【论文阅读】Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
论文地址:https://arxiv.org/abs/1609.04802
0 摘要
对较大的缩放因子进行超分辨率时,想要恢复更精细的纹理细节。最近的工作主要集中在最小化均方重建误差上。由此得到的估计具有很高的峰值信噪比,但它们往往缺乏高频细节,感知上识别不好。本文提出了一个感知损失函数,包括一个对抗损失和内容损失。评价指标采用平均意见得分MOS,这项指标能反应图像的感知质量,SRGAN获得的MOS更接近原始的高分辨率图像。
1 介绍
一般的SR算法优化目标是最小化重建均方误差MSE来提高峰值信噪比PSNR,但是直接这样做只是减少了像素级别的差异,会损失一些纹理细节,在感知上的效果会差一点。
本文采用了一个具有跳跃连接和偏离MSE的深度残差网络(ResNet)作为唯一的优化目标(?)。使用VGG网络的高级特征图结合鉴别器,定义了一种新的感知损失。
1.1 相关工作
1.1.1 图像超分辨率
- 基于预测的方法:可以非常快,但它们过度简化了SISR问题,通常产生过于光滑纹理的解决方案。
- 在低分辨率和高分辨率的图像信息之间建立一个复杂的映射。
- 将基于梯度轮廓先验的边缘定向SR算法与基于学习的细节合成的优点结合起来:为了重建真实的纹理细节,同时避免边缘伪影。
- 多尺度字典:捕获不同尺度下相似图像斑块的冗余。
- 结构感知的对齐匹配准则:从网络中检索了与相似内容相关的HR图像,为了超解析地标图像。
- 邻域嵌入方法:在低维流形中寻找相似的LR训练补丁,并结合其相应的HR补丁进行重建,从而对LR图像补丁进行上采样。
- 基于卷积神经网络(CNN):基于学习的迭代收缩和阈值算法(LISTA)、使用双边插值、使网络能够直接学习升级滤波器、深度递归卷积网络(DRCN)、依赖于一个更接近感知相似性的损失函数来恢复视觉上更有说服力的HR图像(与本文最相近)。
1.1.2 卷积神经网络的设计
- 使用批处理归一化来抵消内部协变量的偏移。
- 设计更深的网络架构,如递归CNN。
- 引入的残差块和跳过连接的概念。
- 将图像输入CNN之前,采用双边缘插值来升级LR观察。
1.1.3 损失函数
单纯的最小化像素重建MSE可能导致解过于平滑因此感知质量较差,丢失高频细节。
- 通过使用生成对抗网络(GANs)应用图像生成来解决这个问题。
- 通过鉴别器损失来增加像素级MSE损失,以训练一个具有大缩放因子的人脸图像(8×)。
- (文中这一段剩下的几个GAN的应用我感觉跟超分没什么关系啊…??)
1.2 本文贡献
描述了第一个非常深的ResNet体系结构,使用GANs的概念来形成一个针对照片逼真的SISR的感知损失函数。
- 我们通过为MSE优化的16块深度ResNet(SRResNet),通过PSNR和结构相似度(SSIM)测量具有高(4×)的标比例因子的图像SR设置了新的技术。
- 提出SRGAN。用在VGG网络的特征映射上计算的损失来替换基于MSE的内容损失,该损失对像素空间的变化更为不变。
- 我们通过对来自三个公共基准数据集的图像进行广泛的平均意见得分(MOS)测试,证实SRGAN是一种用于估计具有高缩放因子的逼真SR图像(4×)的新技术。SRGAN的MOS更接近高分图像。
2 方法
我们的最终目标是训练一个生成函数G,它生成一个给定的LR输入图像与其对应的HR图像。生成网络由以θG为参数的CNN前馈网络组成。θG的公式如下:
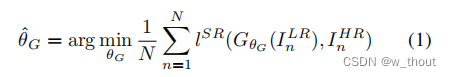
2.1 网络架构
根据原生GAN网络,对抗生成网络就是解决一个最大最小的问题:
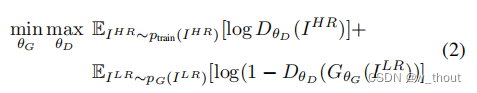
鉴别器鉴别超分辨率图像和真实图像,生成器生成超分辨率图像来骗过鉴别器。这样的过程使得生成的超分辨率图像更符合感知,与之前只关注像素级别的MSE相反。

生成网络中主要有B个相同的残差块。这些残差块由两个具有小的3×3内核和64个特征图的卷积层、两个BN层、两个ParametricReLU激活函数组成。然后通过两个pre-train的亚像素卷积层来提高分辨率,在每个亚像素卷积层中都有一个pixelshuffler层。在这两个亚像素卷积层中,卷积层的卷积核数量是之前的4倍(64->256),因此输出的图片的通道数也是4倍的关系,通过了pixelshuffler层会将这四倍的通道数比率换到宽高上,即(c×4)×w×h->c×(w×2)×(h×2),每次将分辨率提高两倍。
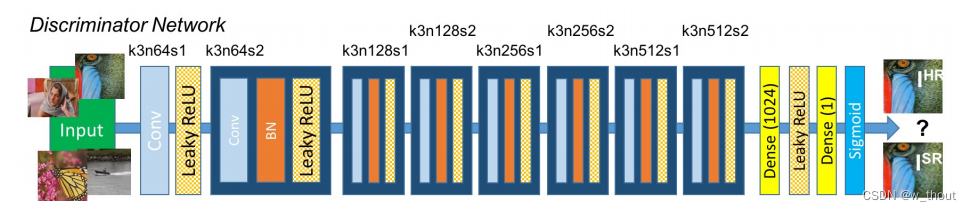
使用LeakyReLU激活(α=0.2),避免了整个网络的最大池化(??)。鉴别器网络包含8个卷积层,3×3卷积核,在VGG网络中从64个增加到512个,增加了2倍。每次特征的数量增加一倍时,跟前面的亚像素卷积层的操作类似,图片的通道数会增加一倍,即图片大小变成(c×2)×w×h,这时候就需要使用卷积核数量、卷积核大小、padding相同但是stride=2的卷积层将图片大小变回原来的大小(卷积计算公式(n+2p-f)/s +1)。最后是两个全连接层和一个sigmoid激活函数,以获得样本分类的概率。
2.2 感知损失函数
感知损失函数的设计是生成网络的关键,表示为内容损失和对抗性损失的加权和:
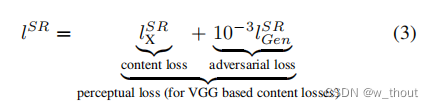
2.2.1 内容损失
像素级别的MSE损失如下:
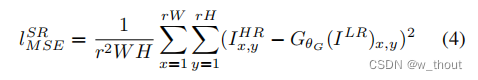
这是使用最广泛的SR问题的损失函数,但是可能导致感知上的缺失。
因此本文使用pre-train的19层VGG网络的ReLU激活层来定义VGG损失(内容损失):

Φi,j表示第i个最大池层之前的第j个卷积(激活后)得到的特征图,Wi,j、Hi,j表示VGG网络中各自的特征图的维数。
(也有点像均方误差?)
2.2.2 对抗性损失
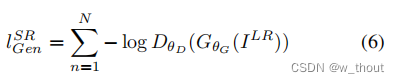
我的理解是跟原始GAN的生成器优化目标差不多。
3 实验
3.1 数据和相似度测量
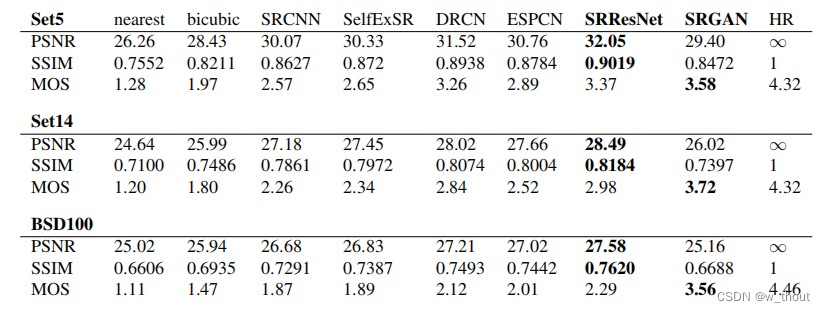
训练集:Set5,Set14和BSD100
测试集:BSD300
参考方法:最近邻、双边缘、SRCNN、SelfExSR、DRCN
3.2 训练详情和参数设置
使用降采样因子r=4的bicubic核对HR图像(BGR,C=3)进行降采样,获得LR图像。对于每个小批,我们随机裁剪16个96×96HR子图像(??)。
将LR输入图像的范围缩小到[0,1],将HR图像放大到[?1,1](??)。在强度范围内的图像上计算了MSE的损失[?1,1](??)。VGG特征图也被重新调整了1/12.75倍,以获得与MSE损失相当的VGG损失(??)。这相当于将方程5乘以≈0.006。使用β1=0.9的Adam优化器。SRResNet网络的学习速率分别为10?4和106次更新迭代。
训练时使用pre-train的基于MSE的SRResNet网络作为生成器的初始化。所有SRGAN变体都以10?4的学习速率进行105次更新迭代,并以10?5的学习速率进行105次迭代。生成器网络有16个相同的(B=16)残差块。在测试期间,关闭BN。
3.3 MOS测试
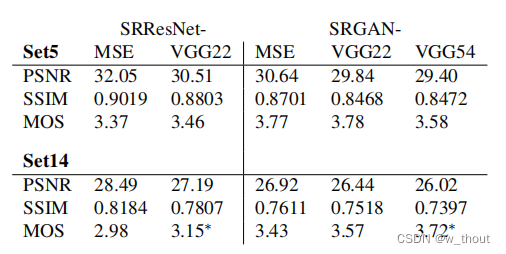
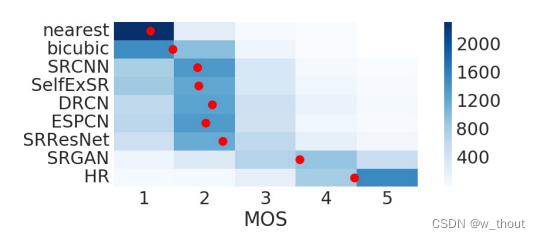
SRGAN-MSE:以标准MSE为内容loss的对抗性网络。
SRGAN-VGG22:代表较低层次特征的特征图上定义的损失。
SRGAN-VGG54:表示在更深网络层的更高级特征的特征图上定义的损失,更有可能关注图像的内容。下面我们将这个网络称为SRGAN。
3.5 最终的网络性能
SRGAN的方法大大优于所有方法,并为逼真图像SR奠定了新的技术。
4 讨论和未来的工作
所提出的模型没有对实时的视频SR进行优化。然而,对网络架构的初步实验表明,较浅的网络有潜力在小幅降低定性性能的前提下提供非常有效的替代方案。更深的SRResNet的性能会提高,但是训练和测试时间更长。由于高频伪影的出现,更深层次网络的SRGAN变体越来越难以训练。
当瞄准针对SR问题的逼真解决方案时,特别重要的是内容损失的选择。更深的网络层代表远离像素空间的更高抽象特征的潜力,因此也能产生感知上更令人信服的结果。这些更深层次的特征图纯粹关注内容,而让对抗性的损失关注纹理细节,这是没有对抗性损失的超分辨图像和逼真图像之间的主要区别。
理想的损失函数取决于应用场景。文本或结构场景的感知重建具有挑战性,是未来工作的一部分。通过描述图像空间内容,但对像素空间变化更不变的内容损失函数的发展,将进一步提高逼真的图像SR结果。
5 结论
本文描述了一个深度残差网络SRResGAN,它在使用广泛使用的PSNR测量方法进行评估时,在公共基准数据集上设置了一个新的技术状态。本文强调了这种PSNR聚焦图像超分辨率的一些局限性,并引入了SRGAN,它通过训练GAN的对抗性损失来增加内容损失函数。通过MOS测试,已经证实了对于大的缩放因子(4×)的SRGAN重建比用最先进的参考方法获得的重建更逼真。

