H.265/HEVC编码原理及其处理流程的分析
H.265/HEVC编码的框架图,查了很多资料都没搞明白,各个模块的处理的分析网上有很多,很少有把这个流程串起来的。本文的主要目的是讲清楚H.265/HEVC视频编码的处理流程,不涉及复杂的计算过程。
文章目录
一、什么是H.265/HEVC?
1、H.265/HEVC的作用
H.265/HEVC是一种新的视频压缩标准,而视频是由一张张连续的图片组成的,因此对视频的压缩就可以理解为对一组图片的压缩。30帧的视频就表示一秒有30张的图片,60帧就表示该视频一秒有60张图片,因此相邻的两张图片间常常存在大量相同的部分。

一张图片是由很多像素点组成,而如图所示(图片来源未知),即使同一张图片内部也存在大量相同的部分,比如这背景几乎全是白色,我们没有必要把每个白色的位置及其像素值全部存储下来,这样既耗费资源又没有必要。因此,我们就需要用H.265/HEVC对组成视频的图片进行压缩,以减少他们的大小。
2、H.265/HEVC编码框架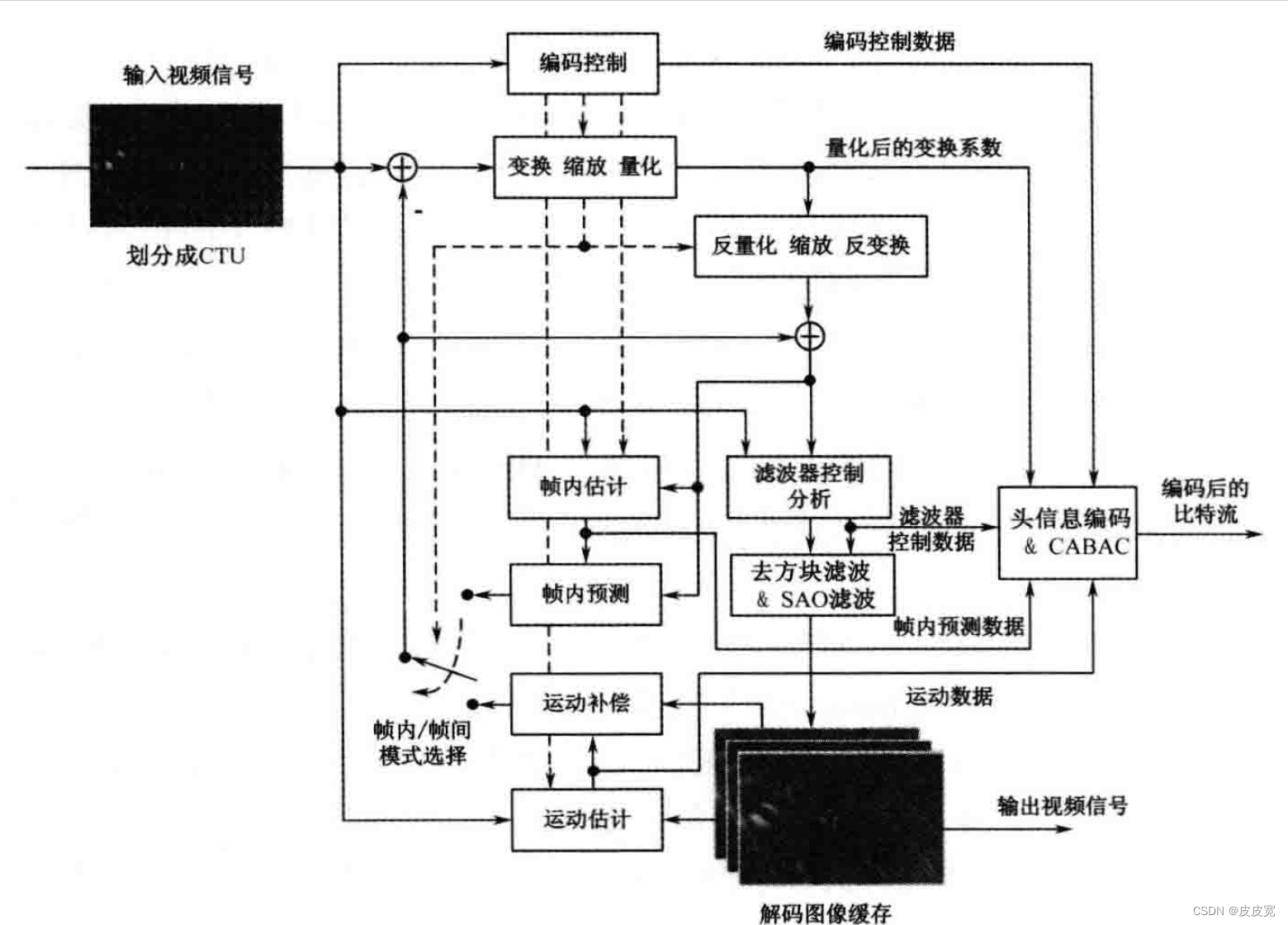
H.265/HEVC的编码框架如图所示,图片来源【1】,本文的主要目的是为了讲清楚这张图展示的处理流程。首先,输入的图片被划分为一个个相似的块(CTU),这些块的大小最大为64*64,通过这样的划分,使得每个CTU的差别都不大。

二、DCT变换和量化
1. DCT变换
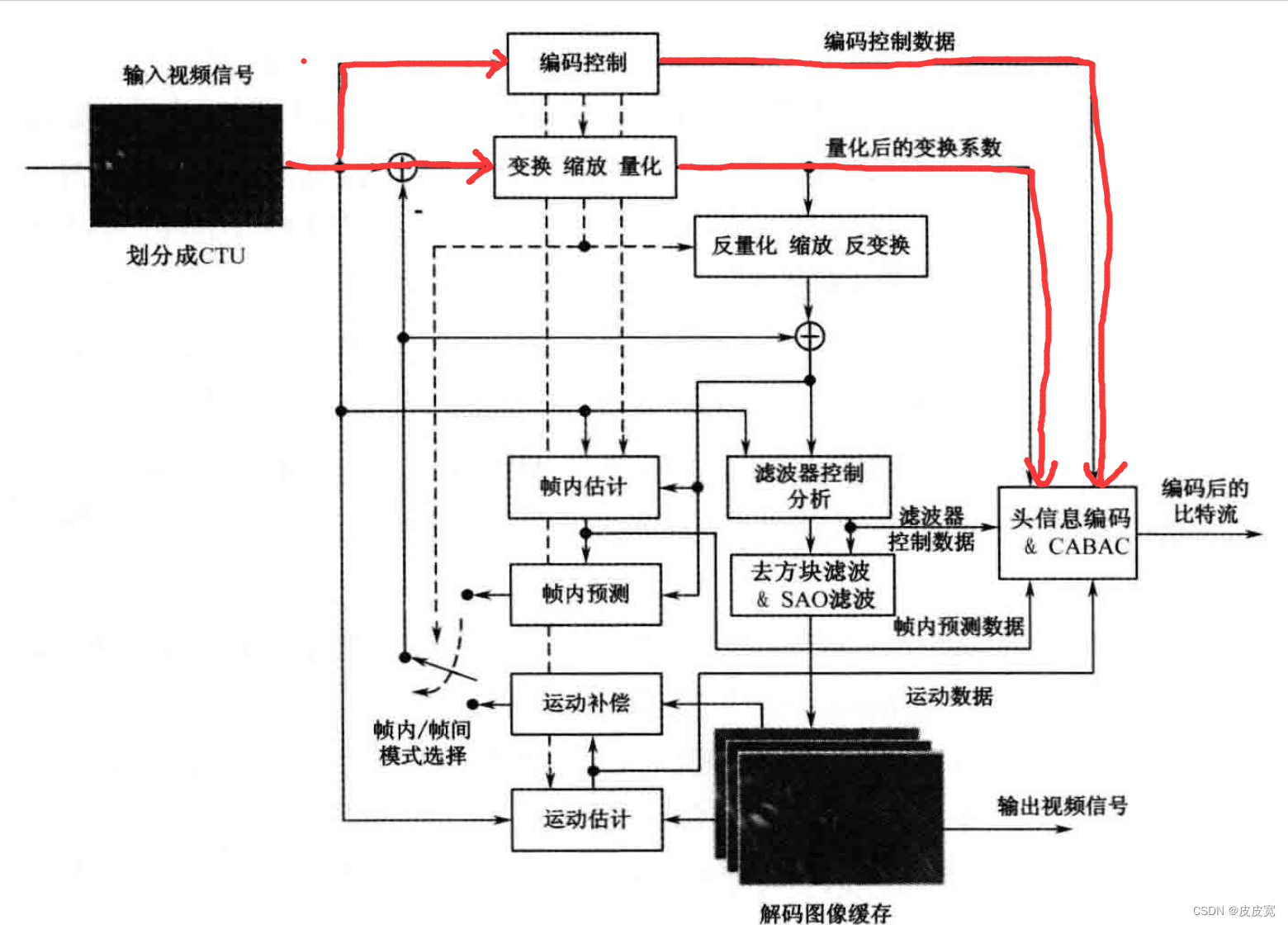
如图所示(红色划线部分),当一个视频,也就是一组图片的第一个CTU输入时,我们先将其进行DCT变换。
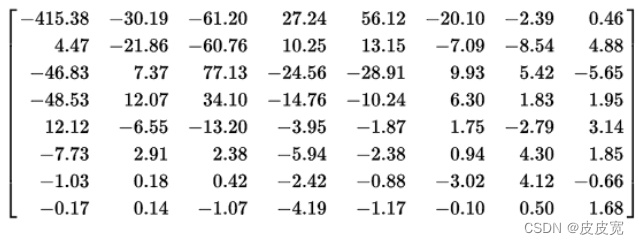
由于我们人眼对高频信息不敏感,比如本文举例的那张图,我们对高频率出现的背景白色并不敏感,黑色线条虽然占据较小的比例,但这低频率出现的黑色信号才是我们关注的重点。该图是某个图片经过DCT变换后的结果,由图可以看出(图片来源【2】),DCT变换后得到频域矩阵,低频部分幅度很大(左上角低频,右下角高频),而高频部分幅度较低。
2. 量化
为了减少存储数据所需要的内存资源。CTU经过DCT变换后,我们再将其进行量化。由于量化步长选取的不一样,造成的精度损失也不一样(参考【3】)。举个例子,如果我们选最小步长是1,向下取整,那么0.6,0.2都将被量化为0,412.6就会被量化为412。可以看到,高频信号由于幅度较小,因此量化后的损失很大,而低频信号由于幅度较大,因此影响较小。毕竟普通人丢了100块钱和富豪丢了100块钱损失是不一样的。
二、帧内预测
由于同一张图片中各个块之间有较强的关联性,因此第一张图片的其他CTU进来时,不需要再像第一张图片一样处理了。
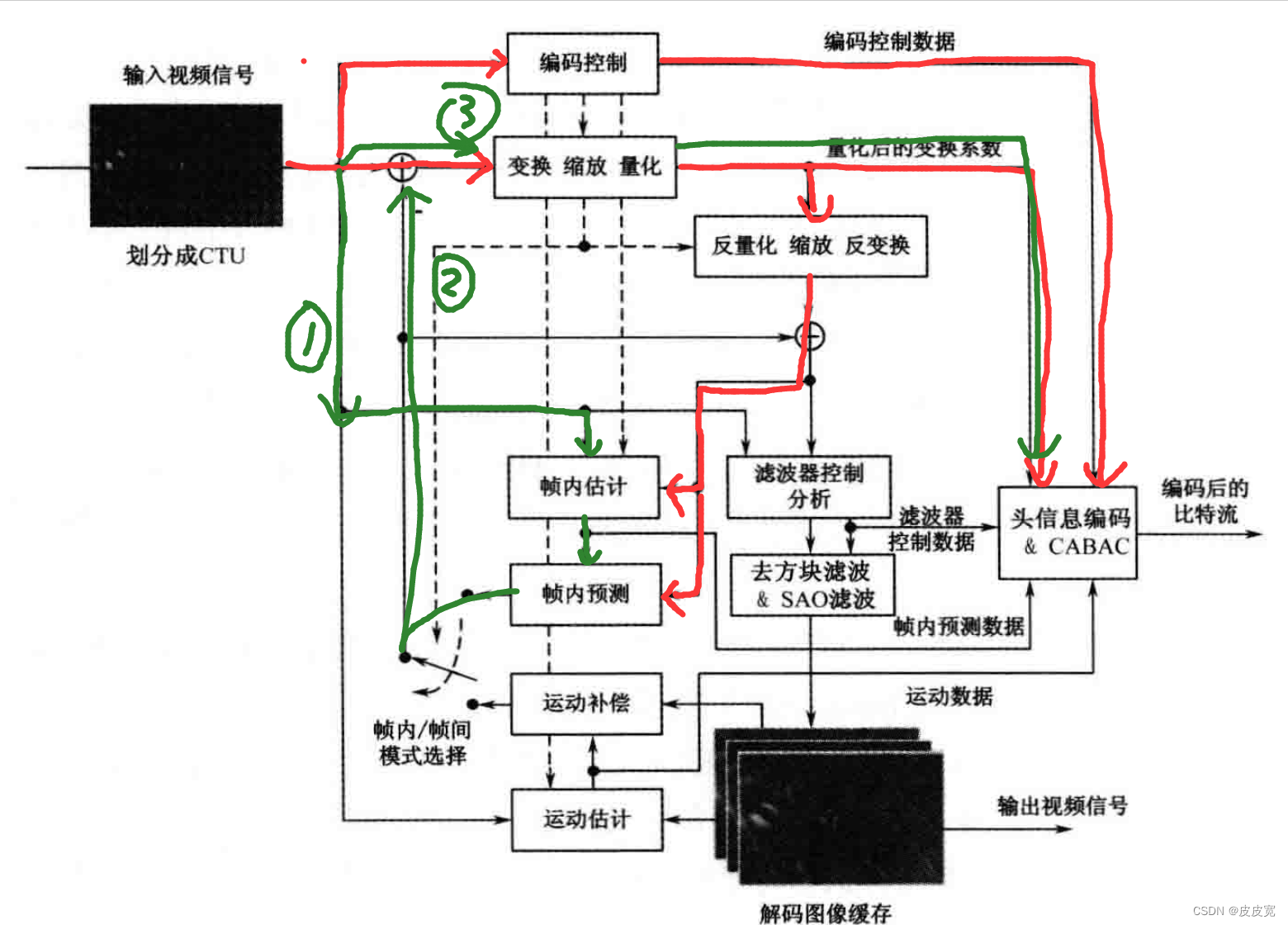
第一张图片的其他小块进来时,处理流程如绿色线部分所示;首先,我们将上一帧的图片进行反量化和反DCT变换来进行恢复(红色线)。根据恢复的数据和新的CTU块来选择一种方式进行预测(H.265提供了几种预测方式,参考【4】),最后我们将新的CTU块与预测出的CTU块做减法,只保留差值就行。也就是说,一张图片的其他块输入时,我们只需要保留,根据前面的CTU预测当前CTU的模式,和预测后的误差,然后经过DCT变换和量化即可。
三、帧间估计
以上是一张图片的处理流程,那下一张图片怎么处理呢?前面也说到了,视频里连续的图片相似度很高,因此H.265/HEVC引入了帧间编码。处理流程如蓝色线条所示。

1、去方块滤波和SAO滤波
由于CTU的处理方式,和高频信号损失的原因,因此我们恢复信号时,除了要进行DCT反变换和反量化,还需要增加一个去方块滤波和SAO滤波。简单来说,我们需要先模拟一下解码端,将之前的图片进行解码,模拟解码端能获得的图片(图中‘解码图像缓存’处)。
2、运动估计和运动补偿
我们根据解码后的前一张图像和当前输入的图片的CTU块进行一个运动的估计,运动补偿模块根据运动数据和上一张图片的CTU,预估一下这张图片CTU的值,最后和这种图片CTU的值做个减法,只保留运动估计模块估计出来的运动信息,和根据这个信息恢复图片与原始数据的差值即可。
3、帧间模式流程
总的来说,帧间编码就是,根据上一张图片的CTU和当前图片对应位置的CTU,分析出一个运动数据,然后根据这个运动数据和上一张图片的CTU来恢复预测当前图片位置CTU的值,最后只保留运动信息,和预测值与实际值的差值即可
四、总结
-
- H.265/HEVC采用帧内帧间混合编码,由控制模块决定当前CTU采用帧内还是帧间编码;
-
- 帧内模式保存预测模式和一个差值,解码端根据预测模式和同一张图片的前面的CTU来预测当前CTU,再加上这个差值,解码端就恢复当前CTU了;
-
- 帧间编码保存一个运动信息和差值,解码端可以根据前一张图片的对应位置CTU和这个运动信息,估算出当前CTU的值,再加上差值,就恢复当前CTU了
五、参考资料
-
【1】新一代高效视频编码H.265/HEVC:原理、标准与实现,作者:万帅、杨付正;

