Pytorch ���Ǩ��
0. ��������
����ʹ�� Kaggle ����ѽ����� Notebook
�̳�ʹ��������ʦ�� ����ѧ���ѧϰ ��վ�� ��Ƶ����
С����:������������������ʱ����� Shift+Tab �鿴������⡣
1. ���Ǩ��
1.1 ����
ʹ�þ���������,�Զ���һ��ͼ���еķ��Ӧ������һͼ��֮��,�����Ǩ��(style transfer)������������Ҫ��������ͼ��:һ��������ͼ��,��һ���Ƿ��ͼ�� ���ǽ�ʹ��������������ͼ��,ʹ���ڷ���Ͻӽ����ͼ��

1.2 ���� CNN ����ʽǨ��
���ȳ�ʼ���ϳ�ͼ��,�������ʹ������ͼ���ʼ����
�ϳ�ͼ����ѵ��������Ψһ��Ҫ���µı���(���� CNN ѵ�����Ǿ������Ȩ��)��
Ȼ��ѡ��һ��Ԥѵ���� CNN ����ȡͼ������(�� VGG��),����ģ�Ͳ�����ѵ���в���Ҫ���¡�
���ѡ��� CNN ƾ��������ȡͼ�������,���ǿ���ѡ������ijЩ��������Ϊ������������������
����ѡȡ��Ԥѵ���������纬��
3
3
3 ��������,���еڶ��������������,��һ��͵�����������������
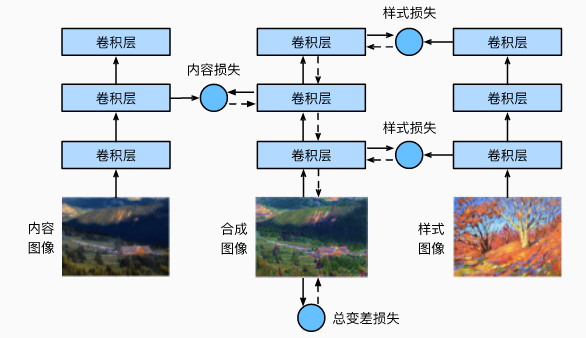
������,����ͨ��ǰ��(ʵ��ͷ����)������Ǩ�Ƶ���ʧ����,��ͨ������(����ͷ����)����ģ�Ͳ���,�����ϸ��ºϳ�ͼ��
���Ǩ�Ƴ��õ���ʧ������3�������:
(i)������ʧʹ�ϳ�ͼ��������ͼ�������������Ͻӽ�;
(ii)�����ʧʹ�ϳ�ͼ������ͼ���ڷ�������Ͻӽ�;
(iii)ȫ�����ʧ(total variation denoising)�������ڼ��ٺϳ�ͼ���е���㡣
���,��ģ��ѵ������ʱ,����������Ǩ�Ƶ�ģ�Ͳ���,���õ����յĺϳ�ͼ��
2. ����
2.1 ����ͼƬ
�� github ����ͼƬ������:
!pip install -U d2l
%matplotlib inline
import torch
import os
import requests
import torchvision
from torch import nn
from d2l import torch as d2l
if not os.path.exists('../data'):
os.mkdir('../data')
for name in ['rainier', 'autumn-oak']:
r = requests.get('https://raw.githubusercontent.com/d2l-ai/d2l-zh/master/img/%s.jpg' % name)
with open('../data/%s.jpg' % name, 'wb') as f:
f.write(r.content)
��ȡ����ͼ��:
d2l.set_figsize()
content_img = d2l.Image.open('../data/rainier.jpg')
d2l.plt.imshow(content_img)
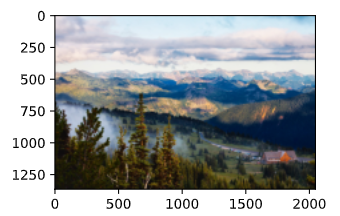
��ȡ���ͼ��:
style_img = d2l.Image.open('../data/autumn-oak.jpg')
d2l.plt.imshow(style_img)
2.2 Ԥ�����ͺ���
Ԥ�������� preprocess ������ͼ���� RGB ����ͨ���ֱ�������,��������任�ɾ�����������ܵ������ʽ(ͼƬ==>Tensor)��
�������� postprocess �����ͼ���е�����ֵ��ԭ�ر���֮ǰ��ֵ�� ����ͼ���ӡ����Ҫ��ÿ�����صĸ�����ֵ��
0
0
0 ��
1
1
1 ֮��,���Ƕ�С��
0
0
0 �ʹ���
1
1
1 ��ֵ�ֱ�ȡ
0
0
0 ��
1
1
1(Tensor==>ͼƬ)��
# imagenet ����Ҫ��
rgb_mean = torch.tensor([0.485, 0.456, 0.406])
rgb_std = torch.tensor([0.229, 0.224, 0.225])
def preprocess(img, image_shape):
transforms = torchvision.transforms.Compose([
torchvision.transforms.Resize(image_shape),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=rgb_mean, std=rgb_std)])
return transforms(img).unsqueeze(0)
def postprocess(img):
img = img[0].to(rgb_std.device)
img = torch.clamp(img.permute(1, 2, 0) * rgb_std + rgb_mean, 0, 1)
return torchvision.transforms.ToPILImage()(img.permute(2, 0, 1))
2.3 ��ȡͼ������
ʹ�û���ImageNet ���ݼ�Ԥѵ���� VGG-19 ģ������ȡͼ������:
pretrained_net = torchvision.models.vgg19(pretrained=True)

ʹ�ò�ͬ�IJ��ȡ��������,����ԽСԽ��������(ƥ��ֲ���Ϣ),Խ��Խ�������(ƥ��ȫ����Ϣ)���������ѡȡ(��Ҫ�ֲ�,ҲҪȫ��),���ݲ�ȡ�����(ֻ����ȫ��):
style_layers, content_layers = [0, 5, 10, 19, 28], [25]
�ó�����,ȡ�� 28 28 28 ��,����ľͲ�Ҫ��:
net = nn.Sequential(*[pretrained_net.features[i] for i in
range(max(content_layers + style_layers) + 1)])
��ȡ����:
def extract_features(X, content_layers, style_layers):
contents = []
styles = []
for i in range(len(net)):
X = net[i](X)
if i in style_layers:
styles.append(X)
if i in content_layers:
contents.append(X)
return contents, styles
�������� Tensor,������� Tensor �������� extract_features:
def get_contents(image_shape, device):
content_X = preprocess(content_img, image_shape).to(device)
contents_Y, _ = extract_features(content_X, content_layers, style_layers)
return content_X, contents_Y
def get_styles(image_shape, device):
style_X = preprocess(style_img, image_shape).to(device)
_, styles_Y = extract_features(style_X, content_layers, style_layers)
return style_X, styles_Y
2.4 ������ʧ����
2.4.1 ������ʧ
�����Իع��е���ʧ��������,������ʧͨ��ƽ�����������ϳ�ͼ��������ͼ�������������ϵIJ��졣 ƽ�����������������Ϊ extract_features �����������õ������ݲ�����:
def content_loss(Y_hat, Y):
# ���ǴӶ�̬�����ݶȵ����з���Ŀ��:
# ����һ���涨��ֵ,������һ��������
return torch.square(Y_hat - Y.detach()).mean()
2.4.2 �����ʧ
���Ƚϲ��ü�����ʧ,�����ô�����Ƿ�һ��?����ͼ����һ�²���Ҫ������ֵһ��,ֻ��Ҫͼ���ͳ�Ʒֲ����Ƽ��ɡ�
def gram(X):
# n ��ÿ��ͨ���������� = h * w
num_channels, n = X.shape[1], X.numel() // X.shape[1]
X = X.reshape((num_channels, n))
X * X.T (3*hw �� hw*3 = 3*3)
return torch.matmul(X, X.T) / (num_channels * n)
def style_loss(Y_hat, gram_Y):
return torch.square(gram(Y_hat) - gram_Y.detach()).mean()
2.4.3 ȫ�����ʧ
����ѧ���ĺϳ�ͼ�������д�����Ƶ���,�����ر��������ر𰵵Ŀ������ء� һ�ֳ�����ȥ�뷽����ȫ���ȥ��(total variation denoising): ����
x
i
,
j
x_{i, j}
xi,j? ��ʾ����
(
i
,
j
)
(i, j)
(i,j)��������ֵ,����ȫ�����ʧ
��
i
,
j
�O
x
i
,
j
?
x
i
+
1
,
j
�O
+
�O
x
i
,
j
?
x
i
,
j
+
1
�O
\sum_{i, j} \left|x_{i, j} - x_{i+1, j}\right| + \left|x_{i, j} - x_{i, j+1}\right|
i,j��?�Oxi,j??xi+1,j?�O+�Oxi,j??xi,j+1?�O
�ܹ�������ʹ�ڽ�������ֵ����:
def tv_loss(Y_hat):
return 0.5 * (torch.abs(Y_hat[:, :, 1:, :] - Y_hat[:, :, :-1, :]).mean() +
torch.abs(Y_hat[:, :, :, 1:] - Y_hat[:, :, :, :-1]).mean())
2.4.4 ������ʧ����
���ת�Ƶ���ʧ������������ʧ�������ʧ���ܱ仯��ʧ�ļ�Ȩ�͡�
ͨ��������ЩȨ�س�����,���ǿ���Ȩ��ϳ�ͼ���ڱ������ݡ�Ǩ�Ʒ���Լ�ȥ��������������Ҫ��:
content_weight, style_weight, tv_weight = 1, 1e3, 10
def compute_loss(X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram):
# �ֱ����������ʧ�������ʧ��ȫ�����ʧ
contents_l = [content_loss(Y_hat, Y) * content_weight for Y_hat, Y in zip(
contents_Y_hat, contents_Y)]
styles_l = [style_loss(Y_hat, Y) * style_weight for Y_hat, Y in zip(
styles_Y_hat, styles_Y_gram)]
tv_l = tv_loss(X) * tv_weight
# ��������ʧ���
l = sum(10 * styles_l + contents_l + [tv_l])
return contents_l, styles_l, tv_l, l
2.5 ��ʼ���ϳ�ͼ��
�ڷ��Ǩ����,�ϳɵ�ͼ����ѵ���ڼ�Ψһ��Ҫ���µı���,���ϳɵ�ͼ����Ϊģ�Ͳ���,ģ�͵�ǰ��ֻ�践��ģ�Ͳ�������(����ֱ��ʹ������ͼ����Ϊ�ϳ�ͼ��ij�ʼ��):
class SynthesizedImage(nn.Module):
def __init__(self, img_shape, **kwargs):
super(SynthesizedImage, self).__init__(**kwargs)
self.weight = nn.Parameter(torch.rand(*img_shape))
def forward(self):
return self.weight
def get_inits(X, device, lr, styles_Y):
gen_img = SynthesizedImage(X.shape).to(device)
gen_img.weight.data.copy_(X.data)
trainer = torch.optim.Adam(gen_img.parameters(), lr=lr)
styles_Y_gram = [gram(Y) for Y in styles_Y]
return gen_img(), styles_Y_gram, trainer
2.6 ѵ��
ѵ��ģ�ͽ��з��Ǩ��ʱ,���Dz��ϳ�ȡ�ϳ�ͼ������������ͷ������,Ȼ�������ʧ����:
def train(X, contents_Y, styles_Y, device, lr, num_epochs, lr_decay_epoch):
X, styles_Y_gram, trainer = get_inits(X, device, lr, styles_Y)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_decay_epoch, 0.8)
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs],
legend=['content', 'style', 'TV'],
ncols=2, figsize=(7, 2.5))
for epoch in range(num_epochs):
trainer.zero_grad()
contents_Y_hat, styles_Y_hat = extract_features(
X, content_layers, style_layers)
contents_l, styles_l, tv_l, l = compute_loss(
X, contents_Y_hat, styles_Y_hat, contents_Y, styles_Y_gram)
l.backward()
trainer.step()
scheduler.step()
if (epoch + 1) % 10 == 0:
animator.axes[1].imshow(postprocess(X))
animator.add(epoch + 1, [float(sum(contents_l)),
float(sum(styles_l)), float(tv_l)])
return X
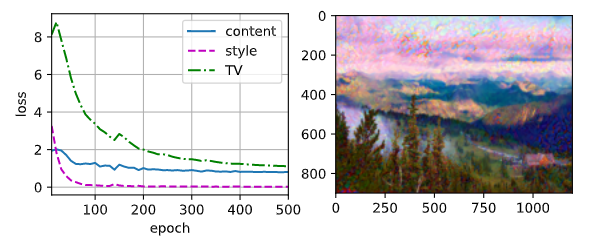
���Ƚ�����ͼ��ͷ��ͼ��ĸߺͿ��ֱ����Ϊ 300 300 300 �� 450 450 450 ����,������ͼ������ʼ���ϳ�ͼ��:
device, image_shape = d2l.try_gpu(), (300, 450)
net = net.to(device)
content_X, contents_Y = get_contents(image_shape, device)
_, styles_Y = get_styles(image_shape, device)
output = train(content_X, contents_Y, styles_Y, device, 0.3, 500, 50)
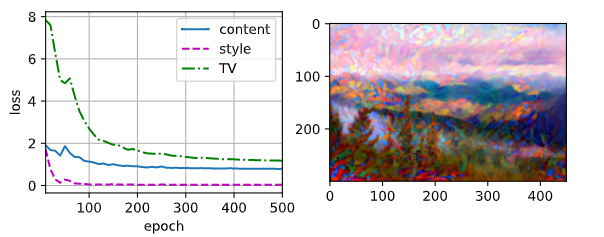
�����Դ�һ������ؿ���Ч��:
device, image_shape = d2l.try_gpu(), (900, 1200)
net = net.to(device)
content_X, contents_Y = get_contents(image_shape, device)
_, styles_Y = get_styles(image_shape, device)
output = train(content_X, contents_Y, styles_Y, device, 0.3, 500, 50)