【视觉情报信息、相机标定】
深度在cv和dl区别:机器视觉(Computer Vision)通常来说图像都是通过摄像头给拍出来的,虽然我们日常生活中事物都是三维的,但是通过摄像头给拍出来的图像却是二维的,因此在拍摄的过程中我们其实丢失了一维的信息,而这个一维的信息就是物体在空间里的相互距离,比如下图左上角的卧室照片,我们可以看到卧室里有哪些东西,但是我们很难估计里面各个物体之间的距离是什么,比如床和电脑桌之间的距离,我们可以看到大概的方位,但是没有办法准确的估计距离,而这里的距离信息也就是深度(Depth)所指的含义,为了方便计算,通常深度在机器视觉里面都是指空间里面的各个点相对于摄像头的距离(一些参数),知道了这个信息之后就可以很方便的计算各点之间的相互距离了。|| 深度信息在机器视觉里是很重要的信息,机器视觉的目的就是准确的识别物体然后利用识别出来的信息进行决策和分析,如果不能识别到深度信息的话,它的应用是很局限的,比如机器人路径规划、自动驾驶,这些不仅需要识别出物体,还需要识别出具体的距离来进行合理避障。
相机呈像的几何描述√:讲述了如何将3D世界坐标系中的点变换到相机坐标系中,然后经透视投影,变成2D像平面上的点(x,y).用矩阵描述了外部参数,即物体的坐标到相机坐标的变换。同时还分析了透视投影,即成像的过程,整个过程就是从(U,V,W)->(X,Y,X)->(x,y)
引入世界坐标(或物体坐标)、相机坐标和像平面坐标:世界坐标用UVW记、相机坐标用XYZ记、数字图像用(u,v)来表示,不弄混淆像平面和数字图像这两个概念,同一个像通过平移、拉伸等,可以得到不同的数学图像(u,v)。

?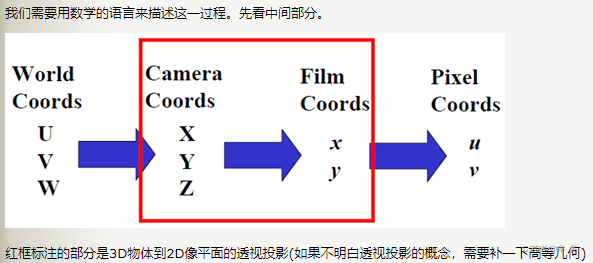

?内参√:主要讨论如何从像平面(x,y)变换到数字图像(u,v),即从像平面(Film Coords)到像素(Pixel Coords)

?

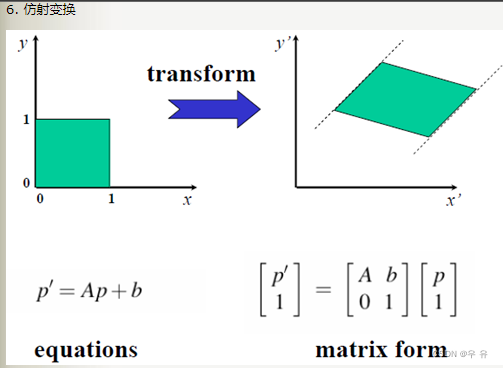
?用矩阵实现:平移、尺度变换、旋转、刚体运动、?刚体+尺度变换、仿射变换、投影变换&总结
?





对极几何(Epipolar Geometry):用两个相机在不同的位置拍摄同一物体,如果两张照片中的景物有重叠的部分,我们有理由相信,这两张照片之间存在一定的对应关系。要寻找两幅图像之间的对应关系,最直接的方法就是逐点匹配,如果加以一定的约束条件对极约束(epipolar constraint),搜索的范围可以大大减小。
科普:视差|透视投影、
相机内参与外参

