Transformer采用自注意力机制,与一般注意力机制计算分配值的方法基本相同,原理可参考
https://blog.csdn.net/weixin_43421371/article/details/124623933?spm=1001.2014.3001.5501
只是!Query的来源不同,一般AM中的query来源于目标语句,而self-AM的query来源于源语句本身。
Encoder模块中自注意力机制计算步骤如下:
- 把输入单词转换为带时序信息的嵌入向量 x(源单词的词嵌入 + 对应的Position Encoding);
- 根据嵌入向量 x 生成 q、k、v 三个向量(即query、key、value);
- 根据 q ,计算每个单词点积后的得分:score = q 点乘 k ;
- 对 score 进行规范化、Softmax 处理,假设结果为a(权重矩阵);
- a 与对应的 v 相乘,然后累加得到当前语句各单词之间的自注意力 z。
例子:

各嵌入向量的维度一般较大(上图为512),q、k、v 的维度比较小,一般使其维度满足:嵌入向量维度 / h(上图中为8)。
实际计算过程中得到的score可能比较大,为保证计算梯度时不影响稳定性,进行归一化操作,上图除以8。
Q、K、V 从哪来??
Q、K、V 都是从同样的 输入矩阵X 线性变换而来的。在实际训练过程中,Q、K、V都是一个dense层,通过反向传播学习得到(更新矩阵值)。
简单理解一下:
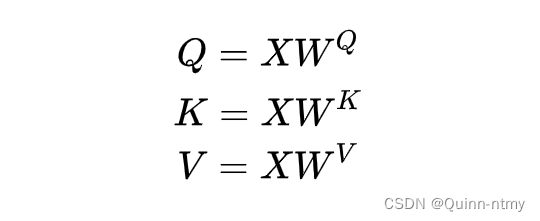
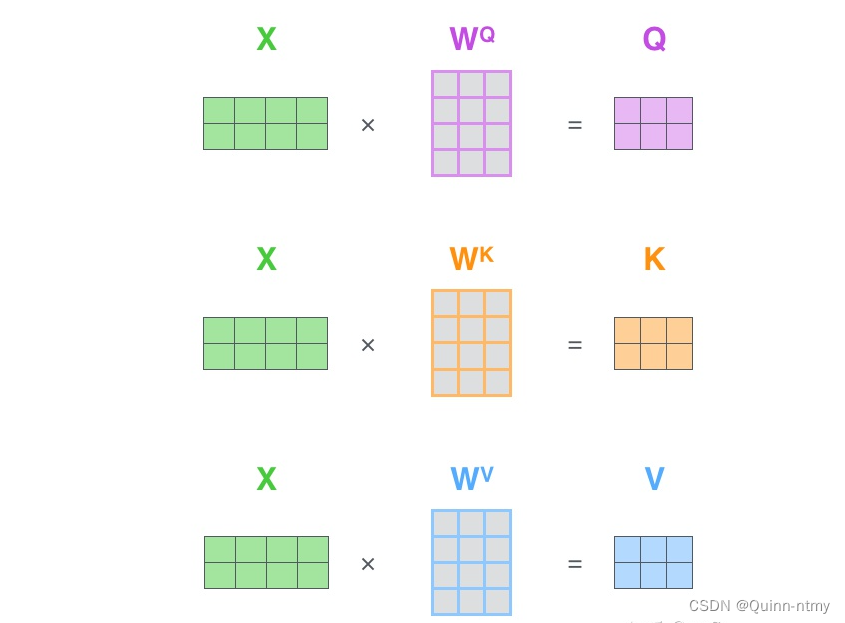
结合上图。输入X分别乘以三个矩阵,生成Q、K、V。
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV是三个可训练的参数矩阵。Attention不直接使用X ,而是使用经过矩阵乘法生成的这三个矩阵Q、K、V,使用三个可训练的参数矩阵,可增强模型的拟合能力。
缩放点积注意力(整体计算流程):
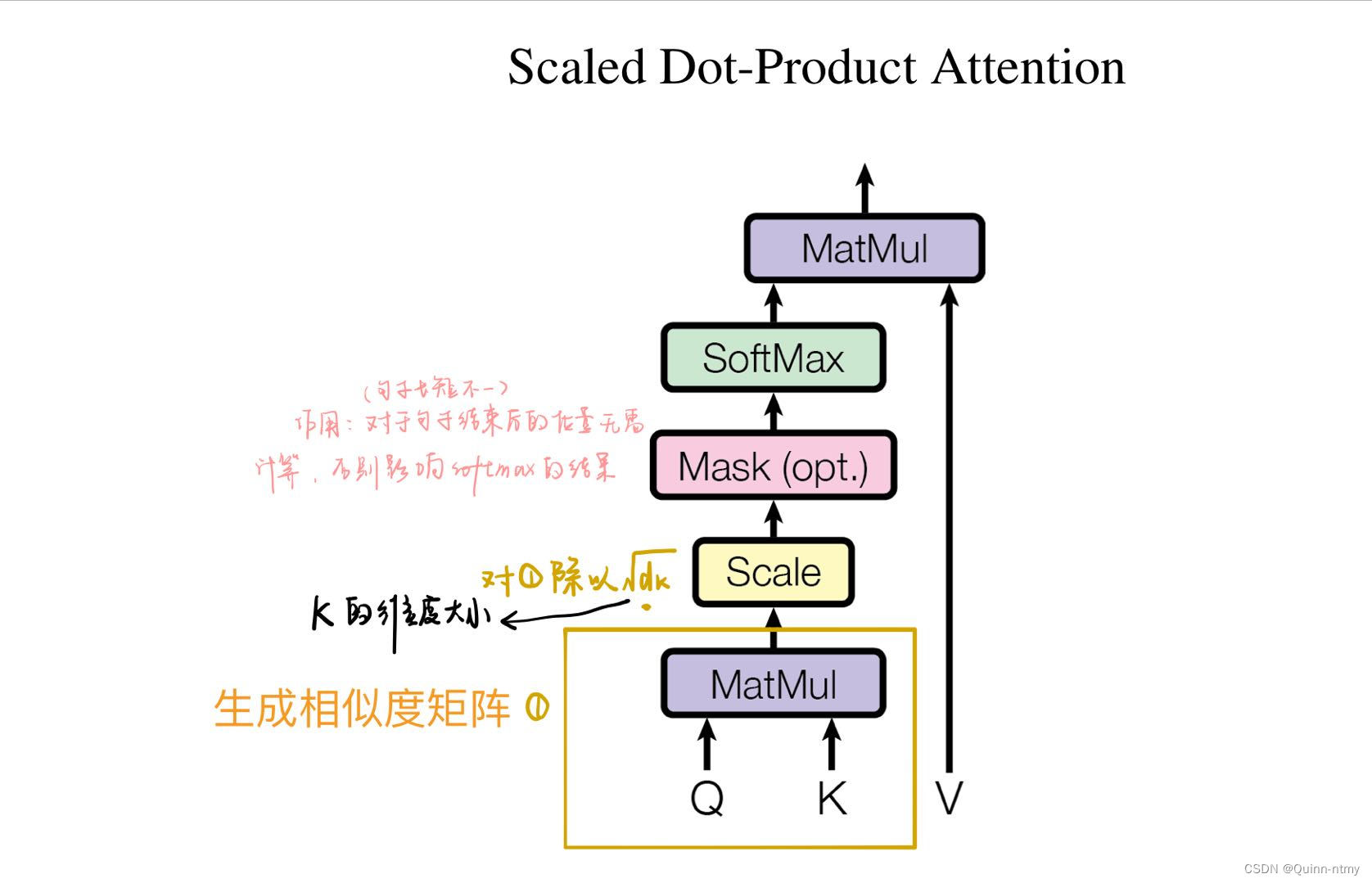
Mask表示掩码,用于遮掩某些值,使其在参数更新时不产生效果。Transformer中涉及两种掩码方式:
- Padding Mask
用于处理长短不一的语句,即对齐(用在Encoder中)
短序列后填充0,长序列截取左边多余内容舍弃。
具体做法:给这些位置的值加上一个非常大的负数,这样经过Softmax计算后,这些位置的概率就会接近0。联想一下代码中的masked_fill()。 - Sequence Mask
只会用在Dencoder的自注意力中,用于防止Decoder预测目标值时看到未来的值。
对于一个序列来说,decode输出应该只能依赖于 t时刻 之前的输出,而不能依赖于 t 之后的输出。所以要把 t 之后的输出隐藏起来。
具体做法:生成一个上三角矩阵,使上三角的值全为0,然后让序列乘以这个矩阵。
实现代码:
def subsequent_mask(size):
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# np.triu(m, k)――返回函数的上三角矩阵,参数k:表示从第几条对角线起保留数据,0是主对角线;正值是主对角线往上数,负值是主对角线往下数
return torch.from_numpy(subsequent_mask) == 0
a = subsequent_mask(6)[0]
print(a)
结果:
tensor([[ True, False, False, False, False, False],
[ True, True, False, False, False, False],
[ True, True, True, False, False, False],
[ True, True, True, True, False, False],
[ True, True, True, True, True, False],
[ True, True, True, True, True, True]])
Process finished with exit code 0
观察上面的结果,第一行只有第一列是True,代表时刻1只能关注输入1;第二行说明时刻2关注{1, 2}而不关注{4, 5, 6}的输入。
对于Decoder的自注意力,需要同时使用Padding Mask和Squence Mask作为attn_mask,然后将两个mask相加作为attn_mask。其他情况下,attn_mask一律等于Padding Mask。
多头注意力机制
三个方面提升性能:
(1)扩展模型专注于不同位置的能力;
(2)将缩放点积注意力过程做h次,再把输出合并起来;
(3)为注意力层提供了多个“表示子空间”。
对于同样的输入X,定义多组不同的
W
Q
W^Q
WQ、
W
K
W^K
WK、
W
V
W^V
WV,每组分别计算不同的 Q、K、V,最后学习到不同的参数。
原始论文中初始化了8组矩阵,最终得到8个
Z
i
Z_i
Zi?(
Z
0
Z_0
Z0? 到
Z
7
Z_7
Z7?),在输出到下一层之前,把这8个
Z
i
Z_i
Zi? 拼接到一起得到
Z
Z
Z,然后将
Z
Z
Z 与初始化的矩阵
W
0
W^0
W0 相乘(降维)得到最终输出值。
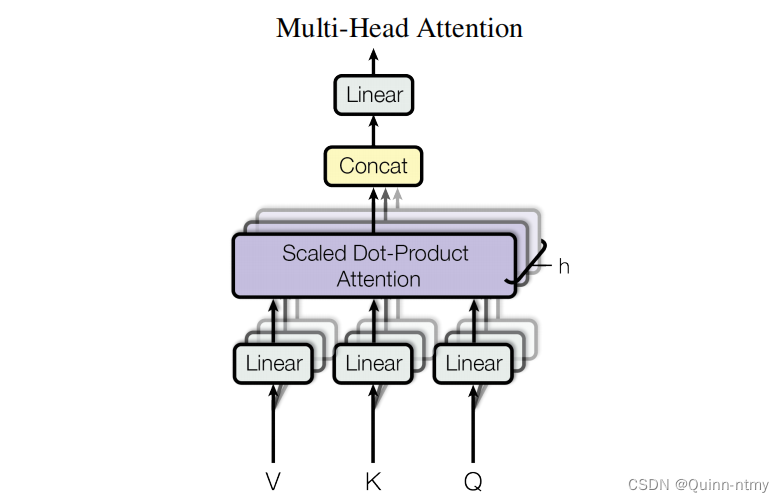
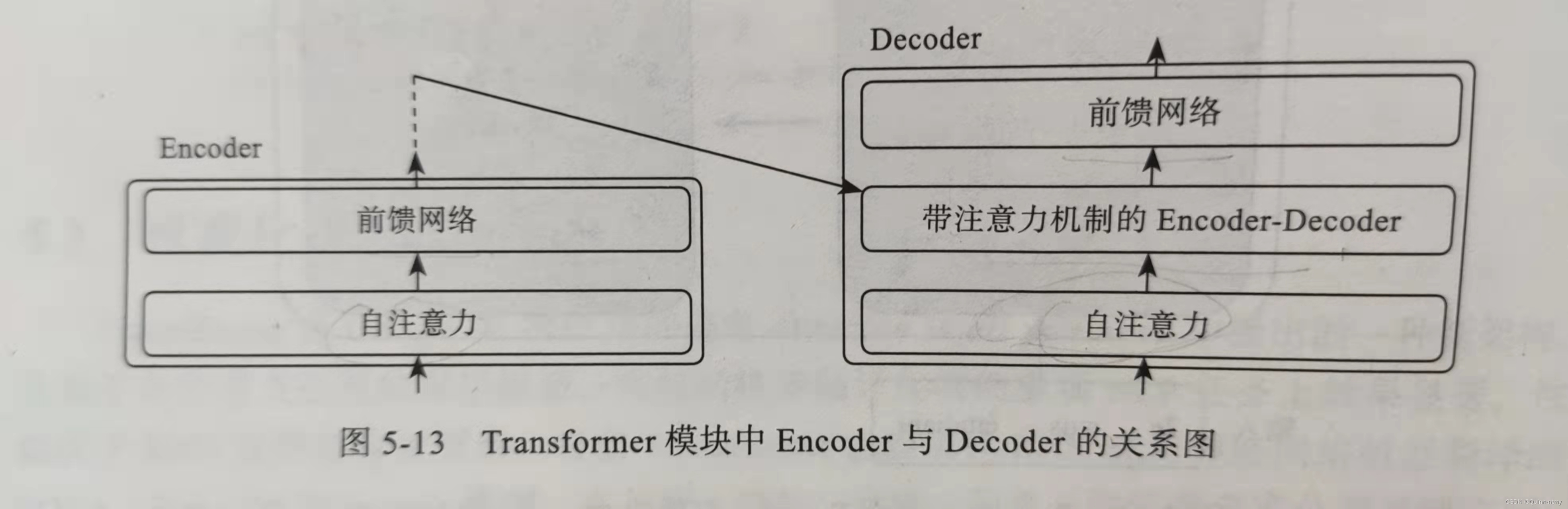
在Decoder中,Encoder-Decoder Attenrion Layer中,Q来自Decoder的上一个输出,K和V来自Encoder最后一层的输出,计算过程与自注意力相同。
可以看出,自注意力机制没有前后依赖关系,可以基于矩阵进行高并发处理,另每个单词的输出与前一层各单词的距离都为1,所以不存在梯度消失。
Transformer的Encoder组件和Decoder组件分别有6层,在某些应用中可能会有更多层。层数增加,网络容量变大,能力也更强,但如何克服网络收敛速度变慢,梯度消失等问题??
解决网络收敛速度变慢,梯度消失
1. 残差连接Residual Connection
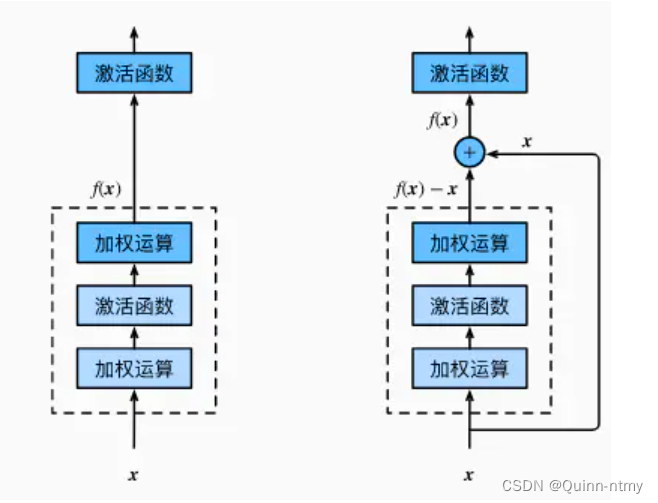
左边为普通结构,右边为残差连接结构。
残差连接指的就是将 浅层的输出 和 深层的输出 求和 作为下一阶段的输入,这样做的结果就是本来这一层权重需要学习是一个对
x
x
x 到
f
(
x
)
f(x)
f(x) 的映射。那使用残差连接以后,权重需要学习的映射变成了从
x
x
x ―>
f
(
x
)
?
x
f(x)-x
f(x)?x,这样在反向传播的过程中,小损失的梯度更容易抵达浅层的神经元。
2. 归一化Normalization(有LayerNorm 和 BatchNorm 建议观看沐神视频)
层规范化是基于特征维度进行,对单个batch进行归一化,批量规范化是对所有batch进行归一化。虽然BatchNorm在CV中应用广泛,但在NLP(X通常是变长序列)中,LayerNorm效果较好。
具体实现方法:在每个Encoder或Decoder的两个子层(Self-Attention 和 FFNN)间增加残差连接和归一化组成的层。
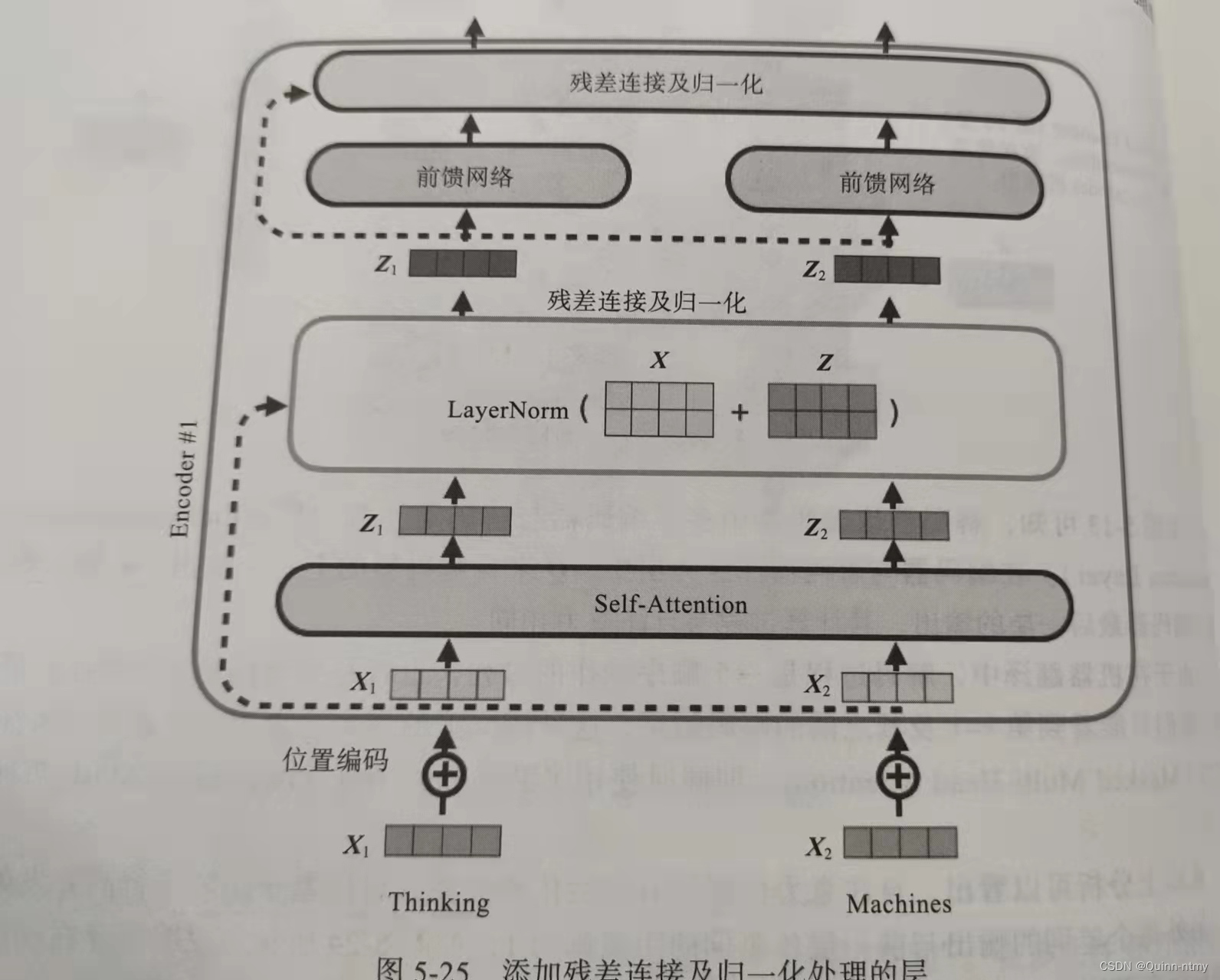
使用ResNet 和 LayerNorm实现AddNorm类:
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
add_norm = AddNorm([3, 4], 0.5)
print(add_norm)
b = add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4)))
print(b)
print(b.shape)
残差连接要求两个输入形状相同,以便加法操作。
输出结果:
AddNorm(
(dropout): Dropout(p=0.5, inplace=False)
(ln): LayerNorm((3, 4), eps=1e-05, elementwise_affine=True)
)
tensor([[[-0.5773, -0.5773, -0.5773, 1.7320],
[-0.5773, -0.5773, -0.5773, -0.5773],
[ 1.7320, 1.7320, -0.5773, -0.5773]],
[[-1.0000, -1.0000, 1.0000, -1.0000],
[ 1.0000, 1.0000, -1.0000, -1.0000],
[ 1.0000, 1.0000, 1.0000, -1.0000]]],
grad_fn=<NativeLayerNormBackward0>)
torch.Size([2, 3, 4])
Process finished with exit code 0

