摘要
目前,基于体素的3D单级检测器已经有很多种,而基于点的单级检测器仍处于探索阶段。在本文中,我们首先提出了一种轻量级且有效的基于点的3D单级目标检测器,名为3DSSD,在精度和效率之间取得了很好的平衡。在这种范式中,所有现有的基于点的方法中必不可少的所有上采样层和细化阶段都被放弃,以减少大量的计算成本。我们在下采样过程中新颖地提出了一种融合采样策略,以使对较少代表性点的检测变得可行。为了满足预测精度和速度的要求,设计了一个精确的框预测网络,包括候选生成层、anchor-free回归头和三维中心度分配策略。我们的范例是一个优雅的单阶段anchor-free框架,与其他现有方法相比具有极大的优势。我们在广泛使用的KITTI数据集和更具挑战性的nuScenes数据集上评估3DSSD。我们的方法在很大程度上优于所有基于最先进体素的单阶段方法,并且与基于两阶段点的方法具有相当的性能,推理速度超过25 FPS,比以前最先进的基于点的方法快2倍。
1.介绍
近年来,三维场景理解在计算机视觉中引起了越来越多的关注,因为它有利于许多实际应用,如自动驾驶[8]和增强现实[20]。在本文中,我们关注3D场景识别中的一个基本任务,即3D目标检测,它预测点云中每个实例的3D边界框和类标签。
尽管在二维检测方面取得了重大突破,但由于点云的独特特性,将这些二维方法直接转换为三维方法是不合适的。与二维图像相比,点云是稀疏的、无序的和局部敏感的,因此不可能使用卷积神经网络(CNNs)来解析它们。因此,如何转换和利用原始点云数据已成为检测任务中的首要问题。
一些现有方法通过将点云投影到图像[4,12,9,21,6]或将其细分为均匀分布的体素[19,29,36,32,31,13],将点云从稀疏形式转换为紧凑表示。我们称这些方法为基于体素的方法,在整个点云上进行体素化。每个体素中的特征由类似点网的主干[24,25]或手工制作的特征生成。然后,许多2D检测范例可以应用于紧凑的体素空间,而无需任何额外的努力。虽然这些方法简单有效,但在体素化过程中会出现信息丢失,并遇到性能瓶颈。
另一个主流是基于点的方法,例如[34, 35, 26]。他们将原始点云作为输入,并根据每个点预测边界框。具体来说,它们由两个阶段组成。在第一阶段,他们首先利用集合抽象(SA)层进行下采样和提取上下文特征。之后,特征传播(FP)层被应用于上采样并将特征广播到在下采样期间被丢弃的点。然后应用3D区域proposal网络(RPN)来生成以每个点为中心的proposals。基于这些proposals,开发了一个细化模块作为第二阶段以给出最终预测。这些方法实现了更好的性能,但它们的推理时间在许多实时系统中通常是不能容忍的。
我们的贡献 与以往的方法不同,我们首先开发了一个轻量级、高效的基于点的三维单级目标检测框架。我们观察到,在基于点的方法中,FP层和细化阶段消耗了一半的推理时间,这促使我们删除这两个模块。然而,放弃FP层并非易事。由于在SA中当前的采样策略下,即基于3D欧几里德距离(D-FPS)的最远点采样,具有少量内部点的前景实例在采样后可能会丢失所有点。因此,它们不可能被检测到,从而导致性能大幅下降。在STD[35]中,如果不进行上采样,即对剩余的下采样点进行检测,其性能将下降约9%。这就是为什么必须采用FP层进行点上采样的原因,尽管会引入大量额外计算。为了解决这个难题,我们首先提出了一种新的基于特征距离的采样策略,称为F-FPS,它有效地保留了各种实例的内部点。我们的最终采样策略是F-FPS和DFPS的融合版本。
为了充分利用SA层后保留的代表点,我们设计了一个精细的框预测网络,该网络利用候选生成层(CG)、anchor-free回归头和3D 中心分配策略。在CG层,我们首先将代表点从F-FPS转移到生成候选点。这种移动操作由这些代表点与其对应实例的中心之间的相对位置进行监督。然后,我们将这些候选点作为中心,从F-FPS和D-FPS的整个代表点集合中找到它们的周围点,并通过多层感知器(MLP)网络提取它们的特征。这些特征最终被输入到anchor-free回归头中以预测3D边界框。我们还设计了一种3D中心分配策略,将更高的分类分数分配给更接近实例中心的候选点,以便检索更精确的定位预测。
我们在广泛使用的KITTI[7]数据集和更具挑战性的nuScenes[3]数据集上评估我们的方法。实验表明,我们的模型在很大程度上优于所有最先进的基于体素的单阶段方法,以更快的推理速度实现了与所有两阶段基于点的方法相当的性能。总之,我们的主要贡献是多方面的。
-
我们首先提出了一种轻量级且有效的基于点的3D单级目标检测器,名为3DSSD。在我们的范例中,我们删除了FP层和细化模块,这在所有现有的基于点的方法中都是必不可少的,从而大大减少了我们框架的推理时间。
-
在SA层中开发了一种新的融合采样策略,以保留不同前景实例的足够内部点,从而为回归和分类保留丰富的信息。
-
我们设计了一个精致的框预测网络,使我们的框架更加有效和高效。在KITTI和nuScenes数据集上的实验结果表明,我们的框架优于所有单阶段方法,并且具有与最先进的两阶段方法相当的性能,速度更快,每个场景为38毫秒。
2.相关工作
使用多个传感器进行3D目标检测 有几种方法可以利用如何融合来自多个传感器的信息来进行目标检测。 MV3D[4]将LiDAR点云投影到鸟瞰图(BEV)以生成proposals。然后将这些带有来自图像、前视图和BEV的其他信息的proposals发送到第二阶段以预测最终的边界框。AVOD[12]通过在proposal生成阶段引入图像特征来扩展MV3D。 MMF[16]融合来自深度图、LiDAR点云、图像和地图的信息,以完成包括深度补全、2D目标检测和3D目标检测在内的多项任务。这些任务相互受益,并提高了3D目标检测的最终性能。
仅使用LiDAR进行3D目标检测 仅使用LiDAR数据处理3D目标检测的方法主要有两种。一种是基于体素的,它将体素化应用于整个点云。基于体素的方法之间的区别在于体素特征的初始化。在[29]中,每个非空体素由该体素内的点用6个统计量编码。[15]中对每个体素网格使用二进制编码。 VoxelNet[36]利用PointNet[24]来提取每个体素的特征。与[36]相比,SECOND[31]应用稀疏卷积层[10]来解析紧凑表示。 PointPillars[13]将伪图像视为体素化后的表示。
另一种是基于点的。他们将原始点云作为输入,并根据每个点生成预测。FPointNet[23]和IPOD[34]采用检测或分割等二维机制来过滤大多数无用点,并从这些保留的有用点生成预测。PointRCNN[26]利用带有SA和FP层的PointNet++[25]来提取每个点的特征,提出一个区域proposal网络(RPN)来生成proposal,并应用一个细化模块来预测边界框和类标签。这些方法优于基于体素的方法,但它们难以忍受的推理时间使其无法应用于实时自动驾驶系统。STD[35]试图利用基于点和基于体素的方法。它使用原始点云作为输入,应用PointNet++提取特征,提出PointsPool层将特征从稀疏表示转换为密集表示,并在细化模块中利用CNN。尽管它比以前所有基于点的方法都快,但它仍然比基于体素的方法慢得多。如前所述,所有基于点的方法都由两个阶段组成,即包括SA层和FP层的proposal生成模块,以及作为准确预测的第二阶段的细化模块。在本文中,我们建议删除FP层和细化模块,以加快基于点的方法。
3.我们的框架
在本节中,我们首先分析基于点的方法的瓶颈,并描述我们提出的融合采样策略。接下来,我们展示了框预测网络,包括候选生成层、anchor-free回归头和我们的3D中心分配策略。最后,我们讨论损失函数。3DSSD的整个框架如图1所示。
3.1.融合采样
Motivation 目前,在3D目标检测中有两种方法为主流,即基于点的框架和基于体素的框架。尽管准确,但与基于体素的方法相比,基于点的方法更耗时。我们观察到当前所有基于点的方法[35,26,34]都由两个阶段组成,包括proposal生成阶段和预测细化阶段了。在第一阶段,SA层被应用于下采样点以提高效率并扩大感受野,而FP层被应用于在下采样过程中对丢弃的点进行广播特征,以恢复所有点。在第二阶段,一个细化模块优化来自RPN的proposals以获得更准确的预测。SA层是提取点特征所必需的,但FP层和细化模块确实限制了基于点的方法的效率,如表1所示。因此,我们有Motivation设计一种轻量级且有效的基于点的单级检测器。
表1.我们复制的PointRCNN[26]模型中差异组件的运行时间,该模型由4个SA层和4个FP层用于特征提取,以及一个具有3个SA层用于预测的细化模块。
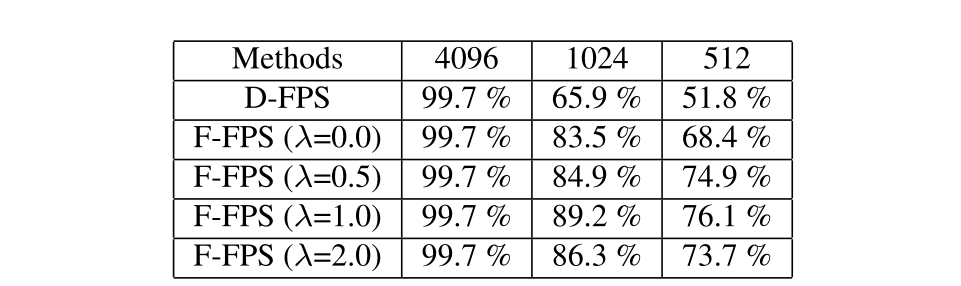
表2.nuScenes数据集上不同采样策略的点召回率。 “4096”、“1024”和“512”代表子集中代表点的数量。

挑战 但是,移除FP层并非易事。如前所述,主干中的SA层利用D-FPS选择点的子集作为下采样的代表点。在没有 FP层的情况下,框预测网络是在那些幸存的代表点上进行的。尽管如此,这种采样方法只考虑了点之间的相对位置。因此,由于数量众多,大部分幸存的代表点实际上是背景点,如地面点。换句话说,有几个前景实例在此过程中被完全擦除,使其无法被检测到。
在代表点总数 N m N_{m} Nm?的限制下,对于一些偏远的实例,它们的内部点不太可能被选中,因为它们的数量远小于背景点。在更复杂的数据集(如 nuScenes [3] 数据集)上,情况变得更糟。从统计上讲,我们使用点召回――内部点在采样代表点中幸存的实例数与实例总数之间的商,以帮助说明这一事实。如表2第一行所示,在1024或512个代表点的情况下,它们的点召回率分别仅为65.9%或51.8%,这意味着近一半的实例被完全擦除,即无法检测到。为了避免这种情况,大多数现有的方法在下采样过程中应用FP层来召回那些被放弃的有用的点,但是他们必须付出更长的推理时间的计算开销。
Feature-FPS 为了保留positive的点(任何实例中的内部点)并消除那些无意义的negative点(位于背景上的点),我们在采样过程中不仅要考虑空间距离,还要考虑每个点的语义信息。我们注意到,语义信息可以被深度神经网络很好地捕获。因此,利用特征距离作为FPS的标准,许多类似的无用的negative点将被大部分删除,比如大量的地面点。即使是远处目标的positive点,它们也可以得到幸存,因为来自不同目标的点的语义特征是彼此不同的。
然而,只把语义特征距离作为唯一的标准,会保留同一实例中的许多点,这也引入了冗余的情况。例如,给定一辆汽车,车窗和车轮周围的点的特征有很大的不同。因此,这两个部分周围的点将被抽样,而任何一个部分的点都是回归的信息。为了减少冗余并增加多样性,我们同时应用空间距离和语义特征距离作为FPS的标准。它被表述为
C
(
A
,
B
)
=
λ
L
d
(
A
,
B
)
+
L
f
(
A
,
B
)
,
(
1
)
C(A, B)=\lambda L_{d}(A, B)+L_{f}(A, B), \quad\quad\quad\quad(1)
C(A,B)=λLd?(A,B)+Lf?(A,B),(1)
其中
L
d
(
A
,
B
)
L_{d}(A, B)
Ld?(A,B)和
L
f
(
A
,
B
)
L_{f}(A, B)
Lf?(A,B)代表两点之间的L2XYZ距离和L2特征距离,
λ
\lambda
λ是平衡因子。我们把这种采样方法称为Feature-FPS(F-FPS)。表2显示了不同
λ
\lambda
λ之间的比较,这表明在下采样操作中,将两个距离结合在一起作为标准,比只使用特征距离(即
λ
\lambda
λ等于0的特殊情况)更有力。此外,如表2所示,在nuScenes[3]数据集中,使用F-FPS的1024个代表点和
λ
\lambda
λ设置为1,可以保证89.2%的实例被保留下来,比D-FPS采样策略高23.3%。
融合取样 由于F-FPS的作用,不同实例中的大量positive点在SA层之后被保留下来。然而,在固定的代表点数 N m N_{m} Nm?的限制下,许多negative点在下采样过程中被丢弃,这有利于回归,但阻碍了分类。也就是说,在SA层的分组阶段,即从相邻点聚集特征的阶段,一个negative点无法找到足够的周围点,使得它无法扩大其感受野。因此,该模型难以区分positive点和negative点,导致分类性能不佳。我们的实验也证明了消融研究中的这种局限性。尽管采用F-FPS的模型比采用D-FPS的模型有更高的召回率和更好的定位精度,但它更倾向于把许多negative点当作positive点,导致分类精度下降。
正如上文所分析的,在SA层之后,不仅要尽可能多地对positive点进行采样,而且还要收集足够多的negative点,以便进行更可靠的分类。我们提出了一种新的融合采样策略(FS),即在SA层中同时使用F-FPS和D-FPS,以保留更多的positive点用于定位,同时也保留足够的negative点用于分类。具体来说,我们用F-FPS和D-FPS分别对 N m 2 \frac{N_{m}}{2} 2Nm??的点进行采样,并将这两组点一起送入SA层的以下分组操作中。
3.2.框预测网络
Candidate Generation Layer 在由几个SA层与融合采样交织实现的骨干网络之后,我们从F-FPS和D-FPS中获得一个点子集,用于最终预测。在以前的基于点的方法中,应该在预测头之前应用另一个SA层来提取特征。普通的SA层有三个步骤,包括中心点选择、周围点提取和语义特征生成。
为了进一步降低计算成本,充分发挥融合采样的优势,我们在预测头之前提出了一个候选生成层(CG),它是SA层的一个变种。由于来自D-FPS的大多数代表点都是负点并且在边界框回归中无用,因此我们只使用来自F-FPS的那些作为初始中心点。如图2所示,这些初始中心点在其相对位置的监督下被转移到其相应的实例中,这与VoteNet[22]相同。我们把这些经过移位(shifting)操作的新点称为候选点。然后,我们将这些候选点作为我们CG层的中心点。出于性能的考虑,我们使用候选点而不是原始点作为中心点,这将在后面详细讨论。接下来,我们从包含D-FPS和F-FPS的点的整个代表性点集中,以预先定义的范围阈值找到每个候选点的周围点,将它们的归一化位置和语义特征连接起来作为输入,并应用MLP层来提取特征。这些特征将被送到预测头进行回归和分类。整个过程如图1所示。
图1.3DSSD框架示意图。总体而言,它由主干和框预测网络组成,包括候选生成层和anchor-free预测头。(a)骨干网络。它以原始点云 ( x , y , z , r ) (x, y, z, r) (x,y,z,r)作为输入,并使用融合采样(FS)策略通过几个SA层为所有代表点生成全局特征。(b)候选生成层(CG)。它在SA层之后对代表点进行下采样、移位和提取特征。?anchor-free预测头。
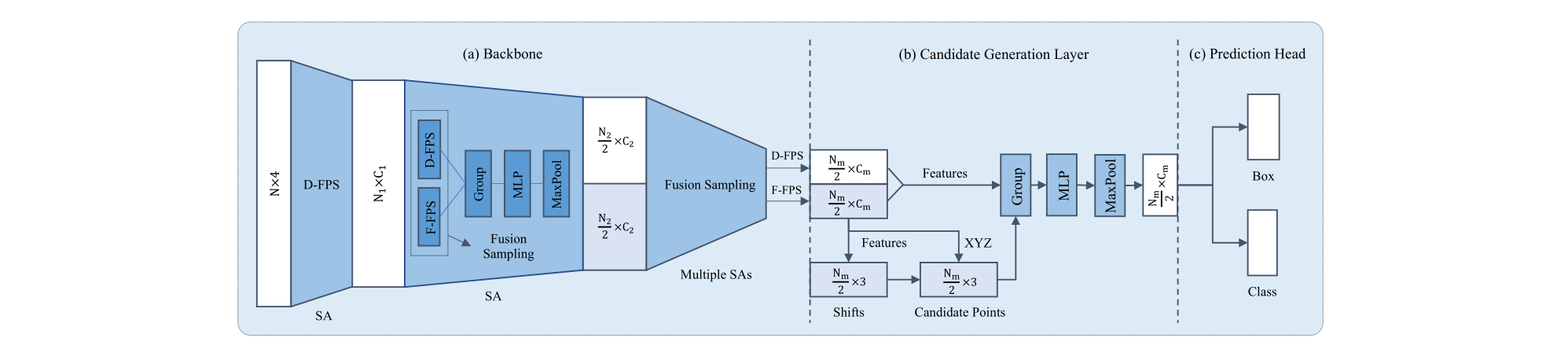
图2.CG层中的移位(shifting)操作示意图。灰色矩形表示具有F-FPS(绿色)和D-FPS(蓝色)的所有正代表点的实例。红点代表实例中心。我们只在F-FPS到实例中心距离的监督下将点从F-FPS转移。
Anchor-free Regression Head 通过融合采样策略和CG层,我们的模型可以安全地移除耗时的FP层和细化模块。在回归头中,我们面临两个选择,基于anchor的预测网络或anchor-free预测网络。如果采用anchor-based head,我们必须构建多尺度和多方向的anchors,以覆盖不同大小和方向的目标。特别是在像nuScenes数据集[3]中的复杂场景中,其中目标来自10个不同类别且具有广泛的方向,我们需要至少20个anchors,包括10个不同的大小和2个不同的方向(0,π/2)在基于anchor的模型中。为了避免多个anchors的繁琐设置并与我们的轻量级设计保持一致,我们使用anchor-free回归头。
在回归头中,对于每个候选点,我们预测到其对应实例的距离 ( d x , d y , d z ) (d_{x}, d_{y}, d_{z}) (dx?,dy?,dz?),以及其对应实例的大小 ( d l , d w , d h ) (d_{l}, d_{w}, d_{h}) (dl?,dw?,dh?)和方向。由于每个点没有先验的方向,我们在方向角回归中采用了分类和回归的混合表述方式,遵循[23]。具体来说,我们预先定义了 N a N_{a} Na?等分的方向角bins,并将提议的方向角分类到不同的bins中。残差相对于bin值进行回归。在我们的实验中, N a N_{a} Na?设置为12。
3D中心分配策略 在训练过程中,我们需要一个分配策略来为每个候选点分配标签。在2D单级检测器中,它们通常使用交叉联合(IoU)[18]阈值或掩码[28, 33]来为像素分配标签。FCOS[28]提出了一个连续的中心标签,代替原来的二元分类标签,以进一步区分像素。它将更高的中心度分数分配给更接近实例中心的像素,与基于IoU或基于掩码的分配策略相比,其性能相对更好。然而,直接将中心标签应用于3D检测任务并不令人满意。鉴于所有LiDAR点都位于目标的表面上,它们的中心标签都非常小且相似,这使得无法将好的预测与其他点区分开来。
我们没有利用点云中的原始代表点,而是求助于预测的候选点,这些候选点被监督为靠近实例中心。靠近实例中心的候选点往往会获得更准确的定位预测,并且3D中心标签能够轻松区分它们。对于每个候选点,我们通过两个步骤定义其中心标签。我们首先确定它是否在一个实例 l m a s k l_{mask} lmask?内,它是一个二进制值。然后我们根据它到其对应实例的6个表面的距离绘制一个center-ness标签。中心标签计算为
l
ctrness?
=
min
?
(
f
,
b
)
max
?
(
f
,
b
)
×
min
?
(
l
,
r
)
max
?
(
l
,
r
)
×
min
?
(
t
,
d
)
max
?
(
t
,
d
)
3
,
(
2
)
l_{\text {ctrness }}=\sqrt[3]{\frac{\min (f, b)}{\max (f, b)} \times \frac{\min (l, r)}{\max (l, r)} \times \frac{\min (t, d)}{\max (t, d)}}, \quad\quad\quad\quad(2)
lctrness??=3max(f,b)min(f,b)?×max(l,r)min(l,r)?×max(t,d)min(t,d)??,(2)
其中
(
f
,
b
,
l
,
r
,
t
,
d
)
(f, b, l, r, t, d)
(f,b,l,r,t,d)分别表示到前、后、左、右、顶和底表面的距离。最终的分类标签是
l
m
a
s
k
l_{mask}
lmask?和
l
c
t
r
n
e
s
s
l_{ctrness}
lctrness?的乘积。
3.3.Loss Function
整体损失由分类损失、回归损失和移动(shifting)损失组成,为
L
=
1
N
c
∑
i
L
c
(
s
i
,
u
i
)
+
λ
1
1
N
p
∑
i
[
u
i
>
0
]
L
r
+
λ
2
1
N
p
?
L
s
,
(
3
)
\begin{aligned} L=& \frac{1}{N_{c}} \sum_{i} L_{c}\left(s_{i}, u_{i}\right)+\lambda_{1} \frac{1}{N_{p}} \sum_{i}\left[u_{i}>0\right] L_{r} \\ &+\lambda_{2} \frac{1}{N_{p}^{*}} L_{s} \end{aligned}, \quad\quad\quad\quad\quad\quad(3)
L=?Nc?1?i∑?Lc?(si?,ui?)+λ1?Np?1?i∑?[ui?>0]Lr?+λ2?Np??1?Ls??,(3)
其中 N c N_{c} Nc?和 N p N_{p} Np?是总候选点和正(positive)候选点的数量,它们是位于前景实例中的候选点。在分类损失中,我们将 s i s_{i} si?和 u i u_{i} ui?分别表示为点 i i i的预测分类分数和中心度标签,并使用交叉熵损失作为 L c L_{c} Lc?。
回归损失
L
r
L_{r}
Lr?包括距离回归损失
L
d
i
s
t
L_{dist}
Ldist?、尺寸回归损失
L
s
i
z
e
L_{size}
Lsize?、角度回归损失
L
a
n
g
l
e
L_{angle}
Langle?和角点损失
L
c
o
r
n
e
r
L_{corner}
Lcorner?。具体来说,我们对
L
d
i
s
t
L_{dist}
Ldist?和
L
s
i
z
e
L_{size}
Lsize?使用了
s
m
o
o
t
h
?
l
1
smooth-l_{1}
smooth?l1?损失,其中目标分别是从候选点到其对应实例中心的偏移量和对应实例的大小。角度回归损失包含方向分类损失和残差预测损失为
L
a
n
g
l
e
=
L
c
(
d
c
a
,
t
c
a
)
+
D
(
d
r
a
,
t
r
a
)
,
(
4
)
L_{a n g l e}=L_{c}\left(d_{c}^{a}, t_{c}^{a}\right)+D\left(d_{r}^{a}, t_{r}^{a}\right),\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(4)
Langle?=Lc?(dca?,tca?)+D(dra?,tra?),(4)
其中
d
c
a
d_{c}^{a}
dca?和
d
c
r
d_{c}^{r}
dcr?是预测的角度类别和残差,而
t
c
a
t_{c}^{a}
tca?和
t
r
a
t_{r}^{a}
tra?是它们的目标。角点损失是预测的8个角点与指定的ground-truth之间的距离,表示为
L
c
o
r
n
e
r
=
∑
m
=
1
8
∥
P
m
?
G
m
∥
,
(
5
)
L_{c o r n e r}=\sum_{m=1}^{8}\left\|P_{m}-G_{m}\right\|,\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(5)
Lcorner?=m=1∑8?∥Pm??Gm?∥,(5)
其中
P
m
P_{m}
Pm?和
G
m
G_{m}
Gm?是ground-truth的位置和点
m
m
m的预测。
至于转移损失 L s L_{s} Ls?,它是CG层中移位预测的监督,我们利用一个 s m o o t h ? l 1 smooth-l_{1} smooth?l1?损失来计算预测的移位(shifting)和从代表点到其对应实例中心的残差之间的距离。 N p ? N_{p}^{*} Np??是来自F-FPS的positive代表点的数量。
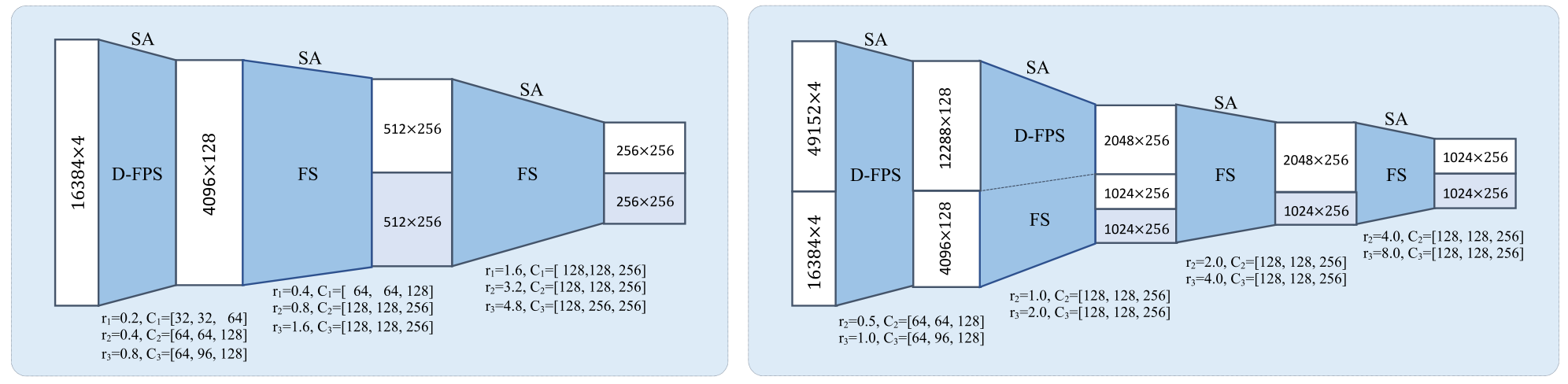
图3.KITTI(左)和nuScenes(右)数据集上的3DSSD骨干网络。
4.实验
我们在两个数据集上评估我们的模型:广泛使用的KITTI目标检测基准[7, 8]和更大、更复杂的nuScenes数据集[3]。
4.1. KITTI
KITTI数据集中共有7,481个训练图像/点云和7,518个测试图像/点云,分为Car、Pedestrian和Cyclist三个类别。由于数据量大、场景复杂,我们只在 Car 类上评估我们的模型。此外,大多数最先进的方法只在这个类上测试他们的模型。我们使用平均精度 (AP) 指标与不同的方法进行比较。在评估过程中,我们遵循官方的KITTI评估协议――即Car类的IoU阈值为0.7。
实施细节 为了对齐网络输入,我们从每个场景的整个点云中随机选择16k个点。骨干网络的细节如图3所示。网络由ADAM[11]优化器训练,初始学习率为0.002,批量大小为16,平均分布在4个GPU卡上。学习率在40个epoch时衰减10。我们训练我们的模型50个epoch。
我们在KITTI数据集上采用了4种不同的数据增强策略,以防止过度拟合。首先,我们使用与[31]相同的混合策略,将前景实例及其内部点从其他场景随机添加到当前点云中。然后,对于每个边界框,我们按照均匀分布 Δ θ 1 ∈ [ ? π / 4 , + π / 4 ] \Delta \theta_{1} \in[-\pi / 4,+\pi / 4] Δθ1?∈[?π/4,+π/4]对其进行旋转,并添加随机平移 ( Δ x , Δ y , Δ z ) (\Delta x, \Delta y, \Delta z) (Δx,Δy,Δz)。第三,每个点云沿 x x x轴随机翻转。最后,我们围绕 z z z轴(上轴)随机旋转每个点云并重新缩放它。
表3.来自官方Benchmark[1]的Car类的KITTI测试集结果。 “Sens.”表示该方法使用的传感器。 “L”和“R”分别表示使用LiDAR和RGB图像。
表4. nuScenes数据集上的AP。 SECOND的结果来自其官方实现[2]。
表5.nuScenes数据集上的NDS。“PP”代表PointPillars。
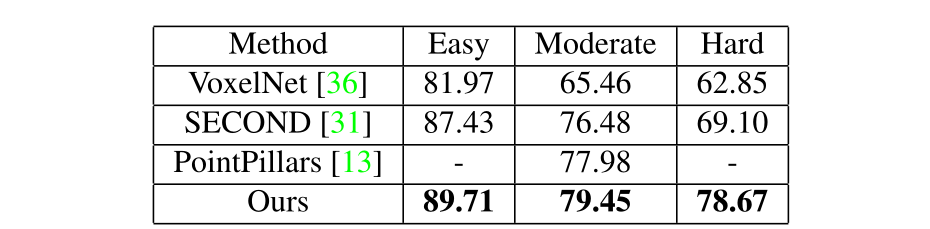
表6. 与其他最先进的单阶段方法相比,我们的“Car”模型的KITTI val集上的3D检测AP。
表7.不同采样方法的点召回率和AP。
表8.不同分配策略中的AP。“with shift”是指在CG层中使用shift。
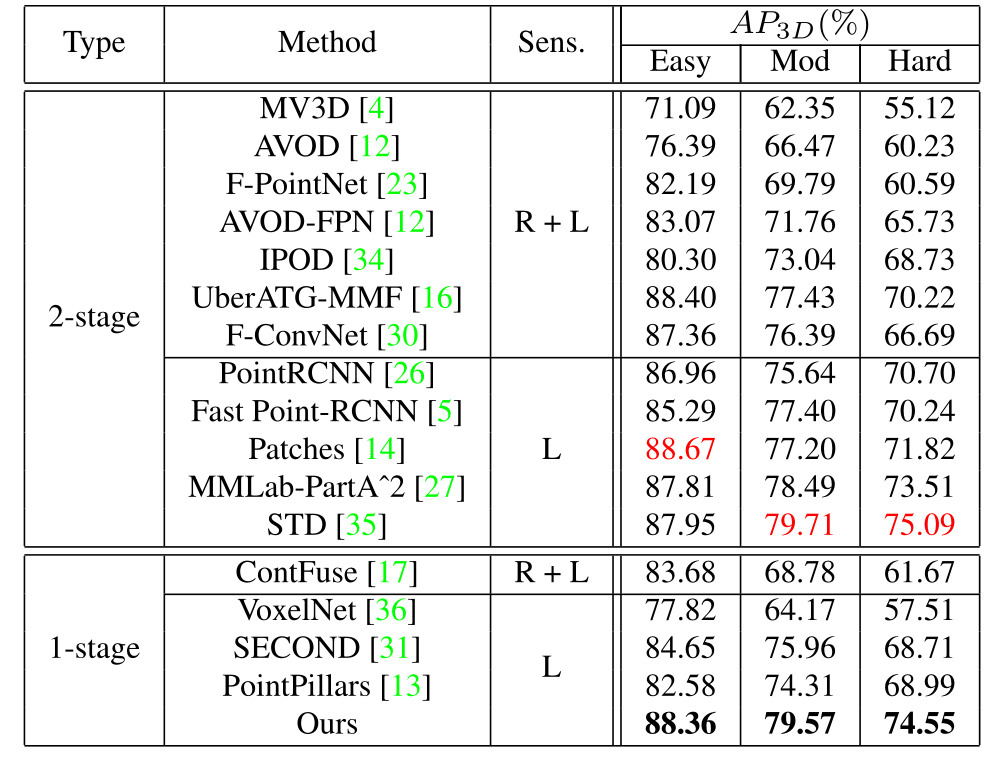




主要结果 如表3所示,我们的方法大大优于所有最先进的基于体素的单级检测器。在主要指标上,即“moderate”实例上的AP,我们的方法分别优于SECOND[31]和PointPillars[13]3.61%和5.26%。尽管如此,它仍然保留了与基于状态点的方法STD[35]相当的性能,推理时间快了2倍以上。我们的方法仍然比其他两个阶段的方法,如part-A^2 net和PointRCNN分别高出1.08%和3.93%。此外,与MMF[16]和F-ConvNet[30]等多传感器方法相比,它还显示出其优势,分别实现了约2.14%和3.18%的改进。我们在图4中展示了几个定性结果。
4.2.nuScenes
nuScenes数据集是一个更具挑战性的数据集。它包含1000个场景,这些场景来自波士顿和新加坡,因为它们的交通密集且驾驶环境极具挑战性。它为我们提供了10个不同类别的140万个3D目标,以及它们的属性和速度。每帧大约有40k点,为了预测速度和属性,以前的所有方法都将关键帧和最近0.5秒内的帧的点结合起来,得到大约400k点。面对如此大量的点,由于GPU内存的限制,所有基于点的两阶段方法在该数据集上的表现都比基于体素的方法差。在基准测试中,提出了一种新的评估指标,称为nuScenes检测分数(NDS),它是平均精度(mAP)、位置平均误差(mATE)、尺寸(mASE)、方向(mAOE)之间的加权和)、属性(mAAE)和速度(mAVE)。我们用TP表示五个平均误差的集合,NDS的计算公式为
N
D
S
=
1
10
[
5
m
A
P
+
∑
m
T
P
∈
T
P
(
1
?
min
?
(
1
,
m
T
P
)
)
]
.
(
6
)
N D S=\frac{1}{10}\left[5 m A P+\sum_{m T P \in T P}(1-\min (1, m T P))\right].\quad\quad\quad\quad\quad\quad(6)
NDS=101?[5mAP+mTP∈TP∑?(1?min(1,mTP))].(6)
实施细节 对于每个关键帧,我们将其点与最近0.5秒内的帧中点进行组合,以获得更丰富的点云输入,与其他方法相同。然后,我们对随机采样点云应用体素化,以对齐输入并保持原始分布。我们随机选择65536个体素,包括16384个来自关键帧的体素和49152个来自其他帧的体素。体素大小为[0.1,0.1,0.1],从每个体素中随机选择1个内部点。我们将这65536个点输入到基于点的网络中。
骨干网络如图3所示。训练时间表与KITTI数据集上的时间表相同。我们只在训练期间应用翻转增强。
主要结果 我们在表5中展示了不同方法之间的NDS和mAP,并在表4中比较了它们在每个类别中的AP。如表5所示,与所有基于体素的单阶段方法相比,我们的方法在很大程度上获得了更好的性能。不仅在mAP上,它在每个类的AP上也优于那些方法,如表4所示。结果表明,我们的模型可以处理规模差异很大的不同目标。即使对于一个有很多negative点的巨大场景,我们的融合采样策略仍然有能力收集到足够多的positive点。此外,速度和属性的更好结果表明我们的模型还可以区分来自不同帧的信息。
图4.3DSSD在KITTI(上)和nuScenes(下)数据集上的定性结果。基本事实和预测分别标记为红色和绿色。
图5.融合采样(上)和仅D-FPS(下)后的代表点之间的比较。整个点云和所有代表点分别用白色和黄色着色。红点代表正代表点。
表9.不同基于点的方法之间的推理时间。



4.3.消融研究
所有消融研究都是在KITTI数据集[7]上进行的。我们按照VoxelNet[36]将原始训练集拆分为3,717个图像/场景训练集和3,769个图像/场景验证集。消融研究中的所有“AP”结果均按“Moderate”难度级别计算。
验证集上的结果 我们在表6中报告并比较了我们的方法在KITTI验证集上与其他最先进的基于体素的单阶段方法的性能。如图所示,在最重要的“moderate”难度级别上,我们的方法优于1.47 %、2.97%和13.99%分别与PointPillars、SECOND和VoxelNet相比。这说明了我们方法的优越性。
融合采样策略的效果 我们的融合采样策略由F-FPS和D-FPS组成。我们在表7中比较了不同子采样方法中的点召回率和AP。包含F-FPS的采样策略比仅D-FPS具有更高的点召回率。在图5中,我们还展示了一些视觉示例来说明F-FPS对融合采样的好处。此外,融合采样策略获得了更高的AP,即比仅使用F-FPS的策略好2.7%。原因是融合采样方法可以收集到足够多的negative点,扩大了感受野,达到了准确的分类结果。
CG层的Shifting效果 在表8中,我们比较了在CG层中从F-FPS转移代表点或不转移代表点的性能。在不同的分配策略下,有移位模型的AP都高于没有移位操作的模型。如果候选点更接近实例的中心,它们将更容易检索到它们对应的实例。
3D中心度分配的效果 我们比较了不同分配策略的性能,包括IoU、掩码和3D中心标签。如表8所示,通过移位操作,使用中心标签的模型比其他两种策略获得更好的性能。
推理时间 3DSSD的总推理时间为38毫秒,在KITTI数据集上使用Titan V GPU进行了测试。我们在表9中比较了3DSSD和所有现有的基于点的方法之间的推理时间。如图所示,我们的方法比所有现有的基于点的方法快得多。此外,与最先进的基于体素的单阶段方法(如40毫秒的SECOND)相比,我们的方法保持了相似的推理速度。在所有现有方法中,它仅比PointPillars慢,后者通过TensorRT等多项实现优化得到增强,我们的方法也可以利用这些优化来实现更快的推理速度。
5.结论
在本文中,我们首先提出了一种轻量级且高效的基于点的3D单阶段目标检测框架。我们引入了一种新的融合采样策略来去除所有现有基于点的方法中耗时的FP层和细化模块。在预测网络中,候选生成层旨在进一步降低计算成本并充分利用下采样的代表点,并提出了具有3D中心标签的anchor-free回归头以提高模型的性能。以上所有精致的设计使我们的模型在性能和推理时间上都优于所有现有的单级3D检测器。
原文连接:https://arxiv.org/abs/2002.10187
References
[1] ”kitti 3d object detection benchmark”. http: //www.cvlibs.net/datasets/kitti/eval_ object.php?obj_benchmark=3d, 2019. 6
[2] ”second github code”. https://github.com/ traveller59/second.pytorch, 2019. 7
[3] Holger Caesar, V arun Bankiti, Alex H. Lang, Sourabh V ora, V enice Erin Liong, Qiang Xu, Anush Krishnan, Y u Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. arXiv preprint arXiv:1903.11027, 2019. 2, 3, 4, 5, 6
[4] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3d object detection network for autonomous driving. In CVPR, 2017. 1, 2, 6
[5] Yilun Chen, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Fast point r-cnn. In ICCV, 2019. 6
[6] Martin Engelcke, Dushyant Rao, Dominic Zeng Wang, Chi Hay Tong, and Ingmar Posner. V ote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In ICRA, 2017. 1
[7] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The KITTI dataset. I. J. Robotics Res., 2013. 2, 6, 7
[8] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the KITTI vision benchmark suite. In CVPR, 2012. 1, 6
[9] Alejandro González, Gabriel Villalonga, Jiaolong Xu, David Vázquez, Jaume Amores, and Antonio M. López. Multiview random forest of local experts combining RGB and LIDAR data for pedestrian detection. In IV, 2015. 1
[10] Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3d semantic segmentation with submanifold sparse convolutional networks. In CVPR, 2018. 2
[11] Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, 2014. 6
[12] Jason Ku, Melissa Mozifian, Jungwook Lee, Ali Harakeh, and Steven Lake Waslander. Joint 3d proposal generation and object detection from view aggregation. CoRR, 2017. 1, 2, 6
[13] Alex H Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. Pointpillars: Fast encoders for object detection from point clouds. CVPR, 2019. 1, 2, 6, 7
[14] Johannes Lehner, Andreas Mitterecker, Thomas Adler, Markus Hofmarcher, Bernhard Nessler, and Sepp Hochreiter. Patch refinement: Localized 3d object detection. arXiv preprint arXiv:1910.04093, 2019. 6
[15] Bo Li. 3d fully convolutional network for vehicle detection in point cloud. In IROS, 2017. 2
[16] Ming Liang*, Bin Yang*, Y un Chen, Rui Hu, and Raquel Urtasun. Multi-task multi-sensor fusion for 3d object detection. In CVPR, 2019. 2, 6
[17] Ming Liang, Bin Yang, Shenlong Wang, and Raquel Urtasun. Deep continuous fusion for multi-sensor 3d object detection. In ECCV, 2018. 6
[18] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott E. Reed, Cheng-Yang Fu, and Alexander C. Berg. SSD: single shot multibox detector. In ECCV, 2016. 5
[19] Daniel Maturana and Sebastian Scherer. V oxnet: A 3d convolutional neural network for real-time object recognition. In IROS, 2015. 1
[20] Y oungmin Park, Vincent Lepetit, and Woontack Woo. Multiple 3d object tracking for augmented reality. In ISMAR, 2008. 1
[21] Cristiano Premebida, Jo?ao Carreira, Jorge Batista, and Urbano Nunes. Pedestrian detection combining RGB and dense LIDAR data. In ICoR, 2014. 1
[22] Charles R. Qi, Or Litany, Kaiming He, and Leonidas J. Guibas. Deep hough voting for 3d object detection in point clouds. ICCV, 2019. 4
[23] Charles Ruizhongtai Qi, Wei Liu, Chenxia Wu, Hao Su, and Leonidas J. Guibas. Frustum pointnets for 3d object detection from RGB-D data. CoRR, 2017. 2, 5, 6, 8
[24] Charles Ruizhongtai Qi, Hao Su, Kaichun Mo, and Leonidas J. Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. In CVPR, 2017. 1, 2
[25] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NIPS, 2017. 1, 2
[26] Shaoshuai Shi, Xiaogang Wang, and Hongsheng Li. Pointrcnn: 3d object proposal generation and detection from point cloud. In CVPR, 2019. 1, 2, 3, 6, 8
[27] Shaoshuai Shi, Zhe Wang, Xiaogang Wang, and Hongsheng Li. Part-a?2 net: 3d part-aware and aggregation neural network for object detection from point cloud. arXiv preprint arXiv:1907.03670, 2019. 6
[28] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS: fully convolutional one-stage object detection. ICCV, 2019. 5
[29] Dominic Zeng Wang and Ingmar Posner. V oting for voting in online point cloud object detection. In Robotics: Science and Systems XI, 2015. 1, 2
[30] Zhixin Wang and Kui Jia. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In IROS. IEEE, 2019. 6
[31] Yan Yan, Y uxing Mao, and Bo Li. Second: Sparsely embedded convolutional detection. Sensors, 2018. 1, 2, 6, 7
[32] Bin Yang, Wenjie Luo, and Raquel Urtasun. PIXOR: realtime 3d object detection from point clouds. In CVPR, 2018. 1
[33] Ze Yang, Shaohui Liu, Han Hu, Liwei Wang, and Stephen Lin. Reppoints: Point set representation for object detection. ICCV, 2019. 5
[34] Zetong Yang, Yanan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. IPOD: intensive point-based object detector for point cloud. CoRR, 2018. 1, 2, 3, 6
[35] Zetong Yang, Yanan Sun, Shu Liu, Xiaoyong Shen, and Jiaya Jia. STD: sparse-to-dense 3d object detector for point cloud. ICCV, 2019. 1, 2, 3, 6, 8
[36] Yin Zhou and Oncel Tuzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. CoRR, 2017. 1, 2, 6, 7

