语言识别的概念
机器翻译用印刷文本作为输入,能清楚地区分单个单词和单词串 。
语音识别用语音作为输入,口语对话与语音信号中语言提取的不同:
(1)上下文猜测
(2)肢体语言传达信息
fare | fair
male | mail
语音识别的主要过程
语音识别流程
分帧:把一段语音分成若干小段
状态:把每一帧识别作为一个状态
音素:把状态组合成音素,即声母亲和韵母。
声学模型(acoustic model):把一系列语音帧转换为若干音素的过程利用了语言的声学特性。
语言模型(language model) :从音素到文字的过程要利用语言表达的特点,从同音字中挑选正确的文字,组成意义明确的语言。
1.语音信号采集
基于单片机,DSP芯片
基于PC机
2.语音信号预处理
滤波
(1)抑制输入信号各频域分量中频率超出采样频率的一半的所有分量,以防止混叠干扰。
(2)抑制50Hz的电源工频干扰。
采样:对信号进行量化,量化不可避免地会产生误差。量化后的信号值与原信号值之间的差值为量化误差,又称为量化噪声。
预加重:提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱,便于频谱分析或声道参数分析。
端点检测:包含语音的一段信号中确定出语音的起点以及终点。
过零率:信号中波形穿越零电平的次数来描述幅度变化的剧烈程度。

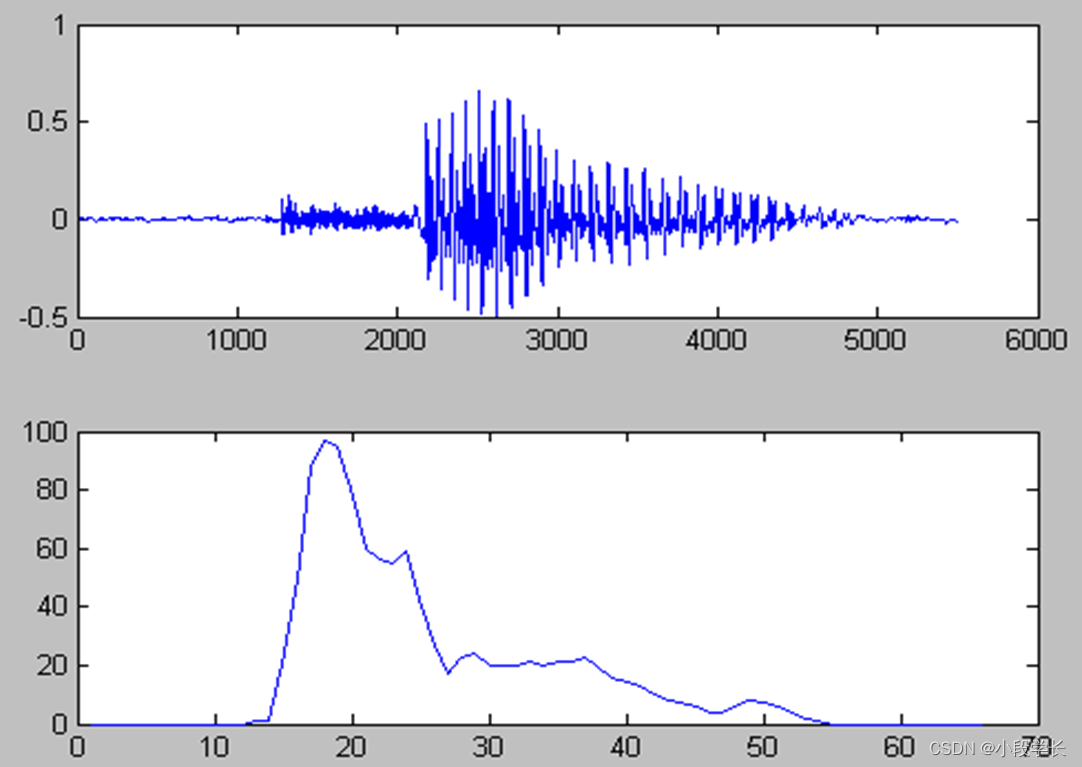
3.语音信号的特征参数提取
声波有两个主要特征:振幅和频率。
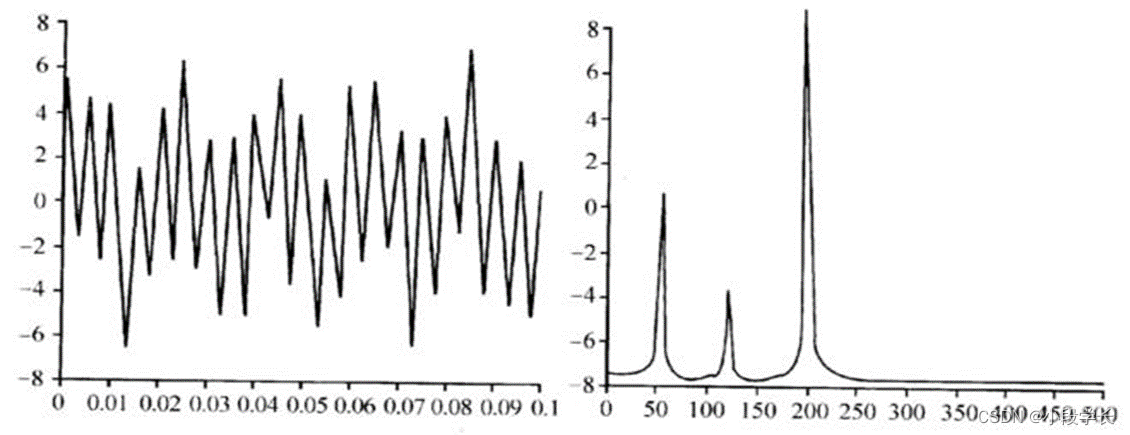
线性预测编码(LPC):
基本思想:由于语音样点之间存在相关性,所以可以用过去p个样点值来预测现在或未来的样点值。
4.向量量化
矢量量化(vector quantization,VQ)技术是七十年代后期发展起来的一种数据压缩和编码技术。
在标量量化中整个动态范围被分成若干个小区间,每个小区间有一个代表值,对于一个输入的标题信号,量化时落入小区间的值就用这个代表值代替
矢量量化的基本原理:将若干个标量数据组成一个矢量在多维空间给予整体量化,从而可以在信息量损失较小的情况下压缩数据量。
5.识别
识别系统的输入是从语音信号中提出的特征参数。
(1)语音识别模板匹配法
在训练阶段,用户将词汇表中的每一个词依次说一遍,将其特征矢量作为模板存入模板库。在识别阶段,将输入语音的特征矢量序列依次与模板库中的每个模板进行相似度比较,将相似度最高者作为识别结果输出。
(2)语音识别随机模型法
如隐马尔可夫模型(HMM)。用HMM的概率参数对似然函数进行估计与判决,从而得到识别结果。
(3)语音识别概率语法分析法
不同的人说同一些语音时,相应的语谱总有一些共同的特点以区分于其他语音。将区别性特征与来自构词、句法、语义等语用约束相互结合,构成由底向上或自顶向下的交互作用知识系统。
隐马尔可夫模型
隐马尔可夫模型: 表示序列可能出现的一种方法。
y跟在ph后面出现的概率>跟在t后面出现的概率
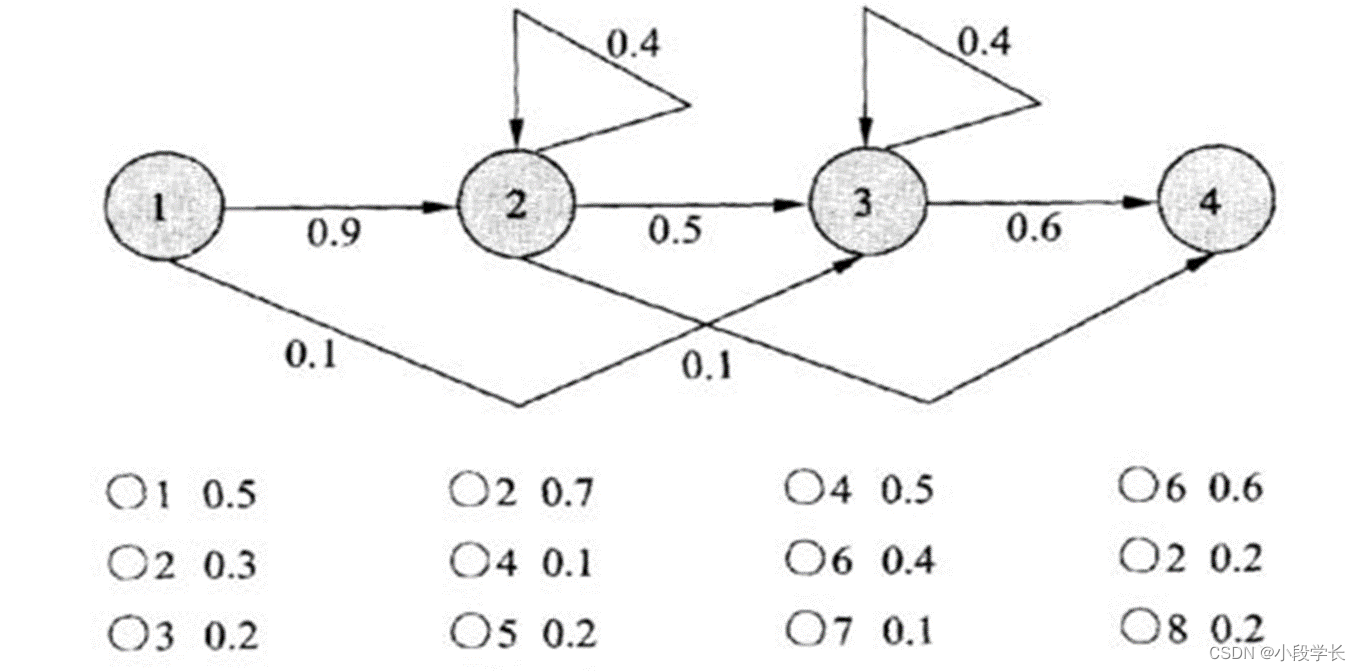
例 序列:1 2 3 3 4。则概率0.9×0.5×0.4×0.6=0.108
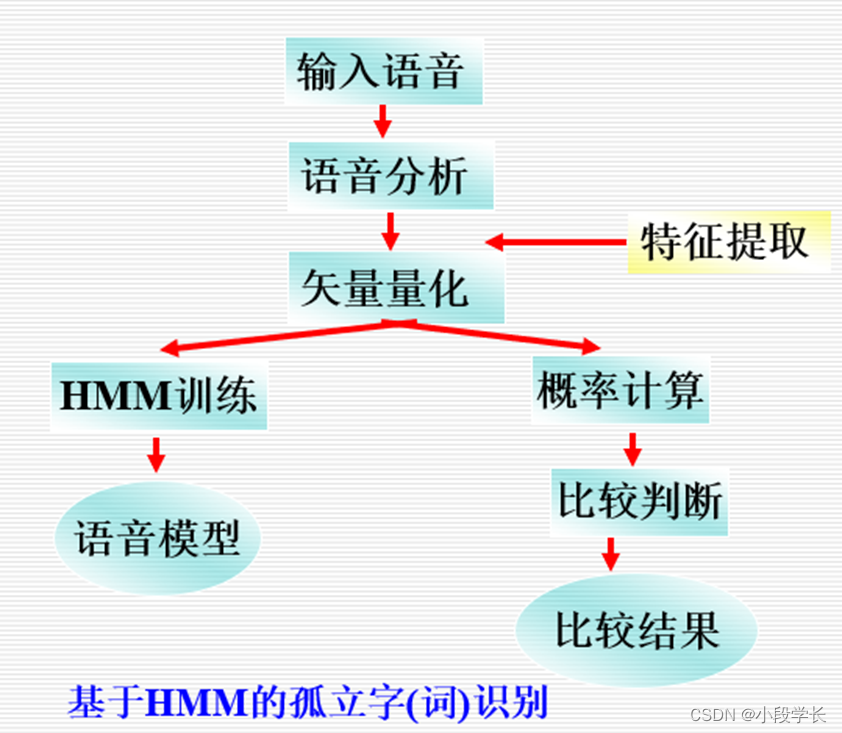
基于隐马尔可夫模型的语音识别方法
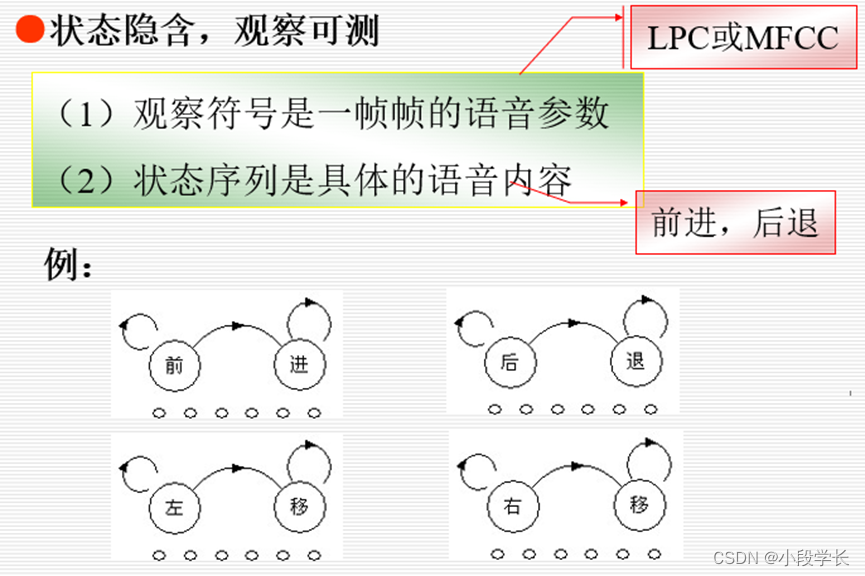
解决三个基本问题:

语音识别进展
深度学习使自然语言处理进入崭新的发展阶段:
现在神经机器翻译已经取代了统计机器翻译,成为机器翻译的主流技术。
目前统计数据表明:神经机器翻译的性能远远超过了统计机器翻译,而且跟人的标准答案非常接近,甚至说是相仿的水平。
不需要人工进行特征抽取,只要准备好足够的标注数据,比如机器翻译的双语对照语料。
可以在大规模语料上进行训练得到一个在多维语义空间上的表达,因此词汇之间、短语之间、句子之间乃至篇章之间的语义距离可以计算。
基于神经网络训练的语言模型,可以更加精准地预测下一个词的出现概率,以及一个句子的概率。
循环神经网络(RNN、LSTM、 GRU)可以对一个不定长的句子进行编码,描述句子的信息。
编码-解码(encoder-decoder)技术可以实现一个句子到另外一个句子的变换。这个技术是神经机器翻译、对话生成、问答、转述的核心技术。
强化学习使自然语言系统可以通过用户或者环境的反馈,调整神经网络参数,改进系统性能。
2012年11月,微软在天津演示自动同声传译系统。
2015年深度学习在计算机视觉、语音识别、自然语言理解上取得突破。
谷歌2016年推出商业级神经系统机器翻译,准确率达86%。
Facebook使用卷积神经网络CNN翻译速度比谷歌快9倍。
欢迎大家加我微信交流讨论(请备注csdn上添加)


