����Ŀ¼
����:ѵ������ ѵ���ĺܺ���,���Ҳ����,Ϊʲô�� ���Լ�������������?
���㷨��ij�����ݼ����г����������,���ܾͳ����� ���������
4.2.1 ʲô�ǹ������Ƿ���
- Ƿ���
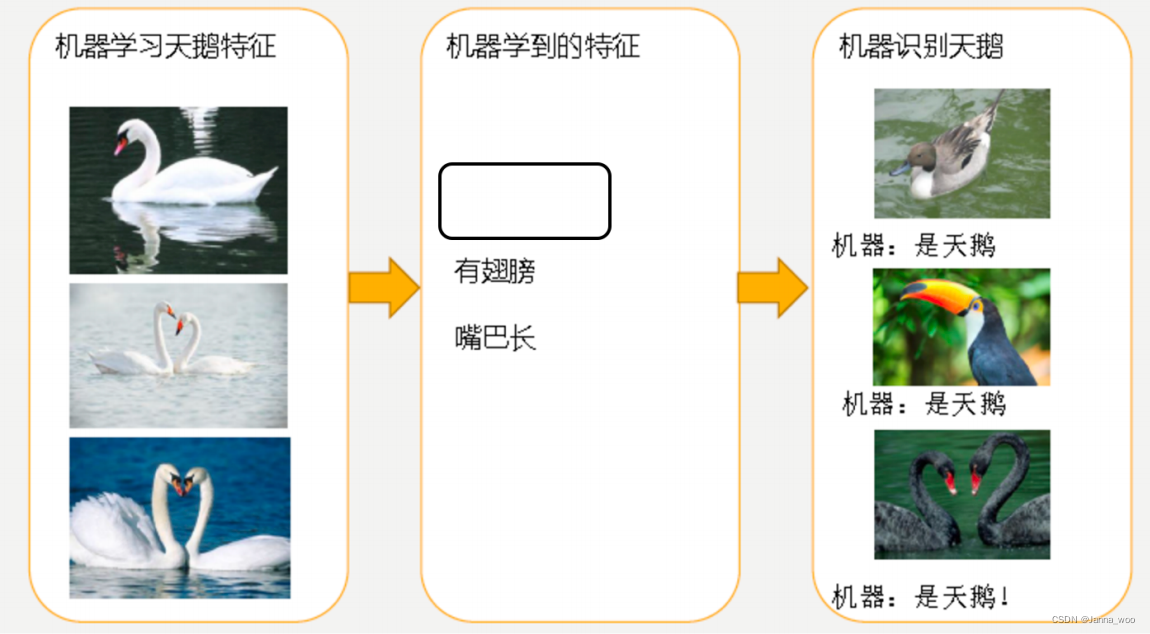
- �����
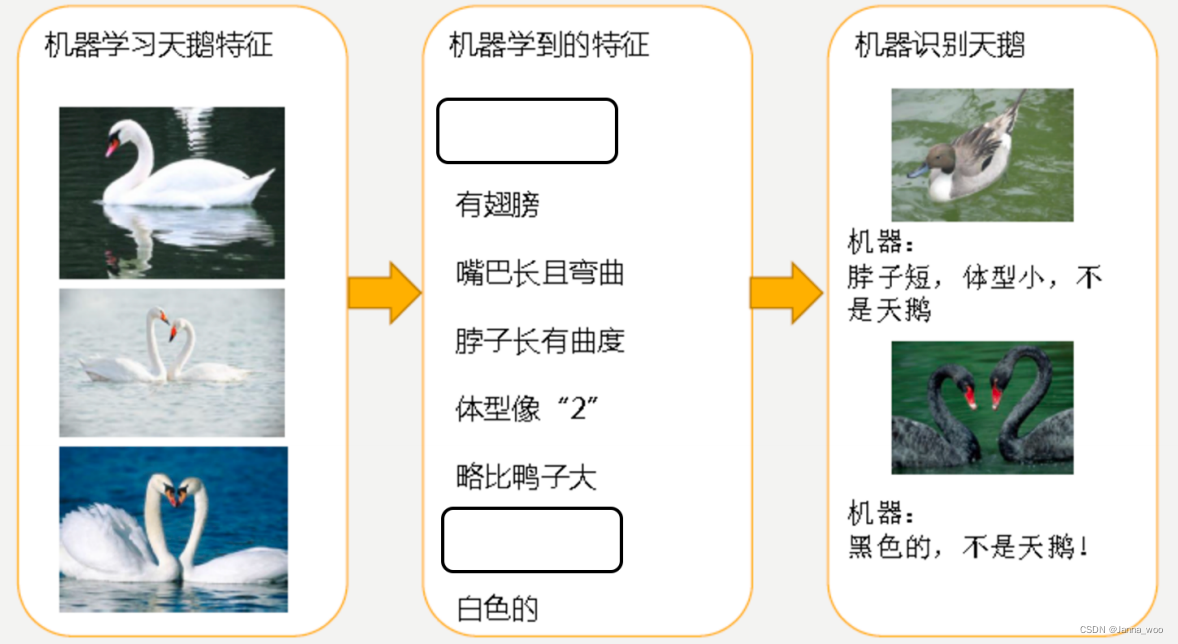
- ����
o ��һ�����:��Ϊ����ѧϰ�����������̫����,�������ֱ�̫�ֲ�,����ȷʶ�����졣
o �ڶ������:�����Ѿ������������������������ˡ�Ȼ��,�ܲ������е����ͼƬȫ�ǰ�����,���ǻ�������ѧϰ��,����Ϊ������ë���ǰ�,�Ժ���ë�Ǻڵ����ͻ���Ϊ�Dz�����졣
1. ����
- �����:һ��������ѵ���������ܹ���ñ�����������õ����, �����ڲ������ݼ���ȴ���ܺܺõ��������,��ʱ��Ϊ�����������˹���ϵ�����(ģ���ڸ���)
- Ƿ���:һ��������ѵ�������ϲ��ܻ�ø��õ����,�����ڲ������ݼ���Ҳ���ܺܺõ��������,��ʱ��Ϊ������������Ƿ��ϵ�����(ģ���ڼ�)
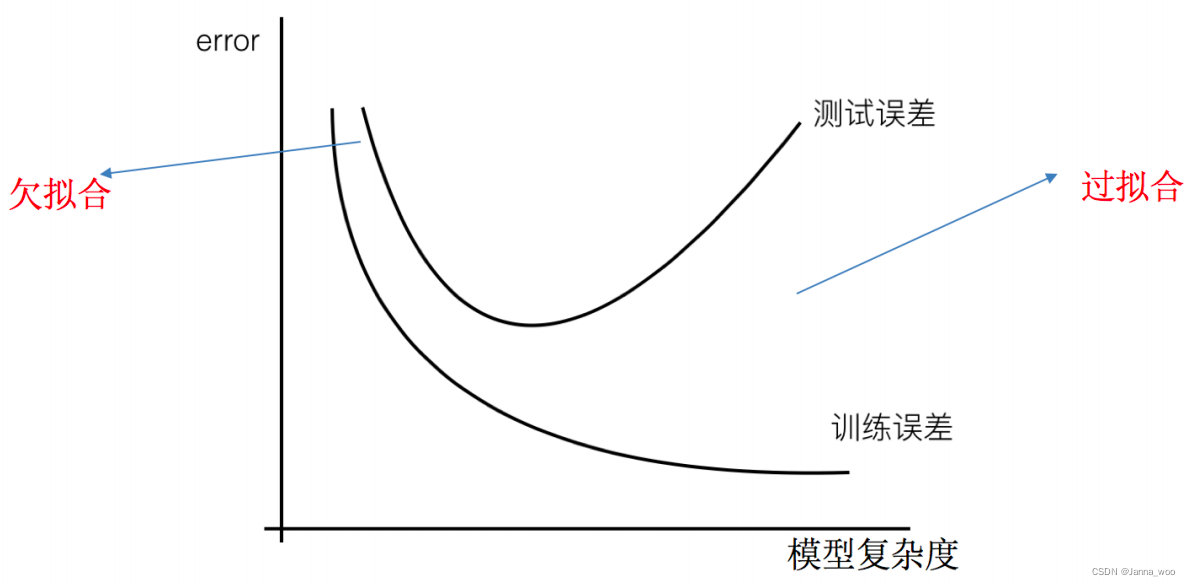
��ô��ʲôԭ����ģ����?���Իع����ѵ��ѧϰ��ʱ����ģ�ͻ��ø���,����Ͷ�Ӧǰ����˵�����Իع�����ֹ�ϵ,�����Թ�ϵ������,Ҳ���Ǵ��ںܶ����õ�����������ʵ�е�����������Ŀ��ֵ�Ĺ�ϵ�����Ǽ����Թ�ϵ��
2. ԭ���Լ�����취
- Ƿ���ԭ���Լ�����취
o ԭ��:ѧϰ�����ݵ���������
o ����취:�������ݵ��������� - �����ԭ���Լ�����취
o ԭ��:ԭʼ��������,����һЩ��������, ģ���ڸ�������Ϊģ�ͳ���ȥ��˸����������ݵ�
o ����취:
����
��������Իع�,����ѡ�����������Ƕ�����������ѧϰ�㷨������㷨��˵Ҳ���������������,����һЩ�㷨��������֮��(��������������),���Ǹ����Ҳ��ȥ�Լ�������ѡ��,����֮ǰ˵��ɾ�����ϲ�һЩ����
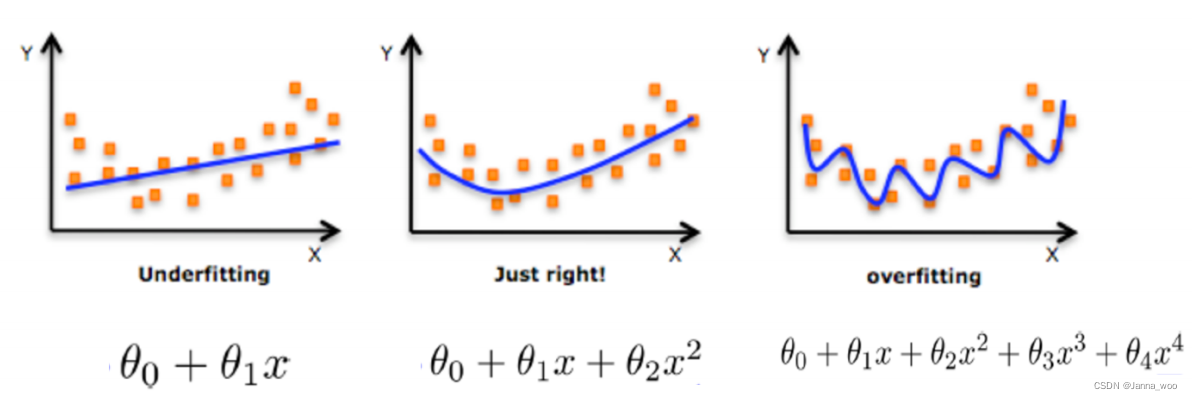
���?

��ѧϰ��ʱ��,�����ṩ��������ЩӰ��ģ���ӶȻ���������������ݵ��쳣�϶�,�����㷨��
ѧϰ��ʱ�����������������Ӱ��(����ɾ��ij��������Ӱ��),���������
ע:����ʱ��,�㷨����֪��ij������Ӱ��,����ȥ���������ó��Ż��Ľ��
4.2.2 ����
1. �������
L2����(������)
- ����:����ʹ������һЩW(Ȩ��ϵ��)�Ķ���С,���ӽ���0,����ij��������Ӱ��
- �ŵ�:ԽС�IJ���˵��ģ��Խ��,Խ��ģ����Խ�����ײ������������
- Ridge�ع�C��ع�
- ����L2�������ʧ����:
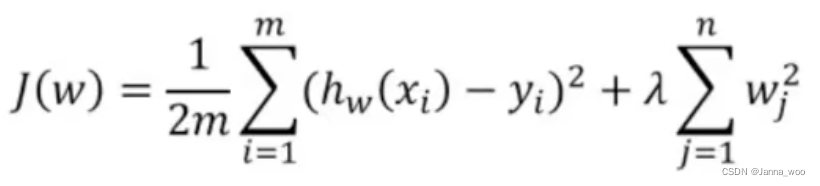
ע:��ʧ���� + �ͷ���
m������,n������
L1����
- ����:����ʹ������һЩW��ֱֵ��Ϊ0,ɾ�����������Ӱ��
- LASSO�ع�
2. ��չ-ԭ��(�˽�)
���Իع����ʧ��������С���˷�,�ȼ��ڵ�Ԥ��ֵ����ʵֵ�����������̬�ֲ�ʱ�ļ�����Ȼ����;
��ع����ʧ����,����С���˷�+L2����,�ȼ��ڵ�Ԥ��ֵ����ʵֵ�����������̬�ֲ�,��Ȩ��ֵҲ������̬�ֲ�(����ֲ�)ʱ�����������;
LASSO����ʧ����,����С���˷�+L1����,�ȼ��ڵȼ��ڵ�Ԥ��ֵ����ʵֵ�����������̬�ֲ�,����Ȩ��ֵ����������˹�ֲ�(����ֲ�)ʱ�����������

