����˼��ʱ������ѧϰ:��Ƶ�����е��ٶ�-ȷ��Ȩ��
paper��Ŀ:Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification
paper��GoogLe Research ������ECCV 2018����
paper��ַ:����
Abstract.
���ܲ��þ��������� (CNN) ����Ƶ��������ȡ�����Ȳ���չ,����ԸĽ���û�� 2D ��̬ͼ�������ô���ҡ�����������Ҫ��ս,�����ռ�(ͼ��)������ʾ��ʱ����Ϣ��ʾ��ģ��/���㸴���ԡ� Carreira �� Zisserman �������,�� 2D ������չ���� ImageNet �Ͻ���Ԥѵ���� 3D CNN ������һ�ֺ���ǰ;�Ŀռ��ʱ���ʾѧϰ������Ȼ��,��ģ��/���㸴���Զ���,3D CNN �� 2D CNN ����ö�,����������ϡ�ͨ��ϵͳ̽���ؼ��������ѡ����������Ч�Ҹ�Ч����Ƶ����ϵͳ,�Ӷ����ٶȺ�ȷ��֮��Ѱ��ƽ�⡣�ر��,���߱��������õͳɱ��� 2D �����滻���� 3D �������൱���˾��ȵ���,���滻����ײ��� 3D ����ʱ,ʵ������ѽ��(�ٶȺ�ȷ��),������������塱������ʱ���ʾѧϰ�����á����ĵĽ����ƹ㵽���зdz���ͬ���Ե����ݼ��������������־��гɱ�Ч������(�����ɷ���Ŀռ�/ʱ������������ſ�)���ʹ��ʱ,���ĵ�ϵͳ������һ����Ч����Ƶ����ϵͳ,��ϵͳ�ڼ������������(Kinetics��Something-something��UCF101 �� HMDB)�ϲ����˷dz��о������Ľ��,�Լ������������(�ֲ���)��(JHMDB �� UCF101-24)��
1 Introduction
���������� (CNN) �ĸ���Ϊʹ�ö˵��˷ֲ�����ѧϰ�ܹ���ͼ����������һ��ǰ��δ�еĽ�����Ȼ��,��Ƶ���������û����ͼ��������������ͬˮƽ��������������ȥ,һ��������ȱ�����ģ�ı����Ƶ���ݼ���Ȼ��,��������� Sports1M��Kinetics��Something-something��ActivityNet��Charades���Ѿ�������������һ�ϰ���
�������ٸ���������ս���ر��,Ҫ�˷�������Ҫ�ϰ�:(1)�����õر�ʾ�ռ���Ϣ(��ʶ����������); (2) �����õر�ʾʱ����Ϣ(��ͨ��ʱ��ʶ�������ġ�����Ժ������ϵ); (3) �����ѵ���Ͳ���ʱ��õ�Ȩ��ģ�����Ժ��ٶȡ�
������,ͨ�����Ǹ��� 3D CNN ���о����������⡣���ĵij����������Ƚ��ķ���,���� Carreira �� Zisserman,����Ϊ��I3D��(��Ϊ������Inception������� 2D �����˲��������͡��� 3D)�������ṩ�����õ�����,����ģ�͵ļ���ɱ��dz��ߡ��������˼�������,��ͼ�ڱ����н����Щ����:
-
��Ҫ 3D ������?���������,Ӧ��������Щ�� 3D,��Щ������� 2D?���Ƿ�ȡ�������ݼ������������?
-
��ʱ��Ϳռ��Ϲ�ͬ������Ҫ,��������Щά���϶����������㹻��?
-
���ʹ����������Ĵ����Ľ���ǰ������ȷ�ԡ��ٶȺ��ڴ�ռ��?
Ϊ�˻ش��һ������,Ӧ�á���������������� I3D �ܹ��ļ��ֱ��塣��Ϊ Bottom-Heavy-I3D ��һ�������,���������Ͳ�(��ӽ����صIJ�)���� 3D ʱ�����,���ڽϸ߲�ʹ�� 2D ��������Ϊ Top-Heavy-I3D ����һ������ϵ����,���෴������,���ڶ��㱣�� 3D ʱ�����,���ڽϵͲ�ʹ�� 2D(�μ�ͼ 1)��Ȼ��,ͨ�������ַ�ʽ�ı䡰������(ת��Ϊ 2D)�IJ������о������ȷ�Ժ��ٶ�֮�����Ȩ�⡣���� Top-Heavy-I3D ģ����,�Ⲣ�����,��Ϊ���ǽ��� 3D Ӧ���ڳ�������ͼ,���ڿռ�ػ�,��������ͼ�ȵͼ�����ͼС������,������ Top-Heavy-I3D ģ��ͨ����ȷ,�����˾���,��Ϊ���Ǻ����˵ͼ��˶���ʾ��
Ϊ�˻ش�ڶ�������(���ڷ���ռ��ʱ��),���ǽ� 3D �����滻Ϊ�ռ��ʱ��ɷ���� 3D ����,��,�� k t �� k �� k k_{t} \times k \times k kt?��k��k��ʽ�Ĺ������滻Ϊ 1 �� k �� k 1 \times k \times k 1��k��k,Ȼ���� k t �� 1 �� 1 k_{t} \times 1 \times 1 kt?��1��1,���� k t k_{t} kt?���˲�����ʱ���ϵĿ���, k k k���˲����ڿռ��еĸ߶�/���ȡ������ɵ�ģ�ͳ�Ϊ S3D,���������ɷ��� 3D CNN���� S3D �IJ�����Ȼ��ʹ�ñ� 3D ������ģ���ٺܶ�,���Ҽ���Ч�ʸ��ߡ����˾��ȵ���,����������Ҳ��ԭʼ I3D ģ�;��и��õ�ȷ�ԡ�
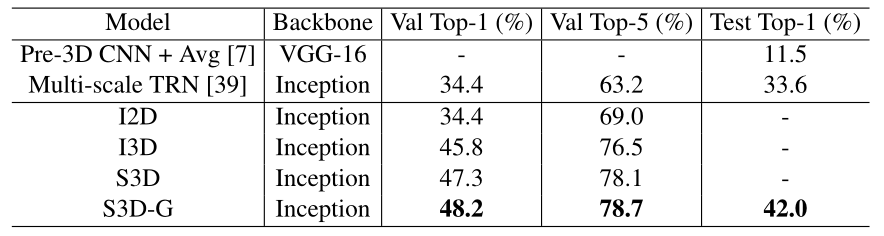
���,Ϊ�˻ش����������(���ڽ����ж�������һ����ʵ�ָ�Ч��ȷ����Ƶ����ϵͳ),���ڻش�������������ʱѧ����֪ʶ��ʱ���ſػ�������,�����һ���µ�ģ�ͼܹ�,��֮ΪS3D-G�����߱���,��ģ���ڸ��־�����ս�Ե���Ƶ�������ݼ�(���� Kinetics��Something-something��UCF-101 �� HMDB)�ϱȻ��߷������������ȷ��,������������Ƶʶ��������Ҳ����������������,����JHMDB �ϵĶ����ֲ�����
2 Related work
2D CNN ��ͼ������ȡ�������Ƚ��Ľ��,���,�������,��������ೢ�Խ���Щ�ɹ���չ����Ƶ���ࡣ Carreira �� Zisserman ����� Inception 3D (I3D) �ܹ��ǵ�ǰ���Ƚ���ģ��֮һ�����ijɹ��������ؼ�����:����,���ǽ� Inception V1 �ܹ�ʹ�õ����� 2D �����˲��������͡�Ϊ 3D ����,�������ڲ�����ϸѡ��ʱ��˴�С�����,ͨ����ʱ��ά���ϸ����� ImageNet ������Ԥѵ����Ȩ������ʼ�����͵�ģ��Ȩ�ء����,�����ڴ��ģ Kinetics ���ݼ���ѵ�����硣
���ҵ���,3D CNN �ļ���ɱ��ܸ�,���������ǶԸ���Ч�ı����������Ȥ����ͬ�ڹ�����,�������˸��ֻ��� ResNet �ܹ���ģ�͡��ر��,���ǿ����ڵײ��ʹ�� 3D ����,�������ʹ�� 2D ��ģ��;���ǽ���Щ��Ϊ����Ͼ�����ģ�͡������������ǵ�ͷ�ؽ���ģ�͡����ǵó�����,�ײ����������ȷ,�������ǵķ�����ì�ܡ�Ȼ��,���Ƿ���ͷ�ؽ���֮��IJ����൱С,��������㸴���Եı仯��Ϊһ̸��ͨ���о������ٶ�-ȷ��Ȩ������(Inception ����),���߱������ڸ����ļ���Ԥ��ʹ��ͷ�ؽ������������Եĺô�(�μ��� 4.2 ��)��
��һ�ֽ�ʡ����ķ������ÿɷ���������� 3D ����,���������� 2D �н��пռ����,Ȼ���� 1D �н���ʱ������������ɵ�ģ�ͳ�Ϊ S3D�����ַֽ��ھ����������ڿɷ������,���˱��Ľ�����뷨Ӧ����ʱ��ά�ȶ���������ά�ȡ�����뷨�Ѿ�������ĸ��������б�ʹ��,������R(2+1)D����(��Pseudo-3D network��)��(���ֽ�ʱ�վ������硱)�ȡ�����ʹ����ͬ�ķ���,��������ͷ�ؽ������ƽ������,����һ���dz���Ч����Ƶ����ϵͳ����ϡ����߱���,�ɷ��������������ʹ��ͷ�ؽ�����Ƶ������ǻ�����(�μ��� 4.4 ��)��
���ȷ�Ե�һ����Ч������ʹ�������ſ�,��ͨ������Ч�ij˷��任����������ͨ��֮���������ϵ������Կ����Ƕ��׳ػ�����Ч���ơ������ſ���������������,����������롢VQA��ǿ��ѧϰ��ͼ�����Ͷ���ʶ�𡣿�������������һ�ֱ���,���н������ſ�ģ������� S3D �����е�ÿ��ʱ�����֮��,����������������ȷ��(�μ��� 4.6 ��)��
������ʵ��������
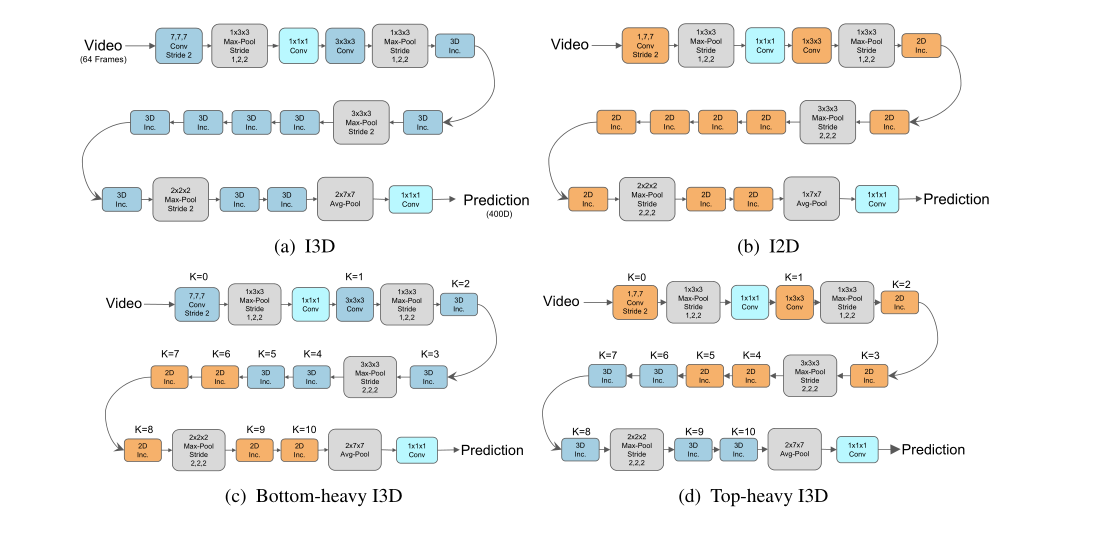
ͼ 2. (a) I3D��(b) I2D��? Bottom-Heavy �� (d) Top-Heavy ���������ܹ�ϸ�ڡ� K ����ʱ�վ����㡣 ��2D Inc.���͡�3D Inc.����ָ����ͼ 3 �ж���� 2D �� 3D ��ʼ�顣
4 Network surgery
���ڱ����˸��֡�����������ʵ��Ľ��,ͨ���ı� I3D ģ�͵IJ�ͬ�������о����ٶȺ�ȷ�Ե�Ӱ�졣
4.1 Replacing all 3D convolutions with 2D
������ͼȷ�� 3D ���������ļ�ֵ,�䶯���� 2D CNN ��������Ƶ�����ľ��˳ɹ���ͨ���� 2D �������滻 I3D ģ���е�ÿ�� 3D ��������������һ�㡣������˽���Ϊ I2D ģ�͵����ݡ�
�������Ͻ�,I2D ����Ӧ�ö�����֡��ʱ�䷴ת���ֲ���,��Ϊ�����ܺϲ�ȫ���źš�Ϊ����֤��һ��,�ھ�������֡˳��� Kinetics-Full �� Something-something ���ݼ���ѵ�� I2D ��ԭʼ I3D ģ��,����ѵ�����ģ��Ӧ����֡��������˳��ͷ�תʱ��˳�����֤���ݡ�ʵ������� 1 ��ʾ���ڲ��Թ�����,���� I2D �������汾�Ͼ�����ͬ������,����Ԥ�ڵ�������Ȼ��,ע� Kinetics ���ݼ���Something-something ���ݼ�֮���һ����Ȥ��������ǰһ�������,I3D �������롰ʱ���ͷ����,���ں�һ�������,�ߵ�˳��������ܡ���Ϊ������ΪSomething-something ���ݼ���Ҫ���Ӿ������ƵĶ������֮�����ϸ���ȵ����֡�
�� 1. Kinetics-Full �� Something-something ���ݼ��� Top-1 ȷ�ȡ�������˳���֡����ѵ��,Ȼ��������˳�����˳���֡���в��ԡ��������,2D CNN ������֡��˳���� Kinetics-Full �ϵ� 3D CNN,�����ͷ���Ľ������ͬ��,���������ʱ���ͷ���ڸ����ݼ��ϲ�����Ҫ��Ȼ��,��Something-something ��,ȷ�е�˳��ȷʵ����Ҫ��

4.2 Replacing some 3D convolutions with 2D
���������Ѿ����� 3D ������ 2D ������ȿ������ȷ��,�����ļ���ɱ��dz��ߡ������о����� 2D �滻һЩ 3D �����Ľ����������˵,�� I2D ģ�Ϳ�ʼ,�� 2D ��������Ϊ 3D,�������еĵͼ�������,�Դ�����ν�� Bottom-Heavy-I3D ģ�͡����������෴�Ĺ���,��ģ�͵Ķ�������Ϊ 3D,�����ֽϵ͵IJ�Ϊ 2D;�ƴ���ģ��Ϊ Top-Heavy-I3D ģ�͡�
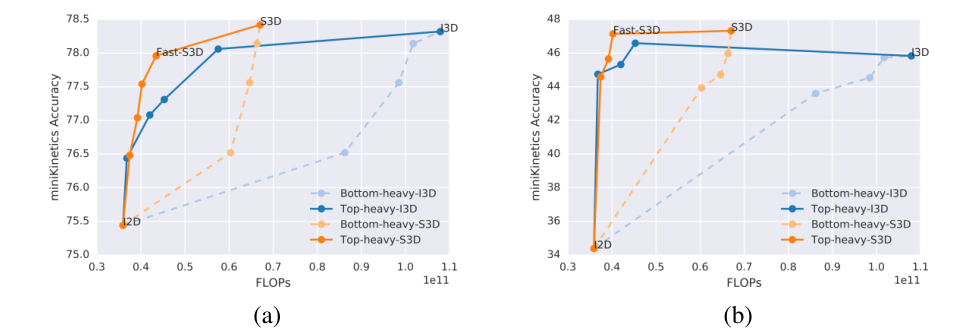
�� MiniKinetics-200 ��Something-something ��ѵ��������Bottom-Heavy-I3D ��Top-Heavy-I3D ģ��,����ͼ4 ����ʾ�����������ɫʵ��(top-heavy I3D)����ͬ FLOPS �µ���ɫ����(�ײ����ص� I3D),��ʾ�������ص�ģ���졢��ȷ��Ԥ���ٶȻ����,��Ϊ��ͷ�ؽ����ģ����,����ͼ���� 3D ����֮ǰʹ�ÿռ�ػ�����С�ߴ硣���ڹ̶��ļ���Ԥ��,Top-Heavy-I3D ͨ���� Bottom-Heavy-I3D ȷ�öࡣ����� 3D ��������������ḻ�ĸ������н�ģʱ��ģʽ�������������á�
ͼ 4. �� 64 �� RGB ִ֡�����������ȷ���� FLOPS ������:Mini-Kinetics-200 ���ݼ�����ͼ:Something-something ���ݼ���ʵ�߱�ʾͷ�ؽ����ģ��,���߱�ʾͷ�ؽ����ģ�͡���ɫ��ʾ�ռ��ʱ��ɷ���� 3D ����,��ɫ��ʾȫ 3D ������
4.3 Analysis of weight distribution of learned filters
Ϊ����֤����ֱ��,������� Kinetics-Full ��ѵ���� I3D ģ�͵�Ȩ�ء�ͼ 5 ��ʾ����ЩȨ����ģ�͵� 4 ���еķֲ�,�ӵͼ��������ر��,ÿ������ͼ��ʾ��ʱ��ƫ��
t
t
t�Ͳ�
l
l
l��
W
l
(
t
,
:
,
:
,
:
)
W_{l}(t,:,:,:)
Wl?(t,:,:,:)�ķֲ���ʹ��
t
=
0
t=0
t=0��ʾû��ʱ��ƫ��,��ʱ���ں��е����ġ��ڳ�ʼ��ʱ,����
t
��
{
?
1
,
0
,
1
}
t \in\{-1,0,1\}
t��{?1,0,1}��ÿ��ֵ,�����˲���������ͬ��һ��(2D ����)Ȩ��(Դ���� Imagenet ��Ԥѵ���� Inception ģ��)��ʼ��ѵ����,����ʱ��ƫ���˲���(��,����
t
��
0
t \neq 0
t��?=0)��Ȩ�طֲ��ڽϵͲ�������Ϊ����(����ͼ),���ֲ��ķ����ڽϸ߲�����(�������)�����ٴα����������ʱ��ģʽ�Զ���ѧ�������������������

ͼ 5. �� Kinetics-Full ��ѵ���� I3D ģ�͵ľ����˲���Ȩ��ͳ�ơ�ÿ������ͼ��ʾ�� W l ( t , : , : , : ) W_{l}(t,:,:,:) Wl?(t,:,:,:)����ʱ��ƫ�� t t t�ķֲ�,���� t = 0 t=0 t=0λ���м䡣��ͬ�� l l l�Ľ����ʾ�ڲ�ͬ�������,�������Ͳ㡣���о��в�ͬʱ��ƫ�ƵĹ�������ʹ����ͬ��Ȩ�ؼ����г�ʼ�����ͼ������������Ϻ�����ʱ��ά��,�������������ͬ,����Ȩ�غܺõطֲ��ڲ�ͬ��ʱ��ƫ���ϡ�
4.4 Separating temporal convolution from spatial convolutions
�����о����÷ֽ�汾�滻�� 3D ������Ч��,�÷ֽ�汾���ò����ֽ�Ϊʱ�䲿�ֺͿռ䲿�֡�����ϸ��˵,���ĵķ����ǽ�ÿ�� 3D �����滻Ϊ���������ľ�����:һ�� 2D ����������ѧϰ�ռ�����,Ȼ����һ��������ʱ�����ϵ� 1D �����㡣�����ͨ���������� 3D ������ʵ��,���е�һ��(�ռ�)���������˲�����״ [ 1 , k , k ] [1, k, k] [1,k,k],�ڶ���(ʱ��)���������˲�����״ [ k , 1 , 1 ] [k, 1,1] [k,1,1]��ͨ�������ַֽ�Ӧ���� I3D,�����һ����Ϊ S3D ��ģ�͡��йؼܹ�����ϸ˵��,�����ͼ 6��
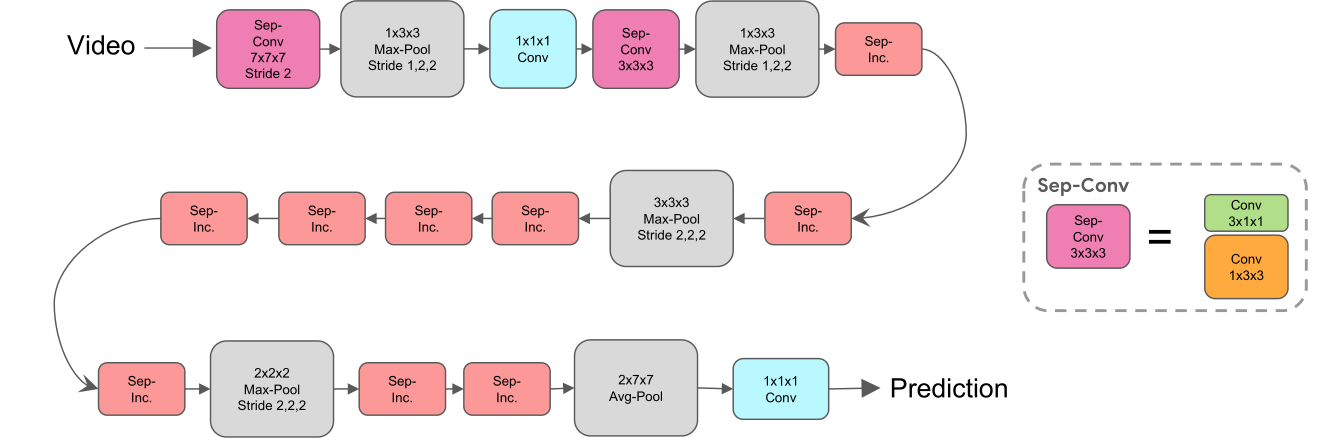
ͼ 6. S3D ģ��ʾ��ͼ�����ɫ����ʱ��ɷ������(sep-conv),�ۺ�ɫ����ʱ��ɷ����ʼ��,��ͼ 3(c)��ʾ��
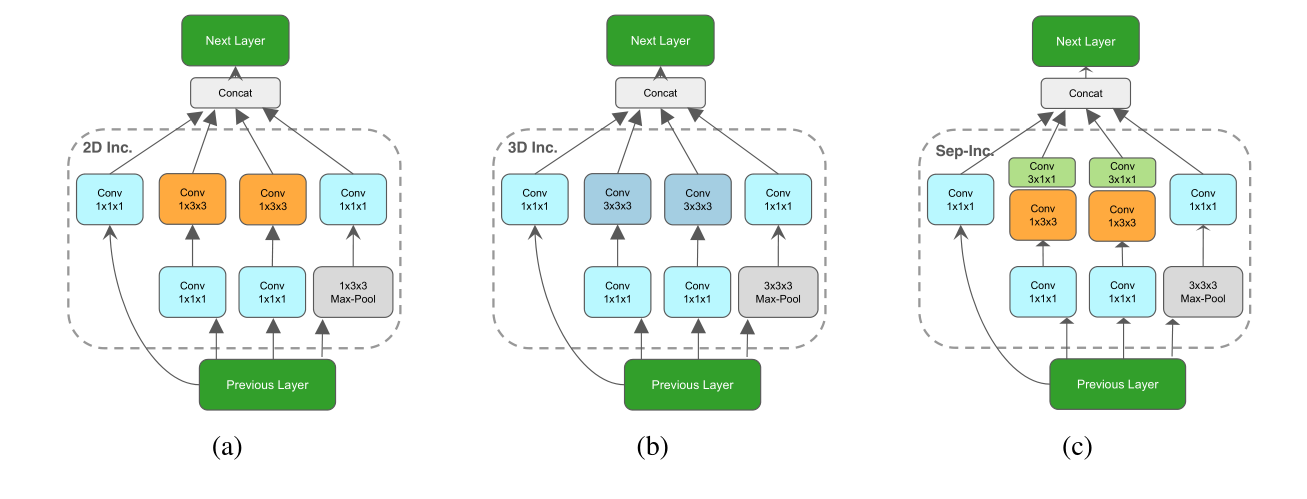
ͼ 3. (a) 2D Inception ��; (b) 3D Inception ��; ? S3D ������ʹ�õ� 3D ʱ��ɷ��� Inception �顣
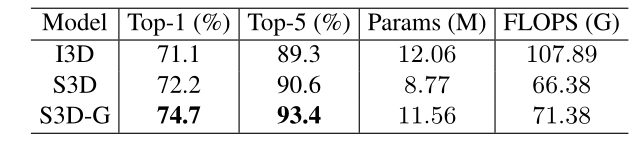
�� 2 �Ƚ��� Kinetics-Full �� S3D �� I3D �Ľ������ 3 ��ʾ S3D �� Something-something ���ݼ��ϵı���Ҳ���� I3D���������,����ģ�ʹ�С���ѹ��(I3D �� 12.06M �������ٵ� S3D �� 8.77M),���Ҽ��ٺܴ�(I3D �� 107.9 GFLOPS ���ٵ� S3D �� 66.38 GFLOPS),���ɷ���ģ���Ǿ��ȵĸ�ȷ(Kinetics-Full �� top-1 ȷ�ʴ� 71.1% ��ߵ� 72.2%,Something-something �� 45.8% ��ߵ� 47.3%)����������ȷ�Ե��������Ϊʱ�շֽ�����˹����,��ij�̶ֳ��ϲ�������ʾ�ı�����,��Ϊ���߷��ּؼ�������IJ���������û�а�����
�� 2. �ɷ�������������ſض�ʹ�� RGB ������ Kinetics-Full ��֤����Ӱ�졣
�� 3. �ɷ�������������ſض�ʹ�� RGB ������Something-something ��֤�Ͳ��Լ���Ӱ�졣
ע��,���Խ����ֿɷ���任Ӧ�õ��κ�ʹ�� 3D �����ĵط�;���,����뷨���� 4.1 �������۵���Щ��Ӧ�ð��� 3D �����������������ġ��� Bottom-Heavy-S3D ��ʾ Bottom-Heavy-I3D ģ�͵Ŀɷ���汾,�� Top-Heavy-S3D ��ʾ Top-Heavy-I3D ģ�͵Ŀɷ���汾,�Ӷ��ṩ�� 4 ��ģ��ϵ�С�
��ͼ 4 �л�������Щģ�͵��ٶ���ȷ�ԡ������ɷ����ͷ�ؽ���ģ���ṩ����ѵ��ٶ�-ȷ��Ȩ�⡣�ر��,��ǰ 2 �㱣��Ϊ�ɷ���� 3D ����,����� 2D ������ģ���ƺ���һ�֡����۵㡱������ģ�ͳ�Ϊ��Fast-S3D��,��Ϊ����Ч���� I3D �� 2.5 ��(43.47 �� 107.9 GFLOPS),�������൱��ȷ��(Mini-Kinetics-200 Ϊ 78.0% �� 78.4%)��
4.5 tSNE analysis of the features
����ʹ�� tSNE ͶӰ����̽����ͬ����� S3D ģ����Something-something ���ݼ���ѧϰ��ʱ�ձ�ʾ�� I3D ģ�͵���Ϊ�dz����ơ�û��ʹ���������� 174 ����������,����ʹ�ý�С�Ĵʻ��,����ġ�10 �������顱������֤���г�ȡ 2,200 �����ݵ㡣��ͼ 7 ��,��һ����ʾ�� S3D ģ���ڴ� Max3a �� Max5c �ļ�����ѧϰ�ı�ʾ���ڸ��ߵIJ����,��������Խ��Խ������
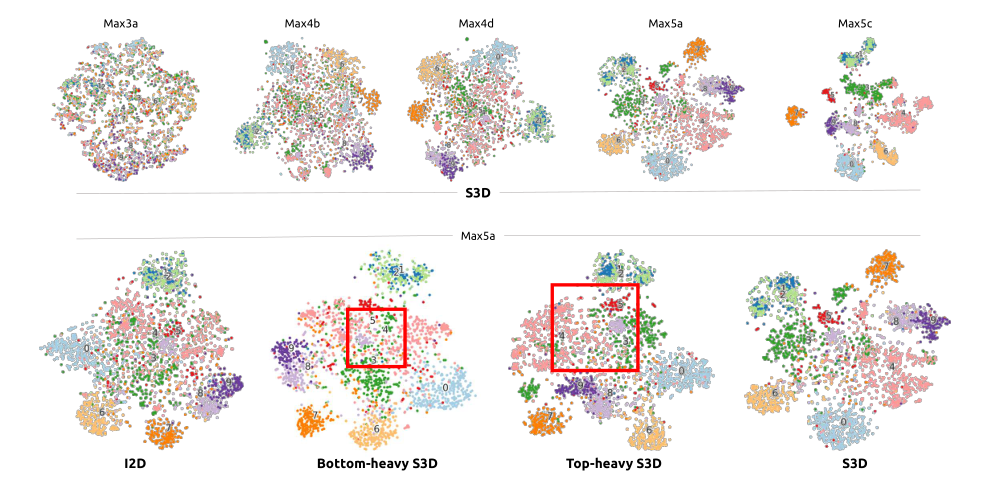
ͼ 7. �� Something-something ���ݼ��е�ͼ�������ļ���ͼ�� tSNE ͶӰ����ɫ�����ִ�������� 10 �������顣������ʾ���������ƶ��� S3D �ĸ��߲�����ӵ�������롣������ʾ�� 4 ����ͬģ���� Max5a ����ļ�����ǿ��� Top-Heavy-S3D �� Bottom-Heavy-S3D ���и��õ��������,�����Ƕ��ں�ɫ�����Ӿ������Ƶ����
������ʾ���ض��������� (Max5a) ѧϰ�ı�ʾ,���粻ͬģ��,���� I2D��Bottom-Heavy-S3D �� Top-Heavy-S3D(�� Max4b �㶼�� 2D-3D ת����),�Լ������� S3D ģ�͡��Ƚϵ���ģ�ͺͶ���ģ��,�������硰3: Picking������4: Putting���͡�5: Poking��֮���ϸ����,�� top-heavy ģ��ѧϰ�ı�ʾ���ڵ���ģ��,�Ӷ�ͨ�� tSNE ͶӰ(�ú�ɫ��ͻ����ʾ)ʵ�ָ��õ�����롣ͷ�ؽ����ģ�Ϳ���ѧϰ����ʹ������ 3D ģ��ѧϰ��������һ���õ�����,�����������ڴ� 2D ģ����ѧϰ��������,����������̫�ദ���ٶȡ���һ�۲��һ��֧���˱��ĵļ���,��ʱ����Ϣ��ģ�ڶ������������������νṹ�Ķ�������Ч��
4.6 Spatio-temporal feature gating
����ͨ��ʹ�������ſؽ�һ�����ģ�͵�ȷ�ԡ����ȿ����״�������Ƶ����������������ſػ��ơ�����һ���ǽṹ����������������
x
��
R
n
x \in \mathcal{R}^{n}
x��Rn(ͨ���ڿ��� logit ���������Ƕ���ѧϰ),������һ�������������
y
��
R
n
y \in \mathcal{R}^{n}
y��Rn,������ʾ:
y
=
��
(
W
x
+
b
)
��
x
y=\sigma(W x+b) \odot x
y=��(Wx+b)��x
����
��
\odot
����ʾԪ�س˷�,
W
��
R
n
��
n
W \in \mathcal{R}^{n \times n}
W��Rn��n��Ȩ�ؾ���,
b
��
b \in
b��
R
n
\mathcal{R}^{n}
Rn��ƫ������������ģ��
��
(
W
x
+
b
)
\sigma(W x+b)
��(Wx+b)Ԥ��
x
x
x��ijЩά�Ⱥ���Ҫ,�û�������ģ�����
x
x
x��ijЩά�ȵ�Ȩ��,�����Ͳ����ά�ȵ�Ȩ��;����Ա���Ϊ��һ�֡���ע���������ơ�
���ڽ�����չ������ʱ�սṹ�������������� X �� X \in X�� R T �� W �� H �� D \mathcal{R}^{T \times W \times H \times D} RT��W��H��DΪ��������,�� Y Y YΪ��ͬ��״�����������������˻� W x W x Wx�滻Ϊ W pool ? ( X ) W \operatorname{pool}(X) Wpool(X),���гػ������� X X X�ڿռ��ʱ���ϵ�ά�Ƚ���ƽ���� (���߷�����Ƚ�����ռ���ʱ��ƽ��Ч�����á�)Ȼ����� Y = �� ( W pool ? ( X ) + Y=\sigma(W \operatorname{pool}(X)+ Y=��(Wpool(X)+ b) �� X \odot X ��X,���� �� \odot ����ʾ������(ͨ��)ά�ȵij˷�,(��,�ڿռ��ʱ���ϸ���ע����ͼ �� ( W pool ? ( X ) + b ) \sigma(W \operatorname{pool}(X)+b) ��(Wpool(X)+b)��
���Խ����ſ�ģ�����������κβ㡣�����˼���ѡ��,��ͨ���� S3D �����е�ÿ�� [k, 1, 1] ʱ�����֮��ֱ��Ӧ�����������ѽ����������ģ��(���ſص� S3D)��Ϊ S3D-G���ӱ� 2 �п���,�� Kinetics-Full ���ݼ��ϵ� S3D ���,�����ȷ�ȵĽ�������(��ǰ 1 �� 72.2% �� 74.7%),���ɱ����ӷdz��ʶ�(�� 66.38 GFLOPS �� 71.38)���� 3 ��ʾ S3D-G ��Something-something �ϵı���Ҳ����S3D ��I3D�����������ڵ�ǰ���Ƚ��ķ���,����߶� TRN,�� top-1 ȷ�ʴ� 33.6% ��ߵ� 42.0%��

