:
# 获取所有wav文件
all_files=[y for y in os.listdir(audio_path+x) if '.wav' in y]
total+=len(all_files)
sample_audio.append(audio_path+x+'/'+all_files[0])
# print(sample_audio)
# 查看每个子文件夹文件数量
print('%s:count:%d'%(x,len(all_files)))
# 查看wav文件总数
print("TOTAL:",total)运行:
bed:count:10
bird:count:15
cat:count:17
dog:count:20
down:count:36
eight:count:16
five:count:16
four:count:22
go:count:18
happy:count:16
house:count:15
left:count:20
marvin:count:19
nine:count:14
no:count:16
off:count:20
on:count:11
one:count:18
right:count:22
seven:count:20
sheila:count:17
six:count:15
stop:count:12
three:count:19
tree:count:14
two:count:12
up:count:10
wow:count:18
yes:count:17
zero:count:20
_background_noise_:count:6
TOTAL: 521?1.5 查看每个子文件当中第一个文件
# 查看每个子文件当中第一个文件
for x in sample_audio:
print(x)运行结果:
./data/train/audio/bed/00f0204f_nohash_0.wav
./data/train/audio/bird/00b01445_nohash_0.wav
./data/train/audio/cat/00b01445_nohash_0.wav
./data/train/audio/dog/fc2411fe_nohash_0.wav
./data/train/audio/down/fbdc07bb_nohash_0.wav
./data/train/audio/eight/fd395b74_nohash_0.wav
./data/train/audio/five/fd395b74_nohash_2.wav
./data/train/audio/four/fd32732a_nohash_0.wav
./data/train/audio/go/00b01445_nohash_0.wav
./data/train/audio/happy/fbf3dd31_nohash_0.wav
./data/train/audio/house/fcb25a78_nohash_0.wav
./data/train/audio/left/00b01445_nohash_0.wav
./data/train/audio/marvin/fc2411fe_nohash_0.wav
./data/train/audio/nine/00b01445_nohash_0.wav
./data/train/audio/no/fe1916ba_nohash_0.wav
./data/train/audio/off/00b01445_nohash_0.wav
./data/train/audio/on/00b01445_nohash_0.wav
./data/train/audio/one/00f0204f_nohash_0.wav
./data/train/audio/right/00b01445_nohash_0.wav
./data/train/audio/seven/0a0b46ae_nohash_0.wav
./data/train/audio/sheila/00f0204f_nohash_0.wav
./data/train/audio/six/00b01445_nohash_0.wav
./data/train/audio/stop/0ab3b47d_nohash_0.wav
./data/train/audio/three/00b01445_nohash_0.wav
./data/train/audio/tree/00b01445_nohash_0.wav
./data/train/audio/two/00b01445_nohash_0.wav
./data/train/audio/up/00b01445_nohash_0.wav
./data/train/audio/wow/00f0204f_nohash_0.wav
./data/train/audio/yes/00f0204f_nohash_0.wav
./data/train/audio/zero/0ab3b47d_nohash_0.wav
./data/train/audio/_background_noise_/doing_the_dishes.wav
1.6 多样本单个频谱可视化
# 构建频谱处理函数
def log_specgram(audio,sample_rate,window_size=20,step_size=10,eps=1e-10):
nperseg=int(round(window_size*sample_rate/1e3))
noverlap=int(round(step_size*sample_rate/1e3))
freqs,_,spec=signal.spectrogram(audio,
fs=sample_rate,
window='hann',
nperseg=nperseg,
noverlap=noverlap,
detrend=False
)
return freqs,np.log(spec.T.astype(np.float32)+eps)
# 多样本单个频谱可视化
fig=plt.figure(figsize=(20,20))
for i,filepath in enumerate(sample_audio[:16]):
#make subplots
plt.subplot(4,4,i+1)
#pull the labels
label=filepath.split('/')[-2]
plt.title(label)
#create spectrogram
samplerate,test_sound=wavfile.read(filepath)
_,spectrogram=log_specgram(test_sound,samplerate)
plt.imshow(spectrogram.T,aspect='auto',origin='lower')
plt.axis("off")
plt.show()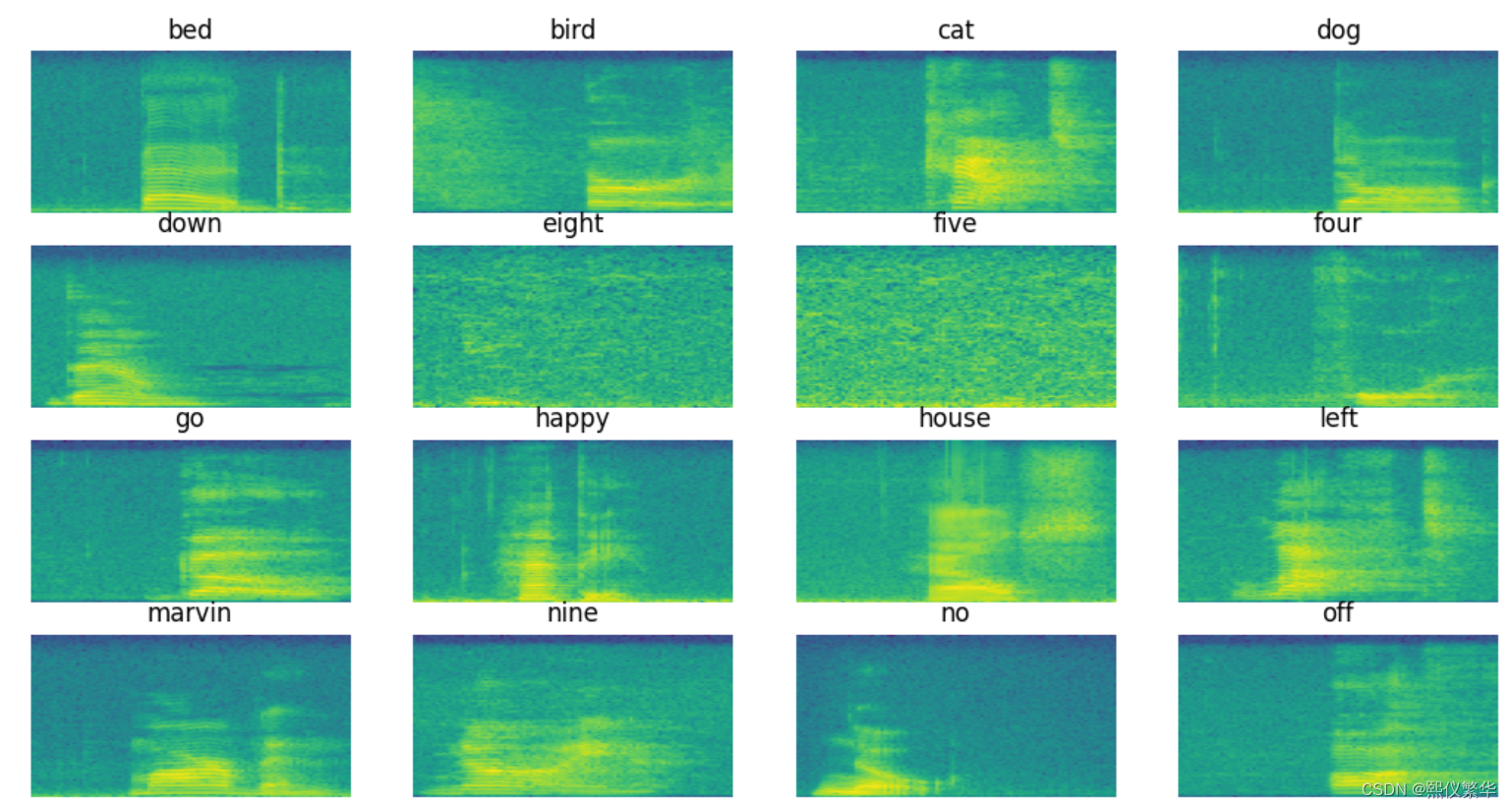
实验二 GMM+HMM?
# 导入依赖
from python_speech_features import mfcc
from scipy.io import wavfile
from hmmlearn import hmm
import joblib
import numpy as np
import os
# 定义数据目录
trainPath = 'training_data'
testPath = 'test_data'
def get_wavlist(wavpath):
'''
获取数据
:param wavpath: 路径
:return:
'''
wavdict = {}
labeldict = {}
'''
dirpath:当前遍历的目录
dirnames:当前遍历的目录下的目录列表
filenames:当前遍历的目录下的文件列表
'''
for (dirpath,dirnames,filenames) in os.walk(wavpath):
for filename in filenames:
if filename.endswith('.wav'): # 判断是否是wav文件
filepath = os.sep.join([dirpath,filename])
fileid = filename.strip('.wav')
wavdict[fileid] = filepath
label = fileid.split('_')[1]
labeldict[fileid] = label
return wavdict,labeldict
def compute_mfcc(file):
'''
特征提取
:param file:
:return:
'''
fs,audio = wavfile.read(file) # 读取语音文件
'''
mfcc() 特征提取
参数:
signal : 待操作的文件
samplerate:我们用来工作的信号的采样率
numcep: 倒频谱返回的数量 默认是13
'''
mfcc_feat = mfcc(audio,samplerate=(fs/2),numcep=26)
return mfcc_feat
class Model():
def __init__(self,CATEGORY,n_comp=3,n_mix =3,cov_type = 'diag',ecpe= 1000):
'''
:param CATEGORY: 标签列表
:param n_comp: 每个孤立词中的状态数
:param n_minx: 每个状态包含的混合高斯数量
:param cov_type: 协方差矩阵的类型
:param ecpe: 训练迭代的次数
'''
self.CATEGORY = CATEGORY
self.category = len(CATEGORY)
self.n_comp = n_comp
self.n_mix = n_mix
self.cov_type = cov_type
self.ecpe = ecpe
# 初始化models,返回特定参数的模型列表
self.models = []
for k in range(self.category):
model = hmm.GMMHMM(n_components=self.n_comp,n_mix=self.n_mix,covariance_type=self.cov_type,
n_iter=ecpe) # 创建GMM-HMM模型
self.models.append(model)
def train(self,wavdict=None,labeldict=None):
'''
进行模型训练
:param wavdic: 训练数据
:param labeldict: 训练目标值
:return:
'''
for k in range(self.category):
subdata = []
model = self.models[k] # 把前面定义好的模型获取出来
for x in wavdict:
if labeldict[x] == self.CATEGORY[k]: # 判断CATEGORY列表中是否存在labeldict[x]标签
mfcc_feat = compute_mfcc(wavdict[x]) #提取数据特征
model.fit(mfcc_feat)
def test(self,wavdict=None,labeldict=None):
'''
测试模型
:param wavdict:
:param labeldict:
:return:
'''
resul = [] # 存放测试结果
for k in range(self.category):
subre = []
label = []
model = self.models[k]
for x in wavdict:
mfcc_feat = compute_mfcc(wavdict[x])
# 生成每个数据在当前模型下的得分情况
re = model.score(mfcc_feat)
subre.append(re)
label.append(labeldict[x])
# 汇总得分情况
resul.append(subre)
# 选取得分最高的种类
result = np.vstack(resul).argmax(axis=0)
# 返回种类的类别标签
result = [self.CATEGORY[l] for l in result]
print('识别得到的结果:\n',result)
print('原始标签类别:\n',label)
# 检查识别率
totalnum = len(label) # 统计总数
correctnum = 0 # 用于记录识别正确的个数
for i in range(totalnum):
if result[i] == label[i]: # 判断识别的结果和真实结果是否相等
correctnum += 1
print('识别率:',correctnum/totalnum)
def save(self,path='model.pkl'):
'''
保存模型
:param path: 模型保存路径
:return:
'''
joblib.dump(self.models,path)
def load(self,path='model.pkl'):
'''
加载模型
:param path:
:return:
'''
self.models = joblib.load(path)
# 准备训练所需要的数据
CATEGORY = ['1','2','3','4','5','6','7','8','9','10'] # 标签列表
wavdict,labeldict = get_wavlist(trainPath) # 获取训练的语音数据和标签
testdict,testlabel = get_wavlist(testPath) # 获取测试的语音数据和标签
# print(wavdict) "{'10_1': 'training_data\\10_1.wav', '10_10': 'training_data\\10_10.wav', ...}"
# print(labeldict) "{'10_1': '1', '10_10': '10', ..."
# 进行模型训练
# models = Model(CATEGORY=CATEGORY)
# if not os.path.exists('model.pkl'):
# models.train(wavdict=wavdict, labeldict=labeldict)
# models.save()
# else:
# models.load()
# models.test(wavdict=testdict,labeldict=testlabel)

