for basics on point cloud, see:
(3D Imaging) Point Cloud_EverNoob的博客-CSDN博客
Moving Point Cloud Processing: PointRNN
https://arxiv.org/abs/1910.08287
In this paper, we introduce a Point Recurrent Neural Network (PointRNN) for moving point cloud processing. At each time step, PointRNN takes point coordinates?P∈Rn×3?and point features?X∈Rn×d?as input (n?and?d?denote the number of points and the number of feature channels, respectively). The state of PointRNN is composed of point coordinates?P?and point states?S∈Rn×d′?(d′?denotes the number of state channels). Similarly, the output of PointRNN is composed of?P?and new point features?Y∈Rn×d′′?(d′′?denotes the number of new feature channels). Since point clouds are orderless, point features and states from two time steps can not be directly operated. Therefore, a point-based spatiotemporally-local correlation is adopted to aggregate point features and states according to point coordinates. We further propose two variants of PointRNN, i.e., Point Gated Recurrent Unit (PointGRU) and Point Long Short-Term Memory (PointLSTM). We apply PointRNN, PointGRU and PointLSTM to moving point cloud prediction, which aims to predict the future trajectories of points in a set given their history movements. Experimental results show that PointRNN, PointGRU and PointLSTM are able to produce correct predictions on both synthetic and real-world datasets, demonstrating their ability to model point cloud sequences. The code has been released at \url{this https URL}.
download pdf:
https://arxiv.org/pdf/1910.08287
3D Object Detection: PV-RCNN
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection | Papers With Code
https://arxiv.org/abs/1912.13192
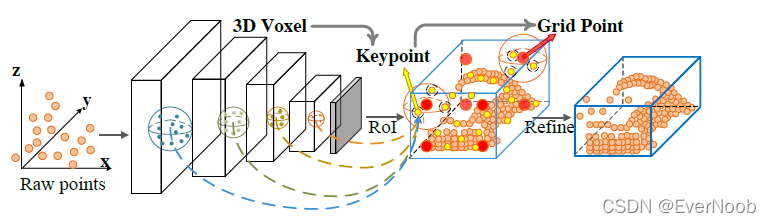
We present a novel and high-performance 3D object detection framework, named PointVoxel-RCNN (PV-RCNN), for accurate 3D object detection from point clouds. Our proposed method deeply integrates both 3D voxel Convolutional Neural Network (CNN) and PointNet-based set abstraction to learn more discriminative point cloud features. It takes advantages of efficient learning and high-quality proposals of the 3D voxel CNN and the flexible receptive fields of the PointNet-based networks. Specifically, the proposed framework summarizes the 3D scene with a 3D voxel CNN into a small set of keypoints via a novel voxel set abstraction module to save follow-up computations and also to encode representative scene features. Given the high-quality 3D proposals generated by the voxel CNN, the RoI-grid pooling is proposed to abstract proposal-specific features from the keypoints to the RoI-grid points via keypoint set abstraction with multiple receptive fields. Compared with conventional pooling operations, the RoI-grid feature points encode much richer context information for accurately estimating object confidences and locations. Extensive experiments on both the KITTI dataset and the Waymo Open dataset show that our proposed PV-RCNN surpasses state-of-the-art 3D detection methods with remarkable margins by using only point clouds. Code is available at?this https URL.
download pdf:
https://arxiv.org/pdf/1912.13192.pdf
Paper Notes
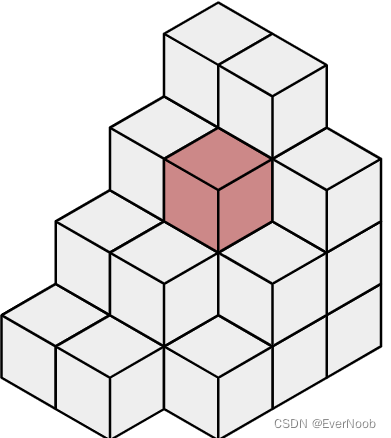
Voxel
https://en.wikipedia.org/wiki/Voxel
A series of voxels in a stack, with a single voxel shaded
In?3D computer graphics, a?voxel?represents a value on a?regular grid?in?three-dimensional space. As with?pixels?in a 2D?bitmap, voxels themselves do not typically have their position (i.e.?coordinates) explicitly encoded with their values. Instead,?rendering?systems infer the position of a voxel based upon its position relative to other voxels (i.e., its position in the?data structure?that makes up a single?volumetric image).
In contrast to pixels and voxels,?polygons?are often explicitly represented by the coordinates of their?vertices?(as?points). A direct consequence of this difference is that polygons can efficiently represent simple 3D structures with much empty or homogeneously filled space, while voxels excel at representing regularly sampled spaces that are non-homogeneously filled.
A voxel is a unit of graphic information that defines a point in three-dimensional space. Since a?pixel?(picture element) defines a point in two dimensional space with its X and Y coordinates , a third?z coordinate?is needed. In 3-D space, each of the coordinates is defined in terms of its position, color, and density. Think of a cube where any point on an outer side is expressed with an?x?,?y?coordinate and the third,?z?coordinate defines a location into the cube from that side, its density, and its color. With this information and 3-D rendering software, a two-dimensional view from various angles of an image can be obtained and viewed at your computer.
Medical practitioners and researchers are now using images defined by voxels and 3-D software to view X-rays, cathode tube scans, and magnetic resonance imaging (MRI) scans from different angles, effectively to see the inside of the body from outside. Geologists can create 3-D views of earth profiles based on sound echoes. Engineers can view complex machinery and material structures to look for weaknesses
==> !!! transforming point cloud to voxels, or voxelization, is often regarded as a discretizatoin process, which clear indicates that voxels is often at a more coarse granularity than points of point cloud?
PointNet
PointNet++?==> for PointNet based set abstraction
RCNN:RCNN and Variants
RCNN and Variants_EverNoob的博客-CSDN博客
3D (Voxel) CNN
==> a straight forward adaptation of regular 2D CNN into 3D, procedurally identical; more, see:
RoI
RoI: Region of Interest Projection and Pooling_EverNoob的博客-CSDN博客
Grid-based vs. Point-based
The grid-based methods generally transform the irregular point clouds to regular representations such as 3D voxels?or 2D bird-view maps, which could be efficiently processed?by 3D or 2D Convolutional Neural Networks (CNN) to learn point features for 3D detection. Powered by the pioneer work, PointNet and its variants, the pointbased methods? directly extract discriminative features from raw point clouds for 3D detection. Generally, the grid-based methods are more computationally efficient?but the inevitable information loss degrades the finegrained localization accuracy, while the point-based methods have higher computation cost but could easily achieve larger receptive field by the point set abstraction [24].
==> this paper propose a method to combine these two ways
PV-RCNN Scheme

==> PointNet used MLP and maxpooling for feature extraction and abstraction.
The principle of PV-RCNN lies in the fact that the voxel-based operation efficiently encodes multi-scale feature representations and can generate high-quality 3D proposals, while the PointNet-based set abstraction operation preserves accurate location information with flexible receptive fields.
Furthest Point?Sampling, FPS
Farthest Point Sampling (FPS)算法核心思想解析 - 知乎
假设有 n?个点,要从里面按照FPS算法,采样出 k?个点(k < n)。逻辑上,可以将所有点归类到两个集合A, B里面。 A?表示选中的点形成的集合,B?表示未选中的点构成的集合。顾名思义,FPS做的事情是:每次从集合 B?里面选一个到集合 A?里面的点距离最大的点。
(for choosing when A has more than 1 point)


Speed-up by DP:
original approach above is ~O(k*n^2) or O(n^3) in time complexity with no spatial?requirement;?possible to use DP optimization by caching recursion states' info:

==> we compute and select the maximum B->A distance with O(n) time each time adding points to A, hence:


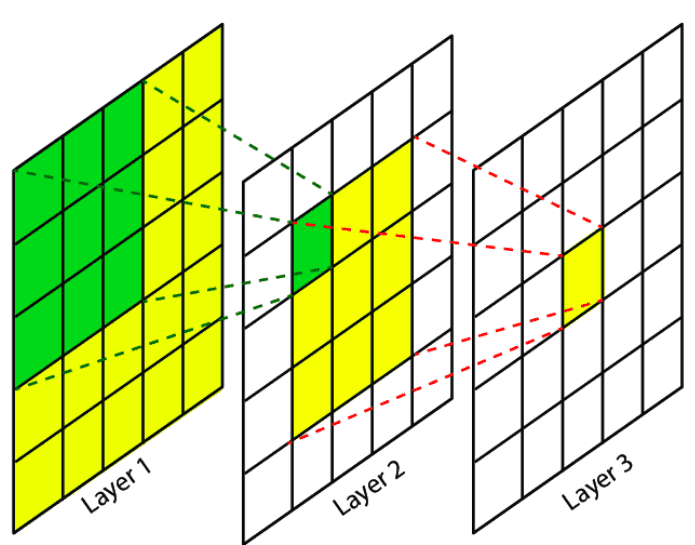
What is the receptive field in deep learning?
Similarly, in a deep learning context, the Receptive Field (RF) is defined as?the size of the region in the input that produces the feature[3]. Basically, it is a measure of association of an output feature (of any layer) to the input?region?(patch). Before we move on, let’s clarify one important thing:
Insight: The idea of receptive fields applies to local operations (i.e. convolution, pooling).
Source:?Research Gate
A convolutional unit only depends on a local region (patch) of the input. That’s why we never refer to the RF on fully connected layers since each unit has access to all the input region. To this end, our aim is to provide you an insight into this concept, in order to understand and analyze how deep convolutional networks work with local operations work.
Ok, but why should anyone care about the RF?
Why do we care about the receptive field of a convolutional network?
There is no better way to clarify this than a couple of computer vision examples. In particular, let’s revisit a couple of dense prediction computer vision tasks. Specifically, in?image segmentation?and optical flow estimation, we produce a prediction for each pixel in the input image, which corresponds to a new image, the semantic label map. Ideally, we would like each output pixel of the label map to have a big receptive field, so as to ensure that no crucial information was?not?taken into account. For instance, if we want to predict the boundaries of an object (i.e. a car, an organ like the heart, a tumor) it is important that we provide the model access to all the relevant parts of the input object that we want to segment. In the image below, you can see two receptive fields: the green and the orange one. Which one would you like to have in your architecture?
The green and orange rectangles are two different receptive fields. Which one would you prefer? Source:?Nvidia's blog
Similarly, in?object detection, a small receptive field may not be able to recognize large objects. That’s why you usually see multi-scale approaches in object detection. Furthermore, in motion-based tasks, like video prediction and optical flow estimation, we want to?capture large motions?(displacements?of pixels in a 2D grid), so we want to have an adequate receptive field. Specifically,?the receptive field should be sufficient if it is larger than the largest flow magnitude of the dataset.
Therefore, our goal is to design a convolutional model so that we ensure that?its RF covers the entire relevant input image region.
==> or in this paper, find a complementary network to handle the RFs.