关键词提取 (Keyphrase Extraction,KPE) 任务可以自动提取文档中能够概括核心内容的短语,有利于下游信息检索和 NLP 任务。当前,由于对文档进行标注需要耗费大量资源且缺乏大规模的关键词提取数据集,无监督的关键词提取在实际应用中更为广泛。无监督关键词抽取的state of the art(SOTA)方法是对候选词和文档标识之间的相似度进行排序来选择关键词。但由于候选词和文档序列长度之间的差异导致了关键短语候选和文档的表征不匹配,导致以往的方法在长文档上的性能不佳,无法充分利用预训练模型的上下文信息对短语构建表征。下面主要介绍一些主流的KPE算法。
目录
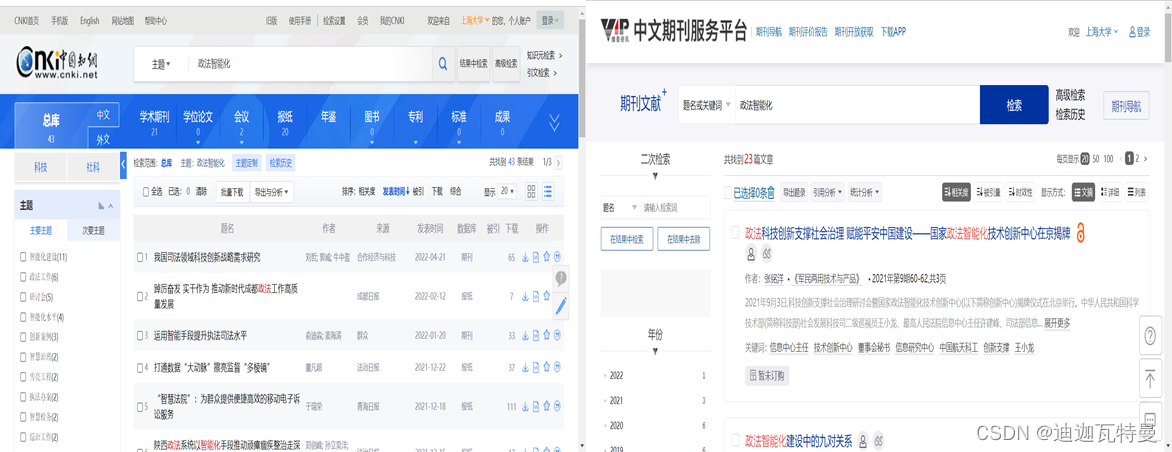
数据集
数据集来自知网和维普网,知网、维普网等数据集的关键词提取可以作为知识发现的一种途径,由于当前关键词提取的各类算法各有优劣,基于统计学的算法依赖切分词效果且缺失上下文语义信息,基于预训练模型的算法偏向于获取长度较长的短语,且在英文数据集效果好于中文数据集,可以尝试结合各类算法结果互补,在缺乏专家知识情况下得到较优的新词发现结果,然后获得细粒度的切分词效果,然后基于词信息熵约束构建整个概念权重网络。
一、基于词袋加权的TFIDF算法
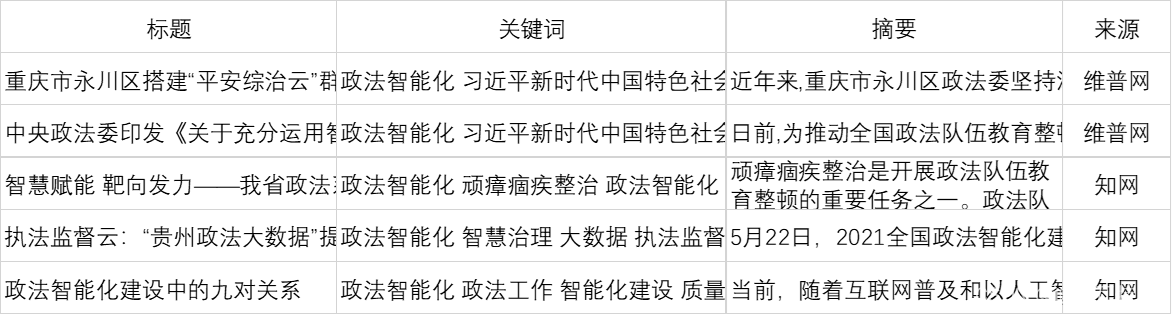
TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降,也就是说一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。
![]()
其中:?

![]()
1.1 代码实现
import jieba.posseg
import jieba.analyse as analyse
text = '''注重数据整合,……风险防控平台。'''
jieba.analyse.extract_tags(text, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v','nr', 'nt'))
[('司法', 0.31185579872983193),
('办案', 0.30549557299495794),
('监督', 0.2777759298537815),
('执法', 0.2525081091236975),
('数据', 0.2410768073137815),
('信息化', 0.19543384931243696),
('制约', 0.1762166436305042),
('检察', 0.16083940019647058),
('平台', 0.15742034837521007),
('建立健全', 0.14336201048487393),
('共享', 0.13940967370890756),
('流程', 0.13050609682168068),
('建设', 0.12384406716756305),
('升级', 0.11327448311445379),
('强化', 0.11210276468184874),
('信息资源管理', 0.11098765102016807),
('检务', 0.10758038120420169),
('执法监督', 0.10516288479747898),
('机制', 0.10114895349579832),
('质效', 0.10046023111680671)]
1.2 优缺点
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
此外,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,IDF的简单结构并不能有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整。
二、考虑词关联网络的TextRank算法?
上面说到,TF-IDF基于词袋模型(Bag-of-Words),把文章表示成词汇的集合,由于集合中词汇元素之间的顺序位置与集合内容无关,所以TF-IDF指标不能有效反映文章内部的词汇组织结构。
TextRank由Mihalcea与Tarau提出,通过词之间的相邻关系构建网络,然后用PageRank迭代计算每个节点的rank值,排序rank值即可得到关键词。
 ??
??
TextRank是一种基于随机游走的关键词提取算法,考虑到不同词对可能有不同的共现(co-occurrence),TextRank将共现作为无向图边的权值。
其中,TextRank的迭代计算公式如下:
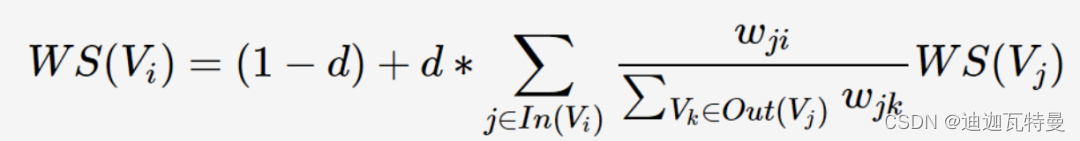
其实现包括以下步骤:
(1)把给定的文本T按照完整句子进行分割;
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即,其中 ti,j 是保留后的候选关键词;
(3)构建候选关键词图G = (V,E),其中V为节点集,由2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词;
(4)根据上面公式,迭代传播各节点的权重,直至收敛;
(5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词;
(6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词;?
2.1? 代码实现
text = '''注重数据整合,……风险防控平台。'''
jieba.analyse.textrank(text, topK=20, withWeight=True, allowPOS=('ns', 'n', 'vn', 'v','nr', 'nt'))
[('司法', 1.0),
('监督', 0.9647984621021379),
('执法', 0.9607658008450345),
('数据', 0.936840175155704),
('办案', 0.7554052188217514),
('建设', 0.6797698445288832),
('信息化', 0.6182449557968936),
('制约', 0.6070954362892574),
('强化', 0.4675181408168901),
('建立健全', 0.43126634205277503),
('机制', 0.42314571354973163),
('升级', 0.395175446851567),
('平台', 0.38252149436269084),
('实现', 0.37281981288061544),
('检察', 0.3638332738126375),
('审批', 0.3615199226179736),
('流程', 0.3538368902905029),
('服务', 0.33734573589742606),
('省公安厅', 0.30721478530101143),
('方式', 0.2926132650881588)]
2.2??优缺点
TextRank与TFIDF均严重依赖于分词结果―如果某词在分词时被切分成了两个词,那么在做关键词提取时无法将两个词黏合在一起
不过,TextRank虽然考虑到了词之间的关系,但是仍然倾向于将频繁词作为关键词。
三、结合主题的LDA算法?
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
因此计算词的分布和文档的分布的相似度,取相似度最高的几个词作为关键词。
3.1 代码实现
下面调用百度预训练主题模型famila为例,预先训练2000个主题,得到给定文档的关键词集合。?
pip install paddlehub -i https://pypi.tuna.tsinghua.edu.cn/simplepip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simpleimport paddlehub as hub
lda_news = hub.Module(name="lda_news")
lda_news.cal_doc_keywords_similarity(text)
[{'word': '数据', 'similarity': 0.053430402861311135},
{'word': '网上', 'similarity': 0.04304698264119976},
{'word': '监督', 'similarity': 0.03763464327414399},
{'word': '司法', 'similarity': 0.03449577064780817},
{'word': '建设', 'similarity': 0.02851954961542021},
{'word': '建立', 'similarity': 0.027868159159810404},
{'word': '执法', 'similarity': 0.026410626643778714},
{'word': '平台', 'similarity': 0.019379493438481735},
{'word': '信息', 'similarity': 0.014868101543143764},
{'word': '管理', 'similarity': 0.013716799754179797}]
3.2?优缺点
LDA通过主题建模,在一定程度上考虑了文档与关键词在主题上的一致性,但这需要找到合适的主题数目作为超参数,具体的效果受其影响较大。
四、结合语义编码的KeyBert算法?
KeyBERT(Sharma, P., & Li, Y. (2019). Self-Supervised Contextual Keyword and Keyphrase Retrieval with Self-Labelling),提出了一个利用bert快速提取关键词的方法。
原理十分简单:首先使用 BERT 提取文档嵌入以获得文档级向量表示。随后,为N-gram 词/短语提取词向量,然后,我们使用余弦相似度来找到与文档最相似的单词/短语。最后可以将最相似的词识别为最能描述整个文档的词。
其中,有几个参数:
keyphrase_ngram_range:?默认(1, 1),表示单个词, 如"抗美援朝", "纪念日"是孤立的两个词;(2, 2)表示考虑词组, 如出现有意义的词组 "抗美援朝 纪念日;(1, 2)表示同时考虑以上两者情况;
top_n:显示前n个关键词,默认5;
use_maxsum:?默认False;是否使用Max Sum Similarity作为关键词提取标准;
use_mmr:?默认False;是否使用Maximal Marginal Relevance (MMR) 作为关键词提取标准;
diversity:?如果use_mmr=True,可以设置该参数。参数取值范围从0到1;
4.1 代码实现
pip install keybert
pip install zh_core_web_sm-2.3.1.tar.gz
pip install --index https://pypi.mirrors.ustc.edu.cn/simple/ spacy==2.3.1import os
from keybert import KeyBERT
kw_model = KeyBERT(model='paraphrase-MiniLM-L6-v2')
print("naive ...")
keywords = kw_model.extract_keywords(text)
print(keywords)
print("\nkeyphrase_ngram_range ...")
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(1, 2), stop_words=None)
print(keywords)
print("\nhighlight ...")
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(1, 2), highlight=None)
print(keywords)
# 为了使结果多样化,我们将 2 x top_n 与文档最相似的词/短语。
# 然后,我们从 2 x top_n 单词中取出所有 top_n 组合,并通过余弦相似度提取彼此最不相似的组合。
print("\nuse_maxsum ...")
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(1, 3), stop_words=None,
use_maxsum=True, nr_candidates=20, top_n=5)
print(keywords)
# 为了使结果多样化,我们可以使用最大边界相关算法(MMR)
# 来创建同样基于余弦相似度的关键字/关键短语。 具有高度多样性的结果:
print("\nhight diversity ...")
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(3, 3), stop_words=None,
use_mmr=True, diversity=0.7)
print(keywords)
# 低多样性的结果
print("\nlow diversity ...")
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(3, 3), stop_words=None,
use_mmr=True, diversity=0.2)
print(keywords)
naive ...
[('建立健全以办案流程节点为依托的执法司法风险防控平台', 0.8561), ('省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设', 0.8493), ('全省政法各单位充分利用数字化办案系统', 0.8323), ('健全完善执法司法数据跨部门共享机制', 0.8266), ('不断升级信息化执法监督制约方式', 0.8068)]
keyphrase_ngram_range ...
[('强化内部制约监督效能 省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设', 0.9147), ('破解信息资源管理分散等问题 健全完善执法司法数据跨部门共享机制', 0.8647), ('强化制约监督 全省政法各单位充分利用数字化办案系统', 0.8584), ('建立健全以办案流程节点为依托的执法司法风险防控平台', 0.8562), ('建立信息化全流程监管模式 省检察院建立健全检察机关主动', 0.8528)]
highlight ...
[('强化内部制约监督效能 省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设', 0.9147), ('破解信息资源管理分散等问题 健全完善执法司法数据跨部门共享机制', 0.8647), ('强化制约监督 全省政法各单位充分利用数字化办案系统', 0.8584), ('建立健全以办案流程节点为依托的执法司法风险防控平台', 0.8562), ('建立信息化全流程监管模式 省检察院建立健全检察机关主动', 0.8528)]
use_maxsum ...
[('省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设 推动', 0.8472), ('畅通信访举报渠道 省公安厅建设升级陕西省执法办案与监督信息系统 实现执法办案信息网上登记', 0.8489), ('大数据慧治 建立健全以办案流程节点为依托的执法司法风险防控平台', 0.851), ('建立健全以办案流程节点为依托的执法司法风险防控平台', 0.8562), ('破解信息资源管理分散等问题 健全完善执法司法数据跨部门共享机制 强化内部制约监督效能', 0.8788)]
hight diversity ...
[('健全完善执法司法数据跨部门共享机制 强化内部制约监督效能 省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设', 0.9189), ('网上办理 网上流转 网上审批', 0.6486), ('省公安厅建设升级陕西省执法办案与监督信息系统 实现执法办案信息网上登记 网上办理', 0.7693), ('推动 数据融合 实现', 0.7187), ('大平台共享 深化 数字法治', 0.7606)]
low diversity ...
[('健全完善执法司法数据跨部门共享机制 强化内部制约监督效能 省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设', 0.9189), ('强化内部制约监督效能 省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设 推动', 0.9179), ('全省政法各单位充分利用数字化办案系统 着眼 大平台共享', 0.8817), ('不断升级信息化执法监督制约方式 提升监督质效 省司法厅着眼', 0.8823), ('注重数据整合 强化制约监督 全省政法各单位充分利用数字化办案系统', 0.879)]
from summa import keywords
TR_keywords = keywords.keywords(full_text, scores=True)
print(TR_keywords[0:20])
[('数据', 0.27811562664925327), ('网上', 0.23353936120730634), ('司法', 0.19555733290021046), ('办案', 0.18536208784194033), ('建设', 0.16875844285923788), ('省', 0.16739452207874952), ('以', 0.16179660543000285), ('信息化', 0.15886621227446107), ('强化 制约 监督', 0.1571025009399033), ('执法', 0.15167298103198953), ('公开', 0.12563130308031134), ('大 平台 共享', 0.12330342757605328), ('建立健全', 0.11496091387406318), ('机制', 0.11363250711566682), ('推动', 0.11310855565873683), ('为', 0.11257151827272399), ('流程', 0.11241271570334126), ('升级', 0.10976078642866843), ('的', 0.10452100670042948)]
import keybert
import jieba
from keybert import KeyBERT
model = KeyBERT('bert-base-chinese')
doc = " ".join(jieba.cut(text))
keywords = model.extract_keywords(doc, keyphrase_ngram_range=(1,1), top_n=20)
keywords
[('信息资源管理', 0.728),
('数据管理', 0.6426),
('检察机关', 0.6256),
('执法监督', 0.609),
('省公安厅', 0.6074),
('信息系统', 0.5997),
('高级法院', 0.5968),
('建立健全', 0.5939),
('数据中心', 0.5848),
('法律文书', 0.5768),
('跨部门', 0.5541),
('充分利用', 0.538),
('数字化', 0.5258),
('司法厅', 0.5079),
('信息沟通', 0.5069),
('检察院', 0.4902),
('当事人', 0.4812),
('信息网', 0.4779),
('陕西省', 0.4663),
('信息化', 0.458)]
import keybert
import jieba
from keybert import KeyBERT
model = KeyBERT('bert-base-chinese')
# doc = " ".join(jieba.cut(text))
keywords = model.extract_keywords(text, keyphrase_ngram_range=(1,1), top_n=20)
keywords
[('省高级法院持续推进以司法大数据管理和服务为基础的司法数据中台建设', 0.941),
('建立健全以办案流程节点为依托的执法司法风险防控平台', 0.9342),
('健全完善执法司法数据跨部门共享机制', 0.9088),
('省公安厅建设升级陕西省执法办案与监督信息系统', 0.9018),
('不断升级信息化执法监督制约方式', 0.8895),
('全省政法各单位充分利用数字化办案系统', 0.8838),
('建立信息化全流程监管模式', 0.8638),
('实现执法办案信息网上登记', 0.8534),
('省检察院建立健全检察机关主动', 0.8509),
('破解信息资源管理分散等问题', 0.8288),
('建成陕西法院数据中心', 0.8151),
('强化内部制约监督效能', 0.8121),
('相关当事人信息沟通机制', 0.8117),
('信息化体系建设', 0.8055),
('加大检务公开力度', 0.7881),
('畅通信访举报渠道', 0.7688),
('法律文书网上生成', 0.7368),
('强化制约监督', 0.7339),
('提升监督质效', 0.7244),
('省司法厅着眼', 0.7125)]
4.2?优缺点
Keybert基于一种假设,关键词与文档在语义表示上是一致的,利用bert的编码能力,能够得到较好的结果。
但缺点很明显:
首先,不同的语义编码模型会产生不同的结果,这个比较重要。
此外,由于bert只能接受限定长度的文本,例如512个字,这个使得我们在处理长文本时,需要进一步加入摘要提取等预处理措施,这无疑会带来精度损失。
五、Yake?
5.1 算法思想?
它是一种轻量级、无监督的自动关键词提取方法,它依赖于从单个文档中提取的统计文本特征来识别文本中最相关的关键词。该方法不需要针对特定的文档集进行训练,也不依赖于字典、文本大小、领域或语言。Yake 定义了一组五个特征来捕捉关键词特征,这些特征被启发式地组合起来,为每个关键词分配一个分数。分数越低,关键字越重要。你可以阅读原始论文[2],以及yake 的Python 包[3]关于它的信息。
特征提取主要考虑五个因素(去除停用词后)
大写term
(Casing)
大写字母的term(除了每句话的开头单词)的重要程度比那些小写字母的term重要程度要大。?
其中,表示该词的大写次数,?
表示该词的缩写次数。
词的位置
(Word Position)
文本越开头的部分句子的重要程度比后面的句子重要程度要大。
其中表示包含该词的所有句子在文档中的位置中位数。
词频
(Term Frequency)
一个词在文本中出现的频率越大,相对来说越重要,同时为了避免长文本词频越高的问题,会进行归一化操作。
其中,MeanTF是整个词的词频均值,??是标准差。
上下文关系
(Term Related to Context)
一个词与越多不相同的词共现,该词的重要程度越低。
其中??表示窗口size为??从左边滑动, DR表示从右边滑动。?表示出现在固定窗口大小为 w下,出现不同的词的个数。?
表示所有词频的最大值。
词在句子中出现的频率
(Term Different Sentence):一个词在越多句子中出现,相对更重要
其中 SF(t) 是包含词t tt的句子频率,?表示所有句子数量。
最后计算每个term的分值公式如下:
S(t)表示的是单词 t 的分值情况,其中 s(t) 分值越小,表示的单词 t 越重要。
5.2?代码实现
pip install git+https://github.com/LIAAD/yake首先从 Yake 实例中调用?KeywordExtractor?构造函数,它接受多个参数,其中重要的是:要检索的单词数top,此处设置为 10。参数?lan:此处使用默认值en。可以传递停用词列表给参数?stopwords。然后将文本传递给?extract_keywords?函数,该函数将返回一个元组列表?(keyword: score)。关键字的长度范围为 1 到 3。?
import yake
title = '智慧赋能 靶向发力――我省政法系统以智能化手段推动顽瘴痼疾整治'
full_text = title +", "+ text
full_text = " ".join(jieba.cut(full_text))
kw_extractor = yake.KeywordExtractor(top=10, n=1,stopwords=None)
keywords = kw_extractor.extract_keywords(full_text)
for kw, v in keywords:
print("Keyphrase: ",kw, ": score", v)
Keyphrase: 信息化 : score 0.018271441664539194 Keyphrase: 建立健全 : score 0.029319757789913803 Keyphrase: 数据中心 : score 0.060484839399623465 Keyphrase: 省公安厅 : score 0.060484839399623465 Keyphrase: 信息系统 : score 0.060484839399623465 Keyphrase: 法律文书 : score 0.060484839399623465 Keyphrase: 政法系统 : score 0.06658412709343704 Keyphrase: 智能化 : score 0.06658412709343704 Keyphrase: 充分利用 : score 0.06658412709343704 Keyphrase: 数字化 : score 0.06658412709343704 Keyphrase: 信息资源管理 : score 0.06658412709343704 Keyphrase: 跨部门 : score 0.06658412709343704 Keyphrase: 高级法院 : score 0.06658412709343704 Keyphrase: 数据管理 : score 0.06658412709343704 Keyphrase: 检察院 : score 0.06658412709343704 Keyphrase: 检察机关 : score 0.06658412709343704 Keyphrase: 当事人 : score 0.06658412709343704 Keyphrase: 信息沟通 : score 0.06658412709343704 Keyphrase: 陕西省 : score 0.06658412709343704 Keyphrase: 信息网 : score 0.06658412709343704
六、Rake
6.1 算法思想?
Rake 是 Rapid Automatic Keyword Extraction 的缩写,它是一种从单个文档中提取关键字的方法。实际上提取的是关键的短语(phrase),并且倾向于较长的短语,在英文中,关键词通常包括多个单词,但很少包含标点符号和停用词,例如and,the,of等,以及其他不包含语义信息的单词。
Rake算法首先使用标点符号(如半角的句号、问号、感叹号、逗号等)将一篇文档分成若干分句,然后对于每一个分句,使用停用词作为分隔符将分句分为若干短语,这些短语作为最终提取出的关键词的候选词。
每个短语可以再通过空格分为若干个单词,可以通过给每个单词赋予一个得分,通过累加得到每个短语的得分。Rake 通过分析单词的出现及其与文本中其他单词的兼容性(共现)来识别文本中的关键短语。最终定义的公式是:
即单词??的得分是该单词的度(是一个网络中的概念,每与一个单词共现在一个短语中,度就加1,考虑该单词本身)除以该单词的词频(该单词在该文档中出现的总次数)。
然后对于每个候选的关键短语,将其中每个单词的得分累加,并进行排序,RAKE将候选短语总数的前三分之一的认为是抽取出的关键词。
6.2?代码实现
不调用包的情况下
import jieba
import jieba.posseg as pseg
import operator
import json
from collections import Counter
# Data structure for holding data
class Word():
def __init__(self, char, freq = 0, deg = 0):
self.freq = freq
self.deg = deg
self.char = char
def returnScore(self):
return self.deg/self.freq
def updateOccur(self, phraseLength):
self.freq += 1
self.deg += phraseLength
def getChar(self):
return self.char
def updateFreq(self):
self.freq += 1
def getFreq(self):
return self.freq
# Check if contains num
def notNumStr(instr):
for item in instr:
if '\u0041' <= item <= '\u005a' or ('\u0061' <= item <='\u007a') or item.isdigit():
return False
return True
# Read Target Case if Json
def readSingleTestCases(testFile):
with open(testFile) as json_data:
try:
testData = json.load(json_data)
except:
# This try block deals with incorrect json format that has ' instead of "
data = json_data.read().replace("'",'"')
try:
testData = json.loads(data)
# This try block deals with empty transcript file
except:
return ""
returnString = ""
for item in testData:
try:
returnString += item['text']
except:
returnString += item['statement']
return returnString
def run(rawText):
# Construct Stopword Lib
swLibList = [line.rstrip('\n') for line in open(r"../../../stopword/stopwords.txt",'r',encoding='utf-8')]
# Construct Phrase Deliminator Lib
conjLibList = [line.rstrip('\n') for line in open(r"wiki_quality.txt",'r',encoding='utf-8')]
# Cut Text
rawtextList = pseg.cut(rawText)
# Construct List of Phrases and Preliminary textList
textList = []
listofSingleWord = dict()
lastWord = ''
poSPrty = ['m','x','uj','ul','mq','u','v','f']
meaningfulCount = 0
checklist = []
for eachWord, flag in rawtextList:
checklist.append([eachWord,flag])
if eachWord in conjLibList or not notNumStr(eachWord) or eachWord in swLibList or flag in poSPrty or eachWord == '\n':
if lastWord != '|':
textList.append("|")
lastWord = "|"
elif eachWord not in swLibList and eachWord != '\n':
textList.append(eachWord)
meaningfulCount += 1
if eachWord not in listofSingleWord:
listofSingleWord[eachWord] = Word(eachWord)
lastWord = ''
# Construct List of list that has phrases as wrds
newList = []
tempList = []
for everyWord in textList:
if everyWord != '|':
tempList.append(everyWord)
else:
newList.append(tempList)
tempList = []
tempStr = ''
for everyWord in textList:
if everyWord != '|':
tempStr += everyWord + '|'
else:
if tempStr[:-1] not in listofSingleWord:
listofSingleWord[tempStr[:-1]] = Word(tempStr[:-1])
tempStr = ''
# Update the entire List
for everyPhrase in newList:
res = ''
for everyWord in everyPhrase:
listofSingleWord[everyWord].updateOccur(len(everyPhrase))
res += everyWord + '|'
phraseKey = res[:-1]
if phraseKey not in listofSingleWord:
listofSingleWord[phraseKey] = Word(phraseKey)
else:
listofSingleWord[phraseKey].updateFreq()
# Get score for entire Set
outputList = dict()
for everyPhrase in newList:
if len(everyPhrase) > 5:
continue
score = 0
phraseString = ''
outStr = ''
for everyWord in everyPhrase:
score += listofSingleWord[everyWord].returnScore()
phraseString += everyWord + '|'
outStr += everyWord
phraseKey = phraseString[:-1]
freq = listofSingleWord[phraseKey].getFreq()
if freq / meaningfulCount < 0.01 and freq < 3 :
continue
outputList[outStr] = score
sorted_list = sorted(outputList.items(), key = operator.itemgetter(1), reverse = True)
return sorted_list[:50]
if __name__ == '__main__':
with open(r'Ai_zhaiyaohebing.txt','r') as fp:
text = ''
for i in range(100):
text += fp.readline()
# print(text)
result = run(text)
print(result)
[('顽瘴痼疾整治', 14.850198412698413), ('国家政法智能化技术创新中心', 12.765927246319404), ('政法智能化建设技术装备', 12.165968381654658), ('政法工作高质量发展', 10.637037037037036), ('浙江政法数字化改革', 9.121612005235697), ('微嘉园', 8.8125), ('政法智能化建设', 8.165968381654658), ('平安中国建设', 8.050367932720874), ('我国政法建设', 7.811164302212895), ('统一桌面平台', 6.734188034188034), ('习近平法治思想', 6.269047619047619), ('数据办案平台', 6.147406498891647), ('司法数据跨部门', 6.076386781535296), ('智慧检务', 5.840354767184035), ('非司法领域', 5.786271896420411), ('智能化建设', 5.573375789062064), ('经营活动', 5.542857142857143), ('政法公共服务', 5.467592592592593), ('深度融合', 5.410714285714286), ('数字法治', 5.338345864661655), ('政法建设', 5.289425171778113), ('微法院', 5.286184210526316), ('智能机器人', 5.244897959183674), ('办案人员', 5.240924092409241), ('智慧法院', 5.13222079589217), ('政法机关', 4.9467592592592595), ('智能监督', 4.9397031539888685), ('智慧司法', 4.915962327940111), ('预付费市场', 4.9), ('政法跨部门', 4.872592592592593), ('区块链', 4.855555555555555), ('在线服务', 4.789687924016283), ('制约监督', 4.772727272727273), ('技术创新策源地', 4.705882352941177), ('政法单位', 4.65925925925926), ('全省政法', 4.592592592592593), ('政法工作', 4.592592592592593), ('台建设', 4.530165912518854), ('顶层设计', 4.4935064935064934), ('数字化改革', 4.471876555500248), ('疫情防控', 4.392857142857142), ('智能化手段', 4.364348087925324), ('政法干警', 4.352592592592592), ('办公办案', 4.288543140028288), ('法治日报', 4.285714285714286), ('政法队伍教育', 4.190476190476191), ('政法领域', 4.121438746438747), ('强劲动力', 4.0), ('协商录音', 4.0), ('智慧社会', 3.965354767184036)]
调用包的情况下?
pip install multi_rakefrom multi_rake import Rake
rake = Rake()
keywords = rake.apply(text)
print(keywords[:20])
[('荣获2020年全市大数据智能化十佳应用案例入围奖。 日前', 4.0), ('人盯人,人 管案', 4.0), ('一刀 切', 4.0), ('法律的生命不在于逻辑而在于经 验。', 4.0), ('法 之理在法外', 4.0), ('电 脑判案', 4.0), ('正 在加快应用,', 4.0), ('升级, 执法司法结果从', 4.0), ('智慧警 务', 4.0), ('的同时, 着力夯实', 4.0), ('结合起来,不 断拓展智能化建设的', 4.0), ('却下得越来越少,键盘 代替了', 4.0), ('的变革。作为智慧社会的驱动引擎和治理技术,互联网、大数据、云计算、人工智能为智慧社会建设提供了强大的生存条件和技术基础,数字化、网络化、智能化成为 ‘社会5.0’时代智慧社会的主要特征。', 4.0), ('本文选择人工智能技术作为观察对象,客观描述其在当下政法建设中的实然状态,审视在实践背后隐藏着的主要矛盾,以此就人工智能在政法智能化建设中的完善路径提出初步建议。希望通过对人工智能技术的讨论,可以针对现阶段新兴技术在政法实践层面出现的部分问题提供一种解决思路,并为今后一个阶段的政法智能化建设予以借鉴二、人工智能在政法智能化建设中的实践应用 人工智能', 4.0), ('。 随着人工智能技术的不断发展,现阶段该技术在智慧政法建设的应用范围已涵盖了司法、检察、公共安全、行政司法等诸领域。2017年3月,最高法印发《最高人民法院关千加快建设智慧法院的意见》,对建设智慧法院的总体要求、目标和意义等进行说明,并明确提出', 4.0), ('运用大数据和人工智能技术,按需提供 精准智能服务', 4.0), ('另一部分问题则可以被看作是属千政法建 设中特有的问题,例如智能法官', 4.0), ('的描述,使得人工智能已经远远超脱了其概念本身的文字含义。对人工智能的讨论,涵盖了政治、伦理、宗教、科技等多个维度,这更使得想要对其概念采取一个简单或较为一致的定义成为了非常困难的事情。 另一方面,人工智能概念的模糊性,并没有随着近年学术界特别是法学界的相关研究增多而得到澄清,', 4.0), ('类似的情况在自动驾驶汽车与尤人驾驶汽车、专家系统与数据库系统等相似概念中同样存在,而不加区分的对其进行研究是一种缺乏基本科学性与严谨性的表现。 这种概念的模糊性,与政法系统本身对千概念准确性的要求是背道而驰的。我国的政法系统,即中国共产党领导下的政法系统,其从概念和体制上被定义为一个特殊的系统,负责履行审判、检察、警察、国家安全、司行法政等重要职能。', 4.0), ('》 (以下简称《五年发展规划》)为例,在其重点建设任务实施路线图中,确定了53项具体重点任务及明确的时间规划。同时,在信息化建设目标图像的设定上,《五年发展规划》围绕着信息化标准规范建设基础设施建设应用建设、信息资源建设等七个方面进行了完备的描述。但对于涉及人工智能部分,则并没有更为具体的内容说明,对其主要表述为突破人工智能关键技术等难题', 4.0)]
七、Summa?
pip install summafrom summa import keywords
TR_keywords = keywords.keywords(full_text, scores=True)
print(TR_keywords[0:20])
[('数据', 0.27811562664925327), ('网上', 0.23353936120730634), ('司法', 0.19555733290021046), ('办案', 0.18536208784194033), ('建设', 0.16875844285923788), ('省', 0.16739452207874952), ('以', 0.16179660543000285), ('信息化', 0.15886621227446107), ('强化 制约 监督', 0.1571025009399033), ('执法', 0.15167298103198953), ('公开', 0.12563130308031134), ('大 平台 共享', 0.12330342757605328), ('建立健全', 0.11496091387406318), ('机制', 0.11363250711566682), ('推动', 0.11310855565873683), ('为', 0.11257151827272399), ('流程', 0.11241271570334126), ('升级', 0.10976078642866843), ('的', 0.10452100670042948)]
八、Autophrasex
8.1 算法思想
Autophrasex是新词发现算法,主要思想是:
Robust Positive-Only Distant Training:使用wiki和freebase作为显眼数据,根据知识库中的相关数据构建Positive Phrases,根据领域内的文本生成Negative Phrases,构建分类器后根据预测的结果减少负标签带来的噪音问题。
POS-Guided Phrasal Segmentation:使用POS词性标注的结果,引导短语分词,利用POS的浅层句法分析的结果优化Phrase bo
AutoPhrase可以支持任何语言,只要该语言中有通用知识库。与当下最先进的方法比较,新方法在跨不同领域和语言的5个实际数据集上的有效性有了显著提高。
8.2 代码实现?
pip install autophrasexfrom autophrasex import *
# 构造autophrase
autophrase = AutoPhrase(
? ? reader=DefaultCorpusReader(tokenizer=JiebaTokenizer()),
? ? selector=DefaultPhraseSelector(),
? ? extractors=[
? ? ? ? NgramsExtractor(N=4),?
? ? ? ? IDFExtractor(),?
? ? ? ? EntropyExtractor()
? ? ]
)
# 开始挖掘
predictions = autophrase.mine(
? ? corpus_files=['./Ai_zhaiyaohebing.txt'],
? ? quality_phrase_files='./wiki_quality.txt',
? ? callbacks=[
? ? ? ? LoggingCallback(),
? ? ? ? ConstantThresholdScheduler(),
? ? ? ? EarlyStopping(patience=2, min_delta=5)
? ? ])
# 输出挖掘结果
for pred in predictions:
? ? print(pred)
('网站', 0.25)
('检察院', 0.24)
('数字化 改革', 0.19)
('处置', 0.19)
('挑战', 0.18)
('政策', 0.18)
('制定', 0.17)
('提升', 0.15)
('信息', 0.13)
('一体化', 0.13)
('语音', 0.13)
('管理系统', 0.13)
('档案', 0.13)
('改革', 0.12)
('推动', 0.11)
('解决', 0.11)
('防范', 0.11)
('落实', 0.11)
('成果', 0.11)
('构建', 0.1)
('地方', 0.1)
('工作', 0.09)
('推进', 0.09)
('科技', 0.09)
('数字', 0.09)
('风险', 0.09)
('质效', 0.09)
('设计', 0.09)
('痼疾', 0.09)
('办案 平台', 0.09)
('实时', 0.09)
('情况', 0.09)
('组织', 0.09)
('政法委', 0.08)
('联动', 0.08)
('干警', 0.08)
('司法 行政', 0.08)
('微嘉园', 0.08)
('材料', 0.08)
('政法', 0.07)
('数据', 0.07)
('三个', 0.07)
('调解', 0.07)
('现代化', 0.07)
('打通', 0.07)
('水平', 0.07)
('联网', 0.07)
('深度 融合', 0.07)
('机制', 0.06)
('办理', 0.06)
('功能', 0.06)
('过程', 0.06)
('案例', 0.06)
('网格', 0.06)
('时代', 0.06)
('区块', 0.06)
('环节', 0.06)
('司法厅', 0.06)
('介绍', 0.06)
('制约 监督', 0.06)
('企业', 0.06)
('司法', 0.05)
('执法', 0.05)
('实践', 0.05)
('数字化', 0.05)
('人工智能 技术', 0.05)
('部门', 0.05)
('检察', 0.05)
('能力', 0.05)
('单位', 0.05)
('核心', 0.05)
('重点', 0.05)
('提高', 0.05)
('政法 单位', 0.05)
('注重', 0.05)
('计算', 0.05)
('着力', 0.05)
('办案', 0.04)
('服务', 0.04)
('智能化 建设', 0.04)
('提供', 0.04)
('全国', 0.04)
('手段', 0.04)
('研发', 0.04)
('审判', 0.04)
('电子', 0.04)
('戒毒', 0.04)
('建成', 0.04)
('市域 社会 治理', 0.04)
('卷宗', 0.04)
('围绕', 0.04)
('信息系统', 0.04)
('监测', 0.04)
('数据 办案 平台', 0.04)
('发展', 0.03)
('案件', 0.03)
('中心', 0.03)
('体系', 0.03)
('社会 治理', 0.03)
('管理', 0.03)
('诉讼', 0.03)
('网上', 0.03)
('融合', 0.03)
('共享', 0.03)
('跨部门', 0.03)
('违规', 0.03)
('智慧 检务', 0.03)
('作用', 0.03)
('深化', 0.03)
('平安', 0.03)
('战略', 0.03)
('提出', 0.03)
('信息化 建设', 0.03)
('助力', 0.03)
('简称', 0.03)
('变革', 0.03)
('公司', 0.03)
('政法 领域', 0.03)
('云 平台', 0.03)
('数据 办案', 0.03)
('智能化', 0.02)
('平台', 0.02)
('系统', 0.02)
('治理', 0.02)
('智能', 0.02)
('监督', 0.02)
('基础', 0.02)
('相关', 0.02)
('机关', 0.02)
('群众', 0.02)
('流程', 0.02)
('协同', 0.02)
('行政', 0.02)
('制度', 0.02)
('检务', 0.02)
('在线', 0.02)
('资源', 0.02)
('之间', 0.02)
('关系', 0.02)
('特别', 0.02)
('全 流程', 0.02)
('我国', 0.02)
('制约', 0.02)
('执法监督', 0.02)
('矛盾', 0.02)
('上线', 0.02)
('微 法院', 0.02)
('一站式', 0.02)
('人民法院', 0.02)
('解决方案', 0.02)
('2020', 0.02)
('深度', 0.02)
('运行', 0.02)
('发挥', 0.02)
('技术创新', 0.02)
('区块 链', 0.02)
('检察机关', 0.02)
('防控', 0.02)
('人工', 0.02)
('决策', 0.02)
('中央', 0.02)
('阶段', 0.02)
('力量', 0.02)
('机构', 0.02)
('架构', 0.02)
('建设', 0.01)
('技术', 0.01)
('政法 智能化', 0.01)
('信息化', 0.01)
('研究', 0.01)
('政法 智能化 建设', 0.01)
('打造', 0.01)
('模式', 0.01)
('探索', 0.01)
('支撑', 0.01)
('分析', 0.01)
('统一', 0.01)
('视频', 0.01)
('人员', 0.01)
('依托', 0.01)
('升级', 0.01)
('政法系统', 0.01)
('精准', 0.01)
('规划', 0.01)
('执行', 0.01)
('时间', 0.01)
('会见', 0.01)
('2021', 0.01)
('包括', 0.01)
('警务', 0.01)
('调度', 0.01)
('持续', 0.01)
('现阶段', 0.01)
('智慧 监狱', 0.01)
('指导', 0.01)
('意见', 0.01)
('程序', 0.01)
('政法 建设', 0.01)
('公开', 0.01)
('规范', 0.01)
('产品', 0.01)
('评估', 0.01)
('2020 年', 0.01)
('节点', 0.01)
('带来', 0.01)
('覆盖', 0.01)
('主任', 0.01)
('场景', 0.01)
('人民检察院', 0.01)
('新 时代', 0.01)
('过程 中', 0.01)
('智慧', 0.0)
('社会', 0.0)
('领域', 0.0)
('创新', 0.0)
('业务', 0.0)
('概念', 0.0)
('完善', 0.0)
('方式', 0.0)
('政法 机关', 0.0)
('执法 司法', 0.0)
('监管', 0.0)
('全省', 0.0)
('公安', 0.0)
('标准', 0.0)
('强化', 0.0)
('市域', 0.0)
('政法 工作', 0.0)
('指挥', 0.0)
('线上', 0.0)
('网络', 0.0)
('基层', 0.0)
('执法 办案', 0.0)
('有限公司', 0.0)
('经验', 0.0)
('进一步', 0.0)
('发现', 0.0)
('自动', 0.0)
('智慧 法院', 0.0)
('综合', 0.0)
('保障', 0.0)
('庭审', 0.0)
('政法 实践', 0.0)
('市域 社会', 0.0)
('立案', 0.0)
('辅助', 0.0)
('信访', 0.0)
('各类', 0.0)
('工作人员', 0.0)
('活动', 0.0)
('预警', 0.0)
('理念', 0.0)
('实践 中', 0.0)
('整合', 0.0)
('流转', 0.0)
('加快', 0.0)
('效率', 0.0)
('一是', 0.0)
('二是', 0.0)
('纠纷', 0.0)
('操作', 0.0)
('内容', 0.0)
('目标', 0.0)
('赋能', 0.0)
('远程', 0.0)
('顽 瘴', 0.0)
('整治', 0.0)
('建立', 0.0)
('传统', 0.0)
('办公', 0.0)
('行业', 0.0)
('人类', 0.0)
('瘴 痼疾', 0.0)
('智慧 治理', 0.0)
('建设 中', 0.0)
('顽 瘴 痼疾', 0.0)
('一系列', 0.0)
九、?MDERank
相关研究ACL2022最新进展(MDERank),主要采用如下方法:
9.1 算法思想?
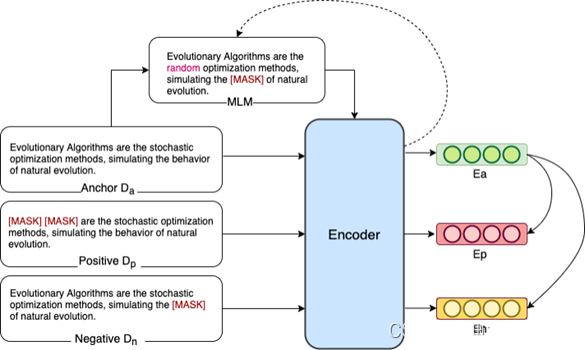
1.由原先的短语-文本层面的相似度计算通过掩码转换为文本-文本层面,从而解决了长度不匹配的问题。
2.避免了使用短语的表征,而是使用掩码后的文本替代候选词,由此可以获得充分利用了上下文信息的文本表征。
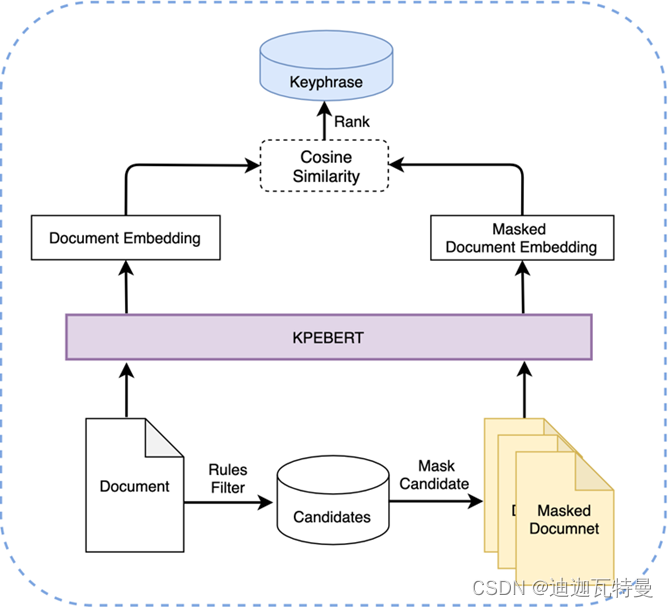
1. 绝对采样:利用现有的无监督关键词提取方法,对每篇文章抽取得到关键词集合,将这些“关键词”作为正例对原始文章进行掩码。然后在剩下候选词(“非关键词”)中随机抽取作为负例。
2. 相对采样:利用现有的无监督关键词提取方法,对每篇文章抽取得到 d 关键词集合,在关键词集合中,随机抽取两个“关键词”,其中排名靠前的一个作为正例,另一个则为负例,从而构建训练数据。
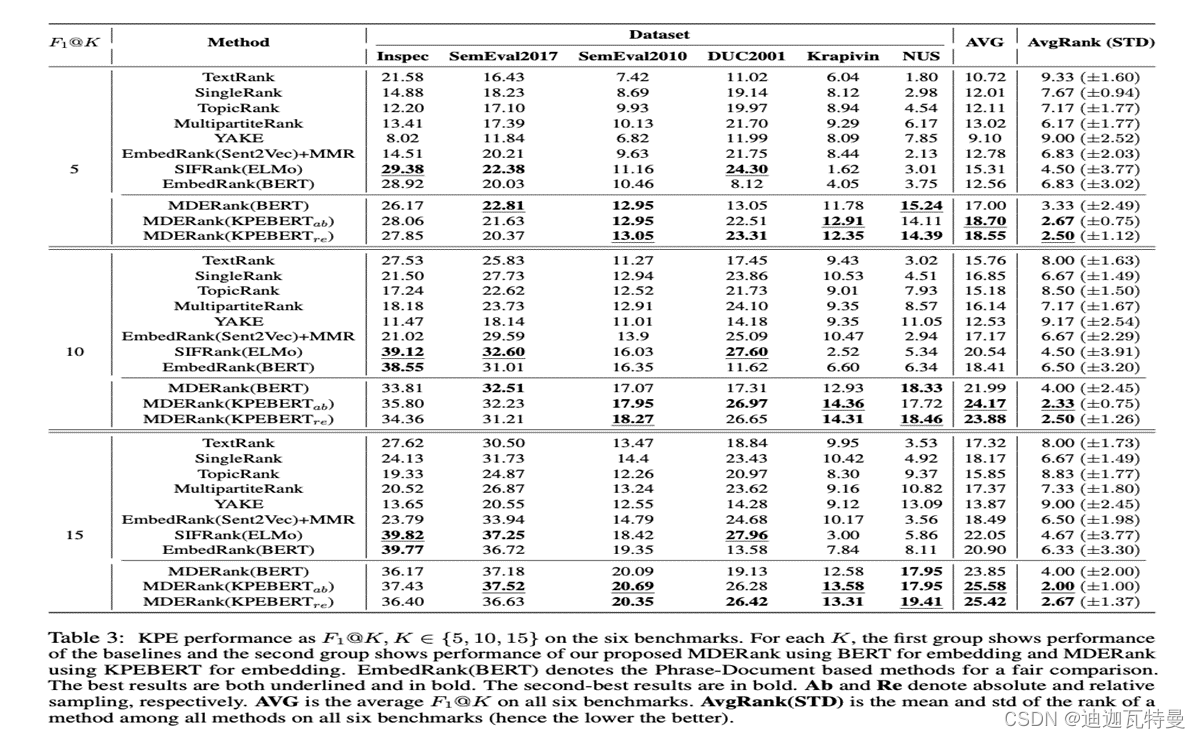
9.2? 实验结果
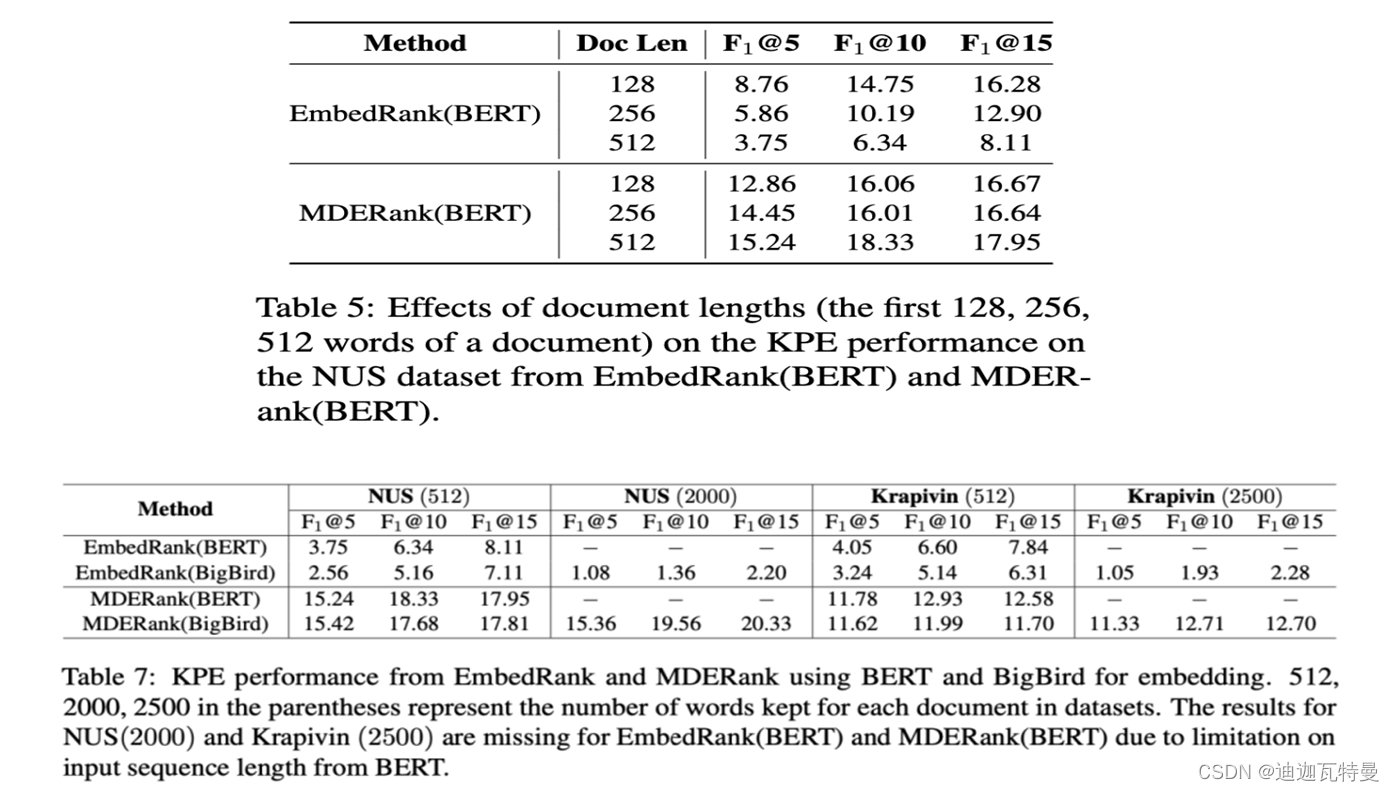
十、小结
从中我们可以看到,TF-IDF基于统计易于实现,但是缺点就是没有考虑词与词,词与文档之间的关系。
TextRank考虑了词与词之间的关系(提取思想就是从窗口之间的词汇关系而来),但是缺点是它针对的是单个文本,而不是整个语料,在词汇量比较少的文本中,也就是短文中,效果不会太好。
以上两种方式都没有考虑到词和整个文档的相关性或者一致性。
因此,如果认为关键词与文档在主题分布或者语义分布是一致或者相似时,我们就可以进一步的展开尝试。
例如,LDA主题模型认为文档是有很多主题组成的,文档既是主题的分布也是关键词的分布,可以计算词的主题分布与文档主题分布的相似性,抽取关键词。
通过Bert编码,可以分别得到文档和词语的embedding表示,通过比对两者之间的相似度,然后排序,可以得到关键词集合。
这两种都是很直接的想法,并且可以快速平移至摘要抽取上,如同类思想的BertSum工作。
基于统计学的关键词提取算法,依赖于切分词,然而普适的切分词,在缺乏领域知识情况下,很容易将我们需要的信息切分开。?
基于深度学习的keybert只能接受限定长度的文本,例如512个字,这个使得我们在处理长文本时,需要进一步加入摘要提取等预处理措施,这无疑会带来精度损失。而且在没有切分词的情况下,生成的结果偏向于长短语,常常达不到预期的效果。?
十一、关键词提取的评价指标?
关键词的评价也是一个关键问题,一般来说,主要有以下几种方式:
搜索推荐评价指标Precision@k、Recall@k、F1@k假设对于一个查询,真实相关的结果是{A,C,E, Q},搜索模型得到5个结果{A, B, C, D, E},则其中只有A,C,E是相关的,标记为{1, 0, 1, 0, 1},1表示相关,0表示不相关。?
1、F1@1:针对top-1的结果计算F1 score
在具体计算上,得到输出的关键词序列后,获取其中的第一个关键词和GT中的第一个关键词作对比,从而计算出f1 score;?
2、F1@3:针对top-3的结果计算F1 score
在具体计算上,得到关键词序列中的前三关键词与GT中的关键词做对比(不关心这三个关键词的相互顺序)
3、MAP(mean average precision)平均精度均值:
在具体计算上,先求出每个候选词在当前文本的精确率(TP/(TP+FP)),然后将这一段文本的所有候选词精确率求和并除以候选词个数得到该文本的平均精确率(AP),最后将所有文本的平均精确率相加后除以文本数,就得到平均精度均值(MAP)。
十二、下一步计划
import pandas as pd
count = {}
filename = "./政法智能化2021至今.xlsx"
inputs = pd.read_excel(filename)
for text in inputs['关键词’]:
for char in str(text).split():
if char in count:
count[char] +=1
else:
count[char] = 1
{'政法智能化': 22, '习近平新时代中国特色社会主义思想': 2, '重庆市永川区': 1, '智能化建设': 8, '枫桥经验': 1, '重庆实践': 1, '共建共享': 1, '创新案例': 3, '社会治理现代化': 2, '政法队伍': 1, '习近平法治思想': 1, '中央政法委': 1, '教育整顿': 1, '制约监督': 1, '内部监督': 1, '政法系统': 1, '顽瘴痼疾整治': 1, '智慧治理': 4, '大数据': 1, '执法监督': 1, '司法行为': 1, '规范执法': 1, '存在的风险': 1, '政法工作': 4, '质量效率': 1, '人工智能': 2, '革命浪潮': 1, '结构性变革': 1, '公信力': 1, '运行模式': 1, '政法智能化建设': 1, '智慧政法;': 1, '公安': 1, '诉讼法与司法制度': 2, '新技术运用': 1, '网络空间': 1, '新一代信息技术': 1, '外部环境': 1, '不稳定因素': 1, '新的挑战': 1, '执法办案': 4, '排头兵': 1, '公益诉讼': 1, '科技强警': 1, '技术革新奖': 1, '区块链': 1, '目标导向': 1, '管理系统': 1, '技术创新中心': 1, '数据治理': 1, '成果展': 2, '数据采集': 1, '创新方案': 1, '保卫部门': 1, '保卫工作': 1, '信息化建设': 1, '稳步推进': 1, '转型升级': 1, '提质增效': 1, '文字产业': 1, '文字发展': 1, '网络时代': 1, '指挥调度平台': 1, '融合通信': 1, '图上指挥': 1, '调度方式': 1, '政法委': 3, '控辩协商': 1, '律师会见': 1, '庭审笔录': 1, '管控系统': 1, '预付式消费': 1, '远程视频技术': 1, '拉杆箱': 1, '参观者': 1, '高级人民法院': 1, '云平台': 1, '公安监所': 1, '市委政法委': 1, '矛盾纠纷': 2, '多元化解': 2, '信访局': 1, '大庆市': 1, '司法': 1, '智能化': 1, '监狱系统': 1, '政法机关': 1, '电子卷宗': 1, '司法厅': 2, '刑事案件': 1, '司法行政机关': 1, '大动脉': 1, '监狱管理局': 1, '社区矫正': 1, '检察长': 1, '涉法涉诉信访案件': 1, '个案监督': 1, '司法行政': 1, '人民检察院': 1, '智慧城市': 1, '经验分享': 1, '一站式': 1, '解纷机制': 1, '民事审判庭': 1, '移动电子': 1, '法院诉讼': 1, '纠纷解决': 1, '调解优先': 1, '在线咨询': 1}
结合知网、维普网等数据集的关键词提取可以作为知识发现的一种途径,由于当前关键词提取的各类算法各有优劣,基于统计学的算法依赖切分词效果且缺失上下文语义信息,基于预训练模型的算法偏向于获取长度较长的短语,且在英文数据集效果好于中文数据集,可以尝试结合各类算法结果互补,在缺乏专家知识情况下得到较优的新词发现结果,然后获得细粒度的切分词效果,然后基于词信息熵约束构建整个概念权重网络。?
参考内容:
1.?NLP关键词提取必备:从TFIDF到KeyBert范式原理优缺点与开源实现

