ר������:
���ѧϰ֪ʶ���ܽ�_Mr.С÷�IJ���-CSDN������ר����Ҫ�ܽ����ѧϰ�е�֪ʶ��,�Ӹ������ݼ�������ʼ,��������ھ��㷨;ͬʱ�ܽ����ѧϰ����Ҫ��֪ʶ��,������ʧ�������Ż��������־����㷨�������㷨���Ż�����Bag of Freebies (BoF)�ȡ�
���½�����RNN��Attention��Transformerϵ��-RNN
Ŀ¼
3.1 RNN
3.1.1 RNN����
????????ѭ��������(Recurrent Neural Network, RNN)��һ��������(sequence)����Ϊ����,�����е��ݽ�������еݹ�(recursion)�����нڵ�(ѭ����Ԫ)����ʽ���ӵĵݹ�������(recursive neural network)��
????????��ѭ����������о�ʼ�ڶ�ʮ����80-90���,���ڶ�ʮһ���ͳ���չΪ���ѧϰ(deep learning)�㷨֮һ,����˫��ѭ��������(Bidirectional RNN, Bi-RNN)�ͳ����ڼ�������(Long Short-Term Memory networks,LSTM)�dz�����ѭ�������硣
????????ѭ����������м����ԡ�������������ͼ���걸(Turing completeness),����ڶ����еķ�������������ѧϰʱ����һ�����ơ�
????????ѭ������������Ȼ���Դ���(Natural Language Processing, NLP),��������ʶ�����Խ�ģ�����������������Ӧ��,Ҳ�����ڸ���ʱ������Ԥ���������˾���������(Convolutional Neural Network,CNN)������ѭ����������Դ���������������ļ�����Ӿ����⡣

?????????ÿ�����ζ���һ������,��ͷ��ʾ����(�������˷�)����������Ϊ��ɫ,�������Ϊ��ɫ,��ɫ��������RNN��״̬(�Ժ���ϸ����)��
������:
- û��RNN����ͨ����ģʽ,�ӹ̶���С�����뵽�̶���С�����(����ͼ�����)��
- ?�������(����,ͼ����Ļ����ͼ��������ʾ���)��
- ��������(����,��������,���и����ľ��ӱ�����Ϊ�������������������)��
- ����������������(�����������:RNN��Ӣ���ȡ����,Ȼ���÷����������)��
- ͬ��������������(����,����ϣ�������Ƶ��ÿһ֡����Ƶ����)����ע��,��ÿ�������,���������϶�û��Ԥ��ָ����Լ��,��Ϊѭ���任(��ɫ)�ǹ̶���,���Ը�����Ҫ���Ӧ�á�
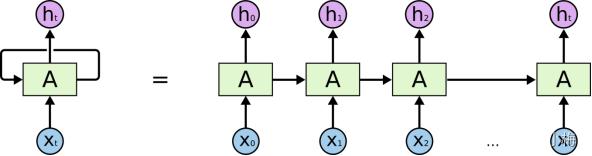
RNN�Ļ�����״:


?չ����:

ע��:
- �����W,U,V��ÿ��ʱ�̶�����ȵ�(Ȩ�ع���).
- ����״̬��������Ϊ: ?S=f(���е�����+��ȥ�����ܽ�)
�ô���ʵ��RNN:
import numpy as np
class RNN:
# ...
def step(self, x):
# update the hidden state
self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))
# compute the output vector
y = np.dot(self.W_hy, self.h)
return y?һ�� RNN ������������,�ڶ��� RNN ���յ�һ�� RNN �������Ϊ�����롣
չ��������:
3.1.2 PyTorch��RNN�ļ���
Pytorch��RNN�Ķ���:
torch.nn.RNN(*args,?**kwargs)

��ʼ��RNN�������:
Parameters
- input_size �C ����x��������,����ÿ�仰��ÿ�����ʵ�������
- hidden_size �C ���ز�������,һ�����RNN�����������
- num_layers �C ���ز����,Ĭ��Ϊ1
- nonlinearity �C �����Ժ��� 'tanh' or 'relu'. Default: 'tanh'
- bias �C �Ƿ�ʹ��bias( b_ih and b_hh). Default: True
- batch_first �C �������ΪTrue�Ļ�,����batchsize�ŵ�ǰ��,Default: False
- dropout �C Default: 0
- bidirectional �C ����ΪTrue���˫��RNN Default: False
ʹ��RNNʱ���������:
Inputs: input, h_0
- input: batch_first=Falseʱ�ߴ�Ϊ(L,N,
)?,batch_first=Trueʱ�ߴ�Ϊ(N, L,
- h_0:����ߴ�Ϊ(D?num_layers,N,
) ,������ʱĬ��Ϊ0��
RNN�����:
Outputs: output, h_n
- ?output:��batch_first=Falseʱ����ߴ�Ϊ(L, N, D * H_{out});��batch_first=Trueʱ����ߴ�Ϊ(N, L, D * H_{out})?
- h_n:(D?num_layers,N,Hout) ��������״̬����
���ϸ�����ĸ�Ľ���:
- N=batch size
- L=sequence length�������еij���
- D=2 if bidirectional=True otherwise 1
RNN�п�ѵ���IJ���
- RNN.weight_ih_l[k] �C ��k�������-���ز�Ȩ��k = 0ʱshape=(hidden_size, input_size) ,k>0ʱshape=(hidden_size,num_directions * hidden_size)
-
RNN.weight_hh_l[k] �C ��k������-���ز�Ȩ��,shape=(hidden_size, hidden_size)
-
RNN.bias_ih_l[k] �C ��k�������-���ز�bias,shape=(hidden_size)
-
RNN.bias_hh_l[k] �C ��k������-���ز�bias,shape=(hidden_size)
?���п�ѵ��������ʼ����Χ(-sqrt(k),sqrt(k)),k=1/(hidden_size)
3.1.3?RNN�ֶ�������֤
PyTorch�ļ�����
import torch
import torch.nn as nn
torch.random.manual_seed(654)
rnn = nn.RNN(input_size=1, hidden_size=3,
num_layers=1, bidirectional=False,
nonlinearity='relu', bias=False)
print(rnn.weight_ih_l0)
'''''shape(1,3)
[[0.4389],
[0.3772],
[-0.3647]]
'''
print(rnn.weight_hh_l0)
'''shape(3,3)
[[0.3091,-0.0224,0.4010],
[-0.1867,-0.5099,0.4860],
[0.4007,0.2936,0.1126]]
'''
h0 = torch.ones((1, 2, 3))
'''
h10=[[[1.,1.,1.],
[1.,1.,1.]]]
'''
x = torch.randn((5, 2, 1)) # shape(sequence length,batchsize,input_size)
print(x)
'''shape(5,2,1)
[[[0.1416],
[0.6004]],
[[-1.1653],
[-2.1373]],
[[1.3519],
[-0.7998]],
[[-0.2477],
[0.1398]],
[[0.2404],
[0.3897]]]
'''
output, hidden = rnn(x, h0)
print(output)
print(output.shape)
'''shape=[5,2,3]
[[[0.7498,0.0000,0.7552],
[0.9512,0.0159,0.5879]],
[[0.0232,0.0000,0.8105],
[0.0000,0.0000,1.2314]],
[[0.9255,0.8995,0.0000],
[0.1428,0.2968,0.4304]],
[[0.1572,0.0000,0.7252],
[0.2714,0.0839,0.1419]],
[[0.4449,0.4138,0.0570],
[0.3099,0.1225,0.0073]]]
'''
print(hidden)
print(hidden.shape)
'''shape=[1,2,3]
[[[0.4449,0.4138,0.0570],
[0.3099,0.1225,0.0073]]]
'''�ֶ�������֤
'''
h0 = 1,1,1,... -> shape(1,2,3)
x -> shape(5,2,1) ��������,�൱��batchsize=2,������5����,ÿ���ʵ�����ά����1
[[[ 0.1416],
[ 0.6004]],
[[-1.1653],
[-2.1373]],
[[ 1.3519],
[-0.7998]],
[[-0.2477],
[ 0.1398]],
[[ 0.2404],
[ 0.3897]]]
Wih -> shape(1,3) ��rnn.weight_ih_l0����㵽���ز�֮��IJ���
[[ 0.4389],
[ 0.3772],
[-0.3647]]
Whh -> shape(3,3)����rnn.weight_hh_l0���ز㵽���ز�֮��IJ���
[[ 0.3091, -0.0224, 0.4010],
[-0.1867, -0.5099, 0.4860],
[ 0.4007, 0.2936, 0.1126]]
��ʼ�������ز���� shape(1,2,3)
h10 = [[[1., 1., 1.],
[1., 1., 1.]]]
# ��������x�ĵ�һ����x[0] �����������
U��Xt=torch.matmul(torch.unsqueeze(x[0],0),rnn.weight_ih_l0.T)
W��S10=torch.matmul(torch.ones((1,2,3)),rnn.weight_hh_l0.T)
�õ���һ�����ʵ����
S11 = ReLU(Wih��x0 + Whh��h10)
= ReLU(
[[[0.1416],
[0.6004]]]
��
[[ 0.4389],
[ 0.3772],
[-0.3647]].T
+
[[[1., 1., 1.],
[1., 1., 1.]]]
��
[[ 0.3091, -0.0224, 0.4010],
[-0.1867, -0.5099, 0.4860],
[ 0.4007, 0.2936, 0.1126]].T
)
= ReLU([[[ 0.7498, -0.1572, 0.7552],
[ 0.9512, 0.0159, 0.5879]]])
=[[[0.7498, 0.0000, 0.7552],
[0.9512, 0.0159, 0.5879]]]
��һ�����ʵ������Ϊ�ڶ������ʵ����
U��Xt==torch.matmul(torch.unsqueeze(x[1],0),rnn.weight_ih_l0.T)
W��S11=torch.matmul(torch.tensor([[[0.7498, 0.0000, 0.7552],
[0.9512, 0.0159, 0.5879]]]),rnn.weight_hh_l0.T)
�õ��ڶ������ʵ����
S12 = ReLU(Wih��x1 + Whh��h12)
= ReLU(
[[[-1.1653],
[-2.1373]]]
��
[[ 0.4389],
[ 0.3772],
[-0.3647]].T
+
[[[0.7498, 0.0000, 0.7552],
[0.9512, 0.0159, 0.5879]]]
��
[[ 0.3091, -0.0224, 0.4010],
[-0.1867, -0.5099, 0.4860],
[ 0.4007, 0.2936, 0.1126]].T
)
= ReLU([[[ 0.0232, -0.2125, 0.8104],
[-0.4085, -0.7062, 1.2314]]])
=[[[0.0232, 0.0000, 0.8104],
[0.0000, 0.0000, 1.2314]]]
....
��������������,���õ�
out = torch.vstack([S11,S12,S13,S14,S15])
�������ز������Ϊ���һ��out,��out[-1]
hn = h15
'''3.1.4?RNN���ڵ�����
????????��������������
????????RNN��������֮һ�����ǿ����ܹ�����ǰ����Ϣ�뵱ǰ������ϵ�������뷨,����ʹ����ǰ����Ƶ֡���ܻ��֪�Ե�ǰ֡�����⡣���RNN����������һ��,���ǽ��dz����á�����������������?��Ҫ�����������
????????��ʱ,����ֻ��Ҫ�鿴�������Ϣ����ִ�е�ǰ��������,����һ������ģ��,��ģ����ͼ����ǰһ������Ԥ����һ�����ʡ����������ͼԤ�⡰the clouds are in the sky���е����һ����,���Dz���Ҫ�κν�һ���������� - ������,��һ���ʽ���sky�������������,��������Ϣ����Ҫ���ĵط�֮��IJ���С,RNN����ѧϰʹ�ù�ȥ����Ϣ��
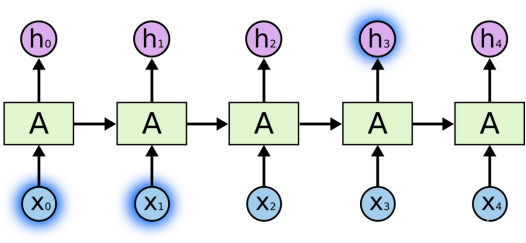
????????����ijЩ�����,������Ҫ����ı��������dz���Ԥ���ı��е����һ���ʡ����ڷ�������......��˵һ�������ķ���������Ϣ����,��һ���ʿ�����һ�����Ե�����,�������������С�������Եķ�Χ,������Ҫ������������,�Ӹ�Զ�ĵط��������Ϣ����Ҫ���ĵ�֮��IJ����ȫ�п��ܱ�÷dz���
????????���ҵ���,�������ֲ�������,RNN��ѧ��������Ϣ��
????????���Ǿ����˺�����LSTM��

