ЫЕУї:етЪЧвЛИіЛњЦїбЇЯАЪЕеНЯюФП(ИНДјЪ§Он+ДњТы+ЮФЕЕ+ЪгЦЕНВНт),ШчашЪ§Он+ДњТы+ЮФЕЕ+ЪгЦЕНВНтПЩвджБНгЕНЮФеТзюКѓЛёШЁЁЃ
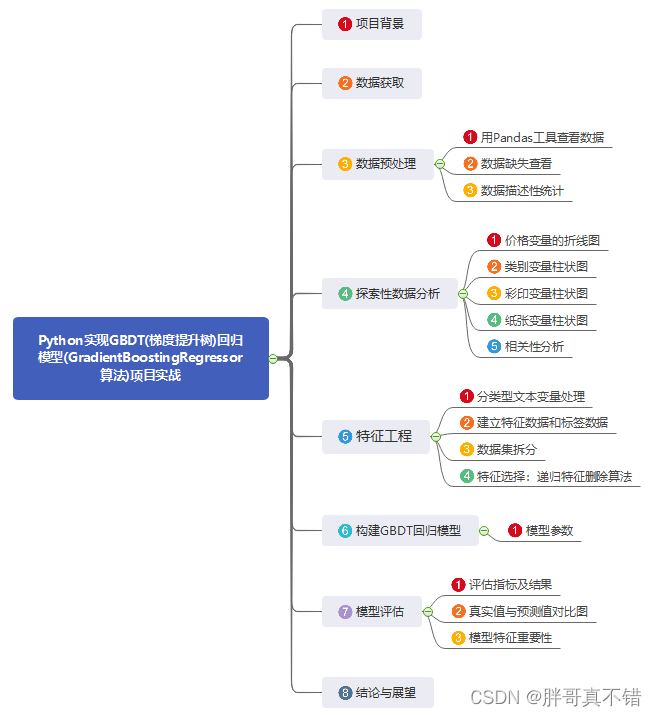
1.ЯюФПБГОА
GBDTЪЧGradient Boosting Decision Tree(ЬнЖШЬсЩ§Ъї)ЕФЫѕаДЁЃГіАцЩчдкЖдЭМЪщНјааЖЈМлЪБЛсПМТЧЭМЪщЕФвГЪ§ЁЂжНеХЁЂРрБ№ЁЂФкШнЁЂзїепМАЖСепЕШКмЖрвђЫи,гУШЫЙЄРДЗжЮіНЯЮЊЗГЫі,ВЂЧвШнвзвХТЉЁЃШчЙћФмНЈСЂвЛИіФЃаЭзлКЯПМТЧИїЗНУцвђЫиЖдЭМЪщНјааЖЈМл,ФЧУДОЭФмИќМгПЦбЇКЯРэЕиНкдМГЩБОЁЂЬсЩ§аЇТЪ,ВЂдкТњзуЖСепашЧѓЕФЭЌЪБДйНјЯњЪл,ЭкОђИќЖрЧБдкРћШѓЁЃИУGBDTЫуЗЈВњЦЗЖЈМлФЃаЭвВПЩвдгУгкЦфЫћСьгђЕФВњЦЗЖЈМл,ШчН№ШкВњЦЗЕФЖЈМлЁЃ
2.Ъ§ОнЛёШЁ
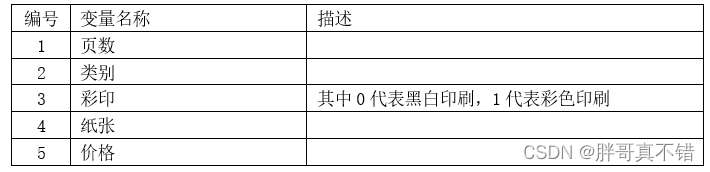
БОДЮНЈФЃЪ§ОнРДдДгкЭјТч(БОЯюФПзЋаДШЫећРэЖјГЩ),Ъ§ОнЯюЭГМЦШчЯТ:
Ъ§ОнЯъЧщШчЯТ(ВПЗжеЙЪО):
?
3.Ъ§ОндЄДІРэ
3.1 гУPandasЙЄОпВщПДЪ§Он
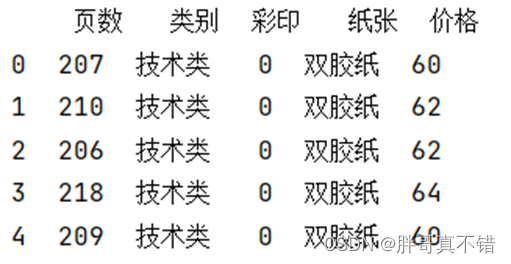
ЪЙгУPandasЙЄОпЕФhead()ЗНЗЈВщПДЧАЮхааЪ§Он:
?
ЙиМќДњТы:
?
3.2Ъ§ОнШБЪЇВщПД
ЪЙгУPandasЙЄОпЕФinfo()ЗНЗЈВщПДЪ§ОнаХЯЂ:
?ДгЩЯЭМПЩвдПДЕН,змЙВга5ИіБфСП,Ъ§ОнжаЮоШБЪЇжЕ,ЙВ1000ЬѕЪ§ОнЁЃ
ЙиМќДњТы:
?
3.3Ъ§ОнУшЪіадЭГМЦ
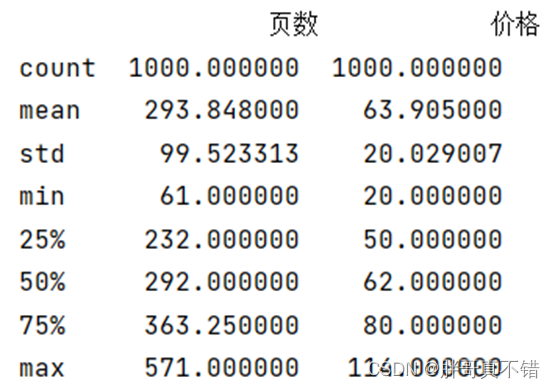
ЭЈЙ§PandasЙЄОпЕФdescribe()ЗНЗЈРДВщПДЪ§ОнЕФЦНОљжЕЁЂБъзМВюЁЂзюаЁжЕЁЂЗжЮЛЪ§ЁЂзюДѓжЕЁЃ
ЙиМќДњТыШчЯТ:
?
4.ЬНЫїадЪ§ОнЗжЮі
4.1 МлИёБфСПЕФелЯпЭМ
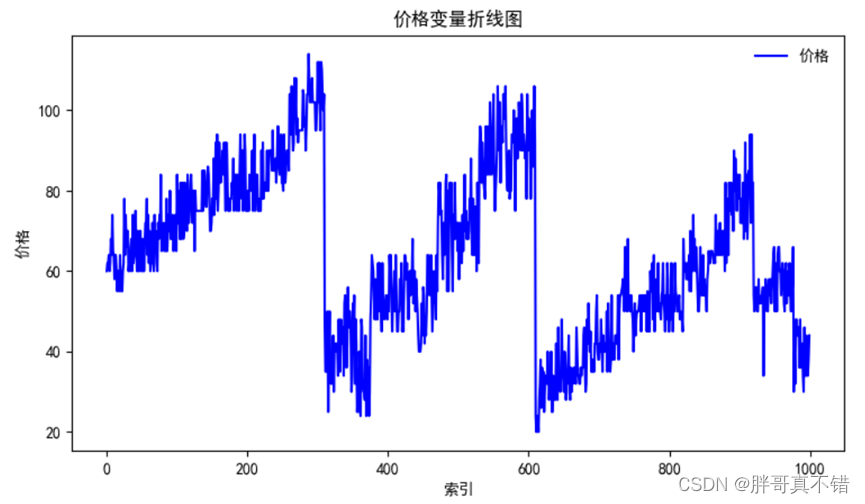
гУMatplotlibЙЄОпЕФplot()ЗНЗЈЛцжЦелЯпЭМ:
4.2 РрБ№БфСПжљзДЭМ
гУPandasЙЄОпЕФplot(kind=ЁЎbarЁЏ)ЗНЗЈЛцжЦжљзДЭМ:
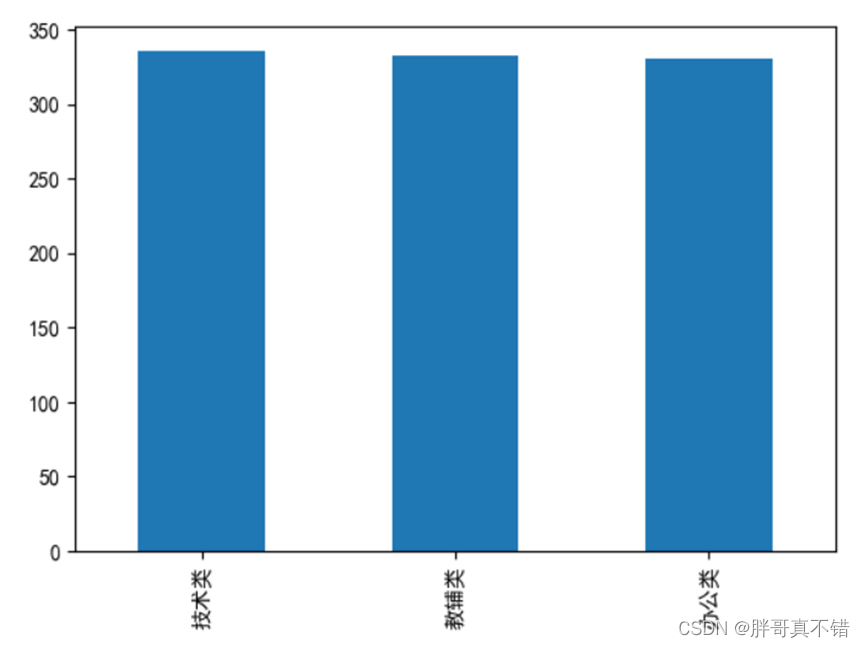
4.3 ВЪгЁБфСПжљзДЭМ
гУPandasЙЄОпЕФplot(kind=ЁЎbarЁЏ)ЗНЗЈЛцжЦжљзДЭМ:
4.4 жНеХБфСПжљзДЭМ
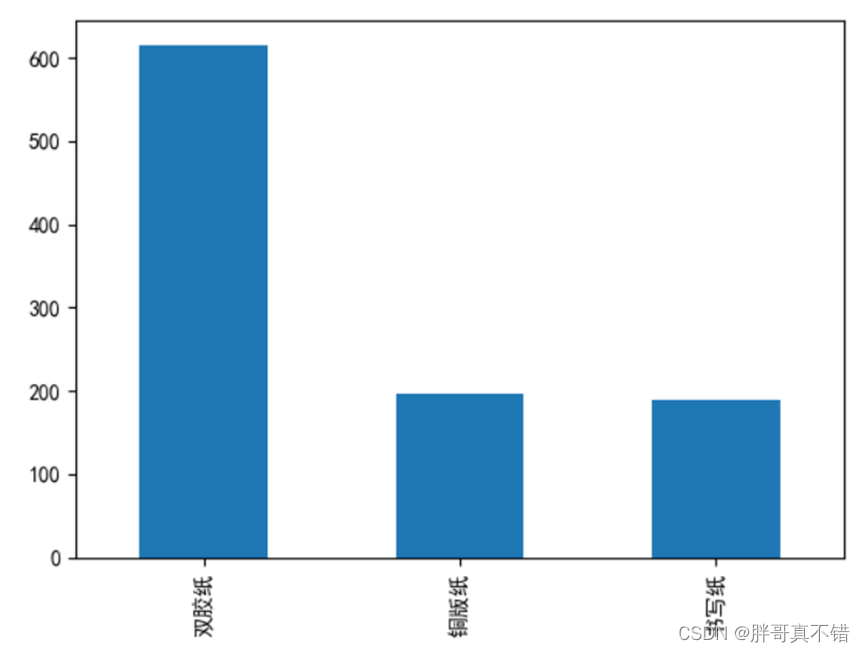
гУPandasЙЄОпЕФplot(kind=ЁЎbarЁЏ)ЗНЗЈЛцжЦжљзДЭМ:
?4.5 ЯрЙиадЗжЮі
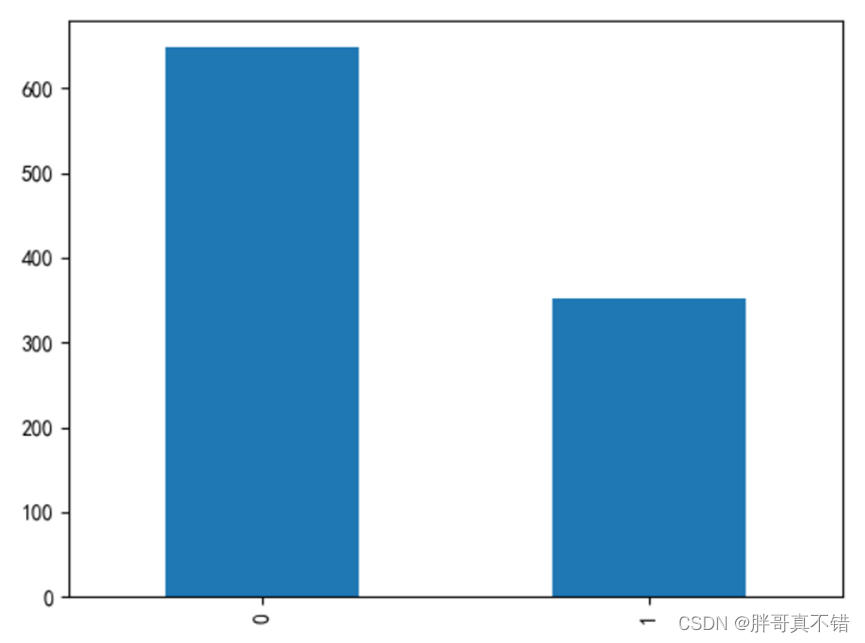
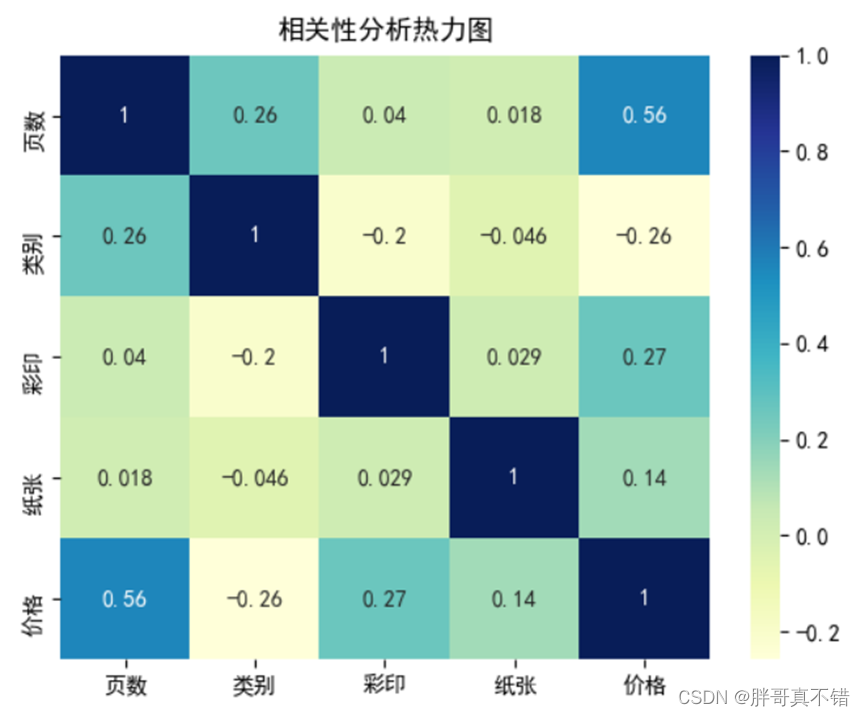
ДгЩЯЭМжаПЩвдПДЕН,Ъ§жЕдНДѓЯрЙиаддНЧП,е§жЕЪЧе§ЯрЙиЁЂИКжЕЪЧИКЯрЙиЁЃ
5.ЬиеїЙЄГЬ
5.1 ЗжРраЭЮФБОБфСПДІРэ
дкЪ§ОнМЏжа,РрБ№КЭжНеХБфСПЮЊЗжРраЭЮФБОБфСП,БОЮФБфСПЮоЗЈжБНггІгУгкЛњЦїбЇЯА,ашвЊзЊЛЛГЩЪ§жЕаЭБфСП,БОЯюФПЪЙгУLabelEncoder()БъЧЉБрТыНјаазЊЛЛ,зЊЛЛКѓЕФНсЙћЮЊ:
?
5.2 НЈСЂЬиеїЪ§ОнКЭБъЧЉЪ§Он
ЙиМќДњТыШчЯТ:
?
5.3 Ъ§ОнМЏВ№Зж
ЭЈЙ§train_test_split()ЗНЗЈАДее80%бЕСЗМЏЁЂ20%ВтЪдМЏНјааЛЎЗж,ЙиМќДњТыШчЯТ:
5.4 ЬиеїбЁдё:ЕнЙщЬиеїЩОГ§ЫуЗЈ
ЪЙгУRFE()ЗНЗЈНјааЬиеїбЁдё,ЗЕЛиЬиеїЕФЙБЯзЧщПі,ЙиМќДњТыШчЯТ:
ЗЕЛиЕФНсЙћ:
ЗЕЛиЕФЪЧЬиеїЙБЯзЖШ,ПЩвдПДЕНзюДѓЕФЪЧ вГЪ§БфСП,зюаЁЕФЪЧ ВЪгЁБфСПЁЃетИідкЪЕМЪгІгУЙ§ГЬжа,ИљОнашвЊНјаабЁдё,гЩгкБОАИР§ЪЙгУЕФЬиеїБфСПВЛЖр,ЫљвдКѓајЕФНЈФЃжа,ЫљгаЬиеїБфСПЖМВЮгыЁЃ
6.ЙЙНЈGBDTЛиЙщФЃаЭ
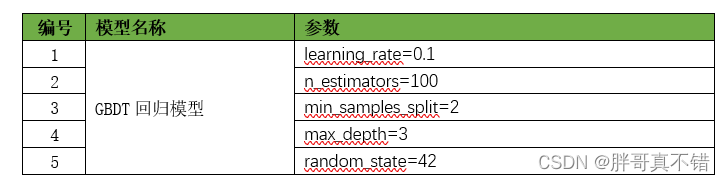
жївЊЪЙгУGradientBoostingRegressorЫуЗЈ,гУгкФПБъЛиЙщЁЃ
6.1ФЃаЭВЮЪ§
7.ФЃаЭЦРЙР
7.1ЦРЙРжИБъМАНсЙћ
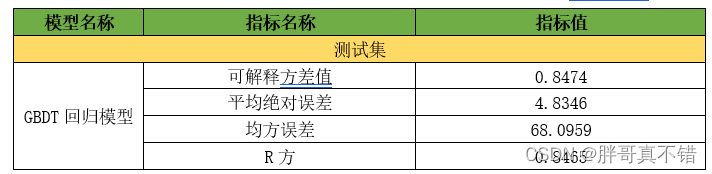
ЦРЙРжИБъжївЊАќРЈПЩНтЪЭЗНВюжЕЁЂЦНОљОјЖдЮѓВюЁЂОљЗНЮѓВюЁЂRЗНжЕЕШЕШЁЃ
?ДгЩЯБэПЩвдПДГі,RЗНЮЊ84.65% ?ПЩНтЪЭЗНВюжЕЮЊ84.74%,GBDTЛиЙщФЃаЭаЇЙћСМКУЁЃ
ЙиМќДњТыШчЯТ:
7.2 ецЪЕжЕгыдЄВтжЕЖдБШЭМ
ДгЩЯЭМПЩвдПДГіецЪЕжЕКЭдЄВтжЕВЈЖЏЛљБОвЛжТ,ФЃаЭФтКЯаЇЙћСМКУЁЃ
7.3 ФЃаЭЬиеїживЊад
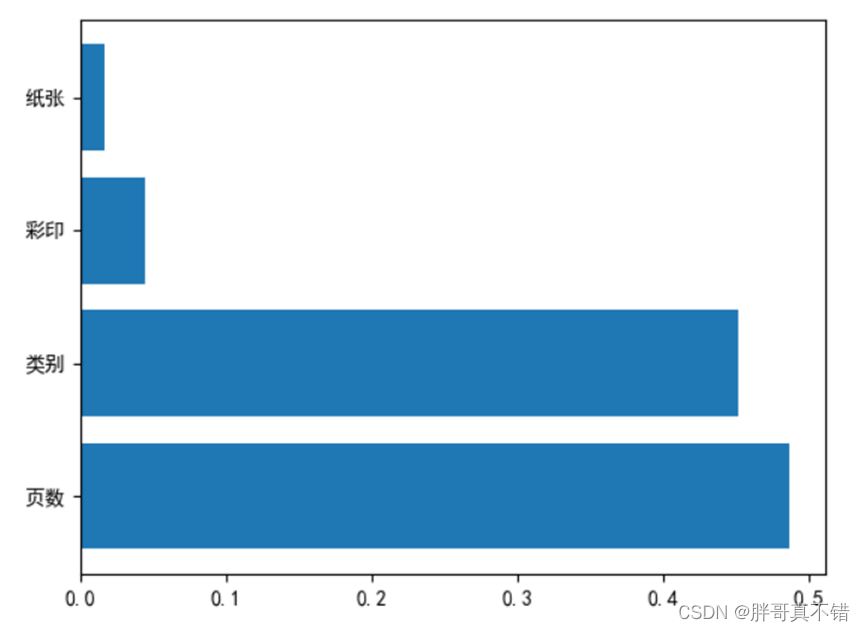
ЬиеїживЊадШчЭМЫљЪО:
ДгЩЯЭМПЩвдПДЕНЬиеїБфСПЖдДЫФЃаЭЕФживЊадвРДЮЮЊ:вГЪ§ЁЂРрБ№ЁЂВЪгЁЁЂжНеХЁЃ
8.НсТлгыеЙЭћ
злЩЯЫљЪі,БОЮФВЩгУСЫGBDTЛиЙщФЃаЭ,зюжежЄУїСЫЮвУЧЬсГіЕФФЃаЭаЇЙћСМКУЁЃДЫФЃаЭПЩгУгкШеГЃВњЦЗЕФЖЈМлЁЃ





БОДЮЛњЦїбЇЯАЯюФПЪЕеНЫљашЕФзЪСЯ,ЯюФПзЪдДШчЯТ:
ЯюФПЫЕУї:
СДНг:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w?
ЬсШЁТы:bcbpЭјХЬШчЙћЪЇаЇ,ПЩвдЬэМгВЉжїЮЂаХ:zy10178083

