��������Ӧ��������ʱ�ղ�̬����
paper��Ŀ:Spatio-temporal Gait Feature with Adaptive Distance Alignment
paper��IEEE Fellow Xuelong Li������arxiv 2022����
paper��ַ:����
Abstract
��̬ʶ����һ����Ҫ��ʶ����,��Ϊ������αװ,ʶ��Ŀ�겻��Ҫ������Ȼ��,��̬ʶ����Ȼ����������ս,�������������Ƶ��˾���������ʶ�𡣱��ij��Դ�����ṹ���Ż�����ȡ�IJ�̬������ϸ���������������Ӳ�ͬĿ��IJ�̬��������,�Ӷ���߶Ծ������Ʋ������Ƶ�Ŀ���ʶ��Ч�ʡ�����ҳ��˱��ĵķ���,����ʱ��������ȡ (SFE) ������Ӧ������� (ADA) ���,���� SFE ʹ��ʱ�������ں� (TFF) ��ϸ����������ȡ (FFE) ��ԭʼ��������Ч����ȡʱ������, ADA ����ʵ�����д���δ��ǵIJ�̬����Ϊ��,����ȡ��ʱ����������ϸ��,ʹ��������ƶȵ�,�������ƶȸߡ��� mini-OUMVLP �� CASIA-B �ϵĴ���ʵ��֤��,���ĵĽ����һЩ���Ƚ��ķ���Ҫ�á�
�ؼ��ʡ�����̬ʶ��ʱ��������ȡ������������
I. INTRODUCTION
���Ĥ��ָ�ơ�����������������ͬ,��̬��ʶ������в���ҪĿ������,�ڲ��ܿ��Ƶij����¿���Զ����ʶ��Ŀ�ꡣ���,��̬�ڷ�ҽ��������Ƶ��ء��������ȷ������Ź㷺��Ӧ�á���Ϊһ���Ӿ�ʶ������,��Ŀ����ѧϰ��ͬĿ����б�������Ȼ��,��ԭʼ��̬������ѧϰʱ������ʱ,�������ܵ������ⲿ���صĸ���,�����������Ƕȡ���ͬ���·�/Я��������
�Ѿ����������������ѧϰ�ķ������˷���Щ���⡣ DVGan ʹ�� GAN ��������ʱ�ǿռ�,���ӽǴ� 0�� �� 180��,���Ϊ 1��,����Ӧ����������Ƕȡ� GaitNet ʹ���Ա�������Ϊ���ǵĿ������ԭʼ RGB ͼ����ѧϰ�벽̬��ص���Ϣ������ʹ�� LSTM ��ѧϰʱ����Ϣ�ı仯,�Կ˷���ͬ���·�/Я�������� GaitSet���ɶ���֡��ɵļ�����ѧϰ������Ϣ,����Ӧ�����ӽǺͲ�ͬ���·�/Я�������� Gaitpart���ò�������������������,����ǿϸ����ѧϰ��
�����ķ���Ҫôֻ��עʱ�������Ĵ���,Ҫôֻ��עϸ������������ȡ,���ܱ�֤ͬʱ�����ȡʱ����Ϣ��Ϊ�˽���������,����ʹ��ʱ�������ں�(TFF)�ں���ߴ����Ե�ʱ������,Ȼ��ʹ��ϸ����������ȡ(FFE)����ߴ����Ե�ʱ����������ȡϸ��������,������Щ����,������ȫ��ȡԭʼ��̬������ʱ��������Ȼ��,���������������������Ƶ�Ŀ��ʱ,����������ṹֻ�ܱ�֤�����ȡ���ǵIJ�̬����,�����ܱ�֤���ǵ��б�����Ϊ�˽���������,���߳���ʹ������Ӧ������뼼����δ��ǵ�����������Ӧ��ѡ����ʵĻ���ϸ����ȡ��ʱ������,�ò���������Ч�����Ӿ������Ʋ��е������ߵIJ�̬�������졣���,����˷���:��������Ӧ��������ʱ�ղ�̬����,����ʱ��������ȡ(SFE)������Ӧ�������(ADA)��ɡ� SFE ���� FFE �� TFF��
������˵,ÿ����ʼ֡�������뵽 TFF ��,��ͨ�����ػ�ѡ����ߴ����Ե�ʱ���������ڴ�֮��,���߽��ںϵ���ߴ����Ե�ʱ�������ֳ� 4 ����,��ʹ�õ�������������ȡϸ�������������,ʹ�� ADA ����ȡ��ʱ����������ϸ��,ʹ����е�������ƶȺ��������ƶȡ�
��������������������������������ŵ�:
-
�� TFF ʹ�����ػ����ں���ߴ����Ե�ʱ������,Ȼ����ߴ����Ե�ʱ�������ֳ� 4 ��������ȡϸ���ȵĿռ��������ⲿ��ʹ����һ����ʱ��������ȡģ��,������Ч��ѧϰԭʼ��̬���е�ʱ��������
-
�Ľ��˾�����뼼��������Ӧ���ڲ�̬ʶ�����Ľ��ľ�����뼼����������Ӧ�ķ�������ʵ������δ��ǵ����ݼ���ѡ����ʵĻ�,Ȼ�����øû�����ȡ��ʱ����������ϸ��,������Ч���Ӿ������Ʋ������Ƶ������ߵIJ�̬�������졣
-
�����һ�ֳ�Ϊ��������Ӧ��������ʱ�ղ�̬�����ķ�������������Ч�ش�ԭʼ��̬��������ȡʱ������,���Ӳ�ͬĿ��֮��IJ��졣�� CASIA-B �� mini-OUMVLP �Ĵ���ʵ��֤��,���ĵķ������������Ƚ��ķ������и��õĽ����ֵ��ע�����,���ĵķ������������������µ� CASIA-B ��̬���ݼ���ʵ���� 97.0% ��ƽ�� rank-1 ȷ�ȡ�
II. RELATED WORK
�ⲿ����Ҫ���ܲ�̬ʶ�����ع���,�������¼�����������:��̬ʶ�����Ҫ��������ԭʼ��̬������ѧϰʱ����Ϣ�ķ������ݱ��Լ���������������
��̬ʶ��Ŀǰ�IJ�̬ʶ�����Է�Ϊ����ģ�͵ķ����ͻ�����۵ķ�����������۵ķ���ͨ������������(CNN)ֱ�ӴӲ�̬�����е�ԭʼ������ѧϰʱ������,Ȼ��ͨ������ƥ�����жϲ�̬���е�Ŀ�����ݡ�����ģ�͵ķ������ȶԲ�̬�����е�ԭʼ�������н�ģ,Ȼ��ʹ��һ���µķ�ʽ������ԭʼ����,��ѧϰ���ǵ�ʱ��������һ�����д����ԵĻ���ģ�͵ķ�����JointsGait,��ʹ��ԭʼ��̬����������ؽ���������̬ͼ�ṹ,Ȼ��ͨ��ͼ�������� (GCN) �Ӳ�̬ͼ�ṹ����ȡʱ��������Ȼ��,�������ַ��������ﲽ̬�����е�����ʱ,�����ᶪʧ�ܶ���Ҫ��ϸ����Ϣ,����ʶ���Ѷȡ�����������ģ�͵ķ���Ҳ�������������,���Ի�����۵ķ����Ѿ���ΪĿǰ�������IJ�̬ʶ�������ĺ����ᵽ�ķ��������ڻ�����۵ķ�����
ʱ��������ȡģ�顣ʱ��������ȡ��Ч���Ǻ���������۵ķ�����������Ҫ����,����Ӱ��ʶ���ȷ�ԡ�ʱ��������ȡģ����Է�Ϊ������:�ռ�������ȡģ���ʱ��������ȡģ�顣
����ʱ��������ȡģ��,�л������ѧϰ�ķ����ʹ�ͳ��������ͳ��������ͨ��һЩ������ԭʼ��̬����ѹ����һ��ͼ��,���� GEI��PEI �� CGI��Ȼ��ʹ��������Ӹ�ͼ������ȡʱ����������Ȼ��Щ��ͳ�����ܼ������о���Ա�������Dz��ܺܺõر���ʱ����Ϣ,������ʹ�û������ѧϰ�ķ�������ȡʱ�������� LSTMʹ���ظ���������ģ�����������ȡԭʼ��̬���е�ʱ����Ϣ�� GaitSet�۲쵽��ʹ��̬���б�����,�������������г���ȷ��˳������,Ȼ��ʹ�ô��ҵ�������ѧϰʱ����Ϣ,��ȷ�����ֲ�̬���е���Ӧ�ԡ����� LSTM �� GaitSet ����һЩȱ��:���ǵ�����ṹ�ͼ�����̸��ӡ����ij���ʹ�ö�����о������ԭʼ��̬��������ȡȫ������,��ʹ�ü����ػ��������ں���ߴ����Ե�ʱ���������������Լ�����ṹ,���ټ�����,��Ч��ȡʱ��������ֵ��ע�����,���ĵķ����ܹ�ֻʹ���� 4 ��������� 2 ���ػ��㡣
���ڿռ�������ȡģ��,��[43]��,�ڲ�̬ʶ����������partial��˼��,��Ϊ��ͬ�����岿λ��������Ϣ��ʶ���л���ͬ�����á����,�������Ϊ�߸���ͬ�IJ���,ͨ��ȥ��ƽ����̬ͼ���е��߸���λ���۲�ʶ���ʵı仯��̽����ͬ��λ�Բ�̬ʶ���Ӱ�졣ΪĿǰ�ֲ�˼���ʹ�õ춨�˻����� GaitPart�����ѧϰ������������˼��������������,�����ȡϸ������Ϣ,����������ֿ���ȡϸ��������,ȡ���˺ܺõ�Ч��������,GaitPart ������partial in shallow features ��˼��,�������������Ϊblock,����������ĸ��Ӷȡ�����ֻ�Ը߲���������һ�λ�������ȡϸ��������,���ҽ�ʹ�õ�����������Ի�����õ����ܡ���������������ṹ��
����Ӧ������롣������뼼����������ϸ����������,�������õ����ܡ���ʹ�ô���δ��ע�������ж���ʵ�����������ֲ��������ܶ�,���Դ��ܶ�Ϊ������ȡ��ʱ����������ϸ��,�������Բ������������һ��,��������ɢ������̫��������ʶ������Ͳ�̬ʶ������ı���Ŀ�Ķ���ͨ������ƥ����ʶ��Ŀ������ݡ����������������������,���߳��ԸĽ�������뼼�����������벽̬ʶ������ǰ��ľ���������ȼ���δ������ݼ��е�������ͼ�⼯��̽�뼯����ȡ��ʱ������֮��ľ���,Ȼ��ͨ����������δ���������ѡ��һЩ����ȡ��ʱ���������Ƶ�����,������Щ����������ѡ�����ֵ��Ϊ����ϸ����ȡ��ʱ�����������ֲ������Դﵽ�ܺõ�Ч��,������ֻʹ������Щ������δ�����������ȡ��ʱ���������Ƶ����ֵ,�����Щ��������û�б�������á����ľ������������Щ���Ƶ�����,��Ӧ�Դ�����(mean)�����(maximum)��������(median)��������ѡ������ʵ�benchmark,�ﵽ��õ�ϸ��Ч�������Ľ��ľ�������Ϊ����Ӧ������뼼����
���ʱ��������ȡģ��ķ�չ�;�����������,�����һ�ַ���:ʱ�ղ�̬����������Ӧ������롣��ʹ�����ػ����ں���ߴ����Ե�ʱ������,�ڸ����������벿��˼��,�Ľ��������,���������벽̬ʶ��������ͨ��ʱ��������ȡģ����Ч�ش�ԭʼ��̬��������ȡʱ������,����ʹ������Ӧ������뼼������ȡ��ʱ����������ϸ��,�����Ӳ�ͬĿ��֮�䲽̬���������ֶȡ�
III. OUR METHOD
��һ���ֽ�������������ܱ��ĵķ���:����������ˮ�ߡ�ʱ��������ȡ(SFE)ģ�������Ӧ�������(ADA),����ʱ��������ȡ��Ҫ����������:����������ȡ(FFE)��ʱ�������ں�(TFF)������������Ŀ����ͼ1��ʾ��
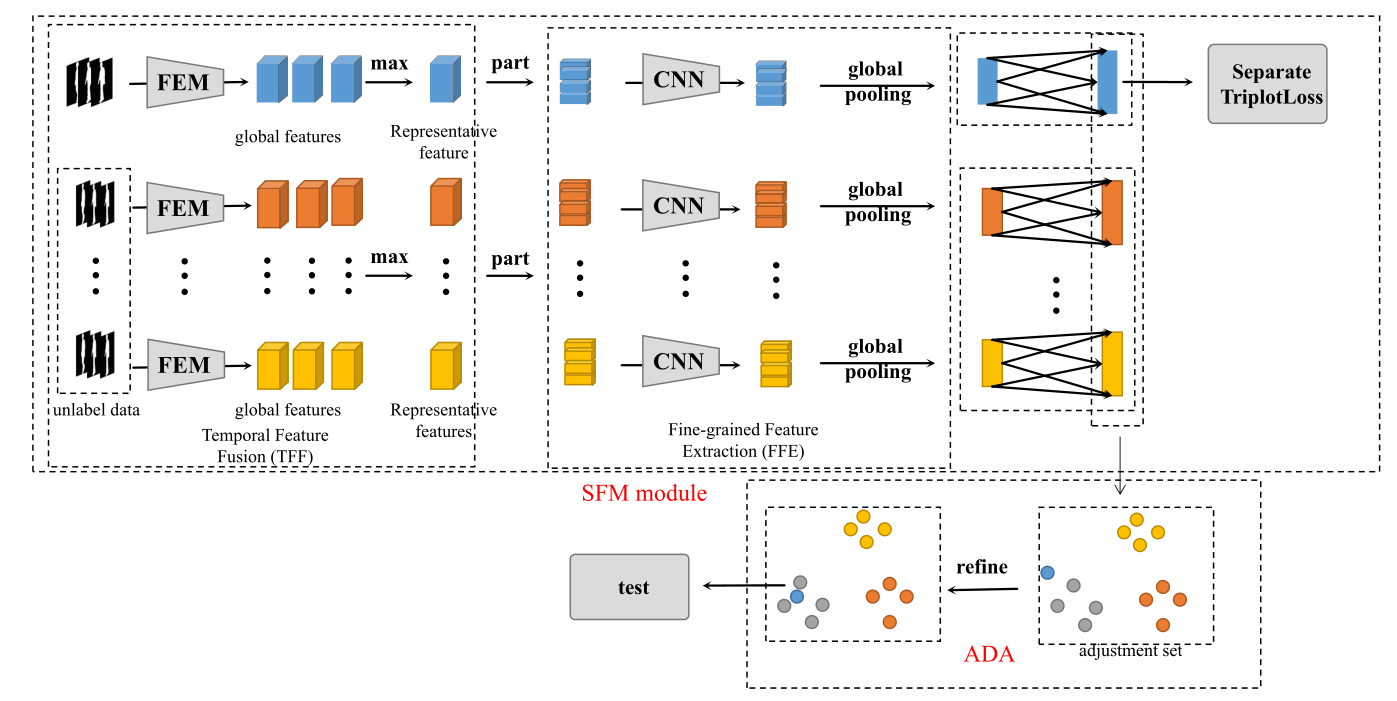
ͼ 1. ���ķ����Ŀ�ܡ���������ع۲쵽,���ĵĿ�������������:ʱ��������ȡ(SFE)ģ�������Ӧ�������(ADA)�� SFEģ����Ҫ��������ṹ���Ż��� ADA�Ƕ�ͼ�⼯��̽�뼯����ȡ��ʱ��������ϸ������ͼ�ĵײ�,Ϊ�˷���鿴�����ķֲ�,��ԲȦ����ʾ������
A. Pipeline
��ͼ 1 ��ʾ,���ĵ�������Ҫ�����������:SFE ģ��� ADA�� SFEģ����Ҫ��������ṹ���Ż�,������ͨ��������ṹ��Ч����ȡԭʼ��̬���е�ʱ�������� ADA��һ�ֺ�������,��Ҫ����ʵ�����д���δ��ǵIJ�̬����Ϊ��,����ȡ��ʱ����������ϸ��,�������Ӳ�ͬĿ��䲽̬�����IJ��졣
������˵,�� SFE ����,���Ƚ�һЩԭʼ��̬������֡���뵽 TFF�� TFF ʹ�� Feature Extraction Module (FEM) ��ѧϰÿһ֡��ȫ����Ϣ,FEM ֻ���� 4 ��������� 2 �� Max pooling ��,�����Ա�֤ÿһ֡����ϸ��Ϣ���ܱ����ѧϰ,Ȼ��ʹ�üIJ���max����ȡ��ȫ���������ں���ߴ����Ե�ʱ���������������ڱ�֤ʱ����Ϣ�������ȡ��ͬʱ������ṹ,���ټ��������� TFF ֮��,����ߴ����Ե�ʱ���������뵽 FFE ��ѧϰϸ��������������֡���ȱ���Ϊ 4 ������,Ȼ���ʹ��һ����������ѧϰ��ϸ������Ϣ�� TFF �� FFE ��ʹ�ü�����ṹ��Ȼ����ȡ��ʱ���������뵽��һ���֡��ⲿ��ʹ����max pooling��mean pooling��ɵ�Global Pooling��ѡ���ÿ��������ȡ�ĺ��ʵ�ϸ����������ȫ���Ӳ���ȫ�ֳػ�֮��,����������֮ǰ��ȡ�����������,ʹ��hard��Ԫ����ʧ��Ϊ��������������ơ�
�� ADA ����,���ȴ���ʵ�������ҵ�����δ��ǵIJ�̬����,Ȼ��ʹ�þ���ѵ���� SFE ģ���δ��ǵIJ�̬���ݼ�����ȡʱ������,������Щ��ȡ��ʱ��������Ϊ��������Ȼ��������������Щ�������ԭʼ��̬��������ȡ��ʱ������֮��ľ���,��ͨ������ľ���ӵ�������ѡ��4������ȡ��ʱ���������Ƶ����������,��Ӧ�ԵĴ���Щѡ��������д�����(mean)�����(maximum)��������(median)��������ѡ������ʵĻ�,��ʹ�û���ϸ����ȡ��ʱ��������
B. Spatio-temporal Feature Extraction module
�ⲿ�������ģ����Ҫ����ͼ��������Ľṹ,���ټ�����,ͬʱ��֤ԭʼ��̬���е�ʱ�������ܹ��������ȡ������ TFF �� FEE ������:���� FFE ��ʾ Fine-grained Feature Extraction,TFF ��ʾ Temporal Feature Fusion��
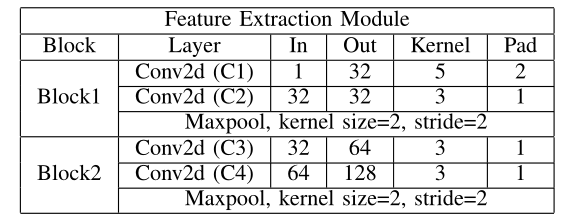
- ʱ�������ں�:TFF �ɶ������ FEM ��һ�����ػ������,���� FEM �IJ����ǹ����ġ� FEMs���ڴ�ÿһ֡����ȡȫ������,���ǿ��Գ����ȡÿһ֡����Ҫ��Ϣ�����ػ����ڴ�ÿ֡��ȡ��ȫ��������ѡ����ߴ����Ե�ʱ�������������������� FEM �Ľṹ�Լ�������Щʲô����Ч���ں���Щ���ӵ�ʱ����Ϣ�Ի����ߴ����Ե�ʱ��������
���1��ʾ,FEM ��ʹ�� 4 ������������ȡԭʼ������ȫ������,��ʹ�� 2 �� Max pooling ����ѡ����Щȫ����������Ҫ��Ϣ����Щ�������Գ����ȡÿһ֡��ȫ��������Ȼ����ʹ�ø��ֲ���:max��mean��medium ���ں���ȡ��ȫ�������еĴ���֡,Ȼ����ʹ�� max �������Ը��õر�������������Ϣ������������Ϊ
T
=
Maxpooling
?
(
T
i
)
,
i
��
1
,
2
,
��
,
N
.
T=\operatorname{Maxpooling}\left(T_{i}\right), i \in 1,2, \ldots, N .
T=Maxpooling(Ti?),i��1,2,��,N.
����
T
i
T_{i}
Ti?�� FEM ��ԭʼ��̬��������ȡ��ȫ������,
T
T
T��ͨ�� max ������
T
i
T_{i}
Ti?���ںϵ���ߴ����Ե�ʱ�������������˲���,��̬��������ߴ����Ե�ʱ���������Ժܺõ��ںϡ�
��1 ������ȡģ��Ľṹ�� IN��OUT��KERNEL��PAD�ֱ������CONV2D���������ͨ�����ں˴�С����䡣
2)ϸ����������ȡ:��������������,���о��߷����þֲ�����������������ͻ���ı��֡�Ȼ��,�������о����Ƿ���dz��ֲ���������������,������Ҫ�ڲ�ͬ�IJ������ж�λ�������ȡϸ��������,�⽫ʹ����ṹ���Ӹ��ӡ����,���ij��Դ������ȡϸ���ȵ�����,�Լ�����ṹ����ø��õĽ��������ȡ����ߴ����Ե�ʱ���������λ���Ϊ 1��2��4 �� 8 ������ѧϰϸ������Ϣ,������ߴ����Ե�ʱ�������Ǹ����������Թ۲쵽,��ʹ�� 4 ������ѧϰϸ��������ʱ,��������õ����ܡ��������,��ѧϰϸ������Ϣʱ,���ȵ�����������ʹϸ������Ϣѧϰ�ø����,�������ܻ�������ڲ���֮��Ĺ�ϵ��������ʹ�ø���ľ������ٴ�ѧϰϸ������Ϣ�����ڴ���������,�������ܲ��絥�������㡣���������֤��,�ڸ�������ʹ�þֲ�˼��ʱ,����Ҫ̫�������ṹ��ѧϰϸ���ȵ���Ϣ��
������˵,���Ƚ���ߴ����Ե�֡����Ϊ 4 ���顣Ȼ��ʹ�õ����������ÿ������ѧϰϸ������Ϣ���ڴ�֮��,ʹ��ȫ�ֳػ���ȫ���Ӳ�ֱ��һ������ϸ����������ʱ����Ϣ�� Global Pooling �Ĺ�ʽ������ʾ
P
=
Avgpooling
?
(
P
i
)
+
Maxpooling
?
(
P
i
)
,
i
��
1
,
2
,
��
,
N
P=\operatorname{Avgpooling}\left(P_{i}\right)+\operatorname{Maxpooling}\left(P_{i}\right), i \in 1,2, \ldots, N
P=Avgpooling(Pi?)+Maxpooling(Pi?),i��1,2,��,N
�������ػ������������� w ά�ȡ�ͨ���������,�����Ӱ��� c��h �� w ����ά���ݱ�Ϊ���� c �� h �Ķ�ά���ݡ�
��̬ʶ����Ҫʹ������ƥ����ʶ��Ŀ�ꡣ���,��ͬĿ��֮��ĵ����ƶȺ�ͬһĿ��֮��ĸ����ƶ��Ǿ���ʶ��ȷ�ʵ���Ҫ���ء� hardtriplet loss�ڽ���������ƶȺ������������ƶȷ����кܺõı��֡������������ʧ��ΪԼ�����������������Ӳ��Ԫ����ʧ��ʾΪ
L
trip?
=
max
?
(
max
?
max
?
(
d
i
+
)
?
min
?
(
d
i
?
)
,
0
)
d
i
+
=
��
f
i
a
i
?
f
i
p
i
��
2
2
d
i
?
=
��
f
i
a
i
?
f
i
n
i
��
2
2
\begin{gathered} L_{\text {trip }}=\max \left(\max \max \left(d_{i}^{+}\right)-\min \left(d_{i}^{-}\right), 0\right) \\ d_{i}^{+}=\left\|f_{i}^{a_{i}}-f_{i}^{p_{i}}\right\|_{2}^{2} \\ d_{i}^{-}=\left\|f_{i}^{a_{i}}-f_{i}^{n_{i}}\right\|_{2}^{2} \end{gathered}
Ltrip??=max(maxmax(di+?)?min(di??),0)di+?=��fiai???fipi??��22?di??=��fiai???fini??��22??
����
d
i
+
d_{i}^{+}
di+?�DZ�ʾ��������ê��
(
a
i
\left(a_{i}\right.
(ai?��
p
i
)
\left.p_{i}\right)
pi?)�������ԵĶ���,
d
i
?
d_{i}^{-}
di??�DZ�ʾ��������ê��
(
a
i
\left(a_{i}\right.
(ai?��
n
i
)
\left.n_{i}\right)
ni?)�������ԵĶ�����ʹ��ŷ����÷����õ�
d
i
+
d_{i}^{+}
di+?��
d
i
?
d_{i}^{-}
di??��ֵ����
d
i
?
d_{i}^{-}
di??����Сֵ��
d
i
+
d_{i}^{+}
di+?�����ֵ��Ϊ������������ʧ,������Ч�ؽ���������ƶ�,�����������ƶȡ�
C. Adaptive Distance Alignment
�ڴ���������,Triplet loss �����������������Բ�����Ŀ�����������ԡ�Ȼ��,�������������Ʋ������Ƶ�Ŀ��ʱ,triplet loss �����ܱ�֤����֮��IJ�̬�������졣���Գ���ʹ�ú����ķ�������ȡ�������ٴν���ϸ��,ʹ������б�������������Ӧ������뼼�������������⡣����,������ʵ�����з��ִ���δ��ǵIJ�̬���ݡ�Ȼ��,ʹ�þ���ѵ���� SFE ģ�����Щδ��ǵIJ�̬��������ȡʱ��������ʹ����Щʱ��������Ϊ������ K G K_{G} KG?��Ȼ��,���� K G K_{G} KG?�е�������probe set��gallery set�е�ʱ������֮��ľ���,��ѡ��һЩ��� K G K_{G} KG?����ȡ��ʱ���������Ƶ����� F S F_{S} FS?�����,��Ӧ�ԵĴ� F S F_{S} FS?�д�����(mean)�����(maximum)��������(median)����ѡ������ʵĻ�,��ʹ�û���ϸ����ȡ��ʱ��������ͼ 2 ��ʾ������������ϸ�����̡���������ؿ���,����ADAϸ����,probe set��gallery set���������������ƶȺ������������˺ܴ����ߡ�������,��������ϸ����������������ADA��
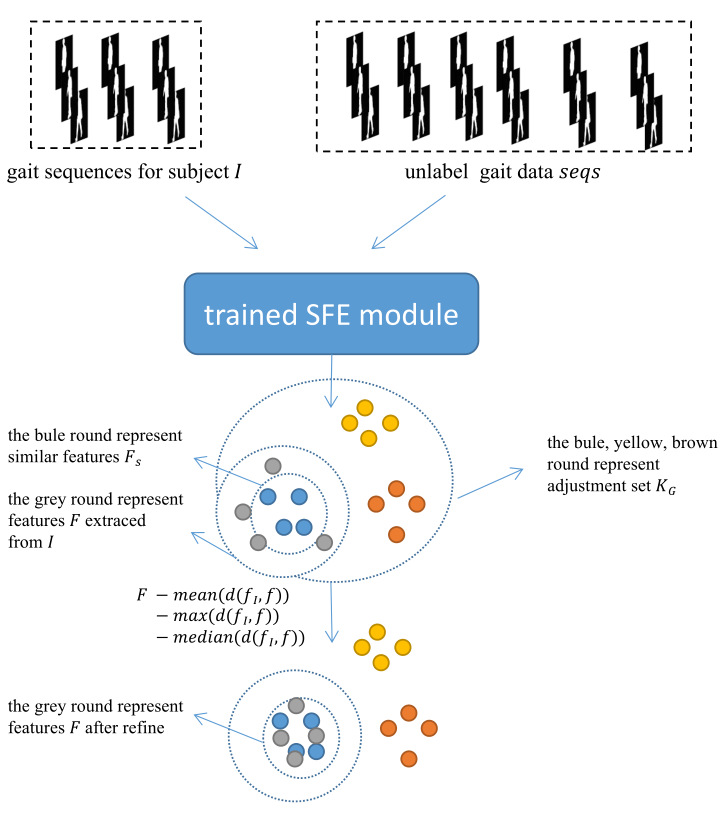
ͼ 2. Ŀ�� I I I�IJ�̬���к�δ��ǵIJ�̬���� Seqs �����뵽����ѵ���� SFE ģ��,���Կ����� I I I����ȡ������ F F F������������������Ժ�С,��ȡ��ʱ����������δ��ǵı����������� K G K_{G} KG?,��ϸ���� I I I����ȡ�������������˲���,����F���������Ⱥ��������ƶȶ������ӡ�
-
������:�ⲿ����Ҫ������������Ӧ���������������ȡ��ʱ���������������������Է�Ϊ�������֡���һ����������ʵ�����з��ִ���δ��ǵIJ�̬���� S e q s Seqs SeqsʱӦ�����صġ�Ӧȷ���ü�����δ��ǵ�����Ӧ�����ʵ�������Ŀ��,��ȷ�����ϵ��Ƚ��ԡ����Ŀ��������,�����д�����,���Ŀ��������,��ᵼ�����ƹ���ϵ����⡣�ڶ�����ʹ��֮ǰ����� SFE ģ��Ӽ��� S e q s Seqs Seqs����ȡʱ����������һ�����Կ�����ЩĿ���������ƶȺ��������ƶ�Ӧ���ж���,���Դ�Ϊ����ϸ��probe set��gallery set�е�ʱ�����������,����Щ��δ�����������ȡ��ʱ��������Ϊ������ K G K_{G} KG?�� K G K_{G} KG?�Ĺ�ʽ����Ϊ
K G = f ( ?Seqs? ) K_{G}=f(\text { Seqs }) KG?=f(?Seqs?)
���� S e q s Seqs Seqs������δ��Dz�̬���ݵIJ�̬����,���а����ʵ������������ߡ� f f f����������ľ���ѵ����ʱ��������ȡģ�顣 K G K_{G} KG?������ϸ��ͼ�⼯��̽�뼯��ʱ�������ĵ������� -
Refinement:����δ��ǵIJ�̬���� S e q s Seqs Seqs�еõ������� K G K_{G} KG?ʱ,���ȼ��� K G K_{G} KG?����Щ������probe set��gallery set�е�ʱ������֮��ľ���,��ѡ��һЩ����ȡ��ʱ���������Ƶ��������� K G K_{G} KG?��ѡ����������FS�Ĺ�ʽ����Ϊ P { d ( f , q i ) ? d ( k , q i ) ) < 0 , k �� K G , f �� F S , F S �� K G } = 1 0 ? t 1 . \left.P\left\{d\left(f, q_{i}\right)-d\left(k, q_{i}\right)\right)<0, k \in K_{G}, f \in F_{S}, F_{S} \in K_{G}\right\}=10^{-t 1} . P{d(f,qi?)?d(k,qi?))<0,k��KG?,f��FS?,FS?��KG?}=10?t1.���� q i q_{i} qi?�Ǵ�probe set��gallery set��Ŀ�� i i i�IJ�̬��������ȡ��ʱ������, f f f�� F S F_{S} FS?�е�ʱ�������� k k k�� K G K_{G} KG?�е�ʱ�������� d ( f , q i ) d\left(f, q_{i}\right) d(f,qi?)��ʾ f f f�� q i q_{i} qi?֮��ľ��롣 d ( k , q i ) d\left(k, q_{i}\right) d(k,qi?)��ʾ k k k�� q i q_{i} qi?֮��ľ��롣�����ʽ��ζ�� F S F_{S} FS?�е� f f f�� q i q_{i} qi?�ľ���С�� K G K_{G} KG?�е� k k k�� q i q_{i} qi?�ľ���ĸ��ʡ����������ҵ�һЩ���� F S F_{S} FS?,��Щ�����������ڴ� K G K_{G} KG?����ȡ��ʱ��������
���õ�
F
S
F_{S}
FS?ʱ,����Ӧ�Եش�����(mean)�����(maximum)��������(median)��������ѡ������ʵ�benchmark
��
(
q
i
,
1
0
?
t
1
)
\theta\left(q_{i}, 10^{-t 1}\right)
��(qi?,10?t1),�Դﵽ��ѵ�ϸ��Ч����ȷ��
��
(
q
i
,
1
0
?
t
1
)
\theta\left(q_{i}, 10^{-t 1}\right)
��(qi?,10?t1)�Ĺ�ʽ����Ϊ
a
d
a
p
=
(
max
?
(
?
)
+
mean
?
(
?
)
+
median
?
(
?
)
)
/
3
,
��
(
q
i
,
1
0
?
t
1
)
=
adap
?
(
d
(
f
,
q
i
)
)
,
f
��
F
S
\begin{gathered} a d a p=(\max (*)+\operatorname{mean}(*)+\operatorname{median}(*)) / 3, \\ \theta\left(q_{i}, 10^{-t 1}\right)=\operatorname{adap}\left(d\left(f, q_{i}\right)\right), f \in F_{S} \end{gathered}
adap=(max(?)+mean(?)+median(?))/3,��(qi?,10?t1)=adap(d(f,qi?)),f��FS??
����
F
S
F_{S}
FS?����probe set��gallery set����Ҫϸ�����������Ƶ������� max��mean��median �ֱ�������ֵ��ƽ��ֵ����ֵ��������ȷ��
F
S
F_{S}
FS?���������ƵĹ��ܶ���������á� adpt ��һ������Ӧ������ѡ����ʵĻ�
��
(
q
i
,
1
0
?
t
1
)
\theta\left(q_{i}, 10^{-t 1}\right)
��(qi?,10?t1)��
����������ʵ�
��
(
q
i
,
1
0
?
t
1
)
\theta\left(q_{i}, 10^{-t 1}\right)
��(qi?,10?t1)ʱ,���Ե���֮ǰ��ȡ��ʱ������
q
i
q_{i}
qi?��ʹ��
��
(
q
i
,
1
0
?
t
1
)
\theta\left(q_{i}, 10^{-t 1}\right)
��(qi?,10?t1)��Ϊ����ϸ��ʱ������,��ʹ���Ǹ����б��������幫ʽ��������:
d
��
(
g
,
q
i
,
1
0
?
t
1
)
=
d
(
g
,
q
i
)
?
��
(
q
i
,
1
0
?
t
1
)
d^{\prime}\left(g, q_{i}, 10^{-t 1}\right)=d\left(g, q_{i}\right)-\theta\left(q_{i}, 10^{-t 1}\right)
d��(g,qi?,10?t1)=d(g,qi?)?��(qi?,10?t1)
����
d
(
g
,
q
i
)
d\left(g, q_{i}\right)
d(g,qi?)����ȷ����̬����
i
i
i�����ĸ�Ŀ��ʱ,̽�뼯�е�Ŀ��
i
i
i�뻭�ȼ��е�Ŀ��֮���ԭʼ����,
��
(
q
i
,
1
0
?
t
1
)
\theta\left(q_{i}, 10^{-t 1}\right)
��(qi?,10?t1)��ʱ�յ�ֵ��Ҫϸ��Ŀ��
i
i
i������
q
i
q_{i}
qi?,
d
��
(
g
,
q
i
,
1
0
?
t
1
)
d^{\prime}\left(g, q_{i}, 10^{-t 1}\right)
d��(g,qi?,10?t1)�ǵ������̽�뼯�е�Ŀ��
i
i
i��ͼ�⼯�е�Ŀ��֮��ľ���,�����ж�Ŀ������ݡ�����,�ù�ʽ����̽�뼯�е��������е���,��������ƥ������վ��롣������һ��������ͬʱϸ��ͼ�⼯��̽�뼯�е�Ŀ���ʱ������ʱ,��ʽ���Զ�������:
d
��
(
g
,
q
,
1
0
?
t
1
)
=
d
(
g
,
q
)
?
��
g
?
��
(
g
,
1
0
?
t
1
)
?
��
q
?
��
(
q
,
1
0
?
t
1
)
d^{\prime}\left(g, q, 10^{-t 1}\right)=d(g, q)-\lambda_{g} * \theta\left(g, 10^{-t 1}\right)-\lambda_{q} * \theta\left(q, 10^{-t 1}\right)
d��(g,q,10?t1)=d(g,q)?��g??��(g,10?t1)?��q??��(q,10?t1)
����
��
(
g
,
1
0
?
t
1
)
\theta\left(g, 10^{-t 1}\right)
��(g,10?t1)�ǵ������ȼ���Ŀ��ʱ��������ֵ,
��
(
q
,
1
0
?
t
1
)
\theta\left(q, 10^{-t 1}\right)
��(q,10?t1)�ǵ���̽�뼯�ж���ʱ��������ֵ.
��
g
\lambda_{g}
��g?��
��
q
\lambda_{q}
��q?��ȷ��ϸ���̶ȵij�������
�����
[43] X. Li, S. J. Maybank, S. Yan, D. Tao, and D. Xu, ��Gait components and their application to gender recognition,�� IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 2, pp. 145�C155, 2008.

