1��VisDrone2019���ݼ�����
�䱸����ͷ�����˻�(��ͨ�����˻�)�ѱ����ٲ��㷺��Ӧ������,����ũҵ��������Ӱ�����ٽ����ͼ��ӡ����,����Щƽ̨���ռ����Ӿ����ݵ��Զ�����Ҫ��Խ��Խ��,��ʹ�ü�����Ӿ������˻��Ĺ�ϵԽ��Խ���С����Ǻܸ���Ϊ������Ҫ�ļ�����Ӿ�����չʾһ�����ͻ�,����ϸע���˵�������,����ΪVisDrone,ʹ�Ӿ������˻�������VisDrone2019���ݼ�������ѧ����ѧϰ�������ھ�ʵ����AISKYEYE�Ŷ��ռ��������ݼ�����288����ƵƬ��,��261908֡��10209����̬ͼ�����,�ɸ������˻�����ͷ����,���Ƿ�Χ�㷺,����λ��(�����й������ǧ�����14����ͬ����)������(���к�ũ��)������(���ˡ����������г�����)���ܶ�(ϡ���ӵ���ij���)����ע��,���ݼ����ڲ�ͬ�ij�������ͬ����������������ʹ�ò�ͬ�����˻�ƽ̨(����ͬ�ͺŵ����˻�)�ռ��ġ���Щ����ó���260�����������Ȥ��Ŀ����ֹ���ע,�������ˡ����������г������ֳ���һЩ��Ҫ������,���������ɼ���,��������ڵ�,Ҳ�ṩ�˸��õ��������á�
��ս��Ҫ�������ĸ�������:
(1)����1:ͼ���е�Ŀ������ս��������ּ�ڴ����˻�����ĵ���ͼ���м��Ԥ������������(������������)��
(2)����2:��Ƶ�е���������ս����������task 1����,��֮ͬ��������Ҫ����Ƶ�м�����塣
(3)task 3:�����������ս��
(4)����4:��Ŀ�������ս(multiobject tracking challenge)��
(5)����5:��Ⱥ������ս���������Ŀ����ͳ��ÿ����Ƶ֡�е�������
2����������
3������һ,Ŀ�������ݼ�
���Ǻܸ��˵�����VisDrone2021ͼ���������ս(����1)���ñ���ּ���ƶ������˻�ƽ̨�����Ƚ���Ŀ���⡣Ҫ���Ŷ�Ԥ��10��Ԥ�������(pedestrian, person, car, van, bus, truck, motor, bicycle, awning-tricycle, and tricycle)������߽��,������ʵֵ���Ŷȡ�һЩ���ٷ��������ֳ���(��machineshop truck, forklift truck, and tanker)�������б����ԡ�
����ս����10209�ž�̬ͼ��(6471������ѵ��,548��������֤,3190�����ڲ���),�����˻�ƽ̨�ڲ�ͬ�ص�Ͳ�ͬ�߶Ȳ���,��������ҳ�������ء������ֶ�ע��ÿ��ͼ���в�ͬ������ı߽����,���ǻ��ṩ���������õ�ע��,�ڵ��Ⱥͽضϱȡ������˵,����ʹ�ñ��ڵ�����ı����������ڵ��ȡ��ضϱ�������ʾ���岿�ֳ����ڿ����ij̶ȡ����һ��������һ֡��û�б���ȫ����,������֡�߽��ϱ�ע�߽��,������ͼ���ⲿ������ƽضϱȡ�ֵ��һ�����,���Ŀ��Ľضϱȴ���50%,��������������������Ŀ�ꡣ������ѵ����֤����ע���ǹ������õġ�
����DET����,���������ݺͱ�ǩ:ѵ�����ݡ���֤���ݺͲ�����ս���ݡ�������֮��û���ص���
Number of images
Dataset Training Validation Test-Challenge
Object detection in images 6,471 images 548 images 1,580 images
1����ǩ���
��ǩ��0��11�ֱ�Ϊ��ignored regions��,��pedestrian��,��people��,��bicycle��,��car��,��van��,
��truck��,��tricycle��,��awning-tricycle��,��bus��,��motor��,��others��
2��ע�ͱ�ǩ
???????????
<bbox_left>,<bbox_top>,<bbox_width>,<bbox_height>,,<object_category>,,
<bbox_left>,<bbox_top>,<bbox_width>,<bbox_height>,,<object_category>,,
Name Description
<bbox_left> The x coordinate of the top-left corner of the predicted bounding box
<bbox_top> The y coordinate of the top-left corner of the predicted object bounding box
<bbox_width> The width in pixels of the predicted object bounding box
<bbox_height> The height in pixels of the predicted object bounding box
The score in the DETECTION file indicates the confidence of the predicted bounding box enclosing
an object instance.
The score in GROUNDTRUTH file is set to 1 or 0. 1 indicates the bounding box is considered in evaluation,
while 0 indicates the bounding box will be ignored.
<object_category> The object category indicates the type of annotated object, (i.e., ignored regions(0), pedestrian(1),
people(2), bicycle(3), car(4), van(5), truck(6), tricycle(7), awning-tricycle(8), bus(9), motor(10),
others(11))
The score in the DETECTION result file should be set to the constant -1.
The score in the GROUNDTRUTH file indicates the degree of object parts appears outside a frame
(i.e., no truncation = 0 (truncation ratio 0%), and partial truncation = 1 (truncation ratio 1% ~ 50%)).
The score in the DETECTION file should be set to the constant -1.
The score in the GROUNDTRUTH file indicates the fraction of objects being occluded (i.e., no occlusion = 0
(occlusion ratio 0%), partial occlusion = 1 (occlusion ratio 1% ~ 50%), and heavy occlusion = 2
(occlusion ratio 50% ~ 100%)).
����:�������õ�ע��:truncation�ض���,occlusion�ڵ��ʡ�
���ڵ��Ķ�������������ڵ��ʡ�
�ض�������ָʾ���ֳ����ڿ���ⲿ�ij̶ȡ�
���Ŀ��Ľض��ʴ���50%,��������������н���������
3����������
����Ҫ��ÿ���������㷨��Ԥ����ĸ�ʽ������Ĵ���ÿ������ͼ�����Ŷȵ÷ֵı߽���б�������Ľ����ʽ�˽����ϸ�ڡ���MS COCO[1]������Э������,����ʹ�� AP, APIOU=0.50, APIOU=0.75, ARmax=1, ARmax=10, ARmax=100, and ARmax=500 metrics to evaluate the results of detection algorithms���������й涨,AP��ARָ����������(loU)ֵ�Ķ��������ƽ���ġ�������˵,����ʹ��ʮ��loU��ֵ[0.50:0.05:0.95]������ָ��ļ����������500����ߵ÷ּ��ÿ��ͼ��(���������)����Щ����ͷ�������ȱʧ���ظ����(ͬһ������ʵ�������������)��APָ�걻�����㷨�������Ҫָ�ꡣ�±���������Щָ�ꡣ
Measure Perfect Description
AP 100% The average precision over all 10 IoU thresholds (i.e., [0.5:0.05:0.95]) of all object categories
���ж�������10��IoU��ֵ(��[0.5:0.05:0.95])��ƽ������
APIOU=0.50 100% The average precision over all object categories when the IoU overlap with ground truth is larger than 0.50
��IoU�������ʵֵ�ص�ʱ,���ж������Ĵ���0.50��ƽ������
APIOU=0.75 100% The average precision over all object categories when the IoU overlap with ground truth is larger than 0.75
ARmax=1 100% The maximum recall given 1 detection per image,����ÿ��ͼ��һ�μ�������ٻ���
ARmax=10 100% The maximum recall given 10 detections per image,����ÿ��ͼ��10�μ�������ٻ���
ARmax=100 100% The maximum recall given 100 detections per image
ARmax=500 100% The maximum recall given 500 detections per image
����ָ���Ǹ���10������Ȥ�Ķ���������ġ��ۺ�����,���ǽ�����ÿ�������������ܡ�ͼ���ж�������������������VisDrone github�ϻ�á�
evalDET.m is the main function used to evaluate your detector -please modify the dataset path and result path -use ��isImgDisplay�� to display the groundtruth and detections
4��VisDrone2019Ŀ�������ݼ���ʽת��
4.1 ת��ΪYOLO(TXT)��ʽ
YOLO���ݼ��ļ��й����������ļ���,һ���� images ,һ���� labels ,�ֱ���ͼƬ���ǩtxt�ļ�,���� images��labels��Ŀ¼�ṹ��Ҫ��Ӧ,��Ϊyolo���ȶ�ȡimagesͼƬ·��,���ֱ�ӽ�images�滻Ϊlabels�����ұ�ǩ�ļ� ��������ʾ:
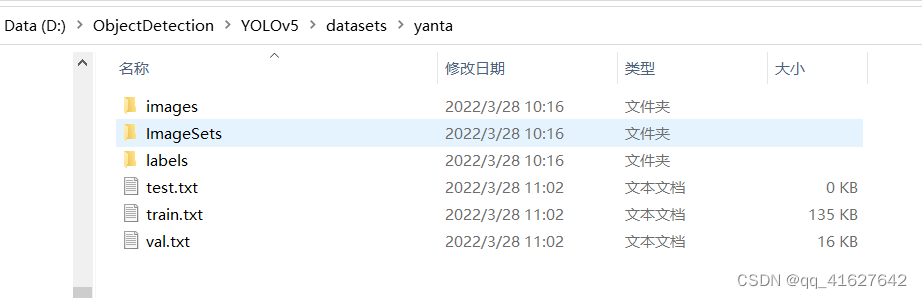
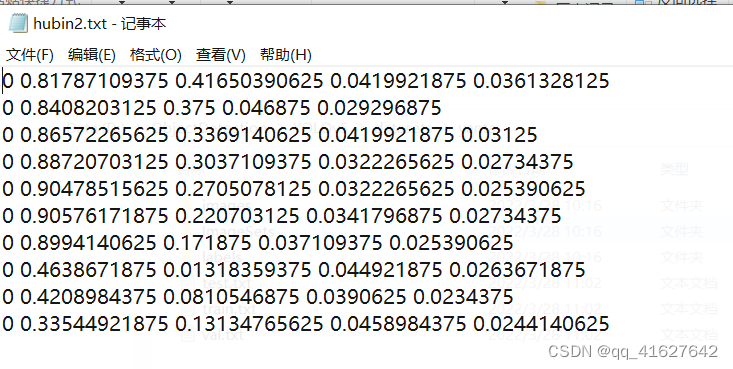
ÿ��ͼƬ��Ӧ��txt�ļ���,���ݸ�ʽ��:cls_id x y w h ��������(x,y)�����ĵ�����,�����������ͼƬ���ߵı���ֵ ,���Ǿ������ꡣ
�°汾��yolov5���Ѿ�������ѵ��visdrone���ݼ��������ļ�,���и��������ݼ��Ĵ�����ʽ,��Ҫ��labels������,�����½�һ��visDrone2019_txt2txt_yolo.py�ļ���
'''
Author: ������ 13752614153@163.com
Date: 2022-05-09 14:05:05
LastEditors: ������ 13752614153@163.com
LastEditTime: 2022-05-09 15:38:09
FilePath: \VisDrone2019\data_process\visDrone2019_txt2txt_yolo.py
Description: ����Ĭ������,������`customMade`, ��koroFileHeader�鿴���� ��������: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE
'''
import os
from pathlib import Path
from PIL import Image
from tqdm import tqdm
def visdrone2yolo(dir):
def convert_box(size, box):
#Convert VisDrone box to YOLO CxCywh box,��������˹�һ��
dw = 1. / size[0]
dh = 1. / size[1]
return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
# (dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
(dir / 'Annotations_YOLO').mkdir(parents=True, exist_ok=True) # make labels directory
pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
for f in pbar:
img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
lines = []
with open(f, 'r') as file: # read annotation.txt
for row in [x.split(',') for x in file.read().strip().splitlines()]:
if row[4] == '0': # VisDrone 'ignored regions' class 0
continue
cls = int(row[5]) - 1
box = convert_box(img_size, tuple(map(int, row[:4])))
lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'Annotations_YOLO' + os.sep), 'w') as fl:
fl.writelines(lines) # write label.txt
dir = Path(r'E:\DPL\DeepLearnData\Ŀ����\����Ŀ��������VisDrone\VisDrone2019') # dataset�ļ�����Visdrone2019�ļ���·��
# Convert
for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
��ȷִ�д����,���ڡ�VisDrone2019-DET-train��, ��VisDrone2019-DET-val��, 'VisDrone2019-DET-test-dev�����ļ�����������Annotations_YOLO�ļ���,���Դ�Ž�VisDrone���ݼ�������YoloV5��ʽ������ݱ�ǩ��
��ǩΪyolo��ʽ���ݼ�����ѵ��������֤��
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt�����ļ���·��,xml�ļ�����·��,ͼƬ�����ļ���·��
def makexml(picPath, txtPath, xmlPath): # txt�����ļ���·��,xml�ļ�����·��,ͼƬ�����ļ���·��
"""�˺������ڽ�yolo��ʽtxt��ע�ļ�ת��Ϊvoc��ʽxml��ע�ļ�
���Լ��ı�עͼƬ�ļ����½��������ļ���,�ֱ�����Ϊpicture��txt��xml
"""
dic = {'0': "hat", # �����ֵ����������ͽ���ת��
'1': "person", # �˴����ֵ�Ҫ���Լ���classes.txt�ļ��е����Ӧ,��˳��Ҫһ��
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # ����annotation��ǩ
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder��ǩ
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder��ǩ����
filename = xmlBuilder.createElement("filename") # filename��ǩ
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename��ǩ����
size = xmlBuilder.createElement("size") # size��ǩ
width = xmlBuilder.createElement("width") # size�ӱ�ǩwidth
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size�ӱ�ǩwidth����
height = xmlBuilder.createElement("height") # size�ӱ�ǩheight
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size�ӱ�ǩheight����
depth = xmlBuilder.createElement("depth") # size�ӱ�ǩdepth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size�ӱ�ǩdepth����
annotation.appendChild(size) # size��ǩ����
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object ��ǩ
picname = xmlBuilder.createElement("name") # name��ǩ
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name��ǩ����
pose = xmlBuilder.createElement("pose") # pose��ǩ
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose��ǩ����
truncated = xmlBuilder.createElement("truncated") # truncated��ǩ
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated��ǩ����
difficult = xmlBuilder.createElement("difficult") # difficult��ǩ
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult��ǩ����
bndbox = xmlBuilder.createElement("bndbox") # bndbox��ǩ
xmin = xmlBuilder.createElement("xmin") # xmin��ǩ
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin��ǩ����
ymin = xmlBuilder.createElement("ymin") # ymin��ǩ
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin��ǩ����
xmax = xmlBuilder.createElement("xmax") # xmax��ǩ
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax��ǩ����
ymax = xmlBuilder.createElement("ymax") # ymax��ǩ
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax��ǩ����
object.appendChild(bndbox) # bndbox��ǩ����
annotation.appendChild(object) # object��ǩ����
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "VOCdevkit/VOC2007/JPEGImages/" # ͼƬ�����ļ���·��,�����/һ��Ҫ����
txtPath = "VOCdevkit/VOC2007/YOLO/" # txt�����ļ���·��,�����/һ��Ҫ����
xmlPath = "VOCdevkit/VOC2007/Annotations/" # xml�ļ�����·��,�����/һ��Ҫ����
makexml(picPath, txtPath, xmlPath)
4.2 ת��ΪVOC(XML)��ʽ
VOCdevkit
�CVOC2007
----Annotations
----ImageSets
------Main
----JEPGImages
Annotations Ŀ¼���.xml�ļ�,JEPGImages ���ѵ��ͼƬ,�������ݼ�ʹ�����´���,
VOC Annotations�ļ���,���ļ��´�ŵ���xml��ʽ�ı�ǩ�ļ�,ÿ��xml�ļ�����Ӧ��JPEGImages�ļ��е�һ��ͼƬ, ���ж�xml�Ľ�������:
<annotation>
<folder>VOC2007</folder>
<filename>2007_000392.jpg</filename> //�ļ���
<source> //ͼ����Դ(����Ҫ)
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> //ͼ��ߴ�(�����Լ�ͨ����)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> //�Ƿ����ڷָ�(��ͼ������ʶ����01����ν)
<object> //��������
<name>horse</name> //�������
<pose>Right</pose> //����Ƕ�
<truncated>0</truncated> //�Ƿض�(0��ʾ����)
<difficult>0</difficult> //Ŀ���Ƿ�����ʶ��(0��ʾ����ʶ��)
<bndbox> //bounding-box(�������½Ǻ����Ͻ�xy����)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> //���������
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>198</xmin>
<ymin>58</ymin>
<xmax>286</xmax>
<ymax>197</ymax>
</bndbox>
</object>
</annotation>
������visDrone2019��txtע���ļ�ת��Ϊvoc xml�Ĵ���,visDrone2019_txt2xml_voc.py
��Ҫ�ĵĵط���ע��,���Ǽ���·����һ�¼��ɡ�
'''
Author: ������ 13752614153@163.com
Date: 2022-05-09 10:17:40
LastEditors: ������ 13752614153@163.com
LastEditTime: 2022-05-09 11:17:20
FilePath: \VisDrone2019\data_process\visDrone2019_txt2xml.py
Description: ����Ĭ������,������`customMade`, ��koroFileHeader�鿴���� ��������: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE
'''
import os
import datetime
from PIL import Image
from pathlib import Path
FILE = Path(__file__).resolve()
# print("FILE",FILE)
ROOT = FILE.parent.parents[0] # root directory
print("ROOT",ROOT)
def check_dir(path):
if os.path.isdir(path):
print("{}�ļ�·������!".format(path))
pass
else:
os.makedirs(path)
print("{}�ļ�·�������ɹ�!".format(path))
#�������root_dir·���ij����Լ���·������
root_dir = ROOT / 'VisDrone2019-DET-train'
annotations_dir = root_dir / "annotations/"
image_dir = root_dir / "images/"
xml_dir = root_dir / "Annotations_XML/" #�ڹ���Ŀ¼�´���Annotations_XML�ļ��б���xml�ļ�
check_dir(xml_dir)
# print("annotation_dir",annotations_dir)
# print("image_dir",image_dir)
# print("xml_dir",xml_dir)
# root_dir = r"D:\object_detection_data\datacovert\VisDrone2019-DET-val/"
# annotations_dir = root_dir+"annotations/"
# image_dir = root_dir + "images/"
# xml_dir = root_dir+"Annotations_XML/" #�ڹ���Ŀ¼�´���Annotations_XML�ļ��б���xml�ļ�
# ��������Ҳ�������Լ��������,Ҳ�����������������ݼ�ת��
class_name = ['ignored regions','pedestrian','people','bicycle','car','van',
'truck','tricycle','awning-tricycle','bus','motor','others']
for filename in os.listdir(annotations_dir):
fin = open(annotations_dir/ filename, 'r')
image_name = filename.split('.')[0]
image_path=Path(image_dir).joinpath(image_name+".jpg")# ��ͼ�������ǡ�png��ת���ɡ�.png������
img = Image.open(image_path) # ��ͼ�������ǡ�png��ת���ɡ�.png������
xml_name = Path(xml_dir).joinpath(image_name+'.xml')
with open(xml_name, 'w') as fout:
#д���xml������Ϣ
fout.write('<annotation>'+'\n')
fout.write('\t'+'<folder>VOC2007</folder>'+'\n')
fout.write('\t'+'<filename>'+image_name+'.jpg'+'</filename>'+'\n')
fout.write('\t'+'<source>'+'\n')
fout.write('\t\t'+'<database>'+'VisDrone2019-DET'+'</database>'+'\n')
fout.write('\t\t'+'<annotation>'+'VisDrone2019-DET'+'</annotation>'+'\n')
fout.write('\t\t'+'<image>'+'flickr'+'</image>'+'\n')
fout.write('\t\t'+'<flickrid>'+'Unspecified'+'</flickrid>'+'\n')
fout.write('\t'+'</source>'+'\n')
fout.write('\t'+'<owner>'+'\n')
fout.write('\t\t'+'<flickrid>'+'LJ'+'</flickrid>'+'\n')
fout.write('\t\t'+'<name>'+'LJ'+'</name>'+'\n')
fout.write('\t'+'</owner>'+'\n')
fout.write('\t'+'<size>'+'\n')
fout.write('\t\t'+'<width>'+str(img.size[0])+'</width>'+'\n')
fout.write('\t\t'+'<height>'+str(img.size[1])+'</height>'+'\n')
fout.write('\t\t'+'<depth>'+'3'+'</depth>'+'\n')
fout.write('\t'+'</size>'+'\n')
fout.write('\t'+'<segmented>'+'0'+'</segmented>'+'\n')
for line in fin.readlines():
line = line.split(',')
fout.write('\t'+'<object>'+'\n')
fout.write('\t\t'+'<name>'+class_name[int(line[5])]+'</name>'+'\n')
fout.write('\t\t'+'<pose>'+'Unspecified'+'</pose>'+'\n')
fout.write('\t\t'+'<truncated>'+line[6]+'</truncated>'+'\n')
fout.write('\t\t'+'<difficult>'+str(int(line[7]))+'</difficult>'+'\n')
fout.write('\t\t'+'<bndbox>'+'\n')
fout.write('\t\t\t'+'<xmin>'+line[0]+'</xmin>'+'\n')
fout.write('\t\t\t'+'<ymin>'+line[1]+'</ymin>'+'\n')
# pay attention to this point!(0-based)
fout.write('\t\t\t'+'<xmax>'+str(int(line[0])+int(line[2])-1)+'</xmax>'+'\n')
fout.write('\t\t\t'+'<ymax>'+str(int(line[1])+int(line[3])-1)+'</ymax>'+'\n')
fout.write('\t\t'+'</bndbox>'+'\n')
fout.write('\t'+'</object>'+'\n')
fin.close()
fout.write('</annotation>')
��ǩΪvoc��ʽ���ݼ�����ѵ��������֤��
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
��������ָ����ݼ�,ѵ����ռ80%,���Լ�ռ20% ���д�������/VOCdevkit/VOC2007/ImageSets/Main��������.txt�ļ�
����.txt�ļ�����ֱ���ѵ������ͼƬ���Ƶ�����,���ݼ�������������
4.3 ת��ΪVOC(XML)TO COCO(JSON)���ݸ�ʽ
�����:
��visdrone���ݼ�ת��Ϊcoco��ʽ����mmdetection��ѵ��,����ת�õ�json�ļ�
1��cocoĿ�����json�����ʽ
����Ŀ����,json�ļ��ĸ�ʽ��Ҫ����:
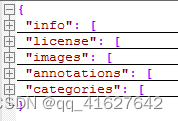
�ǵ�,����������ļ�,��Ȼ���ݺܶ�,�����ļ���ʼ����β����˳�������5�Ρ�����,info��licenses��images�ڲ�ͬ��JSON�ļ���������������һ����,�����ǹ����ġ�
����������annotation��category�����ֽṹ��,�����ڲ�ͬ���͵�JSON�ļ����Dz�һ���ġ�
PS,images���顢annotations���顢categories�����Ԫ����������ȵ�,����ͼƬ��������
ÿ������ʵ��ע�Ͱ���һϵ���ֶ�,������������id�ͷֶ����롣�ָ��ʽȡ����ʵ���Ƿ������������(iscrowd=0,��ʹ�ö���ε������)�����(iscrowd=1,��ʹ��RLE�������)����ע��,��������(iscrowd=0)������Ҫ��������,�����ڵ�����Ⱥע��(iscrowd=1)���ڱ�Ǵ��Ͷ�����(����һȺ��)������,Ϊÿ�������ṩ��һ����յı߽��(��������Ǵ�ͼ�����Ͻǿ�ʼ������,������o������)��
���,ע�ͽṹ��categories�ֶδ洢���id�����ͳ�������Ƶ�ӳ�䡣
2��coco���������ݻ����ṹ
��3���������������еĻ�������,����info��image��license��
{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
info{
"year" : int,
"version" : str,
"description" : str,
"contributor" : str,
"url" : str,
"date_created" : datetime,
}
image{
"id" : int,
"width" : int,
"height" : int,
"file_name" : str,
"license" : int,
"flickr_url" : str,
"coco_url" : str,
"date_captured" : datetime,
}
license{
"id" : int,
"name" : str,
"url" : str,
}
info
info: {
"year": int,# ���
"version": str,# �汾
"description": str, # ���ݼ�����
"contributor": str,# �ṩ��
"url": str,# ���ص�ַ
"date_created": datetime
}
info����,����һ��info���͵�ʵ��:
"info":{
"description":"This is stable 1.0 version of the 2014 MS COCO dataset.",
"url":"http:\/\/mscoco.org",
"version":"1.0","year":2014,
"contributor":"Microsoft COCO group",
"date_created":"2015-01-27 09:11:52.357475"
}
license
license{
"id": int,
"name": str,
"url": str,
}
{
"url":"http:\/\/creativecommons.org\/licenses\/by-nc-sa\/2.0\/",
"id":1,
"name":"Attribution-NonCommercial-ShareAlike License"
}
image
image{
"id": int,# ͼƬ��ID���(ÿ��ͼƬID��Ψһ��)
"width": int,#��
"height": int,#��
"file_name": str,# ͼƬ��
"license": int,
"flickr_url": str,# flickr��·��ַ
"coco_url": str,# ��·��ַ·��
"date_captured": datetime # ���ݻ�ȡ����
}
Images�ǰ������imageʵ��������,����һ��image���͵�ʵ��:
{
"license":3,
"file_name":"COCO_val2014_000000391895.jpg",
"coco_url":"http:\/\/mscoco.org\/images\/391895",
"height":360,"width":640,"date_captured":"2013-11-14 11:18:45",
"flickr_url":"http:\/\/farm9.staticflickr.com\/8186\/8119368305_4e622c8349_z.jpg",
"id":391895
}
ÿһ��image��ʵ����һ��dict��������һ��id�ֶ�,��������ͼƬ��id,ÿһ��ͼƬ����Ψһ��һ�����ص�id��
3��coco�����������ݻ����ṹ
annotations�ֶ�
annotations�ֶ��ǰ������annotationʵ����һ���б�,annotation���ͱ����ְ�����һϵ�е��ֶ�,�����Ŀ���category id��segmentation mask��segmentation��ʽȡ�������ʵ����һ�������Ķ���(��iscrowd=0,��ʹ��polygons��ʽ)����һ�����(��iscrowd=1,��ʹ��RLE��ʽ)��������ʾ:
annotation{
"id": int,
"image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
annotation{
"id": int, # ����ID,��Ϊÿһ��ͼ���в�ֹһ������,����Ҫ��ÿһ��������(ÿ�������ID��Ψһ��)
"image_id": int,# ��Ӧ��ͼƬID(��images�е�ID��Ӧ)
"category_id": int,# ���ID(��categories�е�ID��Ӧ)
"segmentation": RLE or [polygon],# ����ı߽��(�߽�����,��ʱiscrowd=0)��
#segmentation��ʽȡ�������ʵ����һ�������Ķ���(��iscrowd=0,��ʹ��polygons��ʽ)����һ�����(��iscrowd=1,��ʹ��RLE��ʽ)
"area": float,# �������
"bbox": [x,y,width,height], # ��λ�߿� [x,y,w,h]
"iscrowd": 0 or 1 #����
}
ע��,�����Ķ���(iscrowd=0)������Ҫ���polygon����ʾ,�������������ͼ���б���ס�ˡ���iscrowd=1ʱ(����עһ�����,����һȺ��)��segmentationʹ�õľ���RLE��ʽ��
����,ÿ������(������iscrowd=0����iscrowd=1)������һ�����ο�bbox ,���ο����Ͻǵ�����;��ο�ij��������������ʽ�ṩ,�����һ��Ԫ�ؾ������Ͻǵĺ�����ֵ��
����,area�ǿ�����(area of encoded masks)��
һ��annotationΪsegmentation��polygon��ʽ��ʵ��:
{
"segmentation": [[510.66,423.01,511.72,420.03,510.45......]],
"area": 702.1057499999998,
"iscrowd": 0,
"image_id": 289343,
"bbox": [473.07,395.93,38.65,28.67],
"category_id": 18,
"id": 1768
}
categories�ֶ�
categories��һ���������categoryʵ�����б�,��һ��category�ṹ����������:
{
"supercategory": str,# �����
"id": int,# ���Ӧ��id (0 Ĭ��Ϊ����)
"name": str # �����
}
categories����ʵ��:
{
"supercategory": "person",
"id": 1,
"name": "person"
},
{
"supercategory": "vehicle",
"id": 2,
"name": "bicycle"
}
4������ת��
# coco���ݱ�ע�Ļ�����ʽ
'''
{
"info" : info,
"images" : [image],
"annotations" : [annotation],
"licenses" : [license],
}
info {
"year" : int,
"version" : str,
"description" : str,
"contributor" : str,
"url" : str,
"date_created" : datetime,
}
license{
"id" : int,
"name" : str,
"url" : str,
}
image{
"id" : int, # ͼƬid
"width" : int, # ͼƬ��
"height" : int, # ͼƬ��
"file_name" : str, # ͼƬ��
"license" : int,
"flickr_url" : str,
"coco_url" : str, # ͼƬ����
"date_captured" : datetime, # ͼƬ��עʱ��
}
annotation{
"id" : int,
"image_id" : int,
"category_id" : int,
"segmentation" : RLE or [polygon],
"area" : float,
"bbox" : [x,y,width,height],
"iscrowd" : 0 or 1,
}
categories[{
"id" : int,
"name" : str,
"supercategory" : str,
}]'''
import sys, os, json, glob
import xml.etree.ElementTree as ET
from pathlib import Path
from xml.dom import minidom
#�����ID��ʼֵ
INITIAL_BBOXIds = 0
# #����б��ޱ�ҪԤ�ȴ���,�����л��������ͼ���а�����ID������������
# PREDEF_CLASSE = {}
PREDEF_CLASSE = { 'ignored regions':0,'pedestrian': 1, 'people': 2,'bicycle': 3, 'car': 4, 'van': 5, 'truck': 6, 'tricycle': 7,'awning-tricycle': 8, 'bus': 9, 'motor': 10,'others':11}
'''
#������ֻ������ʮ����, 0��11û�м���ת����
PREDEF_CLASSE = { 'pedestrian': 1, 'people': 2,'bicycle': 3, 'car': 4, 'van': 5, 'truck': 6, 'tricycle': 7,'awning-tricycle': 8, 'bus': 9, 'motor': 10}
#class_name = ['ignored regions','pedestrian','people','bicycle','car','van','truck','tricycle','awning-tricycle','bus','motor','others']
'''
def check_dir(path):
if os.path.isdir(path):
print("{}�ļ�·������!".format(path))
pass
else:
os.makedirs(path)
print("{}�ļ�·�������ɹ�!".format(path))
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.'%(name, root.tag))
if length > 0 and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.'%(name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_paths, out_json):
#json�Ļ�����ע��ʽ
json_dict = {'images': [], 'type':"instances",'annotations': [],'categories': []}
categories = PREDEF_CLASSE
bbox_id = INITIAL_BBOXIds
for image_id, xml_f in enumerate(xml_paths):
# �������
sys.stdout.write('\r>> Converting image %d/%d' % (image_id + 1, len(xml_paths)))
sys.stdout.flush()
tree = ET.parse(xml_f)
root = tree.getroot()
path=get(root,'path')
if len(path)==1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, 'filename', 1).text
else:
raise NotImplementedError('%d paths found in %s'%(len(path), xml_f))
#images����
size = get_and_check(root, 'size', 1)
#ͼƬ�Ļ�����Ϣ
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {
'id': image_id + 1,
'height': height,
'width': width,
'file_name': filename
}
json_dict['images'].append(image)
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
#�������ID�ֵ�
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bbox = get_and_check(obj, 'bndbox', 1)
xmin = int(get_and_check(bbox, 'xmin', 1).text) - 1
ymin = int(get_and_check(bbox, 'ymin', 1).text) - 1
xmax = int(get_and_check(bbox, 'xmax', 1).text)
ymax = int(get_and_check(bbox, 'ymax', 1).text)
if xmax <= xmin or ymax <= ymin:
continue
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
# ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id': image_id + 1,
# 'bbox': [xmin, ymin, o_width, o_height], 'category_id': category_id,
# 'id': bbox_id, 'ignore': 0, 'segmentation': [xmin,ymin,xmin,ymax,xmax,ymax,xmax,ymin]}
ann={
'id':bbox_id,
'image_id': image_id,
'category_id': category_id,
# 'segmentation': [xmin,ymin,xmin,ymax,xmax,ymax,xmax,ymin],
'area': o_width * o_height,
'bbox': [xmin, ymin, o_width, o_height],
'iscrowd': 0
}
json_dict['annotations'].append(ann)
bbox_id = bbox_id + 1
# д�����ID�ֵ�
for cate, cid in categories.items():
cat = {'supercategory': 'none', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
# json_file = open(out_json, 'w')
# json_str = json.dumps(json_dict)
# json_file.write(json_str)
# json_file.close() # ��
json.dump(json_dict, open(out_json, 'w'), indent=4) # indent=4 ����������ʾ ��
print("json file write done...")
if __name__ == '__main__':
dir = Path(r'E:\DPL\DeepLearnData\Ŀ����\����Ŀ��������VisDrone\VisDrone2019') # dataset�ļ�����Visdrone2019�ļ���·��
# for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
for d in 'VisDrone2019-DET-train','VisDrone2019-DET-val':
xml_dir=dir / d / 'Annotations_XML'
coco_dir=dir / d/ 'Annotations_COCO'
check_dir( coco_dir)
xml_file = glob.glob(os.path.join(xml_dir, '*.xml'))
json_file=coco_dir / 'instances_{}2017.json'.format(d.split('-')[2])
# convrt Annotations_COCO
convert(xml_file, json_file) #���������ɵ�json����λ��,��һ��
4.4 ֱ����txtTת��Ϊ COCO(JSON)���ݸ�ʽ
import os
import cv2
from PIL import Image
from tqdm import tqdm
import json
def convert_to_cocodetection(dir, output_dir):
#����Ŀ¼
train_dir = os.path.join(dir, "VisDrone2019-DET-train")
val_dir = os.path.join(dir, "VisDrone2019-DET-val")
#���ݱ�עĿ¼
train_annotations = os.path.join(train_dir, "annotations")
val_annotations = os.path.join(val_dir, "annotations")
#����Ӱ��Ŀ¼
train_images = os.path.join(train_dir, "images")
val_images = os.path.join(val_dir, "images")
id_num = 0
categories = [
{"id": 0, "name": "ignored regions"},
{"id": 1, "name": "pedestrian"},
{"id": 2, "name": "people"},
{"id": 3, "name": "bicycle"},
{"id": 4, "name": "car"},
{"id": 5, "name": "van"},
{"id": 6, "name": "truck"},
{"id": 7, "name": "tricycle"},
{"id": 8, "name": "awning-tricycle"},
{"id": 9, "name": "bus"},
{"id": 10, "name": "motor"},
{"id": 11, "name": "others"}
]
for mode in ["train", "val"]:
images = []
annotations = []
print(f"start loading {mode} data...")
if mode == "train":
set = os.listdir(train_annotations)
annotations_path = train_annotations
images_path = train_images
else:
set = os.listdir(val_annotations)
annotations_path = val_annotations
images_path = val_images
for i in tqdm(set):
f = open(annotations_path + "/" + i, "r")
name = i.replace(".txt", "")
#images����
image = {}
image_file_path=images_path + os.sep + name + ".jpg"
print(image_file_path)
img_size = Image.open((images_path + os.sep + name+ ".jpg")).size
height, width=img_size
# height, width = cv2.imread(images_path + os.sep + name + ".jpg").shape[:2]
file_name = name + ".jpg"
image["id"] = name
image["height"] = height
image["width"] = width
image["file_name"] = file_name
images.append(image)
for line in f.readlines():
#annotation����
annotation = {}
line = line.replace("\n", "")
if line.endswith(","): # filter data
line = line.rstrip(",")
line_list = [int(i) for i in line.split(",")]
bbox_xywh = [line_list[0], line_list[1], line_list[2], line_list[3]]
annotation["id"] = id_num
annotation["image_id"] = name
annotation["category_id"] = int(line_list[5])
# annotation["segmentation"] = []
annotation["area"] = bbox_xywh[2] * bbox_xywh[3]
# annotation["score"] = line_list[4]
annotation["bbox"] = bbox_xywh
annotation["iscrowd"] = 0
id_num += 1
annotations.append(annotation)
dataset_dict = {}
dataset_dict["images"] = images
dataset_dict["annotations"] = annotations
dataset_dict["categories"] = categories
json_str = json.dumps(dataset_dict)
with open(f'{output_dir}/VisDrone2019-DET_{mode}_coco.json', 'w') as json_file:
json_file.write(json_str)
print("json file write done...")
def get_test_namelist(dir, out_dir):
full_path = out_dir + "/" + "test.txt"
file = open(full_path, 'w')
for name in tqdm(os.listdir(dir)):
name = name.replace(".txt", "")
file.write(name + "\n")
file.close()
return None
def centerxywh_to_xyxy(boxes):
"""
args:
boxes:list of center_x,center_y,width,height,
return:
boxes:list of x,y,x,y,cooresponding to top left and bottom right
"""
x_top_left = boxes[0] - boxes[2] / 2
y_top_left = boxes[1] - boxes[3] / 2
x_bottom_right = boxes[0] + boxes[2] / 2
y_bottom_right = boxes[1] + boxes[3] / 2
return [x_top_left, y_top_left, x_bottom_right, y_bottom_right]
def centerxywh_to_topleftxywh(boxes):
"""
args:
boxes:list of center_x,center_y,width,height,
return:
boxes:list of x,y,x,y,cooresponding to top left and bottom right
"""
x_top_left = boxes[0] - boxes[2] / 2
y_top_left = boxes[1] - boxes[3] / 2
width = boxes[2]
height = boxes[3]
return [x_top_left, y_top_left, width, height]
def clamp(coord, width, height):
if coord[0] < 0:
coord[0] = 0
if coord[1] < 0:
coord[1] = 0
if coord[2] > width:
coord[2] = width
if coord[3] > height:
coord[3] = height
return coord
if __name__ == '__main__':
# ��һ��������������Ŀ¼��·��,�ڶ���������Ҫ�����·��
# ֻ�����˼��ѵ����Ҫ������,COCO��ʽ��������ݶ���Ϊ��
convert_to_cocodetection(r"E:\DPL\DeepLearnData\Ŀ����\����Ŀ��������VisDrone\VisDrone2019",r"E:\DPL\DeepLearnData\Ŀ����\����Ŀ��������VisDrone\VisDrone2019\VisDrone2019-DET-COCO\annotations")
5��VisDrone2019Ŀ�������ݼ�coco��ʽĿ¼����
VisDrone2019��Ŀ�����COCO��ʽ�����ݼ�Ŀ¼����ͼ��ʾ
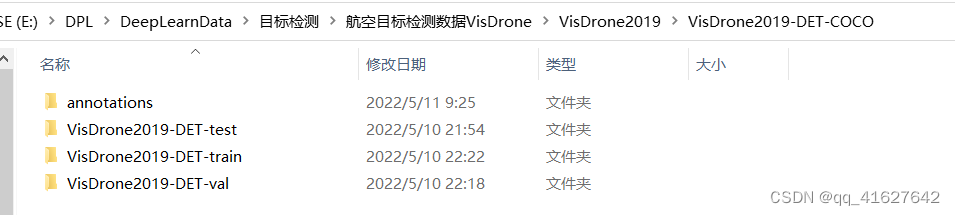 annotations���ݼ�Ŀ¼��������ͼ��ʾ
annotations���ݼ�Ŀ¼��������ͼ��ʾ


