面向制造领域人机物三元数据融合的本体自动化构建方法
点击蓝字 ・ 关注我们
摘要
当前,智能制造面临的许多问题都具有不确定性和复杂性,单纯地利用专家经验和机理模型难以有效解决.鉴于此,面向跨层跨域的复杂制造系统网络化协同控制机制,提出一种基于本体的人机物三元数据融合方法,研究复杂制造环境下的人机物三元数据融合建模.在抽取三元组时,区别于传统的流水线式抽取方式,提出一种基于实体-关系联合抽取的模型ErBERT.该模型首先经过预训练模型BERT进行词序列化,经过最大池化、全连接和Softmax等操作后,完成实体识别和关系分类任务,得到抽取完毕的人机物三元组.将抽取好的三元组按照规则映射至OWL文件,最终存储在图数据库中,实现本体模型的构建.经实验验证,经过ErBERT抽取出的三元组有较好的准确率,能够达到通过本体融合人机物三元数据的目标,并为实现制造企业人机物三元协同决策与优化提供技术支撑.
“
引言
随着互联网、大数据、人工智能等技术的迅猛发展,传统制造业正加速向新一代智能制造迈进[1]. 快速变化的市场环境及多元化的用户需求使制造业环境日趋复杂,提升企业应对复杂环境中不确定性因素的控制与决策水平,是企业向智能工厂转型中亟待解决的重要科学命题.
伴随着制造系统复杂度日益增加、用户个性化需求不断增长,以往的制造体系和制造水平已经难以满足个性化、智能化产品和服务增值升级的需求,制造系统将由以往的机物二元系统发展为人机物三元系统. 在复杂制造系统中,人(人力资源)具备不完全
第37卷
信息决策能力的优点和获取深度知识能力差的缺点,机(虚拟信息系统)具备处理海量数据的优点和处理不完全信息能力差的缺点,物(生产物理系统)具备执行能力强的优点和缺乏数据强处理能力的缺点. 新一代人工智能将人的作用引入到系统中,可极大地提高制造系统处理复杂性、不确定性问题的能力,有效实现产品及其生产和服务过程的最优化,人机物三元深度融合将会使人的智慧与机器的智能相互启发性地增长[2].
语义网是由Tim Berners-Lee最先提出的一个概念,可以使异构的数据信息相关联,组成语义网络,从而计算机可以理解和处理网络中的语义信息[3]. 本体作为语义网的基础,是一种能在语义及知识层次上描述数据的概念模型,用于确定领域内被共同认可的概念,并给出概念间的相互关系,从而实现海量多元异构数据的集成、共享与重用[4]. 传统的本体构建方法主要依靠领域专家手工构建,一旦构建的领域本体较为庞大,则会耗费大量的时间和精力. 因此,如何使用自动化的方式从数据源中抽取信息并构建本体,减少领域专家的参与,是当前本体研究的热点之一.异构数据会造成信息交互的问题,利用本体进行人机物三元数据的集成与融合,不仅可以解决操作障碍, 减少数据冗余, 还可以加强数据的推理和决策能力. 本文提出一种基于本体的人机物三元数据融合模型, 并在进行本体三元组的抽取时, 区别于传统流水线式抽取方式, 基于预训练模型 BERT(bidirectional encoder representation from transformers)提出一种实体-关系联合抽取模型ErBERT (entity andrelationship extraction with BERT),从而更好地整合实体及其关系之间的信息. 最后以宝钢热轧生产环节为案例,使用ErBERT自动构建本体. 结果显示,所提出的ErBERT模型是行之有效的.
一、相关工作
1.1 人机物三元数据融合
数据融合的目的是将多元异构数据进行融合,使得获得的信息能有效地应用到决策中[5]. 传统的数据融合技术,如模糊集理论、概率论理论以及可信度理论,对于各有其特点的人机物三元数据缺乏有效的融合方法. 目前国内外已有针对人机物三元系统数据融合的研究, Hussein等[6] 提出DSSoT智能服务,将人与物联网的数据通过动态社会物联网的模型进行融合; Misra等[7] 提出一种多变量数据融合学习模型,通过训练朴素贝叶斯、k近邻、决策树和支持向量机4个分类器,可以改善数据异构,提高辅助决策预测精度; Bu[8] 提出了一种基于张量模型的高阶K-means算法用于人机物三元数据的聚类,以获得更准确的结果; Wang等[9] 提出一系列基于张量的数据融合方法,最后给出一个综合的人机物数据融合框架; Chen等[10] 对基于强化学习算法的三元数据融合进行研究,但未涉及语义层面的自动化、智能化融合. 上述数据融合方法尝试将人机物数据进行融合,但忽略了人机物数据之间存在的关联与特征. 针对以上问题,本文采用语义融合的方法,将人机物三元数据抽象为语义信息,用本体形式表示语义,进行人机物三元数据的融合.
1.2 本体自动化构建
构建本体的方式可以分为3类:手动构建本体、半自动化构建本体和自动化构建本体,自动化构建本体方法由于其有效性,逐渐成为研究的热点. Hazber等[11] 定义了基于关系型数据库模式自动构造本体的映射规则; Zhao 等[12] 提出基于多标签学习模型与关联标签传播的原始结构单词提取方法,以提高本体关系自动识别精度,优化本体构建; Kethavarapu等[13]采用基于关键字、基于值的抽取方法对日志文件数据进行集成,再将其转换为OWL (web ontologylanguage)文件,从而实现了自动本体的生成.实体-关系抽取是信息抽取、知识图谱以及自然语言处理领域的核心任务和重要环节,同时也是自动化构建本体中最重要的一步[14]. 在本体中,知识以?entity1, relationship, entity2? 的格式保存为结构化三元组,即实体entity1、entity2之间存在relationship关系. 有监督的实体-关系抽取方法可分为流水线式和联 合学习 式两种. 前者将命 名实体 识别(named entity recognition, NER)和关系分类(relationclassifification, RC)作为两个独立的子任务在完成实体识别之后再进行关系的抽取[15-16]. 前,国内外研究学者在进行三元组抽取从而实现本体自动化构建时,大多使用流水线式方法,这种方法忽略了两个子任务之间的相关性,且会造成误差累积. 最近的研究表明,使用联合学习的方法可以更加紧密地交互实体与关系之间的信息,很好地解决了流水线式方式存在的问题. Zheng等[17] 使用混合BiLSTM-EDCNN的神经网络模型,在实体与关系抽取任务上表现优异; Luo等[18] 提出了一种基于Att-BiLSTM-CRF的联合学习方法,用于生物医学实体和关系提取. 这些模型基于实体关系联合训练的方法进行三元组的抽取,但大多使用公开数据集进行训练,不针对制造业领域.?
本文基于BERT预训练模型,提出一种实体-关系联合抽取模型ErBERT,针对特定下游任务对模型进行微调,并针对钢铁制造行业建立数据集HRDT对模型进行训练,完成制造业领域的人机物三元组抽取.
二、面向人机物数据融合的本体自动化构建方法
2.1 总体架构
本文研究面向制造领域人机物三元数据融合的本体自动构建方法,故立足于制造业,寻找人机物三元数据的各自特征和内在联系是本文研究的必经之路. 在制造业领域,人的数据主要指专家经验、供应商及用户信息,同时人具有处理不确定性信息的能力;机可以处理海量数据,但无法处理不确定性知识,数据主要包括数据库里的结构化表单以及企业信息系统内的信息;物的数据来源于客观存在的实体对象,一般指检测设备和生产设备的数据. 为了实现人机物三元本体的自动化构建,本文设计了如图1所示的体系架构,包括数据采集、三元组抽取和本体存储三部分. 其中,如何从文本数据中自动获取三元组是本文研究的重点内容.
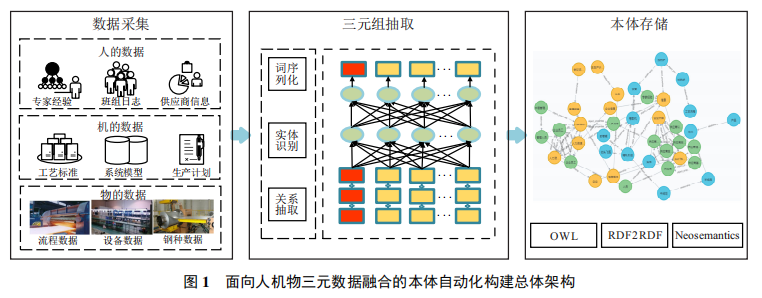
数据采集是指分别以人、机、物作为数据来源,寻找相关的领域特定概念. 人的数据包括专家经验、班组日志以及供应商信息等;机的数据主要来自于企业信息系统,包括工艺制度、生产调度计划以及规则数据等;物的数据由客观存在的数据构成,包括设备数据、钢种数据等. 将采集到的文本数据进行切分,以单句的形式输入至三元组抽取模块.
将切分后的单句作为三元组抽取模块的输入,三元组抽取的主要任务是进行命名实体识别和关系抽取. 本文提出了基于预训练模型BERT的改进算法ErBERT,实现实体、关系的联合抽取,下文进行具体介绍. 三元组抽取以形如?加热炉,包括,点火器?的三元组形式输出至下一部分.
在完成人机物三元组的抽取后,将抽取好的人机物三元组按照规则映射至OWL文件,并将其存储至图数据库中,实现人机物三元本体的自动构建.
2.2基于ErBERT的三元组抽取
三元组抽取是本体的自动化构建任务中极为关键的一步,本文提出的ErBERT模型可以实现实体与关系的联合抽取,其基本流程如图2所示. 在词向量化模块中,使用预训练模型BERT进行词序列化. 将可能的实体向量经最大池化处理,在进行全连接和softmax之后得到实体的类别. 关系分类模块在实体抽取的基础上进行,根据上一步实体抽取的结果,将头尾实体向量与头尾实体之间的词向量经过全连接层与softmax后得到关系分类的结果.
对于输入的单句集合, 首先使用 BERT 预训练模型对其进行分词并向量化. BERT 是 Google AI语言研究人员最近提出的一个预处理模型,在一些自然语言处理任务上表现出超越过往经典模型的优异性能. 输出的向量由词向量 (token embedding)、句向量 (segment embedding) 和位置向量 (positionembedding)组成,相加之后送入双向Transformer结构进行特征提取,最后得到含有丰富语义特征的序列向量. 深层双向Tansformer的模型结构是BERT模型中的核心,使得模型在进行单词的处理时,能够表征单词在上下文中的具体语义. Transformer编码结构采用多头注意力机制,放弃时间循环结构,可以同时处理整个输入序列,多头注意力机制的输出为


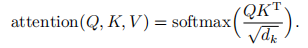
(3)
其中: Q、K、V 矩阵为编码器的输入字向量矩阵;dk为Q、K、V 矩阵的列数,即向量维度.对于一个长度为n的输入序列,t位置对应的向量和ωk定义如下:
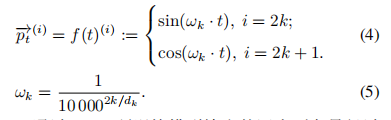
通过BERT预训练模型输出的词序列向量经过最大池化处理,进行平均和之后,与[CLS]向量进行拼接. [CLS]是一个能够表示整个文本的语义特征向量, BERT在输入文本前插入[CLS]符号,并将该符号对应的输出向量作为整个文本的语义表示. 与输入文本中已存在的其他字、词相比较而言, [CLS]作为无明显语义特征的符号,能够更加公平地融合文本中各个字的含义. 经过拼接得到的实体表示xe为

其中: ei为经过最大池化处理过后的词向量表示, c为整个文本的语义表征.最 后, 将 得 到 的 实 体 向 量 xe 送 入 全 连 接 加softmax层,全连接层将前面得到的特征做加权和得到每个类别的分数,再经过softmax映射为概率,计算最有可能的实体标记,公式如下:

完成实体的抽取后进入到关系分类任务. 给定一组预定义的关系类R= {r1, r2, . . . , rj},关系分类模块对处理来自单句中的所有候选实体对,判断其是否存在来自R的关系. 关系分类模块输入由两部分组成,一是在实体识别部分得到的实体向量表示xe,包括词序列向量以及能够表示整个文本的语义特征向量[CLS];二是两个实体之间文本的向量表示,即候选关系向量,在进行最大池化处理后与前后的实体向量进行拼接,送入关系分类器中.公式如下:

其中: cr?为经过最大池化处理后的词序列向量, xe1、xe2为cr前后的实体向量表示.实体和关系分类问题均使用交叉熵作为损失函数计算loss,以衡量同一个随机变量中两个不同概率分布的差异程度,即真实概率分布与预测概率分布之间的差异. 交叉熵函数的值越小,模型预测效果越优异. 关系分类任务的损失函数为
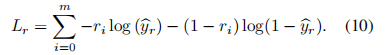
其中: m为样本个数,ri 为类别标签映射而成的onehot向量实体-关系联合抽取的损失函数应表示为实体识别损失函数Le与关系分类损失函数Lr之和,即

2.3基于图数据库的本体存储
经过 ErBERT 进行三元组抽取得到形如? 加热炉,包括,点火器??车间操作工,相关,班组工作日志?等实体关系三元组后,根据规则建立起人机物三元本体的层级结构,并将其映射至OWL文件,完成本体的构建. 构建完的本体以Web本体语言的形式保存在OWL文件中,为了实现快速查询,用于支撑知识推理、知识计算等上层应用,需要进行有效的本体存储.图数据库是一种以图论为理论基础的非关系型数据库,用于存储实体及实体间的关联信息,其基本组成要素是节点、关系和属性. Neo4j是常用的图数据库之一,本文采用Neo4j进行本体的存储. 将映射的OWL文件通过开源工具包RDF2RDF转成RDF格式,再通过Neo4j的功能插件Neosemantics将RDF导入至Neo4j图数据库中,完成本体的存储.
三、案例验证
3.1问题描述
随着国家产能政策的优化调整,供给改革的持续深入,钢铁行业竞争愈加激烈,现代生产中多品种、多规格、个性化生产使得钢铁行业面临日趋复杂的环境. 某钢铁企业连轧产线包括热轧和冷轧两种工艺,同时将多个轧机布置在一条生产线上,从而一次性完成制品的轧制过程,涉及到的流程复杂,设备种类与数量繁多,难以进行有效管理. 热轧生产一般装配步进式加热炉,连铸板坯先后经加热炉加热、除磷箱去除氧化铁皮后,进入粗轧机组进行多道次往复轧制,再经过二次除磷后进行精轧,最后由卷取机卷成热轧卷. 冷轧生产以热轧钢卷为原料,经轧制、退火、酸洗、镀锌及彩图等工序,最终得到冷轧钢板. 在热轧和冷轧实际生产流程中,涉及到日生产计划、车间操作人员、库存以及设备信息等人机物数据,这些数据有的依靠纸张线下传递,有的通过信息系统存储,数据之间缺乏关联性,使得生产车间协同效率低下,信息同步困难,决策知识来源单一. 因此,本课题定位至该企业连轧产线,收集产线生产过程信息,研究基于本体的钢铁连轧产线人机物三元数据融合模型,以增强数据之间的关联性,旨在促进企业内部信息集成,从而提高生产车间协同效率,实现有效的连轧生产管理,对实现连轧生产协同制造具有重要意义.
3.2HRDT数据集
目前, 在三元组的抽取训练中, 最常使用的是ACE 和 CoNLL-04 数据集, 但这些数据集没有针对特定工业领域的子集,且不包含构建本体所需要的层次实体关系. 为了实现人机物三元数据融合的自动化本体构建,针对钢铁制造行业建立了数据集HRDT. HRDT数据集共有778个单句,其中58句来自专家经验,其他从网络上爬取或根据企业提供资料整理而成. 此数据集定义了3种类型的实体, 11种类型的关系,具体如表1和表2所示.

HRDT数据集按照实体来源将实体类别划分为人、机、物三类;关系包括层级关系和其他关系. 层级关系有2种,为Include和Belong_2,意为包括、属于,有明显的层次语义. 在进行本体构建时,需要定义规则,将层级关系和其他关系加以区分,以完成本体的层次结构建立。
3.3实验结果
本文将HRDT数据集随机分为训练集(80 %),验证集 (10 %) 和测试集 (10 %) 输入至 ErBERT 模型中进行实验,采用精确率、召回率和F1值评价算法的性能,评价指标定义如下:

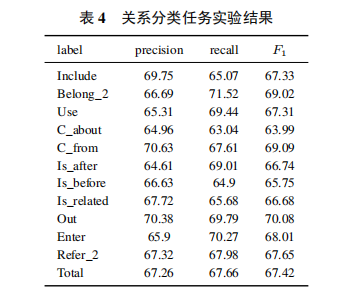
其中: Ncorrect?为预测正确的实体或关系个数, Nall 为预测的实体或关系总个数, Nmarked?为标注的实体或关系总个数.实验结果如表3和表4所示. 由表中数据可知,本文提出的ErBERT模型在实体识别和关系分类任务上有较好的准确率.

经ErBERT模型后得到的人机物实体关系三元组通过定义的规则建立起层级结构,映射至OWL文件后,再将其通过RDF2RDF和Neosemantics存储至Neo4j中. 融合后人机物三元数据具体如图3所示,节点的不同颜色代表不同的数据来源. 黄色节点为物的数据,包括设备数据、钢种数据等; 蓝色节点为机的数据,包括工艺制度、生产调度计划以及规则数据等; 绿色节点为人数据,包括专家经验、供应商数据和人员部门信息等. 人、机、物的节点相互关联、相互交融,增强了人机物数据之间的关联性,实现了人、机、物三元数据在语义层次上的深度融合.
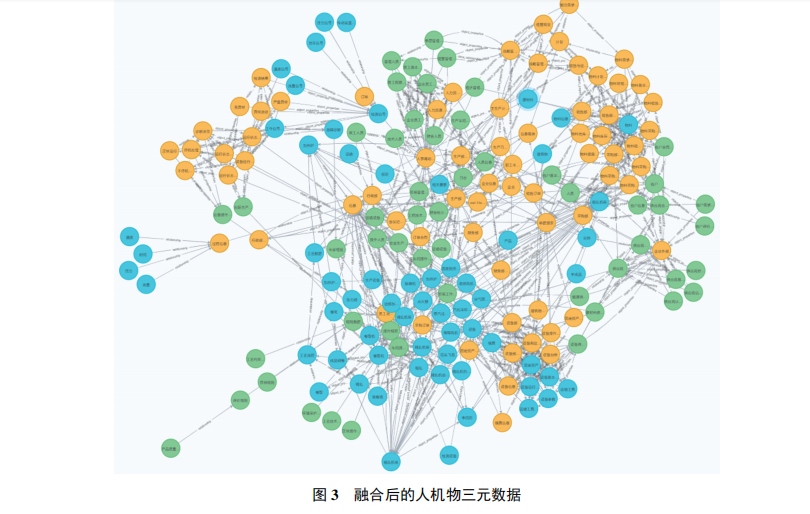
融合后的本体模型可以解决传统人机物独立运作模式不能充分利用人机物优点、无法发挥协同机制优势的问题. 经领域专家的评定,通过ErBERT构建的人机物三元本体起到了融合制造领域人机物三元数据的作用. 研究提出的基于本体的人机物三元数据融合模型能够充分利用本体对多源异构大规模知识的组织和管理优势,有效地进行企业信息集成,提升企业在人机物等更大范畴处理海量数据的综合决策能力,为研究数据驱动的人机物三元协同决策与优化提供了坚实的技术支撑.
结? ?论
本文提出了基于本体的人机物三元数据融合模型,并在抽取三元组时区别于传统的流水线式抽取方式,采用实体-关系联合抽取的模型ErBERT. 该模型首先经过预训练模型BERT进行词序列化,经过最大池化、全连接和softmax等操作后得到实体与关系的类别,完成三元组的抽取;然后将抽取好的三元组按照规则映射至OWL文件中,完成本体的构建;最后将三元本体存储在Neo4j中,实现有效的本体存储.
所提出的实体-关系联合抽取模型ErBERT的优势在于使命名实体识别和关系分类任务共享底层神经网络;且在两个任务之间,信息拥有更加紧密的联系. 实验表明,经过ErBERT抽取出的三元组有较好的准确率,本文最终构建的本体得到了领域专家的一致认可,达到了通过本体融合人机物三元数据的目标,为实现企业人机物三元协同决策与优化提供了技术支撑.
面对复杂多变的制造环境,基于数据驱动,发挥人机物协同运行的优势已成为探索自主智能工厂控制与决策科学命题的主导方向. 基于本体的人机物多维工业大数据融合将驱动后续知识发现、智能工厂自学习知识图谱建模及其进化机制、基于自学习知识图谱智能推理的决策与优化理论的建立,使得企业决策与优化转变为人机物紧密协同合作模式. 在接下来的研究中,将探索智能工厂自学习知识图谱建模及其进化机制,同时将进行数据驱动的人机物三元协同决策与优化理论方法研究,以解决复杂制造环境下企业决策与优化所面临的巨大挑战,有力地推动企业综合决策与优化科学研究从以专家经验为主向数据驱动的模式转变.
?关注微信公众号人工智能技术与咨询?了解更多

