(1) 人工智能领域网络公开的标注测试图像数据集介绍
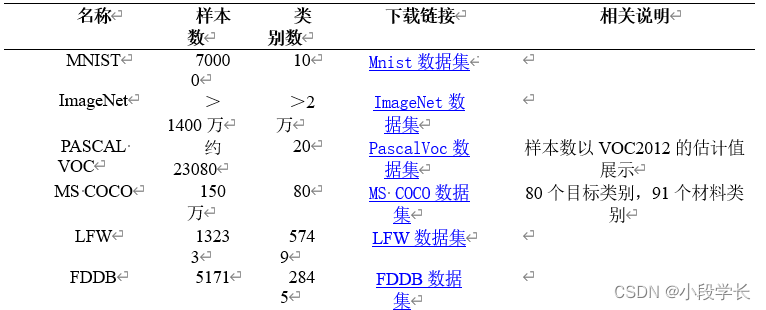
① MNIST
MNIST是一个入门级的计算机视觉数据集,官网给定的数据集分为四个文件,分别是训练及图像和训练集标签、测试集图像和测试集标签。每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。训练集有60000行数据,测试集有10000行数据,MNIST数据集的标签是介于0到9的数字,标签数据为One-Hot向量(One-Hot编码,即独热编码,其方法是使用 N位状态寄存器来对 N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。)
② ImageNet
ImageNet是一个用于视觉对象识别软件研究的大型可视化数据库,用于图片识别物体。它由美国斯坦福的计算机科学家李飞飞模拟人类的识别系统建立的。目前已经包含14197122张图像,是已知的最大的图像数据库。ImageNet包含2万多个类别,每个类别中包含至少五百个图像。第三方图像URL的注释数据库可以直接从ImageNet免费获得。ImageNet就像一个网络一样,拥有多个Node(节点)。每一个node相当于一个item或者subcategory。ImageNet的结构基本上是金字塔型:目录→子目录→图片集。
③ PASCAL VOC
PASCAL VOC数据集是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。常用于目标检测、图像分割等任务。PASCAL VOC从2005年开始举办挑战赛,每年的内容都有所不同,从最开始的分类,到后面逐渐增加检测,分割,人体布局,动作识别等内容,数据集的容量以及种类也在不断的增加和改善。发展到目前为止,该数据集共有4个大类:Vehicle,Household,Animal,Person;每个大类细分为不同的小类,小类共计20类。
对于现在的研究者来说比较重要的两个年份的数据集是 PASCAL VOC 2007与PASCAL VOC 2012。VOC 2007的一些示例图片展示:Classification/detection example images。VOC 2012的一些示例图片展示:Classification/detection example images。VOC 2007与VOC 2012的数据集及二者的并集数据量对比如下图:

图1 VOC 2007与VOC 2012的数据集对比
黑色字体所示数字是官方给定的,由于VOC2012数据集中 test 部分没有公布,因此红色字体所示数字为估计数据,按照PASCAL 通常的划分方法,即 train+val 与test 各占总数据量的一半。
④ MS COCO
COCO的全称是Common Objects in Context,是微软团队提供的一个可以用来进行图像识别的数据集。它包括了目标检测、分割、图像描述等。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包91类目标(stuff categories),328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80类(object categories),有超过33万张图片,其中20万张有标注,整个数据集中个体的数目超过150万个。COCO有5种类型的标注,分别是:物体检测、关键点检测、实例分割、全景分割、图片标注,都是对应一个JSON文件。
⑤ LFW(Labeled Faces in the Wild)
LFW (Labeled Faces in the Wild) 人脸数据库是由美国马萨诸塞州立大学阿默斯特分校计算机视觉实验室整理完成的数据库,主要用来研究非受限自然场景情况下的人脸识别问题。LFW 数据库主要是从互联网上搜集图像,包含了13233张来自5749个人的人脸图片,其中有1680个人至少有2张图片。根据官方声明,LFW的数据量不够大,许多群体在其中没有得到良好体现,如:其中,80岁以上的老人和儿童数量很少,没有婴儿,女性比例较低,且有许多种族的样本稀有或没有。除此之外,LFW是‘in the wild’的,所以有许多不理想的因素,如照明条件差、姿势极端、遮挡严重、分辨率低等。
⑥ FDDB(Face Detection Data Set and Benchmark)
FDDB数据集主要用于约束人脸检测研究,该数据集选取野外环境中拍摄的2845个图像,包含彩色以及灰度图,从中选择5171个人脸图像。这些人脸所呈现的状态多样,包括遮挡、罕见姿态、低分辨率以及失焦的情况。因此是一款专门针对人脸识别算法的评测方法与标准被广泛使用的权威的人脸检测。
表1 常见图像数据集汇总
(2) 常用图像数据标注软件介绍
① Labelme
Labelme 是一个图形界面的图像标注软件。用 Python 语言编写,图形界面使用的是Qt(PyQt)。可以对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注,可用于目标检测,图像分割,等任务;也可对图像或视频进行进行flag形式的标注,用于图像分类和清理任务。
② VoTT
VoTT是微软发布的用于图像目标检测的标注工具,它是基于javascript开发的,因此可以跨Windows、Linux和Mac平台运行,并且支持从图片和视频读取标注。此外,其还提供了基于CNTK训练的faster-rcnn模型进行自动标注然后人工矫正的方式,这样大大减轻了标注所需的工作量。
③ CVAT
Opencv组织出品的一个非常优秀的在线图像标注系统。该系统非常贴心地提供了半自动标注功能,基于tensorflow实现,在官方的demo系统中使用bfaster rcnn模型进行了自动标注,同时cvat支持非常多种的数据导出方案,十分的方便。
④ LabelImg
LabelImg 是一个可视化的图像标定工具。Faster R-CNN,YOLO,SSD等目标检测网络所需要的数据集,均需要借此工具标定图像中的目标。生成的 XML 文件是遵循 PASCAL VOC 的格式的。使用labelImg时要注意更改源图片目录以及打完label后的xml文件存储路径。即打开LabelImg之后,点击Open Dir,选中源图片目录。点击Change Save Dir,选中保存xml文件的文件夹。我的源图片路径是在JPEGImages文件夹中,xml存储路径是Annotations文件夹中。
(3) 吸烟行为检测图像数据集的采集与标注
采集形式: 利用python爬虫爬取网络图片、实地拍摄
途径: 拍摄附近抽烟人士
设备: HUAIWEI P30
时间: 2022年3月17日
地点: 宿舍
注意事项: 征求他人同意后拍摄
(1) 常见图像数据集的读取与显示
① MNIST
from keras.datasets import mnist
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
print(train_images.shape,test_images.shape)
print(train_images[1])
print(train_labels[1])
plt.imshow(train_images[1])
plt.show()
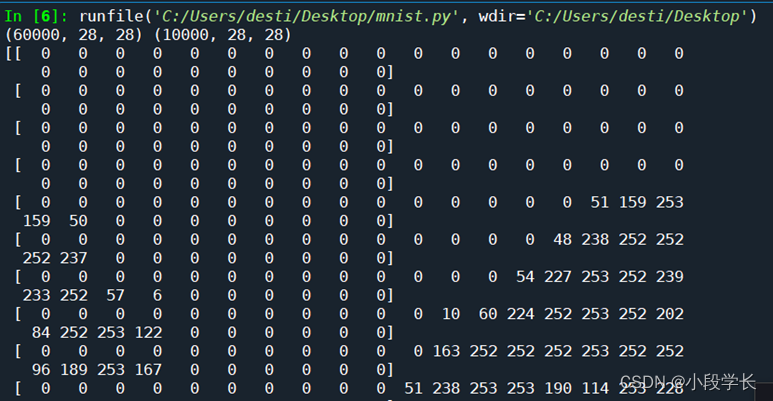
图2.1 MNIST数据读取结果
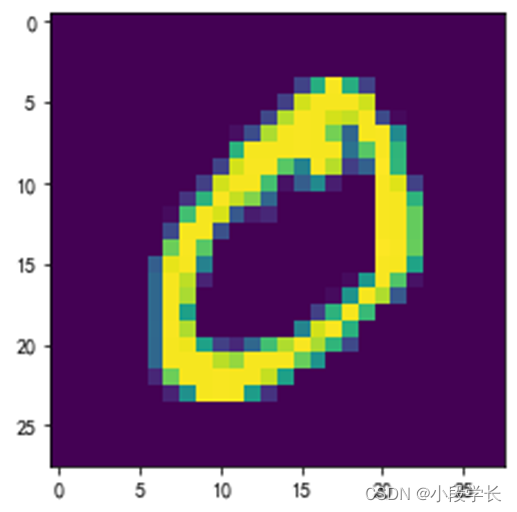
图2.2 MNIST图像显示示例
② CIFAR-10
from keras.datasets import cifar10
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = cifar10.load_data()
print(train_images.shape,test_images.shape)
print(train_images[1])
print(train_labels[1])
plt.imshow(train_images[1])
plt.show()
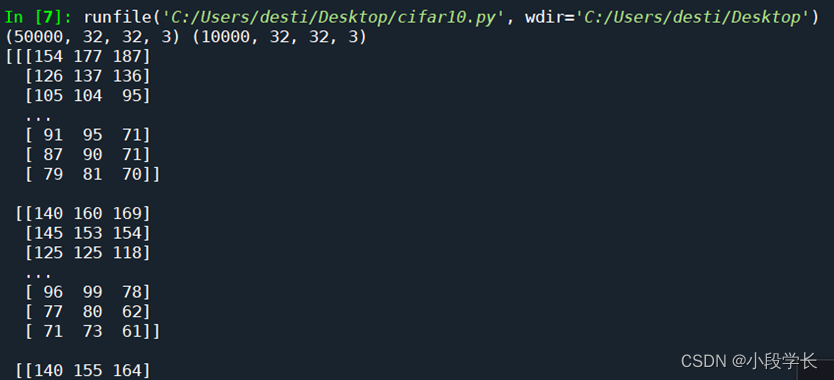
图3.1 CIFAR-10数据读取结果
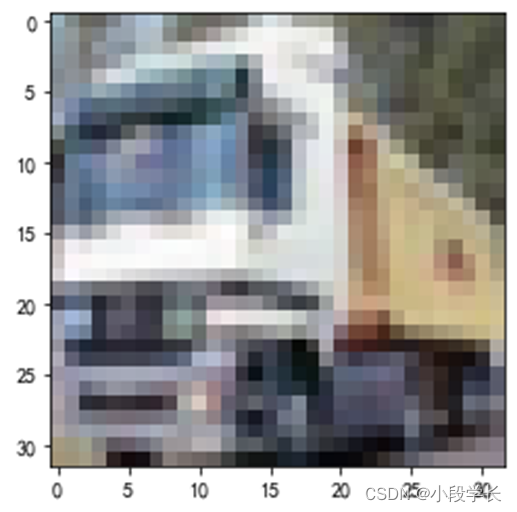
图3.2 CIFAR-10图像显示示例
③ CIFAR-100
from keras.datasets import cifar100
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = cifar100.load_data()
print(train_images.shape,test_images.shape)
print(train_images[2])
print(train_labels[2])
plt.imshow(train_images[2])
plt.show()

图4.1 CIFAR-100数据读取结果
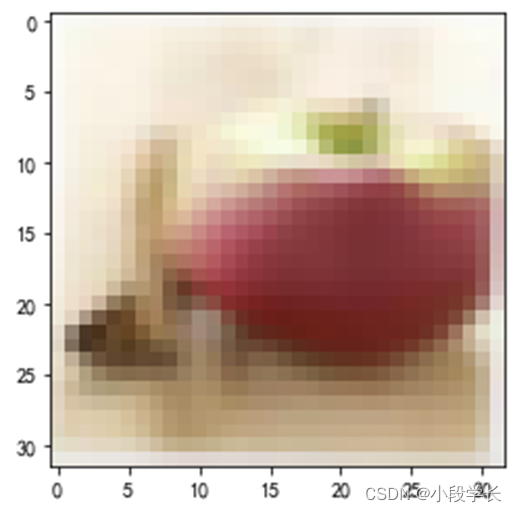
图4.2 CIFAR-100图像显示示例
④ fashion mnist
from keras.datasets import fashion_mnist
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
print(train_images.shape,test_images.shape)
print(train_images[1])
print(train_labels[1])
plt.imshow(train_images[1])
plt.show()

图5.1 FASHION MNIST数据读取结果
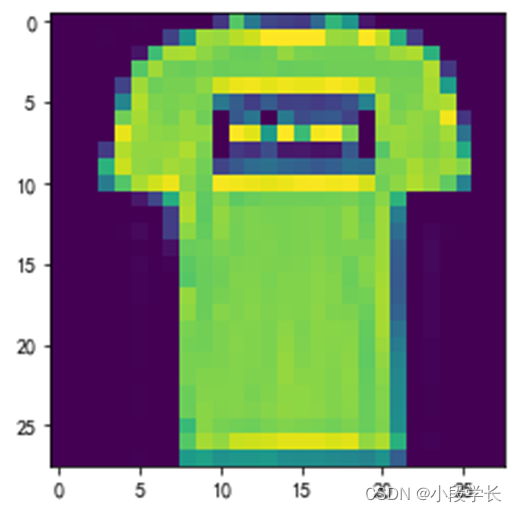
图5.2 FASHION MNIST图像显示示例
⑤ Olivett
from sklearn import datasets
import matplotlib.pyplot as plt
faces = datasets.fetch_olivetti_faces(data_home=None, shuffle=False, random_state=0, download_if_missing=True)
i = 0
plt.figure(figsize=(20, 20))
for img in faces.images:
#总共400张图,把图像分割成20X20
plt.subplot(20, 20, i+1)
plt.imshow(img, cmap="gray")
#关闭x,y轴显示
plt.xticks([])
plt.yticks([])
plt.xlabel(faces.target[i])
i = i + 1
plt.show()
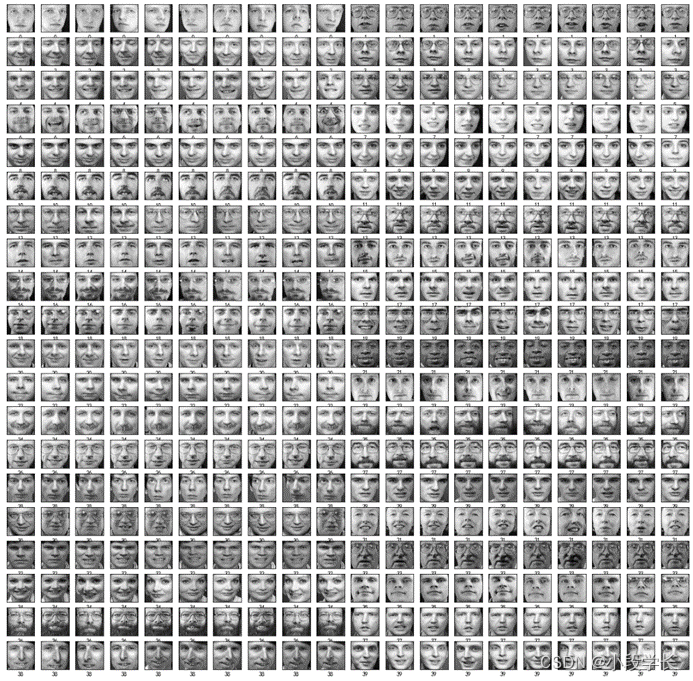
图6 Olivett脸部图片数据集结果显示
⑥ LFW
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people()
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
for i in range(64):
img = faces.images[i]
#总共400张图,把图像分割成20X20
plt.subplot(8, 8, i+1)
plt.imshow(img, cmap="gray")
#关闭x,y轴显示
plt.xticks([])
plt.yticks([])
plt.xlabel(faces.target[i])
i = i + 1
plt.show()

图7 LFW人脸匹配数据集结果显示
(2) 吸烟行为检测图像数据集的网络爬虫
'''
爬取指定关键字图片
'''
import re# 正则表达式,解析网页
import requests# 请求网页
import traceback
import os
def dowmloadPic(html,keyword,startNum):
headers = {'user-agent':'Mozilla/5.0'} # 浏览器伪装,因为有的网站会反爬虫,通过该headers可以伪装成浏览器访问,否则user-agent中的代理信息为python
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) # 找到符合正则规则的目标网站
i = startNum
subroot = root + '/' + word
for each in pic_url:
path = subroot + '/' + str(i+1)
try:
if not os.path.exists(subroot):
os.mkdir(subroot)
if not os.path.exists(path):
pic = requests.get(each,headers = headers,timeout = 10)
with open(path+'.jpg','wb') as f:
f.write(pic.content)
f.close()
except:
traceback.print_exc()
print ('当前图片无法下载')
continue
i += 1
return i
if __name__ == '__main__':
headers = {'user-agent':'Mozilla/5.0'}
words = ['吸烟'] #words为一个列表,可以自动保存多个关键字的图片
root = '有关'
for word in words:
root = root + ' “' + word + '” '
root += '的图片'
if not os.path.exists(root):
os.mkdir(root)
for word in words:
lastNum = 0
if word.strip() == "exit":
break
pageId = 0
#此处的参数为需爬取的页数,设置为2页
for i in range(3):
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + "&pn="+str(pageId)+"&gsm=?&ct=&ic=0&lm=-1&width=0&height=0"
pageId += 15#好像没啥影响
html = requests.get(url,headers = headers)
# print(html.text) #打印网页源码,相当于在网页中右键查看源码内容
lastNum = dowmloadPic(html.text, word, lastNum,)#本条语句执行一次获取60张图
print('正在下载中,请稍后...')
图8 吸烟图片爬取结果显示
(3) 吸烟行为检测图像数据集的标注
① 在labelImg中打开图像所在的文件夹;
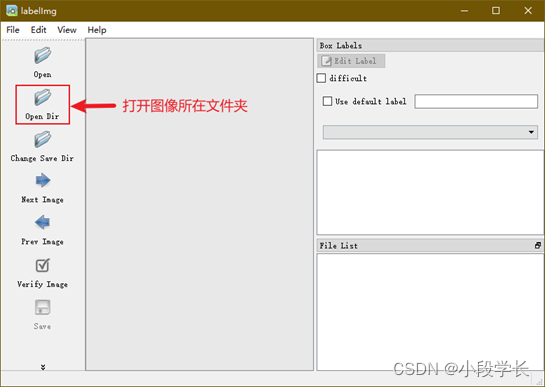
图9.1 打开图像所在文件夹
② 改变图像标注后的保存路径;
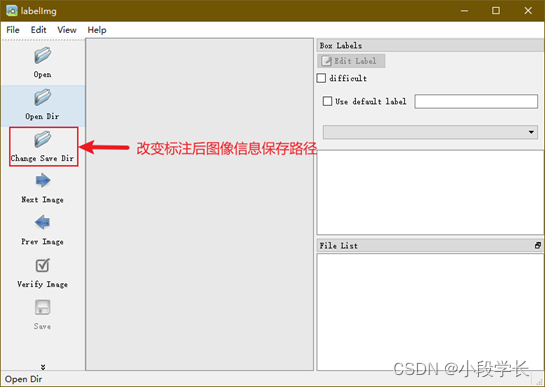
图9.2 改变图像标注后的保存路径
③ 将图像标注并分类保存;
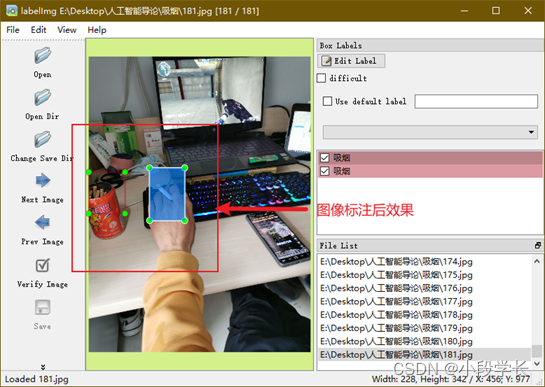
图9.3 图片标注并分类保存
<!--标注的框体位置信息以及其他信息-->
<annotation verified="yes">
<folder>吸烟</folder>
<filename>181.jpg</filename>
<path>E:\Desktop\人工智能导论\吸烟\181.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>1440</width>
<height>1920</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>吸烟</name>
<pose>Unspecified</pose>
<truncated>1</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1</xmin>
<ymin>751</ymin>
<xmax>236</xmax>
<ymax>1020</ymax>
</bndbox>
</object>
</annotation>
(1) 安装labelImg后Anaconda中的Spyder无法打开
解决方法:由于labelImg与Spyder所需的PyQt依赖的版本不同,所以安装labelImg时需要新建虚拟环境,以此来保证PyQt的版本不同。
(2) 使用conda install labelImg命令安装好labelImg之后,输入labelImg命令无法打开labelImg
解决方法:labelImg安装好后,仅有一个labelImg.py文件,所以需要进入到安装的目录中才能打开labelImg,例如:
(base) E:>conda activate deepLearning
(deepLearning) E:>cd D:\Anaconda\envs\deepLearning
Lib\site-packages\labelImg
(deepLearning) D:\Anaconda\envs\deepLearning\Lib
site-packages\labelImg>labelImg
结果分析与体会
当前人工智能发展的三大要素:数据、计算力和算法,知道数据集、计算力和算法是相辅相成、相互提升的,三者缺一不可。数据是基础,任何研究都离不开数据,除了数据之外,计算能力也非常关键。深度学习算法之所以可以兴起,一方面是大规模数据的出现,另一方面得益于高性能计算,可以让庞大的模型能够被很好的拟合。在学界,数据集的意义更加直接:没有数据集,就无法展开相应的研究工作。所以在确定研究课题后,最为首要的任务就是获得相应的数据集,通常有这样几种方案:第一、确定特定研究方向后,在网络上查找是否有公开、共享的数据集;第二、如果该研究方向当前没有公开数据集或者公开数据集不适合自己的具体研究问题,那就可能需要亲自去创建新的数据集。在这次实验中我们就使用了第一种方法,在网上寻找公开的、可共享的数据。
数据标注分类分为三类:图像标注、语音标注和文本标注。图片标注的场景目前应用还是非常广的,主要的标注方法有,点标、框标、区域标注、3D标注、分类标注等等,应用场景如安防、教育、自动驾驶等等也非常多,目前落地比较成熟的要数人脸识别了,不管是在做一些身份识别验证还是出门做地铁、高铁都有可能用到。语音应答交互也是目前重要的分支,所以在此类语音虚拟助理的研发中,基于语音识别、声纹识别、语音合成等建模与测试需要,需要对数据进行发音人角色标注、环境场景标注、多语种标注、ToBBI(Tones and Break Indices)韵律标注、体系标注、情感标注、噪声标注等。自然语音处理是人工智能的分支科学,为了满足自然语音处理不同层次的需求,对于文本数据进行标注处理是关键环节。具体而言,通过语句分词标注、语义判定标注、文本翻译标注、情感色彩标注、拼音标注、多音字标注、数字字符标注等,可提供高准确率的文本预料。
数据部分包含数据收集、数据标注、标注测试、数据样本库和数据处理等步骤。包含两个环,一个是从数据处理接入到模型训练测试后返回数据标注的环,该环表示模型训练测试后对于失败样例重新对数据进行标注后对模型优化的循环过程;另一个是在生产服务系统中,真实场景数据回流,通过该方式可以有效的解决线上数据特征漂移的问题。数据收集指训练数据从哪里来,主要包括4种来源:公开数据集、数据采购或采集、数据回流以及生成数据。
数据筛选是指从收集到的数据中筛选或清洗掉不合格的数据,留下有效数据。在实际生产系统运行时源源不断的回流数据需要合理有效的方法去利用。通过这种方法希望可以做到通用清洗能力(默认对图像):去相似,去模糊,裁剪,旋转,镜像以及高级清洗能力比如根据任务过滤,人脸数据集则自动过滤无人脸图片,人体数据集则过滤无人体图片。
数据标注:在对比标注工具时,重点关注的是对多人协同功能的支持,以及一些基础的标注功能的实现。使用Computer Vision Annotation Tool(CVAT)工具来完成这种对这部分的完成。工具能实现多种任务标注支持,分割、分类、跟踪。支持矩形、多边形、多段线、点、长方体、Tag等功能。CVAT具有支持多人协作、能用于几乎所有CV相关标注任务、支持导入模型,进行半自动标注的优点。
数据质检:对数据进行质量检测,通过提供客观指标,为对数据集的下一步操作(标注、训练等)进行参照引导。有两种指标:整体指标和分布指标,整体指标包括:数据集存储大小、图片数量、破损图像数、标签合格率;分布指标包括:色彩分布空间、图像存储大小分布、高宽比分布、分辨率分布、色偏分布、标注框宽高比分布、标注框面积分布等等。数据质检是为了客观评估数据质量。对于数据标签标注质量可以选择通过CVAT查看成员的标注结果,但是量化评估数据的各项指标暂无开源工具。
数据版本管理:对数据集的增加、修改、删除、格式转换、发布等等操作进行跟踪和版本管理。为了实现方便,操作简单,复现简单的目标,数据版本管理可以使用DVC(Data Verion Control)工具实现,这是一个数据和机器学习模型实验管理工具, 底层是基于Git实现的,但相对于Git,DVC的优点是能够跟踪和存储大文件(数据和模型权重文件),而这也是它能够支持数据集版本管理的基础。支持的存储方式包括本地、Amazon S3, SSH, Google Drive,Azure Blob Storage 和 HDFS等。所以说,用DVC管理数据集过程和共享方式基本与用Git管理代码的过程一样。DVC 仅支持到模型训练测试这一步,对于部署相关功能并不支持。选择DVC的原因是因为:第一,DVC支持对大文件跟踪。第二,DVC支持跟踪对数据做的操作,比如过滤、转换或用于训练模型,跟踪整个操作流,复现很方便。DVC同样支持模型管理,但与MLflow相比,DVC有如下缺点:第一、多人协同:没有一个统一的界面管理多人模型,如何管理多人的模型,并显示模型的开发阶段(比如实验中,已发布,撤回等等)第二、部署支持:DVC 不涉及部署相关的任何支持。第三、环境依赖:MLflow提供了对环境依赖的打包,方便一键复现,而DVC不支持。
数据是人工智能算法发展的基础,“没有免费的午餐”是学界公认的道理,任何算法都不能脱离数据或者应用场景来谈效果的好坏。对于做算法的小伙伴来说,虽然在研究算法的创新,但是如何选择和利用数据集是研究的基础,再优秀的算法也要通过数据来评估它的效果。算法的最终目的是要拟合这种趋势或者分布,不同的数据集的特征分布是不同的,甚至同一个数据集划分方式和比例的不同都也会使得特征的分布存在差异,因此找到合适的数据并做好适当的预处理,可以更加体现算法的能力,使得研究更具说服力。目前机器学习的数据集种类包含图像数据,时序数据,离散数据等,而不同数据集对应的任务可以分类、回归或者两者兼顾。那么我们在研究过程中选择数据集除了一些如 MNIST 等经典数据集外,还需要根据自身模型特点选择具有相应特征的数据。另外,数据集的大小也是需要考虑的一个因素。一般来讲,一些经典的早期的数据集包含的数据量都比较少,更适合小规模的模型。而近年来随着算力的增强和大数据技术的普及,近年的数据集普遍会包含更多的数据,大规模数据集所包含的数据加全面,模型训练的效果会更好,但是同样在训练中也会相对更加耗时。因此选择数据集还是需要根据自己的需要来选择,比较经典的数据集网站可以参考 UCI 数据集(archive.ics.uci.edu/ml/),或者从 kaggle 上找一些需要的数据集。如果选择开源的数据集作为研究基础,那么就会面临两个问题:一、数据集如何预处理来适应研究。二、数据集中的数据如何分割。开源的数据集往往是作者根据当时的研究需求而构建的数据集,数据的特征可能并不严格符合当前研究的要求,那么我们可能就需要做一些格式转换,或者特征填充。例如我们需要对城市的出租车活动的范围进行统计,但是以 Roma/taxi 为例,数据集中所包含的地点是以经纬度坐标来体现的,如果需要经纬度对应的区域信息,可以通过 google map 的反向请求进行爬虫(当然需要一定的反爬虫机制)来补充相关的信息。另外一个例子是当需要对一些视频数据进行分类时,我们往往需要通过 OpenCV 等框架对其进行动作提取等操作,最终转化为分类模型所能识别的时序数据。因此,开源数据集虽然可以节省一些我们打造数据集的工作,但是也不是可以“拿来主义”的,仍然需要我们花很多功夫去研究才能加以利用。当然,一些行业熟悉的开源数据集不仅是大家公认的平均算法的标准,并且可以在 Github 上找到很多相应的处理方法,这样也可以节省很多时间。
做数据集一般有两种动机。一种是为了research,也就是为了造福广大研究人员以及推动领域的进步;另一种,就是为了使用数据驱动的方法来优化业务指标,或解决项目中实实在在存在的问题。对数据集高质量的定义是相近的,那就是:解决问题!只不过,对后一种目的来说,问题一般来源于线上系统。一般来说,在做数据集之前一般已经存在一套系统了(为了让系统冷启动,一般先开发一套规则驱动的系统),系统上线后自然会产生日志,分析其中的badcase便可以知道哪些问题是现有系统搞不定的,这些问题就可以考虑使用数据驱动的方法来解决,于是需要做数据集了。而解决这些问题就是你做数据集的第一目标啦。而对于前一种目的来说,问题一般来源于学术界的研究现状。现阶段的NLP研究多为数据驱动的,甚至说数据集驱动的。虽然这不是一个好现象,不过也不得不承认很大程度上推动了NLP的发展和研究热潮。当现有的数据集无法cover领域痛点,或无法发挥数学工具潜力,或已经被解决掉的时候,就需要一个新的数据集,更确切的说是新的benchmark了。对数据集质量产生第二关键影响的就是数据和标签来源的选择。对数据集质量产生第二关键影响的就是数据和标签来源的选择了。其中数据可以通过人工构造、撰写的方式来产生,也可以从互联网上爬取或对公开数据集进行二次加工得到;标签同样可以人工标注,也可以远程监督的方式来获取。
无论是人工标注的还是远程监督标注的,数据集看起来做好了不代表就是可用的,如果标注的噪声太大或者标签边界太过模糊(大量标注错误,或标注规则写的太松、太模糊,导致人都分不清某几个类别之间的区别),很可能再复杂的模型都在这份数据集上无法收敛;反之,如果数据集中有“标签泄漏”或标签与内容有非常直接的映射关系,那就会导致一个非常简单的模型都会轻易的把这个数据集刷到近乎满分,那这个模型学到的知识基本是没有什么实际意义的,换言之,这么简单直接的任务其实几条规则几行代码就搞定了,完全没必要做数据驱动的模型训练。
附完整代码
吸烟图片爬虫.py
'''
爬取指定关键字图片
'''
import re# 正则表达式,解析网页
import requests# 请求网页
import traceback
import os
def dowmloadPic(html,keyword,startNum):
headers = {'user-agent':'Mozilla/5.0'}# 浏览器伪装,因为有的网站会反爬虫,通过该headers可以伪装成浏览器访问,否则user-agent中的代理信息为python
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)# 找到符合正则规则的目标网站
i = startNum
subroot = root + '/' + word
for each in pic_url:
path = subroot + '/' + str(i+1)
try:
if not os.path.exists(subroot):
os.mkdir(subroot)
if not os.path.exists(path):
pic = requests.get(each,headers = headers,timeout = 10)
with open(path+'.jpg','wb') as f:
f.write(pic.content)
f.close()
except:
traceback.print_exc()
print ('【错误】当前图片无法下载')
continue
i += 1
return i
if __name__ == '__main__':
headers = {'user-agent':'Mozilla/5.0'}
words = ['吸烟']
#words为一个列表,可以自动保存多个关键字的图片
root = '有关'
for word in words:
root = root + ' “' + word + '” '
root += '的图片'
if not os.path.exists(root):
os.mkdir(root)
for word in words:
lastNum = 0
if word.strip() == "exit":
break
pageId = 0
#此处的参数为需爬取的页数,设置为2页
for i in range(3):
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + "&pn="+str(pageId)+"&gsm=?&ct=&ic=0&lm=-1&width=0&height=0"
pageId += 15#好像没啥影响
html = requests.get(url,headers = headers)
# print(html.text) #打印网页源码,相当于在网页中右键查看源码内容
lastNum = dowmloadPic(html.text, word, lastNum,)#本条语句执行一次获取60张图
print('正在下载中,请稍后...')
mnist.py
from keras.datasets import mnist
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
print(train_images.shape,test_images.shape)
print(train_images[1])
print(train_labels[1])
plt.imshow(train_images[1])
plt.show()
LFW.py
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people()
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 8))
for i in range(64):
img = faces.images[i]
#总共400张图,把图像分割成20X20
plt.subplot(8, 8, i+1)
plt.imshow(img, cmap="gray")
#关闭x,y轴显示
plt.xticks([])
plt.yticks([])
plt.xlabel(faces.target[i])
i = i + 1
plt.show()
fashion mnist.py
from keras.datasets import fashion_mnist
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
print(train_images.shape,test_images.shape)
print(train_images[1])
print(train_labels[1])
plt.imshow(train_images[1])
plt.show()
face.py
from sklearn import datasets
import matplotlib.pyplot as plt
faces = datasets.fetch_olivetti_faces(data_home=None, shuffle=False, random_state=0, download_if_missing=True)
i = 0
plt.figure(figsize=(20, 20))
for img in faces.images:
#总共400张图,把图像分割成20X20
plt.subplot(20, 20, i+1)
plt.imshow(img, cmap="gray")
#关闭x,y轴显示
plt.xticks([])
plt.yticks([])
plt.xlabel(faces.target[i])
i = i + 1
plt.show()
cifar100.py
from keras.datasets import cifar100
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = cifar100.load_data()
print(train_images.shape,test_images.shape)
print(train_images[2])
print(train_labels[2])
plt.imshow(train_images[2])
plt.show()
cifar10.py
from keras.datasets import cifar10
import matplotlib.pyplot as plt
#加载数据集
(train_images,train_labels),(test_images,test_labels) = cifar10.load_data()
print(train_images.shape,test_images.shape)
print(train_images[1])
print(train_labels[1])
plt.imshow(train_images[1])
plt.show()
欢迎大家加我微信交流讨论(请备注csdn上添加)


