ЖдгкБОТлЮФЮвАбЫљгаФкШнжиаТХХАцСЫ,МгЩЯздМКИќжБАзЕФЛАРДжБЙлНщЩмЁЃ
ШчЙћЖдгкЮФеТРяЕФУћДЪНтЪЭгавЩЛѓ,ПЩвдВЮПМЮветЦЊЮФеТ
вЛЁЂЙЄзї:
ЪзЯШ,ЮвУЧЪЙгУжсЯђзЂвтФЃПщбЇЯАЪЕЬхЖджЎМфЕФЯрЛЅвРРЕЙиЯЕ,ЬсИпСЫСНЬјЙиЯЕЕФадФмЁЃЦфДЮ,ЮвУЧЬсГіСЫвЛИіздЪЪгІЕФОжВПЫ№ЪЇРДНтОіDocREЕФРрВЛЦНКтЮЪЬтЁЃзюКѓ,ЮвУЧРћгУжЊЪЖеєСѓРДПЫЗўШЫЙЄБъзЂЪ§ОнгыдЖГЬМрЖНЪ§ОнжЎМфЕФВювьЁЃ
ЪзЯШ,ЮЊСЫИФНјСНЬјЙиЯЕЕФЭЦРэ,ЮвУЧЬсГіЪЙгУжсЯђзЂвтФЃПщзїЮЊЬиеїЬсШЁЦїЁЃДЫФЃПщЪЙЮвУЧФмЙЛЙизЂСНЬјТпМТЗОЖФкЕФдЊЫи,ВЂВЖЛёЙиЯЕШ§дЊзщжЎМфЕФЯрЛЅвРРЕЙиЯЕЁЃЦфДЮ,ЮвУЧЬсГіздЪЪгІОжВПЫ№ЪЇКЏЪ§РДНтОіБъЧЉЗжХфЕФВЛЦНКтЮЪЬтЁЃЬсГіЕФЫ№ЪЇКЏЪ§ЙФРјГЄЮВРрЖдећЬхЫ№ЪЇЙБЯзИќЖрЁЃзюКѓ,ЮвУЧРћгУжЊЪЖеєСѓРДПЫЗўДјзЂЪЭЪ§ОнгыдЖМрЖНЪ§ОнжЎМфЕФВювьЁЃ
ЖўЁЂФПЧАЕФЬєеН:
DocREШЮЮёдквдЯТМИИіЗНУцБШОфзгМЖШЮЮёИќОпЬєеНад:(1) DocREЕФИДдгЖШЫцЪЕЬхЪ§СПЕФдіМгГЪЖўДЮЧњЯпдіГЄЁЃШчЙћвЛИіЮФЕЕАќКЌnИіЪЕЬх,дђБиаыЖдn(n - 1)ИіЪЕЬхЖдНјааЗжРрОіВп,ЧвДѓЖрЪ§ЪЕЬхЖдВЛАќКЌШЮКЮЙиЯЕЁЃ(2)Г§СЫе§Р§КЭИКР§ЕФВЛЦНКтЭт,е§Р§ЖдЙиЯЕРраЭЕФЗжВМвВЗЧГЃВЛЦНКтЁЃвдDocRED (Y ao et al., 2019)Ъ§ОнМЏЮЊР§,ЙВга96жжЙиЯЕРраЭ,ЧА10жжЙиЯЕеМЫљгаЙиЯЕБъЧЉЕФ59.4%ЁЃетжжВЛЦНКтЯджјдіМгСЫЮФЕЕМЖREШЮЮёЕФФбЖШЁЃ
Ш§ЁЂDocREВЛзу:
ЯжгаDocREЗНЗЈгаШ§ИіЯожЦ:ЪзЯШ,ЯжгаЗНЗЈжївЊЙизЂЪЕЬхЖдЕФОфЗЈЬиеї,ЖјКіТдСЫЪЕЬхЖджЎМфЕФНЛЛЅзїгУЁЃZhang et al.(2021)КЭLi et al.(2021)ЪЙгУCNNНсЙЙЖдЪЕЬхЖджЎМфЕФНЛЛЅНјааБрТы,ЕЋCNNНсЙЙВЛФмВЖЛёСНЬјЭЦРэТЗОЖФкЕФЫљгадЊЫиЁЃЦфДЮ,жЎЧАУЛгаУїШЗДІРэDocREЕФРрВЛЦНКтЮЪЬтЕФЙЄзїЁЃЯжгазїЦЗ(ZhouЕШШЫ,2021;ZhangЕШ,2021;Zeng et al., 2020)жЛЙизЂуажЕбЇЯАРДЦНКте§Р§КЭИКР§,ЕЋе§Р§ФкВПЕФНзМЖЪЇКтЮЪЬтВЂУЛгаЕУЕННтОіЁЃзюКѓ,ЙигкНЋдЖГЬМрЖНЪ§ОнгІгУгкDocREШЮЮёЕФбаОПКмЩйЁЃXuЕШШЫ(2021)вбОБэУї,дЖГЬМрЖНЪ§ОнФмЙЛЬсИпЮФЕЕМЖЙиЯЕЬсШЁЕФадФмЁЃШЛЖј,ЫќжЛЪЧЕЅДПЕиЪЙгУдЖГЬМрЖНЪ§ОнЖде§дђФЃаЭНјаадЄбЕСЗЁЃ
ЫФЁЂФЃаЭ:
ЙиЯЕГщШЁЮЪЬтБОжЪЩЯЪЧвЛИіЖрБъЧЉЗжРрЮЪЬтЁЃЮвУЧЕФАыМрЖНбЇЯАПђМмжївЊАќРЈШ§ИіВПЗж:
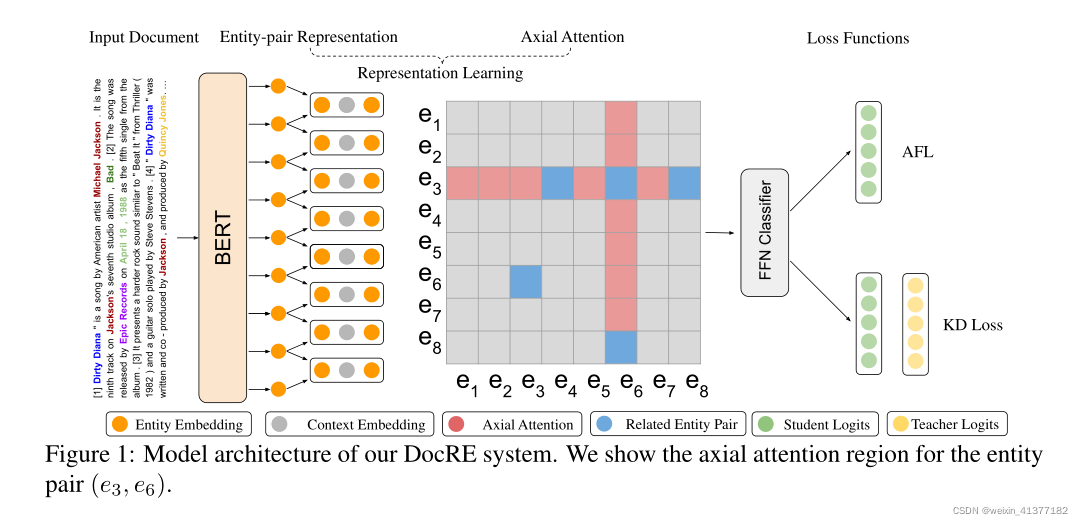
(1)БэЪОбЇЯА:
ЖдгкБэЪОбЇЯА,ЮвУЧЪзЯШЭЈЙ§вЛИідЄЯШбЕСЗЕФгябдФЃаЭЬсШЁУПИіЪЕЬхЖдЕФЩЯЯТЮФБэЪОЁЃЭЈЙ§жсЯђзЂвтФЃПщЖдЪЕЬхЖджЎМфЕФЯрЛЅвРРЕаХЯЂНјааБрТы,НјвЛВНдіЧПЪЕЬхЖдЕФБэЪОЁЃ
ЂйЪЕЬхБэЪО
ЩЯЯТЮФЧЖШы:
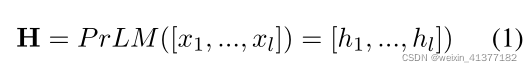
ЪЕЬхeiЕФОлКЯЬиеї:
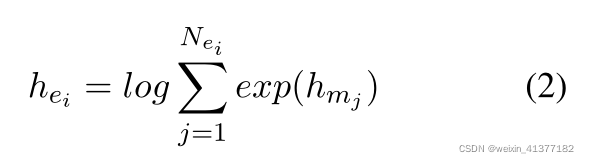
ЂкЮФБОдіЧПЪЕЬхБэЪО
ЦНОљГиЛЏ:ОлКЯзЂвтСІЪфГі
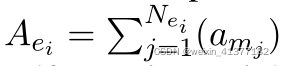
ЩЯЯТЮФВщбЏЕФМЦЫуЗНЗЈ:
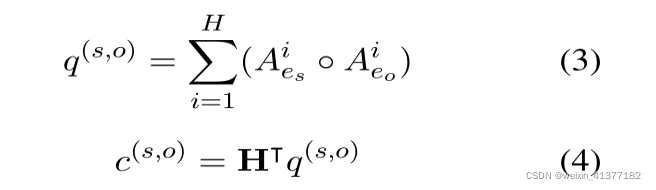
ЪЕЬхЖджаsЕФЧщОАдіЧП:
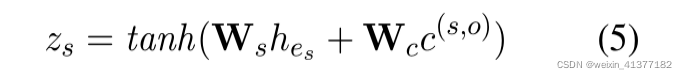
ЪЕЬхЖджаЛёЕУoЭЌРэ
ЂлЪЕЬхЖдБэЪО
ЪЕЬхЖддкУПИіЮЌЖШЩЯЕФжЕ:
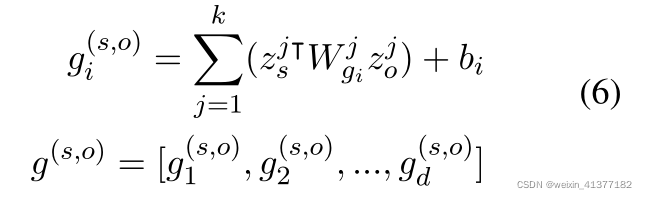
ОпгаnИіЪЕЬхЕФИјЖЈЮФЕЕD,ЮвУЧашвЊЖдn(n - 1)ИіЪЕЬхЖдХХСаНјааЗжРрЁЃ
ЂмжсЯђзЂвтдіЧПЪЕЬхЖдБэеї
ЬсГіЪЙгУСНЬјзЂвтСІ(two-hop attention)ЖдЪЕЬхЖдБэЪОЕФжсЯђЯрСкаХЯЂНјааБрТыЁЃИјЖЈвЛИіn ЁС nЕФЪЕЬхБэ,ЖдгкЪЕЬхЖд(es, eo),ЙизЂЫќЕФжсЯђдЊЫиЖдгІгкЙизЂ(es, ei)Лђ(ei, eo)дЊЫиЁЃвВОЭЪЧЫЕ,ШчЙћПЩвдНЋСНЬјЙиЯЕ(es,eo)ЗжНтЮЊТЗОЖ(es,ei)КЭ(ei,eo),ФЧУДгУгкЗжРр(es,eo)ЕФаХЯЂСПзюДѓЕФСкОгЪЧгыИУЪЕЬхЖдЙВЯэesЛђeoЕФЕЅЬјКђбЁЖдЯѓЁЃ
бижсзіВаВюСДНг:
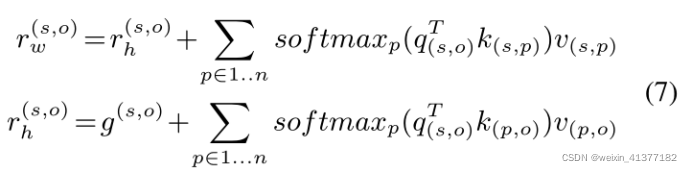
жИЖЈq(i,j) = WQg(i,j),Мќk(i,j) = WKg(i,j),жЕv(i,j) = WV g(i,j),ЫќУЧЖМЪЧЪЕЬхЖдБэЪОgдкЮЛжУ(i,j)ЕФЯпадЭЖгАЁЃ
(2)здЪЪгІОжВПЫ№ЪЇ:
ШЛКѓЮвУЧЪЙгУЧАРЁЩёОЭјТч(FFN)ЗжРрЦїРДЛёШЁlogitВЂМЦЫуЫќУЧЕФЫ№ ЪЇЁЃЮвУЧЪЙгУЮвУЧЬсГіЕФздЪЪгІОжВПЫ№ЪЇ,вдИќКУЕибЇЯАДгГЄЮВРрЁЃ
дЄВтЙиЯЕЯпадВу:
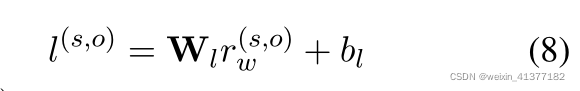
l(s,o)ЁЪRcБэЪОЫљгаЙиЯЕЕФЪфГіlogitЁЃ
здЪЪгІуажЕЫ№ЪЇ(ATL):
ATLУЛгаЖдЫљгаЪОР§ЪЙгУШЋОжИХТЪуажЕ,ЖјЪЧв§ШыСЫвЛИіЬиЪтРрT H зїЮЊУПИіЪОР§ЕФздЪЪгІуажЕЁЃЖдгкУПИіЪЕЬхЖд(esЁЂeo),Цфlogit ДѓгкTHРрlogitЕФРрНЋБЛдЄВтЮЊе§Рр,ЦфгрЕФНЋБЛдЄВтЮЊИКРрЁЃ
здЪЪгІОжВПЫ№ЪЇ(AFL):дкбЕСЗЙ§ГЬжа,НЋБъЧЉПеМфЛЎЗжЮЊСНИізгМЏ: е§РрзгМЏPTКЭИКРрзгМЏNTЁЃ
a)е§УцРрБ№:
е§РрзгМЏPTАќКЌЪЕЬхЖд(es, eo)жаДцдкЕФЙиЯЕ,ШчЙћЪЕЬхЖд(es, eo)жаВЛДцдкЙиЯЕ,дђPTЮЊПе(PT =?)ЁЃ
е§РрИХТЪМЦЫу:
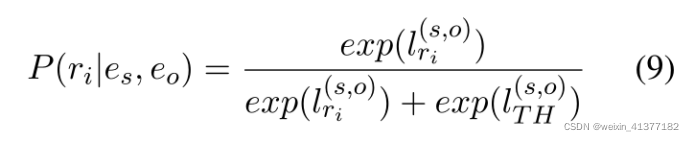
b)ИКУцРрБ№:
ИКзгМЏNTАќКЌВЛЪєгке§РрЕФЙиЯЕРр,NT = R \ PTЁЃ
ИКРрlogitМЦЫуTHРрИХТЪ:
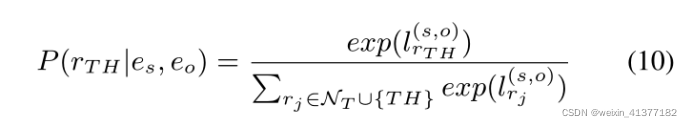
Ы№ЪЇКЏЪ§:
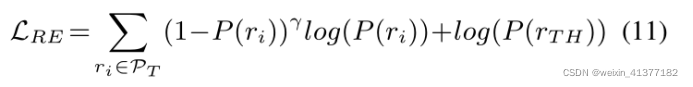
ATLгыAFLЧјБ№:
AFLЦфжаriЕФlogitгыуажЕРрTHЕФlogitЗжБ№ХХађЁЃетгызюГѕЕФATL ВЛЭЌ,дкзюГѕЕФATLжа,ЫљгаЕФе§ЖдЪ§ЖМгыsoftmaxЙІФмвЛЦ№ХХађЁЃ
(3)ЛљгкдЖГЬМрЖНдЄбЕСЗЕФжЊЪЖеєСѓ
зюКѓ,ЮвУЧРћгУжЊЪЖеєСѓРДПЫЗўШЫЙЄБъзЂЪ§ОнгыдЖГЬМрЖНЪ§ОнжЎМфЕФ Вювь(дЖГЬМрЖНЪЪгІЕФЙиМќЬєеНЪЧПЫЗўдЖГЬМрЖНЪ§ОнгыШЫЙЄБъзЂЪ§Он ЕФИХТЪЗжВМжЎМфЕФВювьЁЃ)ЁЃОпЬхРДЫЕ,ЮвУЧЪЙгУДјзЂЪЭЕФЪ§ОнбЕСЗ teacherФЃаЭ,ВЂНЋЦфЪфГігУзїШэБъЧЉЁЃШЛКѓЛљгкШэБъЧЉКЭдЖОрРыБъ ЧЉЖдstudentФЃаЭНјаадЄбЕСЗЁЃдЄЯШбЕСЗЕФstudentФЃаЭНЋЪЙгУДјзЂ ЪЭЕФЪ§ОндйДЮЮЂЕїЁЃ
ЂйЦгЫиЪЪгІ
ЪзЯШЪЙгУОпгаЙиЯЕЬсШЁЫ№ЪЇLRE (Eqn. 11)ЕФдЖГЬМрЖНЪ§ОнЖдФЃаЭНј аадЄбЕСЗ,ШЛКѓЖдОпгаЯрЭЌФПБъЕФШЫЙЄБъзЂЪ§ОнНјааЮЂЕїЁЃЮвУЧГЦет жжЗНЗЈЮЊЦгЫиЪЪгІ(NA)ЁЃ
ЂкжЊЪЖеєСѓ
 БэБэ1:DocREDКЭHacREDЪ§ОнМЏЕФЪ§ОнМЏЭГМЦЁЃ
БэБэ1:DocREDКЭHacREDЪ§ОнМЏЕФЪ§ОнМЏЭГМЦЁЃ
ЮЊСЫНјвЛВНРћгУДјзЂЪЭЕФЪ§Он,ЮвУЧЪЙгУвЛИідкДјзЂЪЭЕФЪ§Он(Бэ1жаЕФ#Train)ЩЯбЕСЗЕФЙиЯЕЗжРрФЃаЭзїЮЊНЬЪІФЃаЭЁЃдЖГЬМрЖНЪ§ОнБЛЪфШыЕННЬЪІФЃаЭжа,ЖјдЄВтЕФlogitsНЋЪЧгУгкбЕСЗбЇЩњФЃаЭЕФШэБъЧЉЁЃбЇЩњФЃаЭгыНЬЪІФЃаЭОпгаЯрЭЌЕФХфжУ,ЕЋЭЌЪБЪЙгУСНИіаХКХНјаабЕСЗЁЃЕквЛИіаХКХЪЧРДзддЖМрЖНЪ§ОнЕФгВБъЧЉЕФМрЖН,ЕкЖўИіаХКХРДзддЄВтЕФШэБъЧЉЁЃ
гВБъЧЉЩЯЕФЫ№ЪЇКЏЪ§ЮЊ:
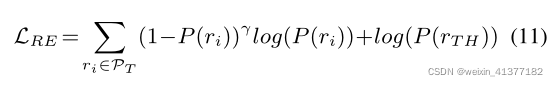
ШэБъЧЉЩЯЕФжЊЪЖеєСѓЫ№ЪЇКЏЪ§:
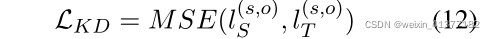
l(s,o) sЮЊбЇЩњФЃаЭЕФдЄВтЖдЪ§,l(s,o) TЮЊНЬЪІФЃаЭЕФдЄВтЖдЪ§ЁЃ
змЬхЫ№ЪЇКЏЪ§:
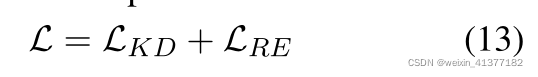
ЮхЁЂЪЕбщ:
дкСНИіЮФЕЕМЖЙиЯЕЬсШЁЪ§ОнМЏЩЯЦРЙРСЫФЃаЭЁЊЁЊDocRED-baseКЭHacREDЪ§ОнМЏЁЃ
DocREDЪЧвЛИіжкАќЕФДѓЙцФЃЮФЕЕМЖЙиЯЕЬсШЁЪ§ОнМЏЁЃЫќАќКЌ3,053/1,000/1,000ИіЪЕР§,ЗжБ№гУгкХрбЕЁЂбщжЄКЭВтЪдЁЃHacREDЪЧвЛИіжаЮФЙиЯЕГщШЁЪ§ОнМЏ,жївЊбаОПЙиЯЕГщШЁЕФвЩФбАИР§ЁЃЫќАќКЌ27ИігВЙиЯЕ,ЗжЮЊ6231 / 1500 / 1500ИіЪЕР§,гУгкбЕСЗЁЂбщжЄКЭВтЪдЁЃШЛЖј,HacREDЕФВтЪдМЏЛЙУЛгаЗЂВМЁЃдкБОЮФжа,ЮвУЧжЛЬсЙЉЦфПЊЗЂМЏЩЯЕФНсЙћЁЃ
жївЊНсЙћ
ЂйDocREDЪ§ОнМЏ
Бэ2:DocREDЪ§ОнМЏЕФЪЕбщНсЙћЁЃБЈИцЕФжИБъЪЧF1ЕУЗжКЭIgn_F1ЁЃЮвУЧБЈИцПЊЗЂМЏ5ДЮЫцЛњдЫааЕФЦНОљжЕ,зюМбМьВщЕугУгкЬсНЛВтЪдНсЙћЕФХХааАёЁЃ?ЕФНсЙћЪЧЭЈЙ§ИДжЦЕУЕНЕФЁЃ
Бэ2ЯдЪОСЫDocREDЪ§ОнМЏЕФжївЊНсЙћЁЃжЊЪЖОЋСѓФмЙЛЯджјЬсИпЮвУЧЕФФЃаЭЕФадФмЁЃЮвУЧЕФkd - rb -lЛёЕУСЫ67.28ЪдбщF1ЕФзюМбЕЅФЃаЭадФмЁЃЮвУЧзюКУЕФФЃаЭдкВтЪдF1ЩЯБШжЎЧАЕФзюЯШНјЕФsan - na - rb -lадФмЬсИпСЫ1.36,дкВтЪдIgn_F1ЩЯЬсИпСЫ1.46ЁЃЮвУЧзюКУЕФФЃаЭдкВтЪдF1ЩЯБШжЎЧАЕФзюЯШНјЕФsan - na - rb -lадФмЬсИпСЫ1.36,дкВтЪдIgn_F1ЩЯЬсИпСЫ1.46ЁЃ
ЂкHacREdЪ§ОнМЏ
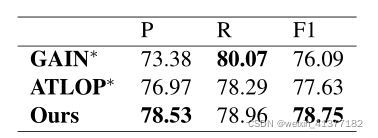
Бэ3:дкHacREDПЊЗЂМЏЩЯЕФЪЕбщНсЙћЁЃ*ЪЧгЩЮвУЧжДааЕФЁЃЫљгаЪЕбщОљЪЙгУXLM-R-baseзїЮЊБрТыЦїЁЃ
HacREDЪ§ОнМЏЕФЪЕбщНсЙћШчБэ3ЫљЪОЁЃ ЮвУЧЕФЗНЗЈКЭTLOPЛљЯпЕФжївЊЧјБ№дкгкздЪЪгІОжВПЫ№ЪЇКЭжсЯђзЂвтФЃПщЁЃ ЮвУЧЬсГіЕФЗНЗЈФмЙЛБШA TLOPЛљЯпГЌГі1.12 F1ЁЃГ§СЫФЃаЭЕФадФмжЎЭт,жЕЕУзЂвтЕФЪЧ,ЖдгкУПжжЗНЗЈ,HacREDЕФОјЖдадФмЖМЯджјИпгкЦфдкDocREDЩЯЕФадФмЁЃетЪЧЮЅЗДжБОѕЕФ,вђЮЊHacREDВржигкгВЙиЯЕ,ЖјDocREDдђИќвЛАуЁЃ
етПЩФмЪЧгЩвдЯТдвђдьГЩЕФ:
1)HacREDЪ§ОнМЏЕФШЫЙЄБъзЂбЕСЗЪЕР§УїЯдЖргкDocRED,ДгЖјЕМжТИќКУЕФЗКЛЏадФмЁЃ
2) ОЁЙмHacREDЩљГЦЫќзЈзЂгкЙиЯЕЬсШЁЕФгВАИР§,ЕЋЫќжЛга27ИіРр,ВЂЧвHacREDЪ§ОнМЏжаЕФЙиЯЕРраЭЗжВМИќМгЦНКтЁЃ
СљЁЂЯћШкЪЕбщ
ЯШАбБъЧЉПеМфЗжГЩСНИізгМЏЁЃЕквЛИізгМЏгЩ10ИізюГЃМћЕФБъЧЉзщГЩ,еМбЕСЗЪ§Онжае§ЙиЯЕЕФ59.4%ЁЃЕкЖўИізгМЏБэЪОЮЊГЄЮВБъЧЉ,ЫќАќКЌСЫ86ИіЙиЯЕжаЕФЦфгрВПЗж(змБъЧЉПеМфЮЊ97,гавЛИіT HРр)ЁЃ
гЩгкЮвУЧЕФздЪЪгІОжВПЫ№ЪЇКЏЪ§жївЊЪЧЮЊСЫЬсИпЕЭЦЕТЪРрЕФадФм,ЮвУЧдкБэ4жаеЙЪОСЫЦЕЗБРрКЭГЄЮВРрЕФЯћШкбаОПЁЃЕБЮвУЧНЋAFLЫ№ЪЇИФБфЮЊДЋЭГЕФздЪЪгІуажЕЫ№ЪЇ(Zhou et al., 2021)ЪБ,KDЕФзмЬхадФмЯТНЕСЫ0.89 F1,ЖјЦЕЗББъЧЉЕФF1ЕУЗжНіЯТНЕСЫ0.65ЁЃ
ЭЌЪБ,ГЄЮВБъЧЉF1ЯТНЕ1.78,УїЯдИпгкећЬхадФмЯТНЕКЭЦЕЗБадФмЯТНЕЁЃетБэУїЮвУЧЕФздЪЪгІНЙЕуЫ№ЪЇФмЙЛЦНКтЦЕЗБРрКЭВЛЦЕЗБРрЕФШЈжиЁЃжсЯђЙизЂФЃПщЖдгкГЄЮВРрБШЦЕЗБРрИќгаРћ,БэУїЮвУЧЕФФЃаЭдкЦЕЗБРрЩЯЕФадФмЪЧБЅКЭЕФЁЃ

Бэ5:DocREDПЊЗЂМЏЩЯinferf - f1ЙиЯЕЕФЯћШкбаОПЁЃ
ЦпЁЂздЪЪгІЗНЗЈБШНЯ
дкБОНкжа,ЮвУЧжБНгБШНЯDocREDПЊЗЂМЏЩЯЕФжЊЪЖЪЪгІЗНЗЈ(Бэ6)ЁЃ
ЮвУЧжївЊБШНЯСЫШ§жжздЪЪгІЗНЗЈ:
1)ЦгЫиздЪЪгІ(NA)
2)KDKLжЊЪЖеєСѓгыKLЩЂЖШЫ№ЪЇ,
3)KDM SEгыОљЗНЮѓВюЫ№ЪЇЁЃ
ПЊЗЂМЏЩЯЕФЪЪХфадФмгыЯТгЮЮЂЕїадФмГЪе§ЯрЙиЁЃдкдЖЖЫЪЪгІЛЗОГжа,ЮвУЧЕФзюМбЗНЗЈKDM SEБШNAИпГі3.07 F1,БШKDKLИпГі0.77 F1ЁЃдкГжајбЕСЗЩшжУжавВЙлВьЕНРрЫЦЕФБэЯжВювьЁЃ
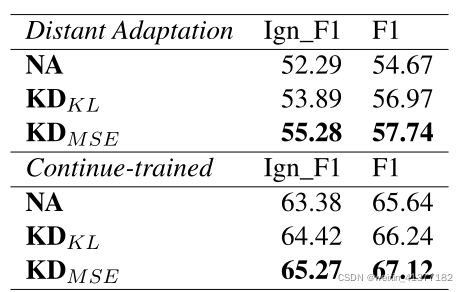
Бэ6:DocREDВЛЭЌжЊЪЖЪЪгІЗНЗЈЕФПЊЗЂМЏадФмЁЃ
АЫЁЂДэЮѓЗжЮі
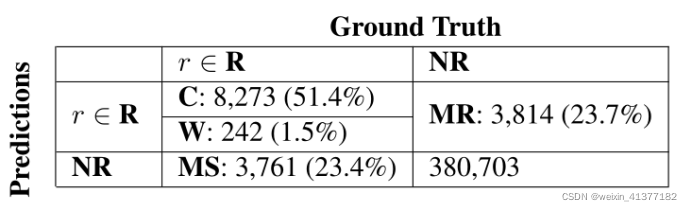
Бэ7:ЮвУЧЕФЮѓВюЗжВМЭГМЦЁЃзюжеЕФЦРМлЗжЪ§ЪЧдкrЁЪRЕФШ§дЊзщЩЯНјааЦРМл,вђДЫдкМЦЫузюжеЗжЪ§ЪБКіТдNRЕФе§ШЗдЄВтЁЃ
ЮвУЧЪзЯШЙЙНЈФЃаЭЕФдЄВтКЭЕиУцецжЕШ§дЊзщЕФСЊКЯ(УЛгаNRБъЧЉ)ЁЃШЛКѓ,ЮвУЧНЋВЂМЏЗжЮЊЫФРр:
(1)Correct ( C),ЦфжадЄВтШ§дЊзщдкground truthжаЁЃ
(2)ДэЮѓ(W),дЄВтЕФЭЗЪЕЬхКЭЮВЪЕЬхЮЛгкЕиУцецжЕ,ЕЋдЄВтЕФЙиЯЕЪЧДэЮѓЕФЁЃ
(3) miss (MS),ФЃаЭдЄВтвЛЖдЭЗЪЕЬхКЭЮВЪЕЬхУЛгаЙиЯЕ,ЕЋдкЕиУцtruthжагаЙиЯЕЁЃ
(4) More (MR),ЦфжаФЃаЭдЄВтСЫвЛЖдЭЗЪЕЬхКЭЮВЪЕЬхдкЕиУцецРэжаВЛЯрЙиЕФЭтВПЙиЯЕЁЃ
ОХЁЂНсТл
БОЮФЬсГіСЫвЛжжаТЕФЮФЕЕМЖЙиЯЕГщШЁПђМм,ИУПђМмЛљгкжЊЪЖОЋСѓЁЂжсЯђзЂвтКЭздЪЪгІНЙЕуЫ№ЪЇЁЃЮвУЧЬсГіЕФЗНЗЈФмЙЛдкDocREDХХааАёЩЯЯджјГЌЙ§вдЧАЕФвеЪѕзДЬЌЁЃДЫЭт,ЮвУЧЛЙНјааСЫЩюШыЕФЯћШкбаОПКЭЮѓВюЗжЮі,вдЪЖБ№ЮФЕЕМЖЙиЯЕЬсШЁШЮЮёЕФЦПОБЁЃ

