基于Pytorch的Transform翻译模型前期数据处理方法
Google于2017年6月在arxiv上发布了一篇非常经典的文章:Attention is all you need,提出了解决sequence to sequence问题的transformer模型,该文章使用全Attention的结构代替了LSTM,抛弃了之前传统的encoder-decoder模型必须结合CNN或者RNN的固有模式。在减少计算量和提高并行效率的同时还取得了更好的结果,也被评为2017年 NLP 领域的年度最佳论文。
一、运行环境安装配置和部分主要Python库的安装
- 点击打开《基于Windows中学习DeepLearning之搭建Anaconda+Pytorch(Cuda+Cudnn)+Pycharm工具和配置环境完整最简版》文章
- 点击打开《基于Windows安装langconv实现繁体和简体字的转换》文章
- 点击打开《Resource punkt not found. Please use the NLTK Downloader to obtain the resource错误解决方案》文章
- 点击打开《Jupyter Notebook安装及使用指南》文章
- 点击打开《Jupyter Notebook自动补全代码配置》文章
二、数据集的准备和下载,整个数据集总共有21005条数据。
三、数据集的前期处理,可以将整个数据集人为分成两个数据集,分别是训练数据集和验证数据集,可以进行7:3的比例划分。博主为了理解展示数据的处理流程,所以每个数据集只部分选取了1000多条数据进行模型流程数据举例。
四、数据处理模块(重要)
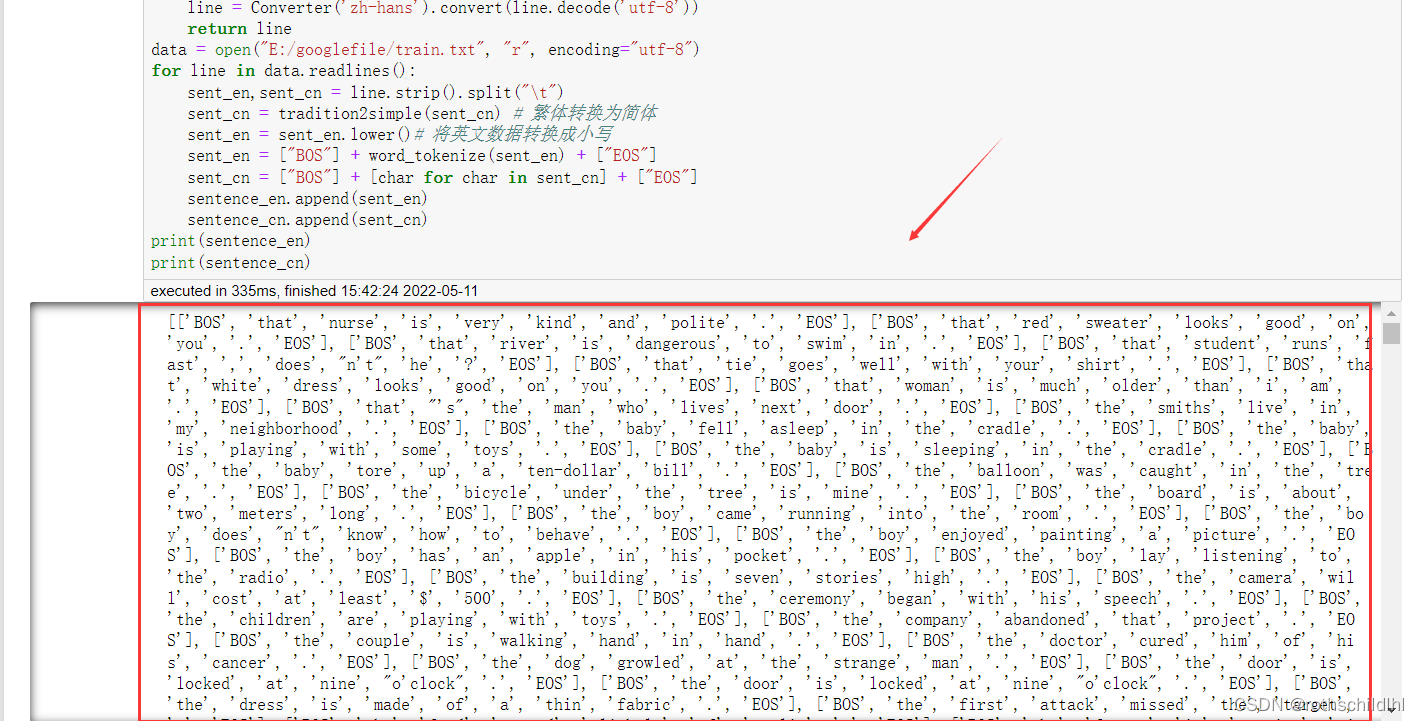
- 首先将数据集导入,然后读取每行数据将每条数据集进行分离这个英文和中文,再分别保存到sent_en和sent_cn,然后将中文繁体字转换为简体字,英文全部变成小写字母,然后分别在每条中英文添加[BOS]和[EOS]两个字符,这两个字符的意义是起始符和终止符,表明一句话的开始和结束,最后将每条中英文数据汇总分别添加到sentence_en和sentence_cn列表。
import sys
from sys import path
path.append(r'D:\Anaconda\Scripts') # 导入langconv文件路径
import numpy as np
import torch
from collections import Counter
from langconv import Converter
from nltk import word_tokenize
sentence_en = []
sentence_cn = []
def tradition2simple(line):
# 将繁体转换成简体
line = line.encode('utf-8')
line = Converter('zh-hans').convert(line.decode('utf-8'))
return line
data = open("E:/googlefile/train.txt", "r", encoding="utf-8") # 导入数据集
for line in data.readlines(): # 读取每条数据
sent_en,sent_cn = line.strip().split("\t") # 每条数据分割成中英文
sent_cn = tradition2simple(sent_cn) # 繁体转换为简体
sent_en = sent_en.lower()# 将英文数据转换成小写
sent_en = ["BOS"] + word_tokenize(sent_en) + ["EOS"] # 每条中文数据添加[BOS]和[EOS]两个字符
sent_cn = ["BOS"] + [char for char in sent_cn] + ["EOS"] # # 每条中文数据添加[BOS]和[EOS]两个字符
sentence_en.append(sent_en) # 英文数据汇总添加
sentence_cn.append(sent_cn) # 中文数据汇总添加
print(sentence_en)
print(sentence_cn)
- 将中英文句子分开以列表存储后,接下来分别统计中英文句子数据的词频,并构成单词和词频的字典w,比如:{“XR”:20},然后根据词频大小排列选出前200的中英文单词,然后将词频大小前200个单词进行枚举构成新的词频字典word_dict_en和word_dict_cn,代码中w[0]就是只提取单词,w[1]单词的词频不需要,再将单词的下标右移两个单位数值增加2,目的是后面要添加两个字符分别是UNK和PAD,这两个字符的作用后面要用到,分别用于填补词频大小前200个单词以外的单词和填补每个batch中以最长的句子为标准的其他小于其的句子,使得每个batch中句子大小一样长;接下来因为添加了两个字符,所以相当于数据集中多了两个字符,所以中英文数据集单词的长度加2,然后将word_dict_en和word_dict_cn的键值互换,结果就互换了,比如:{“everyone”:185}互换变成{185”:“everyone}。
# 建立常用字符字典
word_count_en = Counter([word for sent in sentence_en for word in sent]) # 统计英文数据中每个词的词频构成单词和词频的字典
word_count_cn = Counter([word for sent in sentence_cn for word in sent]) # 统计中文数据中每个词的词频构成单词和词频的字典
mostcommonword_en = word_count_en.most_common(200) # 选取数据集中所有英文单词中词频大小前200的单词
mostcommonword_cn = word_count_cn.most_common(200) # 选取数据集中所有中文单词中词频大小前200的单词
word_dict_en = {w[0]:index + 2 for index,w in enumerate(mostcommonword_en)} # 将mostcommonword_en枚举下标加二和单词构成新的字典
word_dict_cn = {w[0]:index + 2 for index,w in enumerate(mostcommonword_cn)} # 将mostcommonword_en枚举下标加二和单词构成新的字典
word_dict_en['UNK'] = 1 # 在新的字典word_dict_en增加一个字符UNK
word_dict_en['PAD'] = 0 # 在新的字典word_dict_en增加一个字符PAD
word_dict_cn['UNK'] = 1 # 在新的字典word_dict_en增加一个字符UNK
word_dict_cn['PAD'] = 0 # 在新的字典word_dict_en增加一个字符PAD
total_words_en = len(word_count_en) + 2 # 英文数据的字典的长度增加二
total_words_cn = len(word_count_cn) + 2 # 中文数据的字典的长度增加二
index_dict_en = {v:k for k,v in word_dict_en.items()} # 将新字典中的键值互换
index_dict_cn = {v:k for k,v in word_dict_cn.items()} # 将新字典中的键值互换
print(index_dict_en)
print(index_dict_cn)
- 接下来将中英文句子的单词转换成数字编码,然后存进列表code_num_en和code_num_cn,再使用sorted函数根据句子长短排序,也就是每个句子下标的索引值根据句子短到长进行排序,再返回排序后各句子的索引值,再根据索引值依次提取对应的数字编码好的句子,分别存进code_num_en和code_num_cn列表。注意:其中句子中有非常编号为1的句子,就是UNK的编号也就是UNK替换的进行掩盖的单词也就是词频非前200的单词。
# 将中英文句子的内容根据字典换成对应编码
code_num_en = [[word_dict_en.get(word,1) for word in sent] for sent in sentence_en] # 从英文句子中获得句子,再从每条句子获得每个词,再进行对应编码替换
code_num_cn = [[word_dict_cn.get(word,1) for word in sent] for sent in sentence_cn] # 从中文句子中获得句子,再从每条句子获得每个词,再进行对应编码替换
sorted_index_en = sorted(range(len(code_num_en)), key=lambda x: len(code_num_en[x])) # 根据句子长短排序句子索引值
sorted_index_cn = sorted(range(len(code_num_cn)), key=lambda x: len(code_num_cn[x])) # 根据句子长短排序句子索引值
code_num_en = [code_num_en[idx] for idx in sorted_index_en] # 根据索引值重新排列
code_num_cn = [code_num_cn[idx] for idx in sorted_index_cn] # 根据索引值重新排列
print(code_num_en)
print(code_num_cn)
- 首先设定批次数据的大小,然后将数据集长度按照每批次大小进行分开,最后将批次顺序进行打乱。
batch_size = 128 # 设定每批次数据大小
batch_list = np.arange(0,len(code_num_en),batch_size) # 将数据集长度按照每批次大小进行分开
np.random.shuffle(batch_list) # 将批次顺序进行打乱
print(batch_list)

- 根据各批次数据的下标索引值,生成完整的各批次内的各句子下标索引值,注意:在批次累加值不能超过数据集长度,否则会数据溢出报错。
batch_indexs = [] # 数据集各批次数据
for idx in batch_list: # 提取各批次下标
batch_indexs.append(np.arange(idx,min(idx+batch_size,len(code_num_en)))) # 为了防止溢出,批次累加值不能超过数据集长度
print(batch_indexs)
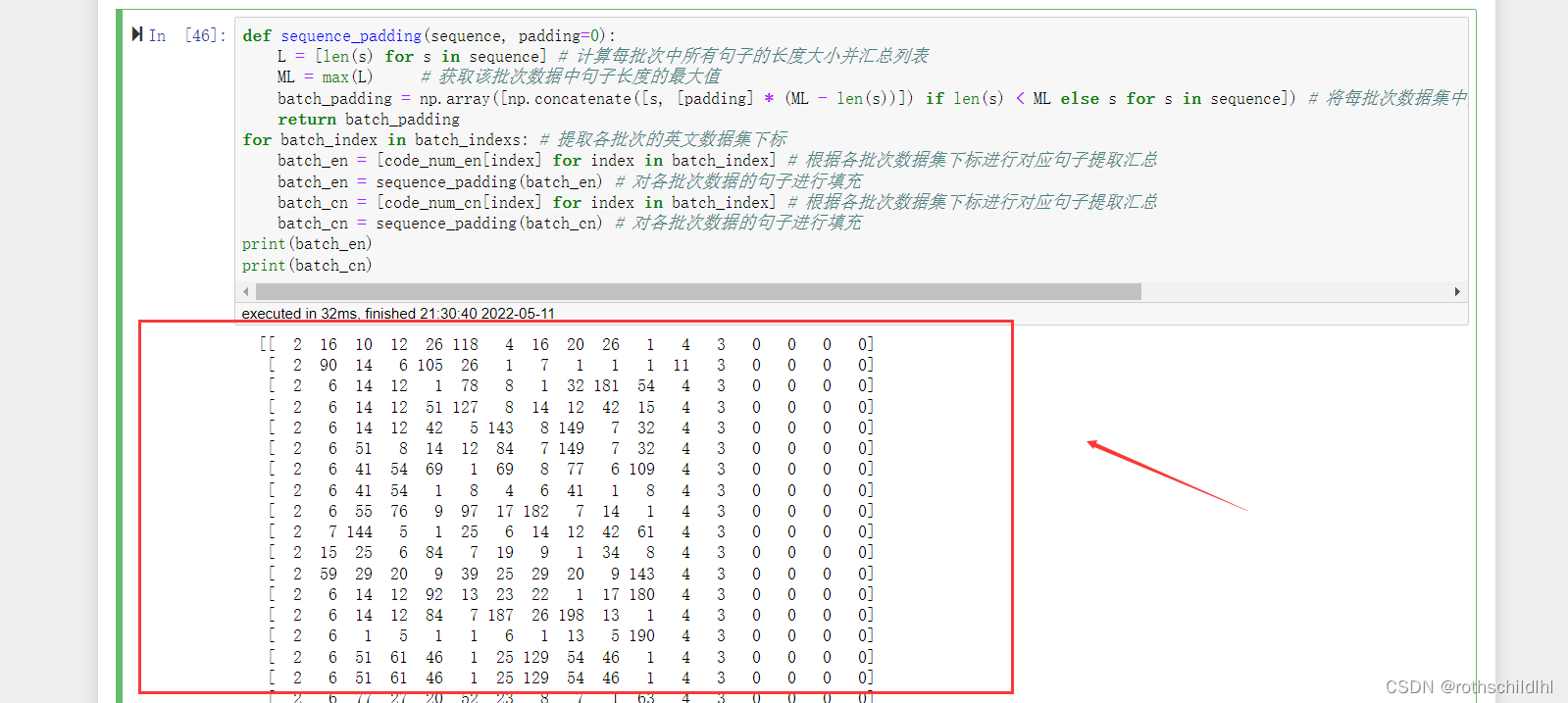
- 首先提取各批次的数据集下标,然后根据各批次数据集下标分别提取对应的中英文的句子,然后将每次批次的中英文句子中的长度最大的句子为标准长度,其余句子按照标准长度用0进行填充,比如:某批次的数据集总共有128个句子,然后其中第30句的长度最大为56个单词,那么该批次其余的句子要用0补充到长度为56。
def sequence_padding(sequence, padding=0):
L = [len(s) for s in sequence] # 计算每批次中所有句子的长度大小并汇总列表
ML = max(L) # 获取该批次数据中句子长度的最大值
batch_padding = np.array([np.concatenate([s, [padding] * (ML - len(s))]) if len(s) < ML else s for s in sequence]) # 将每批次数据集中的每个句子用0填充成一样长度大小,再拼接在一个列表
return batch_padding
for batch_index in batch_indexs: # 提取各批次的数据集下标
batch_en = [code_num_en[index] for index in batch_index] # 根据各批次数据集下标进行对应句子提取汇总
batch_en = sequence_padding(batch_en) # 对各批次英文数据的句子进行填充
batch_cn = [code_num_cn[index] for index in batch_index] # 根据各批次数据集下标进行对应句子提取汇总
batch_cn = sequence_padding(batch_cn) # 对各批次中文数据的句子进行填充
print(batch_en)
print(batch_cn)
[[ 2 16 10 12 26 118 4 16 20 26 1 4 3 0 0 0 0]
[ 2 90 14 6 105 26 1 7 1 1 1 11 3 0 0 0 0]
[ 2 6 14 12 1 78 8 1 32 181 54 4 3 0 0 0 0]
[ 2 6 14 12 51 127 8 14 12 42 15 4 3 0 0 0 0]
[ 2 6 14 12 42 5 143 8 149 7 32 4 3 0 0 0 0]
[ 2 6 51 8 14 12 84 7 149 7 32 4 3 0 0 0 0]
[ 2 6 41 54 69 1 69 8 77 6 109 4 3 0 0 0 0]
[ 2 6 41 54 1 8 4 6 41 1 8 4 3 0 0 0 0]
[ 2 6 55 76 9 97 17 182 7 14 1 4 3 0 0 0 0]
[ 2 7 144 5 1 25 6 14 12 42 61 4 3 0 0 0 0]
[ 2 15 25 6 84 7 19 9 1 34 8 4 3 0 0 0 0]
[ 2 59 29 20 9 39 25 29 20 9 143 4 3 0 0 0 0]
[ 2 6 14 12 92 13 23 22 1 17 180 4 3 0 0 0 0]
[ 2 6 14 12 84 7 187 26 198 13 1 4 3 0 0 0 0]
[ 2 6 1 5 1 1 6 1 13 5 190 4 3 0 0 0 0]
[ 2 6 51 61 46 1 25 129 54 46 1 4 3 0 0 0 0]
[ 2 6 51 61 46 1 25 129 54 46 1 4 3 0 0 0 0]
[ 2 6 77 27 20 52 23 8 7 1 63 4 3 0 0 0 0]
[ 2 6 84 9 122 1 4 33 14 8 84 11 3 0 0 0 0]
[ 2 6 166 1 7 1 104 127 38 141 1 4 3 0 0 0 0]
[ 2 6 41 1 17 5 182 6 55 1 50 4 3 0 0 0 0]
[ 2 6 41 5 74 80 1 7 37 34 8 4 3 0 0 0 0]
[ 2 16 141 25 107 6 84 7 37 9 1 4 108 3 0 0 0]
[ 2 6 44 1 8 25 129 6 98 12 168 8 4 3 0 0 0]
[ 2 6 14 12 51 78 6 19 52 7 14 27 4 3 0 0 0]
[ 2 6 185 7 1 1 25 129 176 6 14 12 4 3 0 0 0]
[ 2 6 41 165 25 129 6 98 12 1 8 171 4 3 0 0 0]
[ 2 78 8 116 9 1 25 6 99 1 8 74 4 3 0 0 0]
[ 2 78 8 83 1 25 1 6 41 1 25 114 4 3 0 0 0]
[ 2 107 59 20 36 86 11 108 107 30 5 1 4 108 3 0 0]
[ 2 107 1 1 10 18 11 108 107 27 10 1 4 108 3 0 0]
[ 2 107 71 16 42 1 11 108 107 1 25 16 71 4 108 3 0]
[ 2 107 15 10 12 50 4 108 107 1 59 10 16 11 108 3 0]
[ 2 107 14 8 1 1 11 108 107 75 25 6 14 12 4 108 3]]
[[ 2 10 17 1 7 9 13 107 67 27 1 10 1 150 1 1 4 3
0 0 0 0 0 0 0]
[ 2 8 95 1 75 71 97 14 13 27 1 1 1 16 1 1 18 3
0 0 0 0 0 0 0]
[ 2 1 9 16 199 6 1 40 18 1 1 1 16 5 6 4 1 3
0 0 0 0 0 0 0]
[ 2 8 117 31 152 22 1 51 73 12 73 58 1 5 63 1 4 3
0 0 0 0 0 0 0]
[ 2 5 39 12 63 34 5 17 22 140 123 1 6 1 1 7 4 3
0 0 0 0 0 0 0]
[ 2 5 1 1 7 14 13 66 33 27 1 22 1 1 61 7 4 3
0 0 0 0 0 0 0]
[ 2 5 54 77 7 1 1 1 16 36 54 26 46 30 144 188 4 3
0 0 0 0 0 0 0]
[ 2 22 1 62 60 5 17 43 7 5 17 102 38 43 6 47 4 3
0 0 0 0 0 0 0]
[ 2 10 12 62 60 49 46 30 10 6 1 40 23 1 72 10 4 3
0 0 0 0 0 0 0]
[ 2 5 12 11 6 33 79 27 10 163 16 5 6 1 1 24 4 3
0 0 0 0 0 0 0]
[ 2 22 1 1 11 14 140 1 41 92 5 1 26 7 90 76 4 3
0 0 0 0 0 0 0]
[ 2 12 1 86 56 46 30 47 27 5 48 29 11 8 1 1 4 3
0 0 0 0 0 0 0]
[ 2 5 1 1 1 45 24 58 180 198 6 166 1 34 1 187 4 3
0 0 0 0 0 0 0]
[ 2 5 21 39 142 143 37 49 46 30 9 30 35 6 1 1 4 3
0 0 0 0 0 0 0]
[ 2 9 13 66 1 67 1 1 7 14 1 160 139 1 6 1 1 4
3 0 0 0 0 0 0]
[ 2 8 17 1 7 120 125 41 166 27 36 46 30 23 43 6 7 4
3 0 0 0 0 0 0]
[ 2 1 12 16 93 13 129 11 9 25 6 24 48 16 1 15 6 4
3 0 0 0 0 0 0]
[ 2 19 20 1 1 150 1 109 1 1 87 1 109 1 1 109 106 4
3 0 0 0 0 0 0]
[ 2 8 29 1 23 14 13 1 1 6 155 1 34 43 9 157 47 4
3 0 0 0 0 0 0]
[ 2 1 8 35 1 68 28 69 1 1 1 12 27 5 12 35 4 1
3 0 0 0 0 0 0]
[ 2 102 15 1 1 48 1 1 11 1 194 33 70 1 1 22 34 4
3 0 0 0 0 0 0]
[ 2 5 62 60 10 6 122 40 27 1 12 62 60 10 6 167 176 4
3 0 0 0 0 0 0]
[ 2 11 8 17 105 57 27 19 20 16 13 127 123 6 167 176 28 18
3 0 0 0 0 0 0]
[ 2 172 200 201 1 36 1 104 11 36 15 1 1 6 33 79 1 1
4 3 0 0 0 0 0]
[ 2 22 140 5 123 26 37 6 33 79 27 37 54 22 42 1 44 6
4 3 0 0 0 0 0]
[ 2 1 19 20 12 11 32 108 4 1 1 32 30 10 11 97 108 18
1 3 0 0 0 0 0]
[ 2 38 12 38 98 8 173 1 5 1 1 1 1 1 6 1 1 1
69 3 0 0 0 0 0]
[ 2 156 132 73 38 6 78 27 11 117 31 111 43 44 9 13 155 89
4 3 0 0 0 0 0]
[ 2 5 62 60 10 6 167 176 27 1 12 62 60 10 179 46 30 122
4 3 0 0 0 0 0]
[ 2 38 11 106 65 142 26 9 122 6 74 6 1 40 1 1 1 123
4 3 0 0 0 0 0]
[ 2 156 132 8 1 1 23 84 1 27 112 23 1 174 1 186 64 155
89 4 3 0 0 0 0]
[ 2 1 10 75 71 1 1 28 69 1 1 1 16 6 1 1 10 75
71 4 1 3 0 0 0]
[ 2 12 23 41 24 57 1 6 1 1 1 1 1 1 27 1 144 1
188 6 4 3 0 0 0]
[ 2 11 8 15 1 23 6 33 79 27 29 1 8 6 1 1 1 16
1 91 6 1 1 4 3]]
五、数据集处理完整代码如下:
import sys
from sys import path
path.append(r'D:\Anaconda\Scripts')
import numpy as np
import torch
from collections import Counter
from langconv import Converter
from nltk import word_tokenize
from torch.autograd import Variable
sentence_en = []
sentence_cn = []
def tradition2simple(line):
# 将繁体转换成简体
line = line.encode('utf-8')
line = Converter('zh-hans').convert(line.decode('utf-8'))
return line
data = open("E:/googlefile/train.txt", "r", encoding="utf-8")
for line in data.readlines():
sent_en,sent_cn = line.strip().split("\t")
sent_cn = tradition2simple(sent_cn) # 繁体转换为简体
sent_en = sent_en.lower()# 将英文数据转换成小写
sent_en = ["BOS"] + word_tokenize(sent_en) + ["EOS"]
sent_cn = ["BOS"] + [char for char in sent_cn] + ["EOS"]
sentence_en.append(sent_en)
sentence_cn.append(sent_cn)
# 建立常用字符字典
word_count_en = Counter([word for sent in sentence_en for word in sent]) # 统计英文数据中每个词的词频构成单词和词频的字典
word_count_cn = Counter([word for sent in sentence_cn for word in sent]) # 统计中文数据中每个词的词频构成单词和词频的字典
mostcommonword_en = word_count_en.most_common(200) # 选取数据集中所有英文单词中词频大小前200的单词
mostcommonword_cn = word_count_cn.most_common(200) # 选取数据集中所有中文单词中词频大小前200的单词
total_words_en = len(word_count_en) + 2 # 英文数据的字典的长度增加二
total_words_cn = len(word_count_cn) + 2 # 中文数据的字典的长度增加二
word_dict_en = {w[0]:index + 2 for index,w in enumerate(mostcommonword_en)} # 将mostcommonword_en枚举下标加二和单词构成新的字典
word_dict_cn = {w[0]:index + 2 for index,w in enumerate(mostcommonword_cn)} # 将mostcommonword_en枚举下标加二和单词构成新的字典
word_dict_en['UNK'] = 1 # 在新的字典word_dict_en增加一个字符UNK
word_dict_en['PAD'] = 0 # 在新的字典word_dict_en增加一个字符PAD
word_dict_cn['UNK'] = 1 # 在新的字典word_dict_en增加一个字符UNK
word_dict_cn['PAD'] = 0 # 在新的字典word_dict_en增加一个字符PAD
index_dict_en = {v:k for k,v in word_dict_en.items()} # 将新字典中的键值互换
index_dict_cn = {v:k for k,v in word_dict_cn.items()} # 将新字典中的键值互换
# 将中英文句子的内容根据字典换成对应编码
code_num_en = [[word_dict_en.get(word,1) for word in sent] for sent in sentence_en] # 从英文句子中获得句子,再从每条句子获得每个词,再进行对应编码替换
code_num_cn = [[word_dict_cn.get(word,1) for word in sent] for sent in sentence_cn] # 从中文句子中获得句子,再从每条句子获得每个词,再进行对应编码替换
sorted_index_en = sorted(range(len(code_num_en)), key=lambda x: len(code_num_en[x])) # 根据句子长短排序句子索引值
sorted_index_cn = sorted(range(len(code_num_cn)), key=lambda x: len(code_num_cn[x])) # 根据句子长短排序句子索引值
code_num_en = [code_num_en[idx] for idx in sorted_index_en] # 根据索引值重新排列
code_num_cn = [code_num_cn[idx] for idx in sorted_index_cn] # 根据索引值重新排列
batch_size = 128 # 设定每批次数据大小
batch_list = np.arange(0,len(code_num_en),batch_size) # 将数据集按照每批次大小进行分开
np.random.shuffle(batch_list) # 将批次顺序进行打乱
batch_indexs = [] # 数据集各批次数据
for idx in batch_list: # 提取各批次下标
batch_indexs.append(np.arange(idx,min(idx+batch_size,len(code_num_en)))) # 为了防止溢出,批次累加值不能超过数据集长度
def sequence_padding(sequence, padding=0):
L = [len(s) for s in sequence] # 计算每批次中所有句子的长度大小并汇总列表
ML = max(L) # 获取该批次数据中句子长度的最大值
batch_padding = np.array([np.concatenate([s, [padding] * (ML - len(s))]) if len(s) < ML else s for s in sequence]) # 将每批次数据集中的每个句子用0填充成一样长度大小,再拼接在一个列表
return batch_padding
for batch_index in batch_indexs: # 提取各批次的英文数据集下标
batch_en = [code_num_en[index] for index in batch_index] # 根据各批次数据集下标进行对应句子提取汇总
batch_en = sequence_padding(batch_en) # 对各批次数据的句子进行填充
batch_cn = [code_num_cn[index] for index in batch_index] # 根据各批次数据集下标进行对应句子提取汇总
batch_cn = sequence_padding(batch_cn) # 对各批次数据的句子进行填充
print(batch_en)
print(batch_cn)

