本篇文章提供来源: 【🌑(这是月亮的背面)】
灵感启发:Python进阶者大佬 的 盘点4种计算数组中元素值为1的个数方法
公众号整理不易,个人能力有限,特来邀请各位大哥大佬巨佬神仙们坐镇,并开设一个*午休专列*专栏,用来分享在各路收集到的,有着积极探讨过程的有趣知识点。在紧张学习之余换换思维,跳出思维陷阱,快乐学习。
系列文章说明:
系列名:本次分享的问题思考或者趣味知识
问题
统计一维数组中的元素数量,有着非常简便且完善的方法,而需要统计多维数组中的各元素该怎么办呢?
思考历程
在我经常使用的几个模块里,没有找到能够有效且简便的直接将多维数组中的元素进行统计,既然不能用直接法,就改为间接法,先将数组转换为一维数组再统计就方便多了,下面为几种例子,仅供参考:
二维数组:
- 数据准备
使用numpy固定随机种子,随机生成一个二维数组。
import numpy as np
import pandas as pd
np.random.seed(2022) # 设定随机种子
a = np.random.randint(0, 10, (100, 3)) # 100*3的二维数组
- 统计元素
numpy是没有统计元素的方法,需要借助其他的方法进行统计,为了简单起见,这里使用collections模块下的Counter类进行统计。
from collections import Counter
# Counter不能直接对numpy.array进行统计
# 使用.flatten方法将其摊平
Counter(a.flatten())
# 或者使用.flat转成numpy.flatiter可迭代对象
Counter(a.flat)

在统计元素方面也比较容易的想到pandas的value_counts,由于value_counts也只能统计一列中的元素数量,此时可以在value_counts之前使用melt方法,将多列数据转换为一维类型的。
# melt后的列名为value,此时对value列进行value_counts
pd.DataFrame(a).melt().value_counts('value')

各个数字对应的数量与Counter的结果一致。
多维数组:
- 规则数组
np.random.seed(2022) # 设定随机种子
a = np.random.randint(0, 10, (10, 3, 4)) # 10*3*4的三维数组
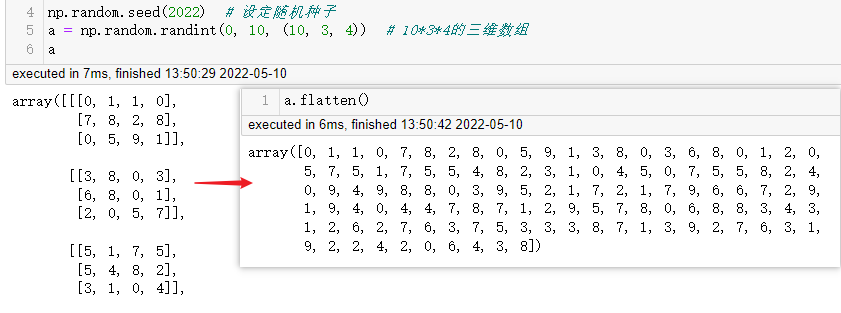
在numpy里只要数组组成是非常规范的,如每个组成部分的大小都是一致的,如上方生成的三维数组是由10个3*4的二维数组组成,可以使用.flatten()非常方便的将其转换为一维数组,再统计各个元素数量,更高维度的数组类似。
pandas对于数组能否转换为pandas的数组结构对象有着一定标准,仅能将二维数组转换为pandas对象,所以不能将多维数组转换后再统计。
- 不规则数组
当多维数组组成不规则,如列表嵌套多个列表,这样的数组类型使用numpy.flatten()就不能比较方便地摊开成一维数组。
list_b = [[[1, 2, 3, 4, [1, 2, 3, 4, [1, 2, 3, 4, [1, 2, 3, 4]], 6, 7], 8, 9, [1, 2, 3, 4, [1, 2, 3, 4]], 6, 7]]]
# 需要将内嵌列表作为元素设置
np.array(list_b, dtype='O').flatten()
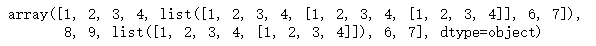
这样的结果显然不能再通过Counter进行计数。
可以考虑定义一个函数,对列表进行摊开:
def flatten(values):
# 在递归前先调用生成numpy.flatiter迭代对象
values = np.array(values, dtype='O').flat
for value in values:
if isinstance(value, (list, np.ndarray)):
yield from flatten(value)
else:
yield value
对多维数组里进行遍历,如果元素为列表或者数组,递归返回,否则返回当前遍历的元素,在开始遍历之前可以先将这个数组转换为numpy.flatiter可迭代对象,这个意义可以解决当处理numpy.matrix矩阵对象出现迭代递归深度问题。

上图为没有先转换为numpy.flatiter可迭代对象前处理矩阵的运行情况。可以看到矩阵的大小仅为3*3时,仍然会报错。
此时调用定义的flatten函数可以轻松地统计list_b中各个元素的数量:

对于这样的多维数组可尝试着用pandas.value_counts计数,先通过调用flatten函数再进行统计。
pd.DataFrame(list_b).stack().map(flatten).map(tuple).explode().value_counts()

这里的stack与melt类似,生成的为Series对象,再链式调用各个方法、函数完成数据的统计。
总结
以上就是经常使用的模块对多维数组进行数据统计的思考,思考的广度深度也许都不够,也仅是我个人的片面之词,难断优劣,通过一个问题能够让大脑转动起来,努力挖掘知识,也是一种快乐之举。
半日阳半日雨,青苔绿阶,艳花满地。
于二零二二年五月十日作

