Word2Vec进阶 - Bert – 潘登同学的NLP笔记
文章目录
Bert介绍
BERT,全称是Pre-training of Deep Bidirectional Transformers for Language Understanding。注意其中的每一个词都说明了BERT的一个特征。
- Pre-training说明BERT是一个预训练模型,通过前期的大量语料的无监督训练,为下游任务学习大量的先验的语言、句法、词义等信息;
- Bidirectional说明BERT采用的是双向语言模型的方式,能够更好的融合前后文的知识;
- Transformers说明BERT采用Transformers作为特征抽取器;
- Deep说明模型很深,base版本有12层,large版本有24层

总的来说,BERT是一个用Transformers作为特征抽取器的深度双向预训练语言理解模型。
BERT的结构
Bert采用的是双向Transformer组件,也就是Transformer的encoder部分,而一个Transformer的encoder部分里面有6个Encoder(一个Encoder称为一层Transformer),那么Bert有12层,就是12个Encoder啦

Bert的输入
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vVlIz1Ry-1651885619501)(https://ask.qcloudimg.com/http-save/yehe-1508658/psxkv6hvcr.png?imageView2/2/w/1620)]](https://img-blog.csdnimg.cn/c699488ae6eb4debbe1d0eaa1ba383e4.png)
如上图所示,BERT接受的输入包括三个部分:
- 词嵌入后的Token Embedding,每次输入总以符号
[CLS]的embedding开始,如果是两个句子,则句之间用[SEP]隔开。 - 句子类别的符号(是否为同一句)
- Position Embedding,这个与Transformer中的一致
Bert的输出
Bert的输出可以理解为RNN的隐状态输出了,拿过来接一层全连接就能做分类任务了…
预训练任务
Masked Language Model(MLM)
BERT会在训练时遮住训练语料中15%的词(实际的MASK机制还有一些调整),用符号[MASK]代替,通过预测这部分被遮住的内容,来让网络学习通用的词义、句法和语义信息。

MLM是BERT能够不受单向语言模型所限制的原因。简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。然而,由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)。因此BERT采用了以下策略来解决这个问题:
- 80%的时候是[MASK]。如,my dog is Cute——>my dog is [MASK]
- 10%的时候是随机的其他token。如,my dog is Cute——>my dog is apple
- 10%的时候是原来的token。如,my dog is hairy——>my dog is hairy
Next Sentence Prediction(NSP)
一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练,简单来说就是预测两个句子是否连在一起。具体的做法是:对于每一个训练样例,我们在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。

总结
bert是预训练大模型,用于提特征的,不是某一类具体下游任务(如:分类,分词,聊天机器人等),但是可以作为这些下游任务的主干网络,在bert后面接一层全连接转成结果对应的维度,进行微调就能用!
ERNIE
ERNIE: Enhanced Language Representation with Informative Entities 提出了将知识显性地加入到BERT中

相比于BERT, ERNIE 1.0 改进了两种 masking 策略,一种是基于phrase (在这里是短语 比如 a series of, written等)的masking策略,另外一种是基于 entity(在这里是人名,位置, 组织,产品等名词 比如Apple, J.K. Rowling)的masking 策略。在ERNIE 当中,将由多个字组成的phrase 或者entity 当成一个统一单元,相比于bert 基于字的mask, 这个单元当中的的所有字在训练的时候,统一被mask. 对比直接将知识类的query 映射成向量然后直接加起来,ERNIE 通过统一mask的方式可以潜在的学习到知识的依赖以及更长的语义依赖来让模型更具泛化性。
ERNIE2.0
传统的pre-training 模型主要基于文本中words 和 sentences 之间的共现进行学习, 事实上,训练文本数据中的词法结构,语法结构,语义信息也同样是很重要的。在命名实体识别中人名,机构名,组织名等名词包含概念信息对应了词法结构。句子之间的顺序对应了语法结构,文章中的语义相关性对应了语义信息。为了去发现训练数据中这些有价值的信息,在ERNIE 2.0 中,提出了一个预训练框架,可以在大型数据集合中进行增量训练
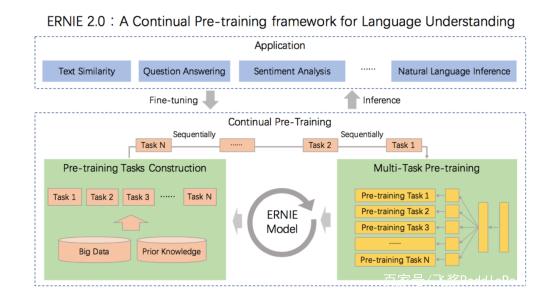
ERNIE 2.0 中有一个很重要的概念便是连续学习(Continual Learning),连续学习的目的是在一个模型中顺序训练多个不同的任务以便在学习下个任务当中可以记住前一个学习任务学习到的结果。通过使用连续学习,可以不断积累新的知识,模型在新任务当中可以用历史任务学习到参数进行初始化,一般来说比直接开始新任务的学习会获得更好的效果。
预训练连续学习
ERNIE 的预训练连续学习分为两步,首先,连续用大量的数据与先验知识连续构建不同的预训练任务。其次,不断的用预训练任务更新ERNIE 模型。
ERNIE 2.0 分别构建了词法级别,语法级别,语义级别的预训练任务。所有的这些任务,都是基于无标注或者弱标注的数据。需要注意的是,在连续训练之前,首先用一个简单的任务来初始化模型,在后面更新模型的时候,用前一个任务训练好的参数来作为下一个任务模型初始化的参数。这样不管什么时候,一个新的任务加进来的时候,都用上一个模型的参数初始化保证了模型不会忘记之前学习到的知识。通过这种方式,在连续学习的过程中,ERNIE 2.0 框架可以不断更新并记住以前学习到的知识可以使得模型在新任务上获得更好的表现;

