从本专栏开始,作者正式研究Python深度学习、神经网络及人工智能相关知识。前一篇文章通过keras-bert库构建Bert模型,并实现微博情感分析。这篇文章将利用Keras构建Transformer或多头自注意机制模型,并实现商品论文的情感分析,在这之前,我们先构建机器学习和深度学习的Baseline模型,只有不断强化各种模型的实现,才能让我们更加熟练地应用于自身研究领域和改进。基础性文章,希望对您有所帮助!
文章目录
本专栏主要结合作者之前的博客、AI经验和相关视频及论文介绍,后面随着深入会讲解更多的Python人工智能案例及应用。基础性文章,希望对您有所帮助,如果文章中存在错误或不足之处,还请海涵!作者作为人工智能的菜鸟,希望大家能与我在这一笔一划的博客中成长起来。写了这么多年博客,尝试第一个付费专栏,为小宝赚点奶粉钱,但更多博客尤其基础性文章,还是会继续免费分享,该专栏也会用心撰写,望对得起读者。如果有问题随时私聊我,只望您能从这个系列中学到知识,一起加油喔~
- Keras下载地址:https://github.com/eastmountyxz/AI-for-Keras
- TensorFlow下载地址:https://github.com/eastmountyxz/AI-for-TensorFlow
前文赏析:
- [Python人工智能] 一.TensorFlow2.0环境搭建及神经网络入门
- [Python人工智能] 二.TensorFlow基础及一元直线预测案例
- [Python人工智能] 三.TensorFlow基础之Session、变量、传入值和激励函数
- [Python人工智能] 四.TensorFlow创建回归神经网络及Optimizer优化器
- [Python人工智能] 五.Tensorboard可视化基本用法及绘制整个神经网络
- [Python人工智能] 六.TensorFlow实现分类学习及MNIST手写体识别案例
- [Python人工智能] 七.什么是过拟合及dropout解决神经网络中的过拟合问题
- [Python人工智能] 八.卷积神经网络CNN原理详解及TensorFlow编写CNN
- [Python人工智能] 九.gensim词向量Word2Vec安装及《庆余年》中文短文本相似度计算
- [Python人工智能] 十.Tensorflow+Opencv实现CNN自定义图像分类案例及与机器学习KNN图像分类算法对比
- [Python人工智能] 十一.Tensorflow如何保存神经网络参数
- [Python人工智能] 十二.循环神经网络RNN和LSTM原理详解及TensorFlow编写RNN分类案例
- [Python人工智能] 十三.如何评价神经网络、loss曲线图绘制、图像分类案例的F值计算
- [Python人工智能] 十四.循环神经网络LSTM RNN回归案例之sin曲线预测
- [Python人工智能] 十五.无监督学习Autoencoder原理及聚类可视化案例详解
- [Python人工智能] 十六.Keras环境搭建、入门基础及回归神经网络案例
- [Python人工智能] 十七.Keras搭建分类神经网络及MNIST数字图像案例分析
- [Python人工智能] 十八.Keras搭建卷积神经网络及CNN原理详解
[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解 - [Python人工智能] 二十.基于Keras+RNN的文本分类vs基于传统机器学习的文本分类
- [Python人工智能] 二十一.Word2Vec+CNN中文文本分类详解及与机器学习(RF\DTC\SVM\KNN\NB\LR)分类对比
- [Python人工智能] 二十二.基于大连理工情感词典的情感分析和情绪计算
- [Python人工智能] 二十三.基于机器学习和TFIDF的情感分类(含详细的NLP数据清洗)
- [Python人工智能] 二十四.易学智能GPU搭建Keras环境实现LSTM恶意URL请求分类
- [Python人工智能] 二十六.基于BiLSTM-CRF的医学命名实体识别研究(上)数据预处理
- [Python人工智能] 二十七.基于BiLSTM-CRF的医学命名实体识别研究(下)模型构建
- [Python人工智能] 二十八.Keras深度学习中文文本分类万字总结(CNN、TextCNN、LSTM、BiLSTM、BiLSTM+Attention)
- [Python人工智能] 二十九.什么是生成对抗网络GAN?基础原理和代码普及(1)
- [Python人工智能] 三十.Keras深度学习构建CNN识别阿拉伯手写文字图像
- [Python人工智能] 三十一.Keras实现BiLSTM微博情感分类和LDA主题挖掘分析
- [Python人工智能] 三十二.Bert模型 (1)Keras-bert基本用法及预训练模型
- [Python人工智能] 三十三.Bert模型 (2)keras-bert库构建Bert模型实现文本分类
- [Python人工智能] 三十四.Bert模型 (3)keras-bert库构建Bert模型实现微博情感分析
- [Python人工智能] 三十五.基于Transformer的商品评论情感分析 (1)机器学习和深度学习的Baseline模型实现
一.数据预处理
首先进行数据预处理,并给出整个项目的基本目录。
C:.
│ 01-cutword.py
│ 02-wordcloud.py
│ 03-ml-model.py
│ 04-CNN-model.py
│ 05-TextCNN-model.py
│ 06-BiLSTM-model.py
│ 07-BiGRU-model.py
└─data
data-word-count-train-happy.csv
data-word-count-train-sad.csv
online_shopping_10_cats.csv
online_shopping_10_cats_words.csv
online_shopping_10_cats_words_test.csv
online_shopping_10_cats_words_train.csv
1.数据集
整个数据集来源于github,是一个包含十类商品的评论数据集,我们将对其进行情感分析研究。
- https://github.com/SophonPlus/ChineseNlpCorpus/tree/master/datasets/online_shopping_10_cats
- 关于文本分类(情感分析)的中文数据集汇总 - 樱与刀
整个数据集包含3个字段,分别是:
- cat:商品类型
- label:商品类别
- review:评论内容

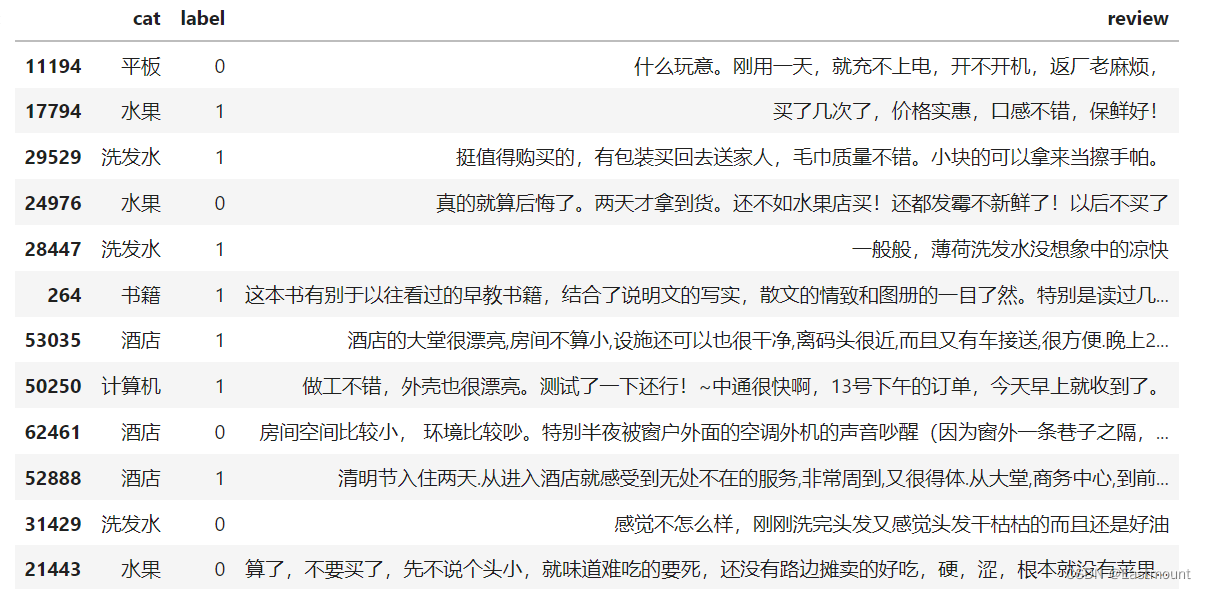
数据集存储在CSV文件中,如下图所示:

数据分布如下图所示:

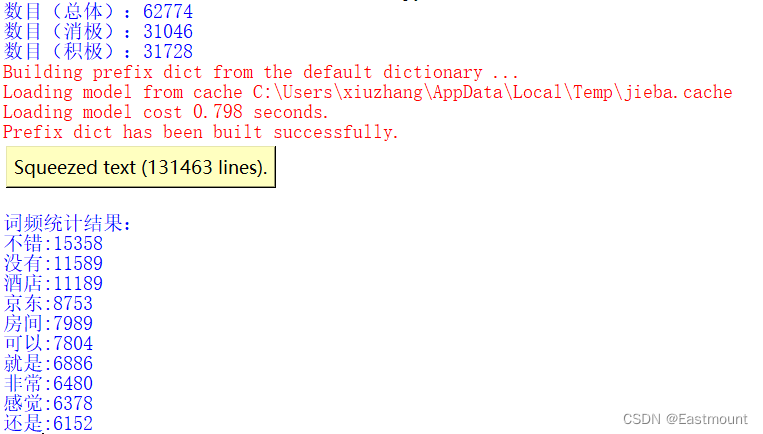
2.中文分词
中文分词利用Jieba工具实现,处理后的结果如下图所示:

程序的运行结果如下图所示:
该部分代码如下所示:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import pandas as pd
import jieba
import csv
from collections import Counter
#-----------------------------------------------------------------------------
#样本数量统计
pd_all = pd.read_csv('data/online_shopping_10_cats.csv')
moods = {0: '消极', 1: '积极'}
print('数目(总体):%d' % pd_all.shape[0])
for label, mood in moods.items():
print('数目({}):{}'.format(mood, pd_all[pd_all.label==label].shape[0]))
#-----------------------------------------------------------------------------
#中文分词和停用词过滤
cut_words = ""
all_words = ""
stopwords = ["[", "]", ")", "(", ")", "(", "【", "】", "!", ",", "$",
"・", "?", ".", "、", "-", "―", ":", ":", "《", "》", "=",
"。", "…", "“", "?", "”", "~", " ", "-", "+", "\\", "‘",
"~", ";", "’", "...", "..", "&", "#", "....", ",",
"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "10"
"的", "和", "之", "了", "哦", "那", "一个", ]
fw = open('data/online_shopping_10_cats_words.csv', 'w', encoding='utf-8')
for line in range(len(pd_all)): #cat label review
dict_cat = pd_all['cat'][line]
dict_label = pd_all['label'][line]
dict_review = pd_all['review'][line]
dict_review = str(dict_review)
#print(dict_cat, dict_label, dict_review)
#jieba分词并过滤停用词
cut_words = ""
data = dict_review.strip('\n')
data = data.replace(",", "") #一定要过滤符号 ","否则多列
seg_list = jieba.cut(data, cut_all=False)
for seg in seg_list:
if seg not in stopwords:
cut_words += seg + " "
all_words += cut_words
#print(cut_words)
fw.write(str(dict_cat)+","+str(dict_label)+","+str(cut_words)+"\n")
else:
fw.close()
#-----------------------------------------------------------------------------
#词频统计
all_words = all_words.split()
print(all_words)
c = Counter()
for x in all_words:
if len(x)>1 and x != '\r\n':
c[x] += 1
#输出词频最高的前10个词
print('\n词频统计结果:')
for (k,v) in c.most_common(10):
print("%s:%d"%(k,v))
二.词云可视化分析
接着我们给“online_shopping_10_cats_words.csv”增加表头:cat、label和review,然后进行词云可视化分析。
第一步,安装Pyecharts扩展包。
- pip install pyecharts
第二步,分别统计积极和消极情绪特征词的数量,并利用Counter函数统计高频词。

第三步,调用Pyecharts绘制词云。

积极和消极情感的最终词云如下图所示:


完整代码如下:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import pandas as pd
import csv
from collections import Counter
#-----------------------------------------------------------------------------
#读取分词后特征词
cut_words = ""
all_words = ""
pd_all = pd.read_csv('data/online_shopping_10_cats_words.csv')
moods = {0: '积极', 1: '消极'}
print('数目(总体):%d' % pd_all.shape[0])
for line in range(len(pd_all)): #cat label review
dict_cat = pd_all['cat'][line]
dict_label = pd_all['label'][line]
dict_review = pd_all['review'][line]
if str(dict_label)=="1": #积极
cut_words = dict_review
all_words += str(cut_words)
#print(cut_words)
#-----------------------------------------------------------------------------
#词频统计
all_words = all_words.split()
c = Counter()
for x in all_words:
if len(x)>1 and x != '\r\n':
c[x] += 1
print('\n词频统计结果:')
for (k,v) in c.most_common(10):
print("%s:%d"%(k,v))
#存储数据
name ="data/data-word-count-train-happy.csv"
fw = open(name, 'w', encoding='utf-8')
i = 1
for (k,v) in c.most_common(len(c)):
fw.write(str(i)+','+str(k)+','+str(v)+'\n')
i = i + 1
else:
print("Over write file!")
fw.close()
#-----------------------------------------------------------------------------
#词云分析
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
#生成数据 word = [('A',10), ('B',9), ('C',8)] 列表+Tuple
words = []
for (k,v) in c.most_common(120):
words.append((k,v))
#渲染图
def wordcloud_base() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 40], shape='diamond') #shape=SymbolType.ROUND_RECT
.set_global_opts(title_opts=opts.TitleOpts(title='词云图'))
)
return c
wordcloud_base().render('电商评论积极情感分析词云图.html')
三.机器学习情感分析
为了更准确地评估模型,本文将分词后的数据集分成了训练集和测试集,并在相同环境进行对比实验。
具体流程如下:
- 数据读取及预处理
- TF-IDF计算
- 分类模型构建
- 实验评估
输出结果如下图所示:
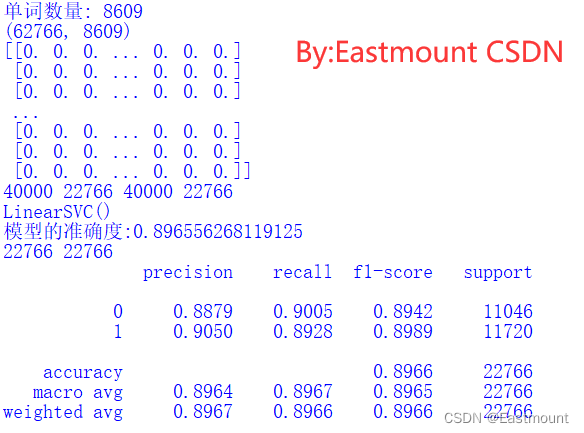
完整代码如下所示:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import jieba
import pandas as pd
import numpy as np
from collections import Counter
from scipy.sparse import coo_matrix
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn import svm
from sklearn import neighbors
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import AdaBoostClassifier
#-----------------------------------------------------------------------------
#变量定义
train_cat = []
test_cat = []
train_label = []
test_label = []
train_review = []
test_review = []
#读取数据
train_path = 'data/online_shopping_10_cats_words_train.csv'
test_path = 'data/online_shopping_10_cats_words_test.csv'
types = {0: '消极', 1: '积极'}
pd_train = pd.read_csv(train_path)
pd_test = pd.read_csv(test_path)
print('训练集数目(总体):%d' % pd_train.shape[0])
print('测试集数目(总体):%d' % pd_test.shape[0])
for line in range(len(pd_train)):
dict_cat = pd_train['cat'][line]
dict_label = pd_train['label'][line]
dict_content = str(pd_train['review'][line])
train_cat.append(dict_cat)
train_label.append(dict_label)
train_review.append(dict_content)
print(len(train_cat),len(train_label),len(train_review))
print(train_cat[:5])
print(train_label[:5])
for line in range(len(pd_test)):
dict_cat = pd_test['cat'][line]
dict_label = pd_test['label'][line]
dict_content = str(pd_test['review'][line])
test_cat.append(dict_cat)
test_label.append(dict_label)
test_review.append(dict_content)
print(len(test_cat),len(test_label),len(test_review),"\n")
#-----------------------------------------------------------------------------
#TFIDF计算
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j]表示词j在第i类文本下的词频
vectorizer = CountVectorizer(min_df=10) #MemoryError控制参数
#统计每个词语的tf-idf权值
transformer = TfidfTransformer()
#第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(train_review+test_review))
for n in tfidf[:5]:
print(n)
print(type(tfidf))
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
print("单词数量:", len(word))
#元素w[i][j]表示词j在第i类文本中的tf-idf权重
X = coo_matrix(tfidf, dtype=np.float32).toarray() #稀疏矩阵
print(X.shape)
print(X[:10])
X_train = X[:len(train_label)]
X_test = X[len(train_label):]
y_train = train_label
y_test = test_label
print(len(X_train),len(X_test),len(y_train),len(y_test))
#-----------------------------------------------------------------------------
#分类模型
clf = svm.LinearSVC()
print(clf)
clf.fit(X_train, y_train)
pre = clf.predict(X_test)
print('模型的准确度:{}'.format(clf.score(X_test, y_test)))
print(len(pre), len(y_test))
print(classification_report(y_test, pre, digits=4))
with open("SVM-pre-result.txt","w") as f: #结果保存
for v in pre:
f.write(str(v)+"\n")
其他常见机器学习模型如下:
- clf = LogisticRegression(solver=‘liblinear’)
- clf = RandomForestClassifier(n_estimators=5)
- clf = DecisionTreeClassifier()
- clf = AdaBoostClassifier()
- clf = MultinomialNB()
- clf = neighbors.KNeighborsClassifier(n_neighbors=3)
四.CNN和TextCNN情感分析
1.CNN
基本流程:
- 数据读取及预处理
- 特征提取
- Embedding
- 构建深度学习分类模型
- 实验评估
训练构建的模型如下所示:
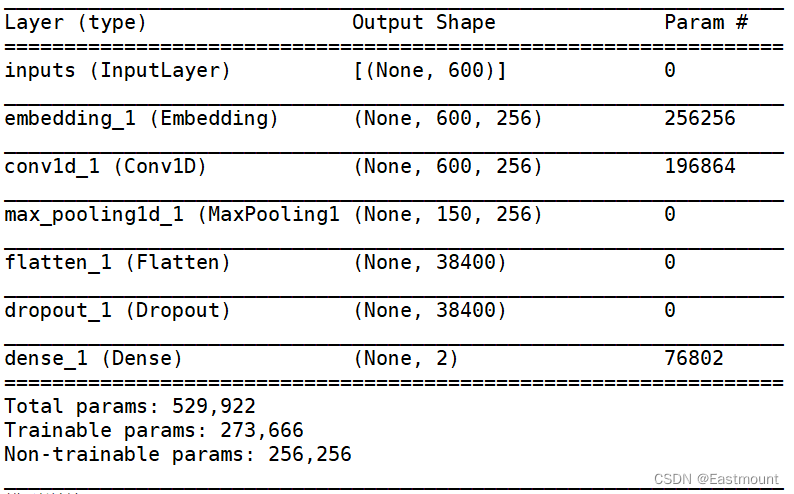
训练输出的结果如下:
Train on 40000 samples, validate on 10000 samples
Epoch 1/12
40000/40000 [==============================] - 8s 211us/step - loss: 0.4246 - acc: 0.8048 - val_loss: 0.3602 - val_acc: 0.8814
Epoch 2/12
40000/40000 [==============================] - 6s 161us/step - loss: 0.2941 - acc: 0.8833 - val_loss: 0.2525 - val_acc: 0.9232
Epoch 3/12
40000/40000 [==============================] - 6s 159us/step - loss: 0.2364 - acc: 0.9119 - val_loss: 0.2157 - val_acc: 0.9409
Epoch 4/12
40000/40000 [==============================] - 6s 159us/step - loss: 0.1891 - acc: 0.9317 - val_loss: 0.1225 - val_acc: 0.9724
Epoch 5/12
40000/40000 [==============================] - 6s 159us/step - loss: 0.1527 - acc: 0.9480 - val_loss: 0.1082 - val_acc: 0.9765
Epoch 6/12
40000/40000 [==============================] - 6s 160us/step - loss: 0.1222 - acc: 0.9597 - val_loss: 0.0957 - val_acc: 0.9802
Epoch 7/12
40000/40000 [==============================] - 6s 159us/step - loss: 0.1008 - acc: 0.9682 - val_loss: 0.0845 - val_acc: 0.9836
Epoch 8/12
40000/40000 [==============================] - 6s 161us/step - loss: 0.0846 - acc: 0.9738 - val_loss: 0.0584 - val_acc: 0.9897
Epoch 9/12
40000/40000 [==============================] - 6s 160us/step - loss: 0.0681 - acc: 0.9802 - val_loss: 0.0512 - val_acc: 0.9884
Epoch 10/12
40000/40000 [==============================] - 6s 161us/step - loss: 0.0601 - acc: 0.9815 - val_loss: 0.0239 - val_acc: 0.9967
Epoch 11/12
40000/40000 [==============================] - 6s 162us/step - loss: 0.0526 - acc: 0.9840 - val_loss: 0.0415 - val_acc: 0.9911
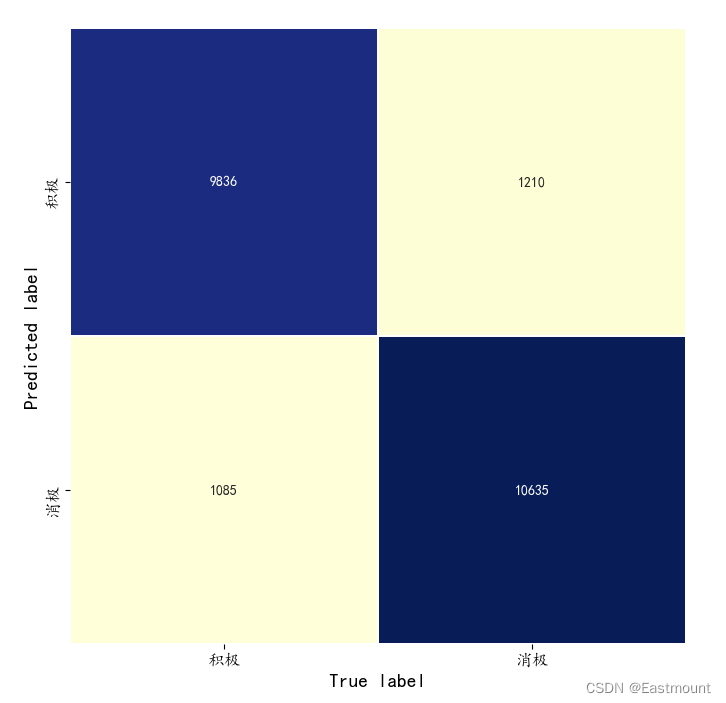
最终模型预测结果如下所示:
[[ 9836 1085]
[ 1210 10635]]
precision recall f1-score support
0 0.8905 0.9007 0.8955 10921
1 0.9074 0.8978 0.9026 11845
avg / total 0.8993 0.8992 0.8992 22766
完整代码:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import os
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D, MaxPool1D, Flatten
from keras.optimizers import RMSprop
from keras.layers import Bidirectional
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from keras.models import Sequential
from keras.layers.merge import concatenate
import tensorflow as tf
#GPU加速: 指定每个GPU进程中使用显存的上限 0.9表示可以使用GPU 90%的资源进行训练 CuDNNLSTM比LSTM快
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
#-----------------------------第一步 读取数据---------------------------------
#变量定义
train_cat = []
test_cat = []
train_label = []
test_label = []
train_review = []
test_review = []
#读取数据
train_path = 'data/online_shopping_10_cats_words_train.csv'
test_path = 'data/online_shopping_10_cats_words_test.csv'
types = {0: '消极', 1: '积极'}
pd_train = pd.read_csv(train_path)
pd_test = pd.read_csv(test_path)
print('训练集数目(总体):%d' % pd_train.shape[0])
print('测试集数目(总体):%d' % pd_test.shape[0])
for line in range(len(pd_train)):
dict_cat = pd_train['cat'][line]
dict_label = pd_train['label'][line]
dict_content = str(pd_train['review'][line])
train_cat.append(dict_cat)
train_label.append(dict_label)
train_review.append(dict_content)
print(len(train_cat),len(train_label),len(train_review))
print(train_cat[:5])
print(train_label[:5])
for line in range(len(pd_test)):
dict_cat = pd_test['cat'][line]
dict_label = pd_test['label'][line]
dict_content = str(pd_test['review'][line])
test_cat.append(dict_cat)
test_label.append(dict_label)
test_review.append(dict_content)
print(len(test_cat),len(test_label),len(test_review),"\n")
#------------------------第二步 OneHotEncoder()编码---------------------------
le = LabelEncoder()
train_y = le.fit_transform(train_label).reshape(-1, 1)
test_y = le.transform(test_label).reshape(-1, 1)
val_y = le.transform(train_label[:10000]).reshape(-1, 1)
print("LabelEncoder:")
print(len(train_y),len(test_y))
print(train_y[:10])
#对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-----------------------第三步 使用Tokenizer对词组进行编码-----------------------
#Tokenizer将输入文本中的每个词编号 词频越大编号越小
max_words = 1200
max_len = 600
tok = Tokenizer(num_words=max_words)
tok.fit_on_texts(train_review)
print(tok)
#保存训练好的Tokenizer和导入
with open('tok.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('tok.pickle', 'rb') as handle:
tok = pickle.load(handle)
#word_index属性查看词对应的编码 word_counts属性查看词对应的频数
for ii, iterm in enumerate(tok.word_index.items()):
if ii < 10:
print(iterm)
else:
break
for ii, iterm in enumerate(tok.word_counts.items()):
if ii < 10:
print(iterm)
else:
break
#序列转换
data_train = train_review
data_val = train_review[:10000]
data_test = test_review
train_seq = tok.texts_to_sequences(data_train)
val_seq = tok.texts_to_sequences(data_val)
test_seq = tok.texts_to_sequences(data_test)
#长度对齐
train_seq_mat = sequence.pad_sequences(train_seq, maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq, maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq, maxlen=max_len)
print(train_seq_mat.shape)
print(val_seq_mat.shape)
print(test_seq_mat.shape)
print(train_seq_mat[:2])
#--------------------------第四步 建立CNN模型---------------------------------
num_labels = 2
inputs = Input(name='inputs', shape=[max_len], dtype='float64')
layer = Embedding(max_words+1, 128, input_length=max_len, trainable=False)(inputs)
cnn = Convolution1D(128, 4, padding='same', strides = 1, activation='relu')(layer)
cnn = MaxPool1D(pool_size=4)(cnn)
flat = Flatten()(cnn)
drop = Dropout(0.4)(flat)
main_output = Dense(num_labels, activation='softmax')(drop)
model = Model(inputs=inputs, outputs=main_output)
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer='adam', # RMSprop()
metrics=["accuracy"])
#----------------------------第五步 训练和测试--------------------------------
flag = "test"
if flag == "train":
print("模型训练:")
model_fit = model.fit(train_seq_mat, train_y,
batch_size=64, epochs=12,
validation_data=(val_seq_mat, val_y),
callbacks=[EarlyStopping(monitor='val_loss',
min_delta=0.0005)]
)
model.save('cnn_model.h5')
del model #deletes the existing model
else:
print("模型预测")
model = load_model('cnn_model.h5') #导入已经训练的模型
test_pre = model.predict(test_seq_mat)
confm = metrics.confusion_matrix(np.argmax(test_pre, axis=1),
np.argmax(test_y, axis=1))
print(confm)
with open("CNN-pre-result.txt","w") as f: #结果保存
for v in np.argmax(test_pre, axis=1):
f.write(str(v)+"\n")
#混淆矩阵可视化
Labname = ['积极', '消极']
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
print(metrics.classification_report(np.argmax(test_pre, axis=1),
np.argmax(test_y, axis=1),
digits=4))
plt.figure(figsize=(8, 8))
sns.heatmap(confm.T, square=True, annot=True,
fmt='d', cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel('True label', size=14)
plt.ylabel('Predicted label', size=14)
plt.xticks(np.arange(2)+0.5, Labname, size=12)
plt.yticks(np.arange(2)+0.5, Labname, size=12)
plt.savefig('CNN-result.png')
plt.show()
2.TextCN
构建的模型如下:
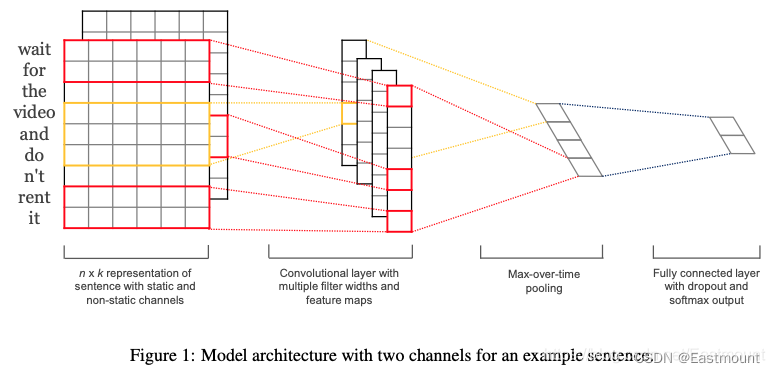
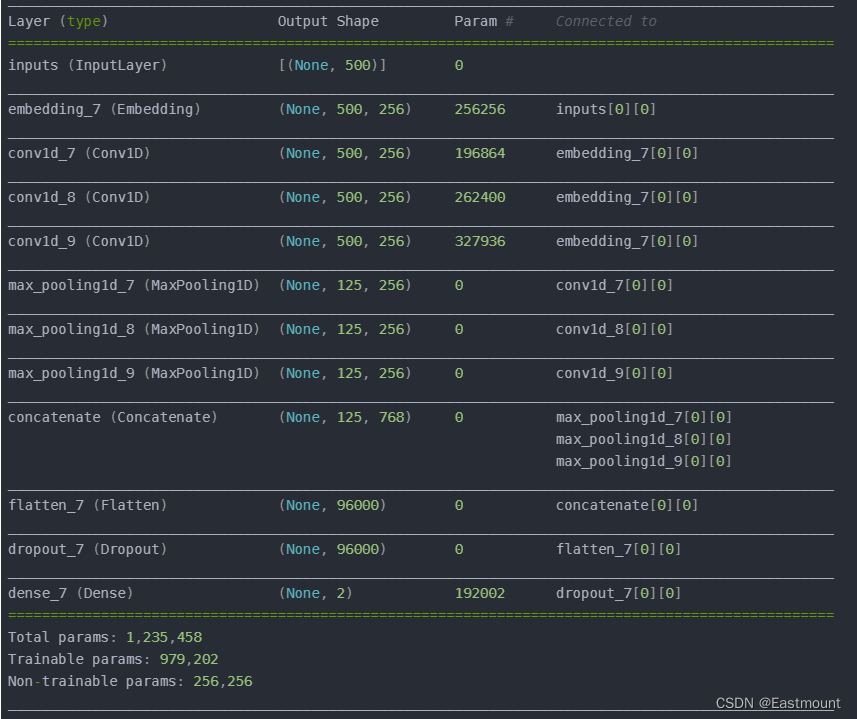
核心代码如下:
num_labels = 2
inputs = Input(name='inputs', shape=[max_len], dtype='float64')
layer = Embedding(max_words+1, 256, input_length=max_len, trainable=False)(inputs)
cnn1 = Convolution1D(256, 3, padding='same', strides = 1, activation='relu')(layer)
cnn1 = MaxPool1D(pool_size=4)(cnn1)
cnn2 = Convolution1D(256, 4, padding='same', strides = 1, activation='relu')(layer)
cnn2 = MaxPool1D(pool_size=4)(cnn2)
cnn3 = Convolution1D(256, 5, padding='same', strides = 1, activation='relu')(layer)
cnn3 = MaxPool1D(pool_size=4)(cnn3)
cnn = concatenate([cnn1,cnn2,cnn3], axis=-1)
flat = Flatten()(cnn)
drop = Dropout(0.3)(flat)
main_output = Dense(num_labels, activation='softmax')(drop)
model = Model(inputs=inputs, outputs=main_output)
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer='adam', # RMSprop()
metrics=["accuracy"])
最终预测结果如下所示:
[[ 9933 1160]
[ 1113 10560]]
precision recall f1-score support
0 0.8992 0.8954 0.8973 11093
1 0.9010 0.9047 0.9028 11673
avg / total 0.9002 0.9002 0.9002 22766
五.BiLSTM和BiGRU情感分析
1.BiLSTM
BiLSTM构建的模型结构如下所示:
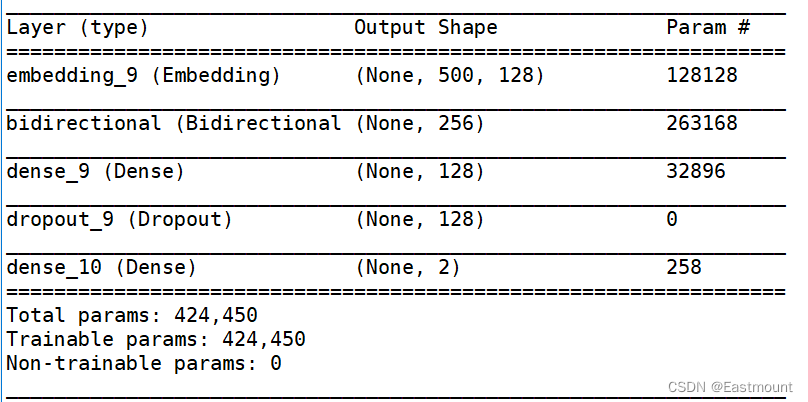
完整代码如下:
# -*- coding: utf-8 -*-
"""
@author: xiuzhang Eastmount 2022-05-04
"""
import os
import pickle
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.layers import Convolution1D, MaxPool1D, Flatten, CuDNNLSTM
from keras.optimizers import RMSprop
from keras.layers import Bidirectional
from keras.preprocessing.text import Tokenizer
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
from keras.models import Sequential
from keras.layers.merge import concatenate
import tensorflow as tf
#GPU加速: 指定每个GPU进程中使用显存的上限 0.9表示可以使用GPU 90%的资源进行训练 CuDNNLSTM比LSTM快
os.environ["CUDA_DEVICES_ORDER"] = "PCI_BUS_IS"
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=0.8)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options))
#-----------------------------第一步 读取数据---------------------------------
#变量定义
train_cat = []
test_cat = []
train_label = []
test_label = []
train_review = []
test_review = []
#读取数据
train_path = 'data/online_shopping_10_cats_words_train.csv'
test_path = 'data/online_shopping_10_cats_words_test.csv'
types = {0: '消极', 1: '积极'}
pd_train = pd.read_csv(train_path)
pd_test = pd.read_csv(test_path)
print('训练集数目(总体):%d' % pd_train.shape[0])
print('测试集数目(总体):%d' % pd_test.shape[0])
for line in range(len(pd_train)):
dict_cat = pd_train['cat'][line]
dict_label = pd_train['label'][line]
dict_content = str(pd_train['review'][line])
train_cat.append(dict_cat)
train_label.append(dict_label)
train_review.append(dict_content)
print(len(train_cat),len(train_label),len(train_review))
print(train_cat[:5])
print(train_label[:5])
for line in range(len(pd_test)):
dict_cat = pd_test['cat'][line]
dict_label = pd_test['label'][line]
dict_content = str(pd_test['review'][line])
test_cat.append(dict_cat)
test_label.append(dict_label)
test_review.append(dict_content)
print(len(test_cat),len(test_label),len(test_review),"\n")
#------------------------第二步 OneHotEncoder()编码---------------------------
le = LabelEncoder()
train_y = le.fit_transform(train_label).reshape(-1, 1)
test_y = le.transform(test_label).reshape(-1, 1)
val_y = le.transform(train_label[:10000]).reshape(-1, 1)
print("LabelEncoder:")
print(len(train_y),len(test_y))
print(train_y[:10])
#对数据集的标签数据进行one-hot编码
ohe = OneHotEncoder()
train_y = ohe.fit_transform(train_y).toarray()
val_y = ohe.transform(val_y).toarray()
test_y = ohe.transform(test_y).toarray()
print("OneHotEncoder:")
print(train_y[:10])
#-----------------------第三步 使用Tokenizer对词组进行编码-----------------------
#Tokenizer将输入文本中的每个词编号 词频越大编号越小
max_words = 1200
max_len = 600
tok = Tokenizer(num_words=max_words)
tok.fit_on_texts(train_review)
print(tok)
#保存训练好的Tokenizer和导入
with open('tok.pickle', 'wb') as handle:
pickle.dump(tok, handle, protocol=pickle.HIGHEST_PROTOCOL)
with open('tok.pickle', 'rb') as handle:
tok = pickle.load(handle)
#word_index属性查看词对应的编码 word_counts属性查看词对应的频数
for ii, iterm in enumerate(tok.word_index.items()):
if ii < 10:
print(iterm)
else:
break
for ii, iterm in enumerate(tok.word_counts.items()):
if ii < 10:
print(iterm)
else:
break
#序列转换
data_train = train_review
data_val = train_review[:10000]
data_test = test_review
train_seq = tok.texts_to_sequences(data_train)
val_seq = tok.texts_to_sequences(data_val)
test_seq = tok.texts_to_sequences(data_test)
#长度对齐
train_seq_mat = sequence.pad_sequences(train_seq, maxlen=max_len)
val_seq_mat = sequence.pad_sequences(val_seq, maxlen=max_len)
test_seq_mat = sequence.pad_sequences(test_seq, maxlen=max_len)
print(train_seq_mat.shape)
print(val_seq_mat.shape)
print(test_seq_mat.shape)
print(train_seq_mat[:2])
#--------------------------第四步 建立BiLSTM模型---------------------------------
num_labels = 2
model = Sequential()
model.add(Embedding(max_words+1, 128, input_length=max_len))
model.add(Bidirectional(CuDNNLSTM(128))) #LSTM
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_labels, activation='softmax'))
model.summary()
model.compile(loss="categorical_crossentropy",
optimizer='adam', # RMSprop()
metrics=["accuracy"])
#----------------------------第五步 训练和测试--------------------------------
flag = "test"
if flag == "train":
print("模型训练:")
model_fit = model.fit(train_seq_mat, train_y,
batch_size=128, epochs=12,
validation_data=(val_seq_mat, val_y),
callbacks=[EarlyStopping(monitor='val_loss',
min_delta=0.0005)]
)
model.save('BiLSTM_model.h5')
del model #deletes the existing model
else:
print("模型预测")
model = load_model('BiLSTM_model.h5') #导入已经训练的模型
test_pre = model.predict(test_seq_mat)
confm = metrics.confusion_matrix(np.argmax(test_pre, axis=1),
np.argmax(test_y, axis=1))
print(confm)
with open("BiLSTM-pre-result.txt","w") as f: #结果保存
for v in np.argmax(test_pre, axis=1):
f.write(str(v)+"\n")
#混淆矩阵可视化
Labname = ['积极', '消极']
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
print(metrics.classification_report(np.argmax(test_pre, axis=1),
np.argmax(test_y, axis=1),
digits=4))
plt.figure(figsize=(8, 8))
sns.heatmap(confm.T, square=True, annot=True,
fmt='d', cbar=False, linewidths=.6,
cmap="YlGnBu")
plt.xlabel('True label', size=14)
plt.ylabel('Predicted label', size=14)
plt.xticks(np.arange(2)+0.5, Labname, size=12)
plt.yticks(np.arange(2)+0.5, Labname, size=12)
plt.savefig('BiLSTM-result.png')
plt.show()
实验结果如下:
[[ 9700 817]
[ 1346 10903]]
precision recall f1-score support
0 0.8781 0.9223 0.8997 10517
1 0.9303 0.8901 0.9098 12249
avg / total 0.9062 0.9050 0.9051 22766
2.BiGRU
该模型的核心代码如下:
num_labels = 2
model = Sequential()
model.add(Embedding(max_words+1, 128, input_length=max_len))
model.add(Bidirectional(CuDNNGRU(128))) #GRU
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.4))
model.add(Dense(num_labels, activation='softmax'))
model.summary()
实验结果如下:
[[10072 949]
[ 974 10771]]
precision recall f1-score support
0 0.9118 0.9139 0.9129 11021
1 0.9190 0.9171 0.9180 11745
avg / total 0.9155 0.9155 0.9155 22766
六.总结
写到这里,这篇文章就介绍结束了,下一篇文章将具体实现Transformer情感分析。真心希望这篇文章对您有所帮助,加油~
- 一.数据预处理
1.数据集
2.中文分词 - 二.词云可视化分析
- 三.机器学习情感分析
- 四.CNN和TextCNN情感分析
1.CNN
2.TextCN - 五.BiLSTM和BiGRU情感分析
1.BiLSTM
2.BiGRU
下载地址:

(By:Eastmount 2021-05-10 夜于武汉 http://blog.csdn.net/eastmount/ )

