���Ļ�����Ϣ
�ڿ�: ���Ŵ�ѧѧ��(��Ȼ��ѧ��) ���������
Ӱ������: 0.77
ժҪ
Step1: ͨ����������������ʽ(��:�˹���д��ͼ��ϳɡ�ͼ��ü�)�����80�����ֱ���,��110610������ǩ���ַ�����;
Step2: ��Faster-RCNN�㷨Ӧ�õ�ˮ��ż�����ʶ����,������������Բ�ͬ��ϵ����ݼ���Ϊ�������ʵ��,��ȫ��80��Ŀ������ϻ����91.95%��ƽ��ʶ���ʡ�
����
�����˺ܶ�Ŀǰ��ˮ��ʶ��,������Ҫ��¼�����¼����Լ����ܻ��õ�������:
| ���� |
|---|
| 1. ����谵������һ�ָĽ���ͼ����ǿ��ͼ �� ʶ �� �� ��,������Ӧ����ˮ������ͼ����,�����Ҷ�ת������ֵ�˲�ȥ�롢ֱ��ͼ���⻯�ȴ���,֮����ͨ��Sobel���������ֱ�Ե,������ȡ��ˮ�����ͼ����ͼ���е�ˮ������ |
| 2. �̏������һ������������ṹ, ��5���ˮ���ַ��������Ͻ����˷���ʵ��,�õ���93.3%��ʶ��ȷ��,���о�û���漰ҳ���ˮ������ʶ��,��Ҫ�ǵ���ˮ�����ֵķ����о�. |
| 3. �Ժ�˧�Ƚ�������˹��������Կ�������������,��ˮ��ż�ͼ��������������ȴ���;��ʹ�û�����Ϣ�ص��ල�ܶȾ����㷨,�о�ˮ��ż�ͼ�����ֵ��Զ���ע;��6230��ˮ���ַ������Ͻ���ʵ��.��������:������˹�������ṹ�����ɶԿ������ˮ�����ֵ�ͼ���������и��ߵķֱ� ��,������������������,���Զ���ע��������һЩ����,���Զ���ע��ȷ�ʲ���,Ӱ����ˮ�����ֵ�ʶ��ȷ�� |
| 4. ������ �� ����YOLOģ�Ͷ�ˮ�����ֽ���ʶ����,�� �� ��ʶ�����ȶ���98%����,������õ�����������Դ��ˮ�����ֺͺ��ֻ����鼮��,����ˮ�����ԭ��ͼ���Ӱӡ��ͼ������,��δ���������ʹ�õ����ݼ�����ģ. |
1. ���ݼ�
��ԭʼ���ݼ���Դ�ڡ����Ǽ����ȹż�Ӱӡ������
��Ҫ������������:
���Ķ�һЩ�����Ƚ��ٵ���Ƨ��,Ϊ���ģ�͵�³���Ժ���չ����,ͨ���˹���д��ͼ��ϳɡ�ͼ��ü� �ȷ�ʽ��������������
(1)�˹���ʽ
����������������300����ˮ��������������˹���д,����8���ʼDz�ͬ��־Ը�߽�����д����,�õ�37������ˮ�����ֹ�12021���ַ�������
(2)ͼ��ϳ�
��������������500��ˮ���������ͨ��ͼ��ϳɷ�ʽ����������������������:
Step1: ����ȷ��������ͨ������任���ᷢ������,��:�����е�һ��ʮ��
Step2: ���ַ���Ƭ���ж�ֵ������ת����ת�����������ȷ�ʽ;
Step3: ���,�Դ�������ͼ��������,�����ϳ�һ��������ͼƬ��
ͨ�����Ϸ�ʽ�����ͼƬ1600��,����37363���ַ�������
Ŀ��: ����������,�Ұ������ֳ�����ʹ���ݳ��ֶ�����,�Ӷ���ǿģ�͵ķ�������,��ֹ����ϡ�
(3)ͼ��ü�
��39���˹���д������ͼ���1734��ԭʼ����ͼ������ϡ��¡����Ҽ����IJü�,���ջ��ˮ������ͼ��9053��,����73247���ַ�����
2. Ŀ�����㷨��ѡȡ
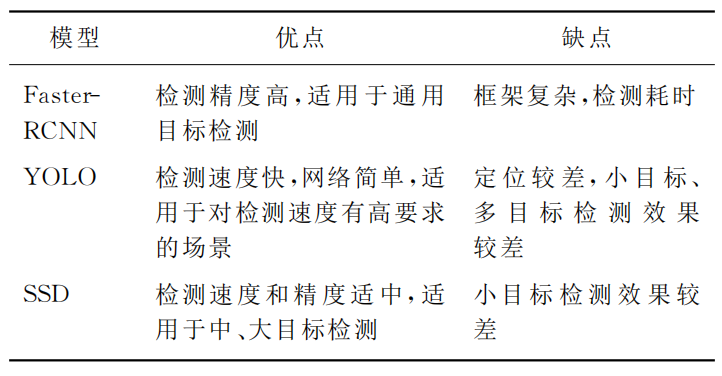
(1)Ŀ�����㷨���
��Ҫ��Ϊ"һ������㷨"������������㷨��
| һ����ⷨ | ������ⷨ |
|---|---|
| �ڶ������ͼ��ֱ�ӳ������ع�,һ ����������������ʺ�λ������ֵ�����,����ٶȿ�,���͵���:SSD��YOLO | Step1: ����������ͼ�ϳ��������ܼ��ĺ�ѡ����; Step2: �ٶԺ�ѡ������з���ͻع顣 ��������: RCNN��Fast-RCNN��Faster-RCNN |
(2)��������㷨��ϸ����
a. RCNN
Step1: ����ѡ���������㷨��ÿ��������������ȡ1000-2000����ѡ����;
Step2: ��ʹ�þ���������������������ȡÿһ����ѡ���������;
Step3: �����֧��������������Щ��ѡ������������������ۺϷ���.
�ŵ�: ��ȷ�����в����ı���;
ȱ��: �÷�������������,���Դ�������Դ������ʱ��Ϊ���ۻ�ȡȷ�ʵ�����
b. Fast-RCNN
Fast-RCNN��RCNN�������汾��Fast_RCNN�ھ�������������һ��������������ROI�ػ���,ʹ����������ijߴ�����������(��Ϊ�ػ���γ̸ı�ͼƬ�ijߴ�),���Ҷ�ÿһ��ͼ��ֻ����һ��������ȡ,������Ч�ʡ�
����,Fast-RCNN����Softmax����֧�����������ж�����ķ���,ʹ�ü��Ч�ʵõ�������
����,���㷨��Ȼ����ѡȡ��ѡ�����ʱ������⡣
c. Faster-RCNN
Faster-RCNN�ĵ���Ҫ�ص��Ǹı��˺�ѡ�������ȡ����,��ʹ���˺�ѡ��������RPN,ʹ�þ���������ֱ�Ӳ�����ѡ����,��������֮ǰʹ�õ�ѡ��������������
Faster-RCNN����ѵ���ķ�ʽ,�����ڴ������Ŀ�����ʱ��ͬʱ,��Ч���Ŀ�����ȷ��.
(3)һ������㷨��ϸ����
a. YOLO
YOLO��ѵ���ͼ�����һ�����������н���,�����ͼ����辭��һ��ͼ��Ԥ��,���ܵõ���Ԥ��ͼ������������Ŀ������λ�á���Ӧ���Ÿ���,�����ٶȿ����нϸߵ�ȷ��.
����,YOLO�㷨ֱ�ӽ�ͼ��ָ����������,��Ҫ��ǰ�趨��ѡ�����ҵ����Ŀ��ͬʱ����һ������ʱ,ֻ��ȡ���Ŷ���ߵ�һ�ࡣ
���,YOLO�㷨��СĿ���Ŀ���ܼ��ļ�⾫�Ƚϲ
b. SSD
���㷨�����Faster-RCNN��YOLO�IJ���˼��,��ͼ��ͬλ�õĶ��ֳ߶ȵ�����IJ�ͬ�������лع�,����Щ�������зֲ���ȡ�ͷ���,�����ν��б߿�ij߶Ȼع����������ȼ��������������ɶ��ֲ�ͬ�߶�����Ŀ���ѵ�����������
SSD�㷨�ڲ�Ӱ���ص�ͬʱ,�����Ŀ����ȷ�ʡ�
�����㷨��Ĭ�Ͽ���״������ߴ綼��Ԥ��ġ�
��˶�СĿ��ļ��Ч����Ȼ�������롣
3. ʵ��
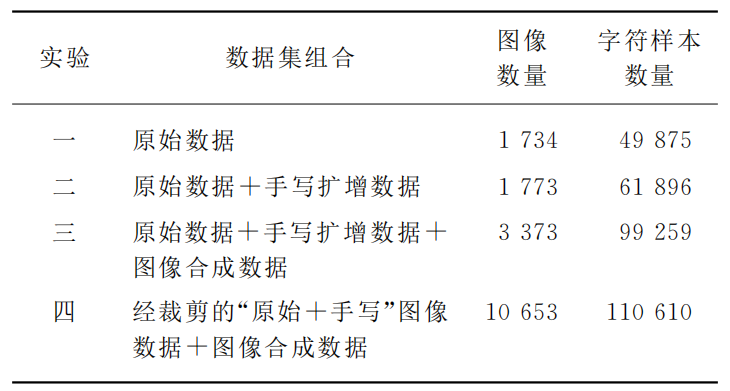
(1)ʵ�����
��Ϊ������3�ֲ�ͬ����������ʽ,�ʲ����˲�ͬ��ϵ����ݼ�����������ʵ�顣��������:
(2)����ָ��
ʵ���������۲��ø�������������mAP���бȽ�.mAP��������ģ�͵ĺû�,��Ŀ�����е���Ҫ����ָ��,�乫ʽ����:
P
m
A
=
��
i
=
1
N
P
i
A
N
?
100
%
P_{mA} = { \sum_{i=1}^N P_i^A \over N } * 100\%
PmA?=N��i=1N?PiA???100%
����,
N
N
NΪ�����Ŀ,
P
i
A
P_i^A
PiA? Ϊ��i��ľ�ȷ��,���������:
P
i
A
=
P
(
i
)
��
r
(
i
)
P_i^A = P(i) \Delta r(i)
PiA?=P(i)��r(i)
����,
P
(
i
)
P(i)
P(i) ��ʾ��i���ȷ��,
��
r
(
i
)
\Delta r(i)
��r(i)��ʾ��i����ٻ��ʡ�
(3)ʵ�����
- ʵ�����Faster-RCNNģ�ͽ���ѵ���Ͳ���;
- ʹ��VGG16��Ϊ��������ȡͼ�������Ļ�������;
- ѵ����: ���Լ� = 8: 2
- ��ʼѧϰ�� lr = 0.001
(4)ʵ����


