文章目录
Neural Ranking Models
- 优点:避免手工特征
- 本文仅考虑text
- 仅考虑dense表示,构建排序函数
排序模型:
- vector space models [1],
- probabilistic models [2],
- learning to rank(LTR) models [3, 4]
神经网络
- 从原始输入中学习抽象表示
- 可解决困难问题
以前的LTR模型:
- 手工特征(耗时、具体)
- 相关性:定义模糊
稀疏表示/表示学习方法
- 不使用神经网络构建排序函数
- 用神经模型[15,16]的文本的低维表示,并在传统的红外模型中使用它们,
- or,使用一些新的相似性度量来排序任务。
深度-密集表示(2013-)
- 2014-2015:短文本
- Deep Structured Semantic Model (DSSM) [13]
- the ad-hoc retrieval task.
- Lu and Li[14] proposed DeepMatch,
- Community-based Question Answering (CQA)
- micro-blog matching tasks.
- ARC I and ARC II [17]
- MatchPyramid [18]
- Deep Structured Semantic Model (DSSM) [13]
- 以上用于: short text ranking tasks,such as TREC QA tracks and Microblog tracks [19].
- 2016:
- 研究人员开始讨论神经排序模型对不同排序任务[21,22]的实际有效性
- 任务:
- ad-hoc retrieval [23, 24]
- community-based QA [25]
- conversational search [26]
- 新的训练范式:
- neural representations [28]
- integration of external knowledge [29, 30
- 其他IR用途: [31, 32].
- 从0学习:(完全无手工特征)超过手工的效果
数据集
- ad hoc:short-long
- Robust [21, 18],
- ClueWeb [21],
- GOV2 [33, 34]
- Microblog[33],
- the AOL log [27]
- the Bing Search log [13, 47, 48,23].
- 大规模: NTCIR WWW Task [49],
- QA:问题比query长,答案比doc短,相关性定义精确
- TREC QA [53]
- WikiQA [37],
- WebAP [57, 58],
- InsuranceQA [59],
- WikiPassageQA [56]
- MS MARCO [36].
- 模型 [60, 19, 61, 25, 14]
- Community Question Answering:短-短(问题间匹配),清晰,对称
- the Quora Dataset7,
- Yahoo! Answers Dataset [25]
- and SemEval-2017 Task3 [64].
- 最近CQADupStack8[65],
- ComQA9[66]
- LinkSO [67].
- 模型:[68, 18, 69, 70, 25]
- Automatic Conversation
- 从问题集合中选择适当响应、生成关于输入对话的适当响应
- 单轮对话、多轮对话
- 无词表匹配问题
- 问题: correspondence/coherence and avoid general trivial responses
- 数据集:
- Ubuntu Dialog Corpus (UDC) [75,77, 78],
- Sina Weibo dataset [74, 26, 79, 80],
- MSDialog [81, 30, 82]
- ”campaign” NTCIR STC [83]
3. 同一框架
框架:LTR

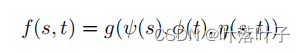
- 传统:
- 函数固定
- s,t为原始文本
- 神经网络:
- 所有的函数ψ、φ、η和g都被编码在网络结构中,因此它们都可以从训练数据中学习到。
- s,t为原始文本或者word embedding
4. 模型结构-对称与非对称
对称结构:s,t可互换
假设:同质假设
任务:CQA/AC
- 通过减少异质性用于ad-hoc和QA
- 仅适用doc标题
- 短的答案句子
代表:
- siamese networks
- symmetric interaction networks
siamese networks
DSSM [13], CLSM [47] and LSTMRNN [48]
-
DSSM:两个一样的处理
- letter-trigram mapping+ MLP
- cos
-
CLSM [47]
- CNN:局部词序信息
-
LSTM-RNN [48]:
- LSTM:长距离依赖信息
Symmetric interaction networks,
DeepMatch [14], Arc-II [17], MatchPyramid [18] and Match-SRNN [69]
Arc-II [17]:
- 计算s和t上每个n-gram对之间的相似度
- score:CNN+max pooling多个获得最终相似度
MatchPyramid:
- 计算每个词对之间的相似度
- 细粒度
- score:2D CNN+dynamic pooling layer
- 将匹配矩阵视作图像(二维)
PACRR [24]
- 将匹配矩阵视作图像(二维)
非对称结构
query和doc:异质
如果互换,则输出完全不同
任务:ad-hoc/QA

query split
假设:query:基于关键字
- query―>相应的term
- model:DRMM[21]
DRMM[21]
- query拆分为term,
- 交互:query 拆分为多个term,计算每个term和doc的相似度(FFC)
- socre:相似度聚合函数(gating network)
KNRM[85]
- kernel pooling函数近似匹配histogram mapping
- 端到端
document split
假设:长文本的部分与query相关
- 得到细粒度的交互信号
HiNT [34]
- 滑动窗口:分割段落
- 相似度:cos
Joint split,
假设:
- doc:长文本的部分与query相关
- query:基于关键字
DeepRank [33]
- 依据每个query term,将doc划分为以term为中心的上下文
one-way attention mechanism
利用问题表示来获得对候选答案词的关注,以增强答案表示
IARNN [86]
CompAgg [87]
- 得到由问题句子表示加权的注意答案表示序列。
基于表示的模型和基于交互的模型
- 表示函数 or 交互函数
- representation-focused architecture
- interaction-focused architecture
- 混合结构

representation-focused architecture
假设:相关性取决于输入文本的组成含义( compositional meaning)
表示函数:ffn,cnn,rnn…
交互函数:无
得分函数:g(cos,mlp,…)
MLP:DSSM
CNN:
- Arc-I [17],
- CNTN [25]
- CLSM [47】
RNN:
LSTM-RNN [48] and MV-LSTM [88]
模型:
Arc-I [17],
- 1D CNN+Max pooling
- concat:MLP
CNTN:
- score:neural tensor layer替代MLP
LSTM-RNN:
- encoder:单向LSTM
MVLSTM
- encoder:bi-LSTM
- MLP
通过基于每个输入文本的高级表示来评估相关性,以表示为中心的架构更好地适合于全局匹配需求[21]。
任务:CQA/AC
适用于:在线
- 表示可以离线学习
- 优点:
- 与全局匹配的需求匹配
- 适合短输入文本,长文本难以获得好的高层表示
- 在线
interaction-focused architecture
假设:相关性在本质上是输入文本之间的关系,所以从交互中学习更高效
non-parametric interaction functions and parametric interaction functions
这种架构可以更好地适合需要特定匹配模式(例如,精确的单词匹配)和不同匹配需求[21],
适合异质任务
- ad-hoc
- QA
适合离线,不适合在线
优点:
- 估计相似度定义在交互上,可以满足大多IR
- 通过详细IR,而非单个文本表示,可以更好地适应需要特定匹配和不同匹配需求的任务(exact word matching,ad-hoc)
- 更好地拟合异构输入任务,因为避开了对长文本的编码
- 不适合在线
non-parametric interaction functions
反应输入之间的距离或者接近程度
输入:每一对word vectors
binary indicator function [18, 33], cosine similarity function [18, 61, 33],
dot-product function [18, 33, 34] and radial-basis function [18]
其他:
. the
matching histogram mapping in DRMM [21] and the kernel pooling layer
in K-NRM [85].
parametric interaction functions
Arc-II [17]
-
1D convolutional layer for the interaction bwteen two phrases.
-
Match-SRNN [69]
- the neural tensor layer to model complex interactions between input words.
混合结构
混合表示和交互
- 组合策略
- 耦合策略
Combined strategy
较为松散
将基于表示的和基于交互的输出结合在一起
DUET [23]
- CLSM-like
- MatchPyramid-like
- 两者输出结合得到最终输出
Coupled strategy
IARNN [86] and CompAgg [87],
模型结构: Single-granularity vs. Multi-granularity Architecture
依据相关性估计过程的不同假设划分
Single-granularity
假设:基于φ,ψ和η从单格式文本输入中提取的高层特征来评估相关性
φ,ψ和η:两个表示函数,一个交互函数
输入:words 或 word embeddings
eg:DSSM、MatchPyramid、DRMM、HiNT、ARC-I、MV-LSTM、K-NRM、Match-SRNN等。
Multi-granularity Architecture
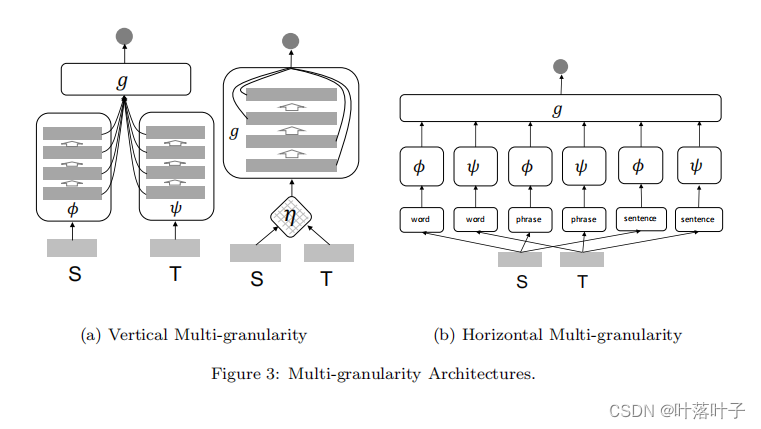
假设:相关性估计需要多粒度的特征
- 不同级别的特征抽象
- 不同类型的语言单元
划分
- 垂直多粒度:利用了深层网络的分层性质,使得评估函数g可以利用特征的不同级别抽象来进行相关性估计。
- 水平多粒度:通过将输入从单词(words)扩展到短语/n元串(phrases/n-grams)或句子(sentences)来增强输入,在每个输入形式上应用特定的单粒度体系结构,并聚合最终相关性输出的所有粒度。
任务:
- ad-hoc retrieval
- QA
模型学习
Pointwise:交叉熵
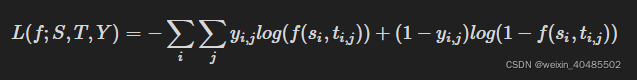
优点:
- 易于扩展:pointwise ranking objectives 基于每个query-document pair (si,ti,j) 分别计算,这使得它很简单且易于扩展。
- 实际含义与价值:以 pointwise loss function 作为损失函数的 neural model 的输出往往在实际中有真实的含义和价值。
缺点:效率低,达不到全局最小。
一般而言,按点排序目标在排序任务中被认为效率较低。因为逐点损失函数不考虑文档偏好或排序信息,因此它们不能保证在模型损失达到全局最小值时可以生成最佳的排序列表。
pairwise:margin loss/交叉熵
hinge loss:
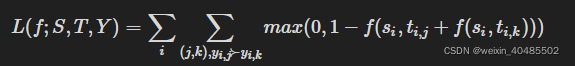
交叉熵:
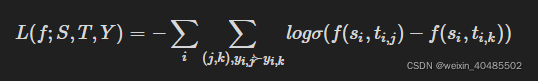
优点:有效,最优结果列表
理想情况下,当成对排序损失最小化时,文档之间的所有偏好关系都应该得到满足,并且模型将为每个查询生成最优结果列表。这使 pairwise ranking objectives 在根据相关文档的排序来评估性能的许多任务中有效。
缺点:然而,在实践中,由于以下两个原因,在 pairwise 方法中优化文档偏好并不总是导致最终ranking metrics 的改进:
- 理想只是理想:开发一个在所有情况下都能正确预测文档偏好的排序模型是不可能的。
- 重要性不一致:在大多数现有排名度量的计算中,并不是所有的文档对都同等重要。
Listwise
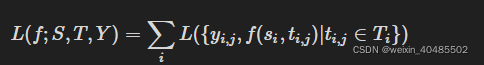
loss:ListMLE、Attention Rank function
优点
- 有效: 当我们在无偏学习框架下用用户行为数据(例如,点击)训练神经排序模型时,它特别有用。
- re-rank: 它们适用于对一小部分候选文档的重新排序阶段(re-ranking phase)。由于许多实用的搜索系统现在使用神经模型进行文档重新排序,因此 Listwise Ranking Objective 在神经排序框架中变得越来越流行。
缺点:成本高:虽然列表排序目标通常比成对排序目标更有效,但其高昂的计算成本往往限制了它们的应用。
多任务学习
模型比较
在 ad-hoc retrieval 任务上的比较
① 概率模型(即QL和BM25)虽然简单,但已经可以达到相当好的性能。具有人为设计特征的传统PRF模型(RM3)和LTR模型(RankSVM和LambdaMart)是强基线,其性能是大多数基于原始文本的神经排序模型难以比拟的。然而,PRF技术也可以用来增强神经排序模型,而人类设计的LRT特征可以集成到神经排序模型中以提高排序性能。
② 随着时间的推移,该任务中的 neural ranking model architecture 似乎从对称到不对称,从以表示为中心到以交互为中心的范式发生转变。的确,不对称和以交互为中心的结构可能更适合表现出异构性的ad-hoc检索任务。
③ 在不同数量的查询和标签方面具有更大的数据量的神经模型更有可能获得更大的性能改进。(与非神经模型相比)
④ 观察到,通常情况下,非对称的、关注交互的、多粒度的架构可以在ad-hoc检索任务中工作得更好。
在 QA 任务上的比较
① 可能因为问题和答案之间的同构性的增加,对称(symmetric)结构在 QA 任务中得到了更广泛的采用。
② 表示=交互:在QA任务中,以表示为中心的架构和以交互为中心的架构没有一个明显的胜者。在 short answer sentence retrieval 数据集(即TREC QA和WikiQA)上更多地采用了以表示为中心的架构,而在longer answer passage retrieval 数据集(例如Yahoo!)上更多地采用了以交互为中心的架构。
③ 与ad-hoc检索类似,在较大的数据集上,神经模型比非神经模型更有可能获得更大的性能改进。

