������Ӿ�֮R-CNN, Fast R-CNN, Faster R-CNNĿ����
һ��Ŀ����
1.1 ����
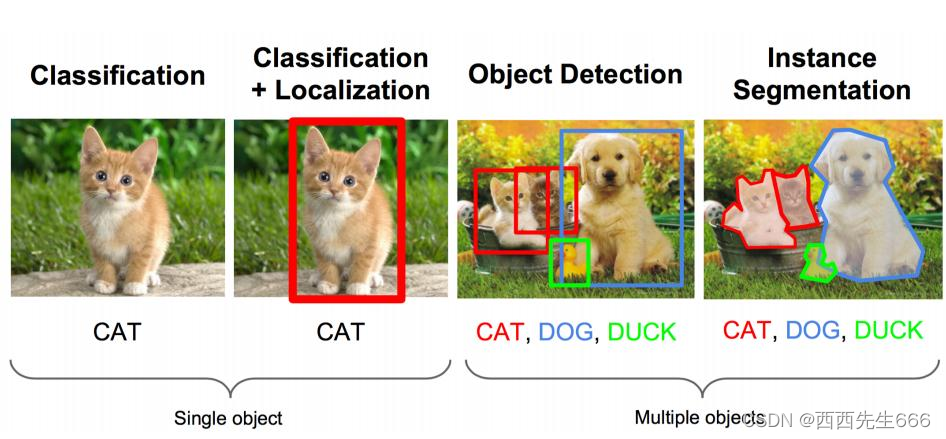
- ��λ�ͷ���:���ڽ���һ��Ŀ���ͼƬ,������Ŀ��������λ�ü���Ŀ������;
- Ŀ����:�����ж��Ŀ���ͼƬ,��������Ŀ��������λ�ü����;
- ��ͼ���Ϊ��λ�ͷ�������,�Ҳ�ΪĿ��������;
1.2 ��λ+����
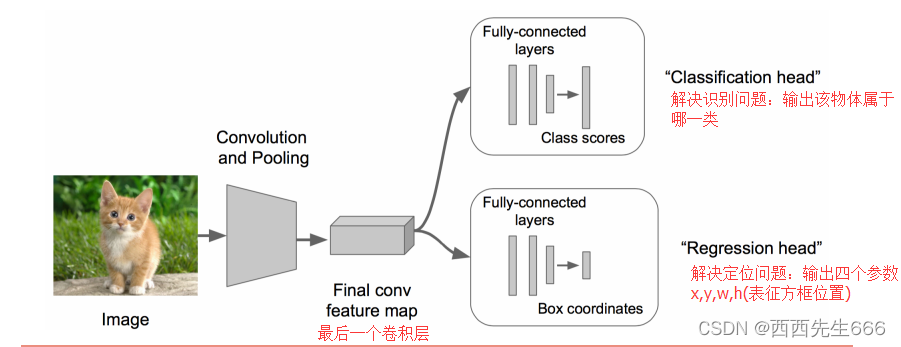
- ��������ͼƬ,��λ������Ҫ����ͼƬ��Ŀ����������,��Ŀ��� ( x , y , w , h ) (x, y, w, h) (x,y,w,h)��Ԫ��,��Ԫ���Ԥ��ɿ����ع�����;
- ��������Ҫʶ��Ŀ������;


- ��λ+����ľ��岽������:
1)ѵ��������һ������ģ��,����Alexnet��VGGNet,Resnet;
2)�ڷ����������һ���������������(feature map)������"Regression head";
3)ͬʱѵ��"Classification head"��"Regression head",Ϊ��ͬ��ѵ������ͻع�����,������ʧ�����Ƿ���Ͷ�λ����"head"��������ʧ�ļ�Ȩ��;
4)����ʹ�÷���ͻع������"head"�õ�����+��λ�Ľ��,����Ԥ��Ľ���� C C C�����,�ع�Ԥ����������:һ���������,���4��ֵ;һ����������,��� 4 ? C 4*C 4?C��ֵ��
1.3 Ŀ����
- Ŀ������Ҫ��ȡͼƬ������Ŀ���λ�ü����,��ͼƬ��ֻ��һ��Ŀ��ʱ,"Regression head"Ԥ��4��ֵ,��ͼƬ��������Ŀ��ʱ,"Regression head"Ԥ��12��ֵ,��ͼƬ���ж��Ŀ��ʱ,"Regression head"ҪԤ��϶��ֵ;
- ������������,������ֽ������:
1)ʹ�û����ķ������,��Ҫ��ƴ����IJ�ͬ�߶Ⱥͳ����ȵġ���������ʹ����ͨ��CNN,�˷�����������,�ݲ�����;
2)ʹ��һ�ִ�ͼƬ��ѡ��DZ�������ѡ��(Region of Interest,ROI)�ķ���selective search,���ڴ˷��������RCNN��
1.4 R-CNN(Region-CNN)
- RCNNѵ��������ͼ��ʾ:
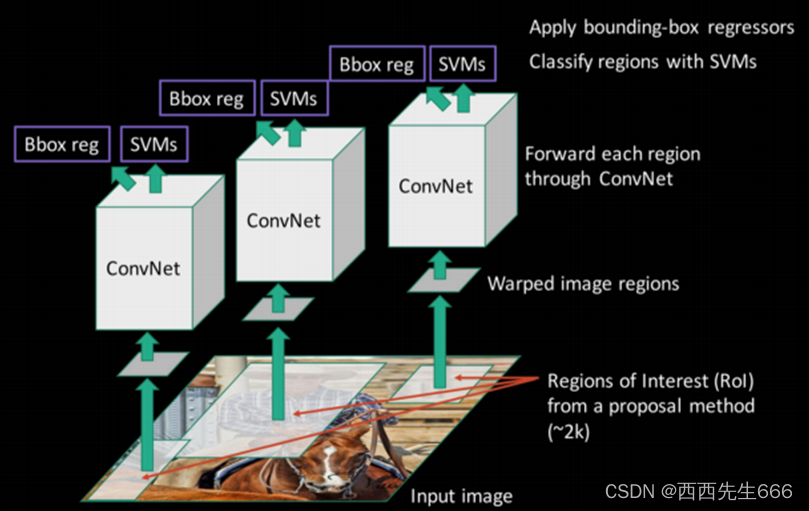
- ѵ����������:
1)ѡ��DZ��Ŀ���ѡ��ROI:����selective search��������2000��DZ�������ѡ��ROI,Ȼ���ÿ����ѡ��Resize�ɹ̶���С;
2)ѵ��һ��������ȡ��:����AlexNet��VGGNet��GoolgeNet��ResNet��CNNģ����ȡһ��4096ά����������,�õ����һ����������;
Ϊ�˻��һ���Ϻõ�������ȡ��,һ����ģ��������,Ψһ�ĸĶ����ǽ�ģ�͵�1000����������Ϊ ( C + 1 ) (C+1) (C+1)�����,���� C C CΪ��ʵԤ��������, 1 1 1�DZ��������,�µ�����ѵ��������������ݶ��½���SGD����ѵ��,��ȡѵ���õ�ģ�͵����һ��������;
��������������ָ��IOU(Intersection Over Union),����������������Ľ������Բ���,�ٶ������������,1�����α�ʾROI,��һ�����α�ʾ��ʵ�ľ��ο�,�� R O I �� 0.5 ROI\ge 0.5 ROI��0.5ʱ,��Ϊ�������λ����ཻ,��Ϊ��������;����Ϊ������;
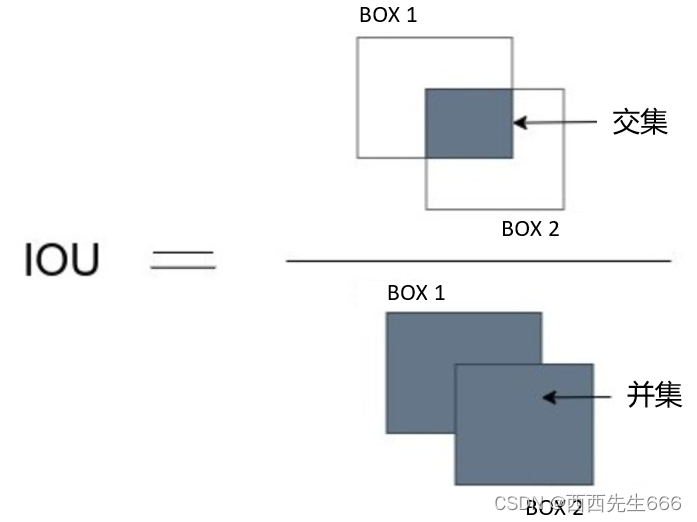
����RCNN��������ȡ���Ϳ�ʼѵ����,ѵ��������Ҫ�������������в���,ѵ����������̫�ٻᵼ������������ƽ��,������ȡһ��4096ά����������;
3)ѵ�����շ�����:��������������SVM��������,Ԥ�����ѡ�����жຬ��������ÿ����ĸ���ֵ(ÿ�����ѵ��һ��SVM,�ж��Ƿ�����������,������positive,��֮nagative),RCNN���������ѡ����ʵֵ�ľ������Ϊ������;
4)ѵ���ع�ģ��:����ÿһ����,ѵ��һ�����Իع�ģ��,����ROI����ʵ���ο�λ�úʹ�С��ƫ��;

- ����IOU����������ʾ:
def cal_IOU(boxA, boxB):
A_xmin = boxA[0]
A_ymin = boxA[1]
A_xmax = boxA[2]
A_ymax = boxA[3]
A_width = A_xmax - A_xmin
A_height = A_ymax - A_ymin
B_xmin = boxB[0]
B_ymin = boxB[1]
B_xmax = boxB[2]
B_ymax = boxB[3]
B_width = B_xmax - B_xmin
B_height = B_ymax - B_ymin
xmin = min(A_xmin, B_xmin)
ymin = min(A_ymin, B_ymin)
xmax = max(A_xmax, B_xmax)
ymax = max(A_ymax, B_ymax)
A_B_width_and = (A_width + B_width) - (xmax - xmin) # ���Ľ���
A_B_height_and = (A_height + B_height) - (ymax - ymin) # �ߵĽ���
if A_B_width_and <= 0.0001 or A_B_height_and <= 0.0001:
return 0
area_and = A_B_width_and * A_B_height_and
area_or = A_width * A_height + B_width * B_height
IOU = area_and / (area_or - area_and)
return IOU
if __name__ == '__main__':
rect1 = (661, 27, 679, 47)
rect2 = (662, 27, 682, 47)
iou = cal_IOU(rect1, rect2)
print("IOU={:.4f}".format(iou))
#���
IOU=0.8095
- Ԥ�ⲽ������:
1)ʹ��selective search��������2000��ROI;
2)����ROI����Ϊ������ȡ��������������С������������ȡ,�õ���2000��ROI��Ӧ��2000��4096ά����������;
3)��2000�����������ֱ����뵽SVM��,�õ�ÿ��ROIԤ�����;
4)ͨ���ع�������ROI��λ��;
5)����ʹ�ü���ֵ����(Non-MaximumSuppression, NMS)������ͬһ����ROI���кϲ��õ����ռ������NMS��ԭ���ǵõ�ÿ�����ο�ķ���(���Ŷ�),����������ο��IOU����ָ����ֵ,���������������Ǹ����ο�
1.5 Fast R-CNN
1.5.1 R-CNNȱ��
- 2000��ROI��CNN������ȡռ�ô���ʱ��;
- CNN����������ΪSVM�ͻع�ĵ���������;
- R-CNNѵ�����̸���,�������˵�����ѵ������(��ΪR-CNN���Ƚ���2000��ROI����ȡ,����ȡ�Ľ���ٷŽ�CNN�н���������ȡ�ͺ���ѵ��,��2������,�����Ƕ˵��˵�ѵ��);
1.5.2 SPP Net (Spatial Pyramid Pooling�ռ�������ػ�)
- Ҫ���������:
1)һ��CNN���ȫ���Ӳ���߷�����,���Ƕ���Ҫ�̶�������ߴ�,��˲��ò����������ݽ��вü�,��ЩԤ������������ݵĶ�ʧ�ε�ʧ�档SPP Net�ĵ�һ�������ǽ�������˼����뵽CNN,�ھ������ȫ���Ӳ�֮�������SPP layer����ʱ������������������߶ȵ�,����Ҫ��������ȡǰ��ͼ����resize����,��SPP layer��ÿһ��pooling��filter��������������С,��SPP������߶�ʼ���ǹ̶���;
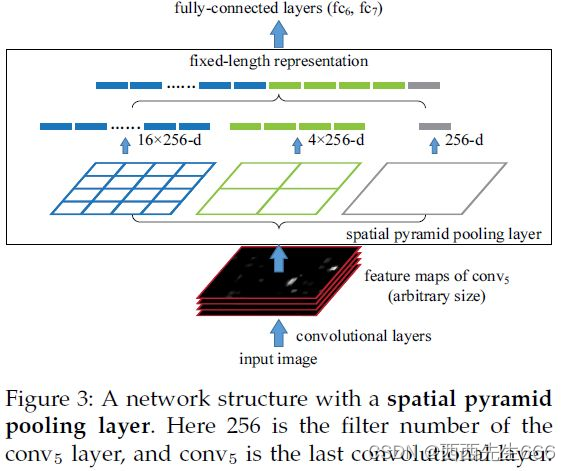
����ԭͼ������224x224,����conv5������������13x13x256��,�����������256��������filter,ÿ��filter��Ӧһ��13x13��reponse map���������ͼ������reponse map�ֳ�1x1(����������),2x2(�������м�),4x4(����������)������ͼ,�ֱ���max pooling��,��������������(16+4+1)x256 ά�ȡ����ԭͼ�����벻��224x224,������������Ȼ��(16+4+1)x256ά�ȡ�������ʵ���˲���ͼ��ߴ���� �ػ�n �������Զ�� (16+4+1)x256 ά�ȡ� - ����sppnet�������,����ROI Pooling��
1.5.3 Fast R-CNNԭ��
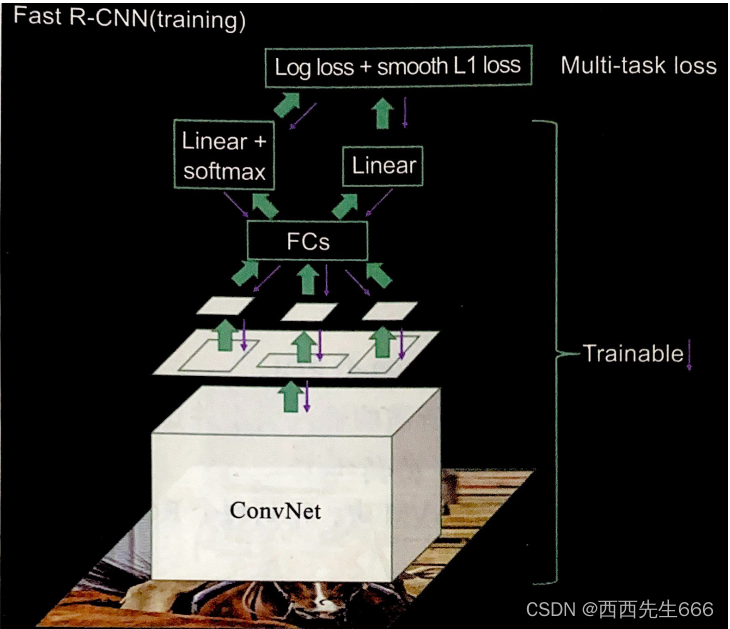
- ѵ����������ͼ��ʾ,��������:
1)������ͼƬ�����ֺõ�ROIֱ�����뵽ȫ������CNN��,��ʱ����ͼƬ����ȫ��������,����Ҫ��ROI����ȫ��������,������õ�������Ͷ�Ӧ���������ϵ�ROI(��ʱROI���Ը����伯��λ�üӾ�����ʽ�Ƶ��ó�);
2)Ϊ�˱�֤FCs(ȫ���Ӳ�)����ߴ�һ��,���������ϵ�ROI�ߴ��С��һ,����Ҫ����ROI Pooling�㴦��,����ROI Pooling���ת��Ϊ�ߴ�һ�µ���������(������Ϊ M ? N M*N M?N);
3)����ROI Pooling���,ȫ����2000�� M ? N M*N M?N��ѵ������ͨ��ȫ���Ӳ㲢�ֱ�2��head:Softmax���༰L2�ع�,������ʧ�����Ƿ���ͻع���ʧ�����ļ�Ȩ�͡� - ���Թ�������ͼ��ʾ��
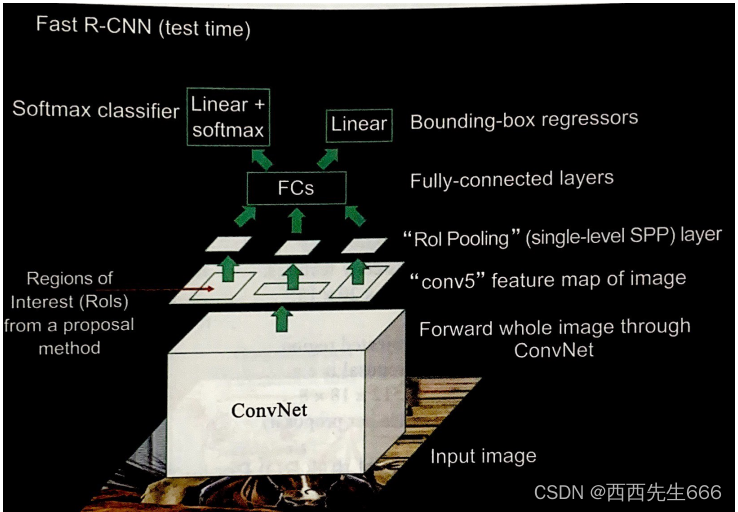
�ص�:
1)R-CNNһ��ȱ��:����ÿһ����ѡ��Ҫ���Ծ���CNN,��ʹ�û��ѵ�ʱ��dz��ࡣ
���:����������,���ڲ���ÿһ����ѡ�����������CNN��,��������һ��������ͼƬ,�ڵ�����������ٵõ�ÿ����ѡ�������
2)ԭ���ķ���:�����ѡ��(������ǧ��)�C>CNN�C>�õ�ÿ����ѡ��������C>����+�ع�
���ڵķ���:һ������ͼƬ�C>CNN�C>�õ�ÿ�ź�ѡ��������C>����+�ع�
3)����������,Fast RCNN�����RCNN������ԭ�������:����RCNN��ÿ����ѡ������������������,��������ͼ��һ������,�ٰѺ�ѡ��ӳ�䵽conv5��,��SPPֻ��Ҫ����һ������,ʣ�µ�ֻ��Ҫ��conv5���ϲ����Ϳ����ˡ�
������������Ҳ���൱���Ե�:
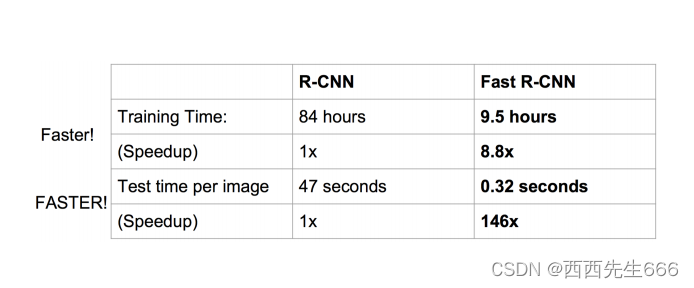
1.6 Faster R-CNN
1.6.1 Fast R-CNNȱ��
- ѡ��������selective search,�ҳ����еĺ�ѡ��,���Ҳ�dz���ʱ��
���:����һ����ȡ��Ե��������,��ѡ���ѡ��ROI�Ĺ���Ҳ���������������ˡ�����������������������Region Proposal Network(RPN)��
1.6.2 RPN����ԭ��
- RPN�����������:
����? ��RPN�������һ��������ĺ���;
����? RPNֱ��ѵ���õ���ѡ����; - RPN�ĺ���˼����:����һ��С��ȫ��������,���������С��ͼƬ,���ROI�ľ���λ�ü���ROI�Ƿ�ΪĿ��,RPN�����ھ�������������һ�������ϻ�����
- ����ͼa)��ʾ,�������ɫ������Ϊ�����������������,����ʾRPN������,��С�� 3 ? 3 3*3 3?3,�������ӵ�256ά�������ϡ���� 3 ? 3 3*3 3?3�Ĵ��ڻ�����������������,����ÿ�μ��㶼����256ά���������������2�����:�� 3 ? 3 3*3 3?3�����������Ƿ�������,�Լ��û������ڶ�Ӧ����ľ����λ�ö�Ӧ��4��ֵ;
- b)ͼΪ������ת��Ϊ����������м���Ĺ��̱�ʾ;
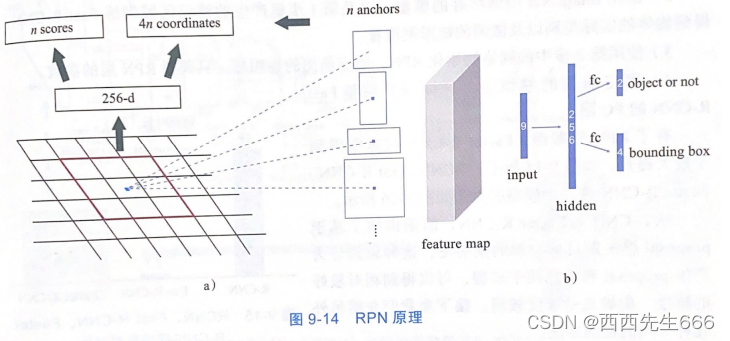
- Ϊ����Ӧ������״������,RPN������ K K K�ֲ�ͬ�߶ȵĻ���,ͳһ�� 3 ? 3 3*3 3?3�Ļ�����������������,��ʱ����һ��רҵ����anchor(anchor:��Ϊê��,λ�� n ? n n*n n?n���ڵ����Ĵ�),ÿ��anchor����������(feature map)�ϵ����ص�Ϊ���IJ��Ҹ�����ߴ��С���к�������ġ���Faster R-CNN������,�������������ÿ��λ��ʹ��3�ִ�С��3�ֱ���,���� 3 ? 3 = 9 3*3=9 3?3=9��anchor,����ͼ�� n = 9 n=9 n=9��
- �����������,���ڻ���������ÿһ��anchor�������anchor����ʵ��Ǿ�����IOU,�� I O U �� 0.7 IOU\ge0.7 IOU��0.7ʱ,����Ϊ��anchor����Ŀ��;�� I O U �� 0.3 IOU\le0.3 IOU��0.3ʱ,����Ϊ��anchor������Ŀ��;��IOU����0.3~0.7ʱ,��������ѵ���ĵ������̡�
- ����ع�����,��ҪԤ��anchor���ĵ�ĺᡢ�������Լ�anchor�Ŀ�����,ѧϰĿ��Ϊanchor����ʵbox���ĸ�ֵ�ϵ�ƫ��,RPNΪһ��ȫ��������,����������ݶ��½�SGD�ķ�ʽ���ж˵��˵�ѵ����
- ��Ҫע�����,ѵ������������ʵĿ�������ཻ�� I O U �� 0.7 IOU\ge 0.7 IOU��0.7��anchor������,����������Ǹ�����,��˻ᵼ������������������ʧ�⡣�����RPNѵ��������,��ÿ��batch�����������(��ÿ��batch������Ϊ256)������������������Ϊ1:1,��������������С��128ʱ,ȥȫ��������,����������ʹ�ø��������в�ȫ��
1.6.3 Faster R-CNNԭ��
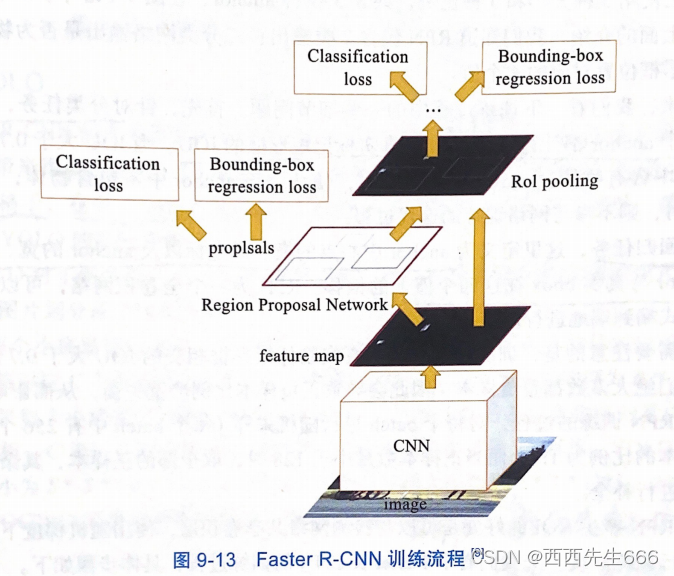
- Faster R-CNNѵ����������ͼ��ʾ,ѵ������Ϊ:
1)ʹ�ö�����ͼƬ���CNN,�õ�feature map;
2)�����������뵽RPN,�õ���ѡ���������Ϣ;
3)�Ժ�ѡ������ȡ��������,����ROI Pooling��任Ϊ�ߴ��Сһ�µĺ�ѡ����;
4)���任�������ʹ�÷������б��Ƿ�����һ���ض���;
5)��������ijһ�����ĺ�ѡ��,�ûع�����һ��������λ�á�
1.7 �ܽ�����㷨����
�ο���ַ:https://www.cnblogs.com/skyfsm/p/6806246.html
RCNN:
����1. ��ͼ����ȷ��Լ2000����ѡ�� (ʹ��ѡ��������);
����2. ÿ����ѡ����ͼ�����������ͬ��С,�����뵽CNN�ڽ���������ȡ ;
����3. �Ժ�ѡ������ȡ��������,ʹ�÷������б��Ƿ�����һ���ض���;
����4. ��������ijһ�����ĺ�ѡ��,�ûع�����һ��������λ�á�
Fast RCNN:
����1. ��ͼ����ȷ��Լ2000����ѡ�� (ʹ��ѡ��������);
����2. ������ͼƬ���CNN,�õ�feature map;
����3. �ҵ�ÿ����ѡ����feature map(������conv5����������Ϊfeature map)�ϵ�ӳ���ѡ��,���˺�ѡ����Ϊÿ����ѡ��ľ����������뵽SPP layer��֮��IJ�;
����4. �Ժ�ѡ������ȡ��������,ʹ�÷������б��Ƿ�����һ���ض���;
����5. ��������ijһ�����ĺ�ѡ��,�ûع�����һ��������λ�á�
Faster RCNN:
����1. ������ͼƬ���CNN,�õ�feature map;
����2. �����������뵽RPN,�õ���ѡ���������Ϣ;
����3. �Ժ�ѡ������ȡ��������,ʹ�÷������б��Ƿ�����һ���ض���;
����4. ��������ijһ�����ĺ�ѡ��,�ûع�����һ��������λ�á�

