ResNet�Ľ�ԭ���������ıʼ�
Identity Mappings in Deep Residual Networks
Abstract
���ʣ��������һϵ�м������ϵ�ṹ,��ʾ�������ŷ���ȷ�Ժ����õ�������Ϊ���ڱ�����,���Ƿ�����ʣ����鱳��Ĵ�����ʽ,�������ʹ������ӳ����Ϊ�������Ӻͼӷ������,ǰ��ͺ����źſ���ֱ�Ӵ�һ���鴫�����κ������顣һϵ������ʵ��֤������Щ���ʽӳ�����Ҫ�������ʹ���������һ���µIJвԪ,��ʹѵ��������,����˷������������DZ�����ʹ��CIF AR10�ϵ�1001��ResNet(4.62%���)��CIF AR-100�Լ�ImageNet�ϵ�200��ResNet�ĸĽ����������ɴ�������ַ��ȡ:https://github.com/KaimingHe/resnet-1k-layers.
1 Introduction
��ʣ������(Resnet)[1]������ѵ��ġ�Residual Units����ɡ�ÿ����Ԫ(ͼ1(a))������һ����ʽ��ʾ:
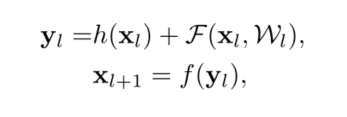
����, x l x_l xl?�� x l + 1 x_{l+1} xl+1?�ǵ�l����λ����������,F�Dzв������[1]��, h ( x l ) = x l h(x_l)=x_l h(xl?)=xl?��һ�����ʽӳ��,f��һ��ReLU[2]������
��ImageNet[3]��MS COCO[4]������,��ȳ���100���Resnet��ʾ�������Ƚ���ʶ��,�����ڶ��������ս�Ե�ʶ������resnet�ĺ���˼����ѧϰ���� h ( x l ) h(x_l) h(xl?)�ļ��Բв��F,�ؼ���ѡ����ʹ�ú��ӳ�� h ( x l ) = x l h(x_l)=x_l h(xl?)=xl?������ͨ�����ӱ�ʶ��������(��shortcut��)ʵ�ֵġ�
�ڱ�����,����ͨ������һ����ֱ�ӡ�·�����������ʣ������,��·��������ʣ�Ԫ�ڴ�����Ϣ,���������������д�����Ϣ�����ǵ��Ƶ�����,��� h ( x l ) h(x_l) h(xl?)�� f ( y l ) f(y_l) f(yl?)������λӳ��,��ô�źſ�������ǰ�����Ĺ����д�һ����λֱ�Ӵ������κ�������λ�����ǵ�ʵ�龭�����,����ϵ�ṹ���ӽ�������������ʱ,ѵ��ͨ�����ø����ס�
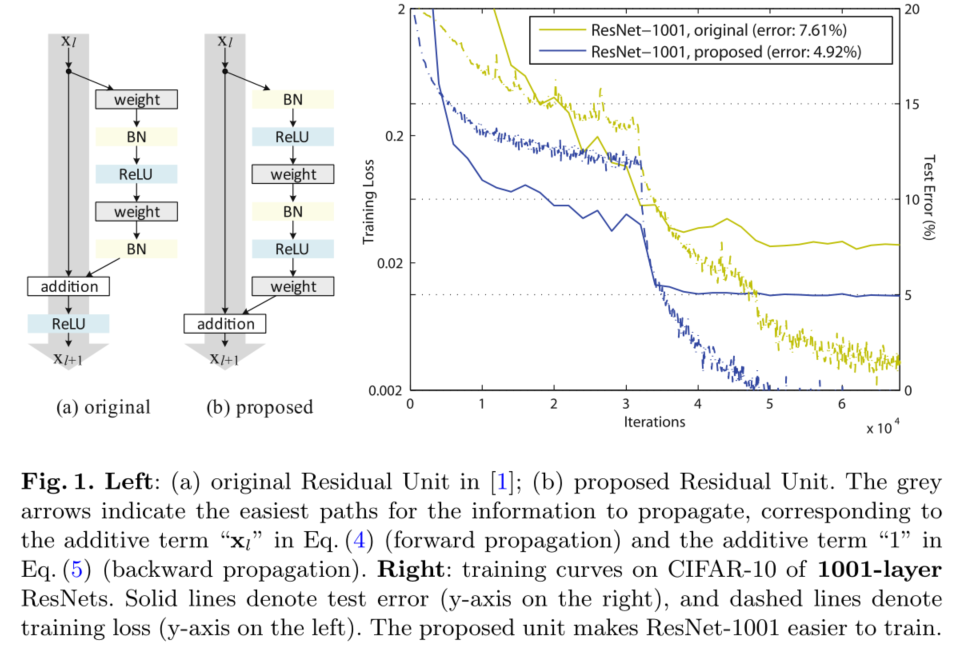
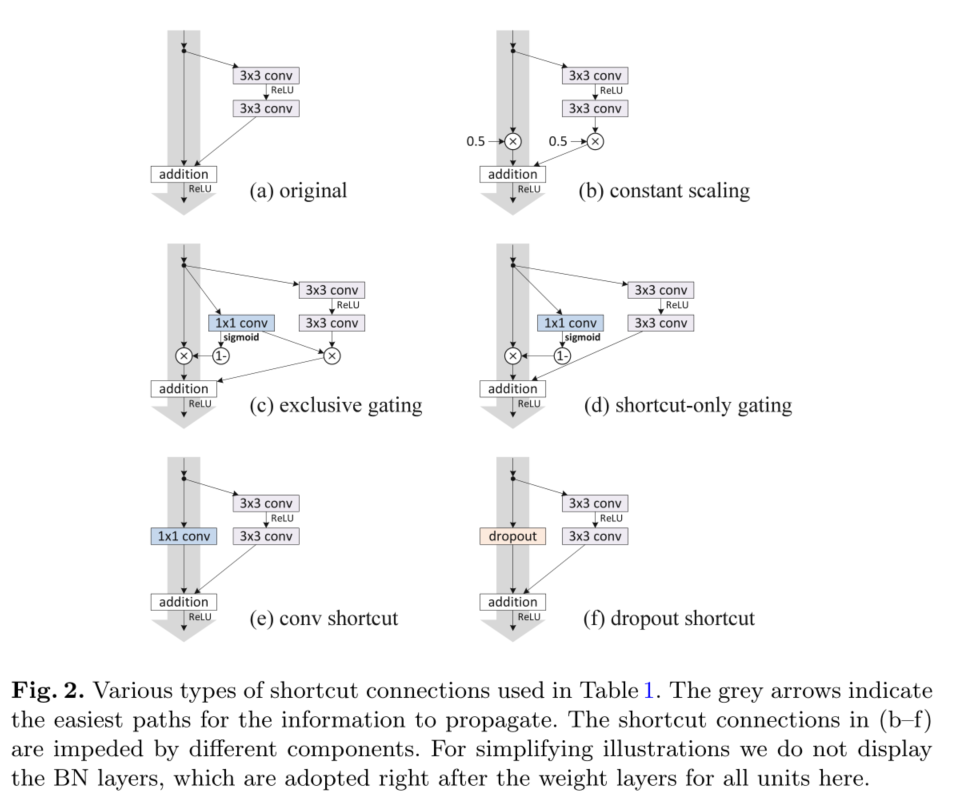
Ϊ��������ת���ӵ�����,���Ƿ����ͱȽ��˸������͵� h ( x l ) h(x_l) h(xl?)�����Ƿ���[1]��ѡ�������ӳ�� h ( x l ) = x l h(x_l)=x_l h(xl?)=xl? ,�������о������б�����,ʵ�������Ĵ�����ٺ���͵�ѵ����ʧ,�����š�ѡͨ[5�C7]��1��1�������������Ӷ��ᵼ�¸��ߵ�ѵ����ʧ�ʹ�������Щʵ�����,���֡��ɾ�������Ϣ·��(��ͼ1��ͼ2��ͼ4�еĻ�ɫ��ͷָʾ)�����ڼ��Ż���
Ϊ�˹�������ӳ�� f ( y l ) = y l f(y_l)=y_l f(yl?)=yl?,���ǽ������(ReLU��BN[8])��ΪȨ�ز�ġ�Ԥ���,���봫ͳ�ġ����ͬ�����ֹ۵㵼����һ���µIJвԪ���,��(ͼ1(b))��ʾ�����������Ԫ,���Ǹ�����CIFAR-10/100�ϵľ������,������һ��1001���ResNet,����[1]�е�ԭʼResNet������ѵ�����ƹ㡣���ǽ�һ��������ʹ��200��ResNet��ImageNet�ϵĸĽ����,����[1]�Ķ�Ӧ���ֿ�ʼ������ϡ���Щ�������,���������һ�ִ����ѧϰ�ɹ��Ĺؼ�ά�Ȼ��кܴ�Ŀ����ռ���
2 Analysis of Deep Residual Networks
[1]�п�����RESNET��һ��ģ�黯�ļܹ�,���Զѵ���ͬ������״�Ĺ����顣�ڱ�����,���dz���Щ��Ϊ��ʣ�Ԫ����[1]�е�ԭʼ�вλִ�����¼���:
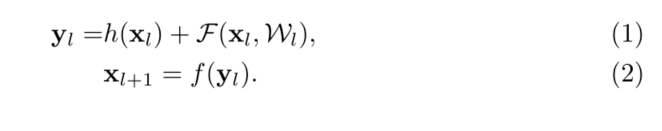
���� x l {x_l} xl?�ǵ�l��ʣ�λ������������ W l = W l , k �O 1 �� k �� K W_l={W_{l,k | 1��k��K}} Wl?=Wl,k�O1��k��K? �����l��ʣ�Ԫ�������һ��Ȩ��(��ƫ��),K��ʣ�Ԫ�еIJ���(K��[1]�е�2��3)��F��ʾ�в��,����[1]������3��3������Ķ�ջ������f��Ԫ����Ӻ�IJ���,[1]�е�f��ReLU������h������Ϊ����ӳ��: h ( x l ) = x l h(x_l)=x_l h(xl?)=xl?��
���fҲ��һ������ӳ��: x l + 1 �� y l x_{l+1}��y_l xl+1?��yl? ���ǿ��ѵ�ʽ(2)�ŵ���ʽ(1) �����:
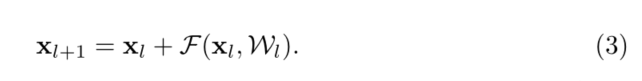
�ݹ�� ( x l + 2 = x l + 1 + F ( x l + 1 , W l + 1 ) = x l + F ( x l , W l ) + F ( x l + 1 , W l + 1 ) (x_{l+2}=x_{l+1}+F(x_{l+1},W_{l+1})=x_l+F(x_l,W_l)+F(x_{l+1},W_{l+1}) (xl+2?=xl+1?+F(xl+1?,Wl+1?)=xl?+F(xl?,Wl?)+F(xl+1?,Wl+1?)���ǽ���:
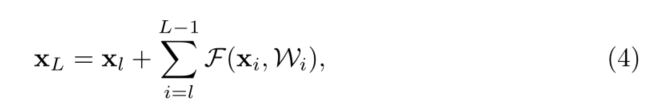
�����κν���ĵ�ԪL���κν�dz�ĵ�Ԫl,����(4)չʾ��һЩ�ܺõ����ʡ�(i) �κν��λL������ x L x_L xL?���Ա�ʾΪ�κν�dz��λL������ x L x_L xL?������ʽΪ �� i = l L ? 1 F \sum_{i=l}^{L-1} \mathcal{\mathcal { F }} ��i=lL?1?F,��ʾģ�����κε�λl��l֮�䴦��ʣ��״̬��(ii)���� x L = x 0 + �� i = 0 L ? 1 F ( x i , W i ) \mathbf{x}_{L}=\mathbf{x}_{0}+\sum_{i=0}^{L-1} \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right) xL?=x0?+��i=0L?1?F(xi?,Wi?),�κ���ȵ�λL������֮ǰʣ�ຯ��(����x0)�����֮�͡����롰��ͨ���硱�γɶԱ�,�ڡ���ͨ���硱��,���� x L x_L xL?��һϵ�о���������, �� i = 0 L ? 1 W i x 0 \prod_{i=0}^{L-1} W_{i} \mathbf{x}_{0} ��i=0L?1?Wi?x0?(����BN��ReLU)��
����(4)���������õ���������������ʧ������ʾΪ �� \varepsilon ��,���ݷ�������ʽ����[9]:
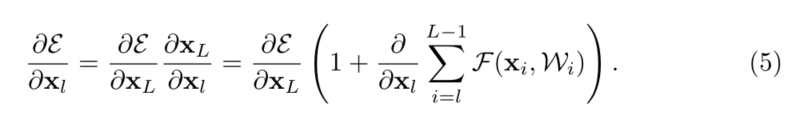
��ʽ(5)�����ݶ� ? �� ? x l \frac{\partial \varepsilon }{\partial x_l} ?xl??��?���Էֽ�Ϊ���������:һ���� ? �� ? x L \frac{\partial \varepsilon }{\partial x_L} ?xL??��?ֱ�Ӵ�����Ϣ,���漰�κ�������,�Լ� ? E ? x L ( ? ? x l �� i = l L ? 1 F ) \frac{\partial \mathcal{E}}{\partial \mathbf{x}_{L}}\left(\frac{\partial}{\partial \mathbf{x}_{l}} \sum_{i=l}^{L-1} \mathcal{\mathcal { F }}\right) ?xL??E?(?xl???��i=lL?1?F)ͨ��Ȩ�ز㴫���� ? �� ? x L \frac{\partial \varepsilon }{\partial x_L} ?xL??��?�ļӷ���ȷ����Ϣ���Դ������κν�dz�ĵ�λl������ʽ(5)Ҳ�����ݶ� ? �� ? x l \frac{\partial \varepsilon }{\partial x_l} ?xl??��?��̫���ܱ�ȡ������һ��С����,��Ϊһ����˵ ? ? x l �� i = l L ? 1 F \frac{\partial}{\partial \mathbf{x}_{l}} \sum_{i=l}^{L-1} \mathcal{\mathcal { F }} ?xl???��i=lL?1?F����С�����е�������Ʒ����ʼ��Ϊ-1������ζ��,��ʹȨ������С,����ݶ�Ҳ������ʧ�� (��ֹ�ݶ���ʧ)
Discussions.
��ʽ(4)��(5)����,�źſ���ֱ�Ӵ��κε�Ԫ��ǰ���������һ����Ԫ����ʽ(4)�Ļ������������ʽӳ��:(i)���ʽ�������� h ( x l ) = x l h(x_l)=xl h(xl?)=xl,�Լ�(ii)f�Ǻ��ʽӳ���������
��Щֱ�Ӵ�������Ϣ����ͼ�еĻ�ɫ��ͷ��ʾ��1��2��4������Щ��ɫ��ͷ�������κβ���(������֮��),����ǡ��ɾ���ʱ,���������������ȷ�ġ��ڽ���������������,���ǽ��ֱ��о����������(���ӳ�����ӺͲ�����)��Ӱ�졣
3 On the Importance of Identity Skip Connections
�����ǿ���һ������, h ( x l ) = �� l x l h(x_l)=��_lx_l h(xl?)=��l?xl?,�Դ������ݿ�ݷ�ʽ:
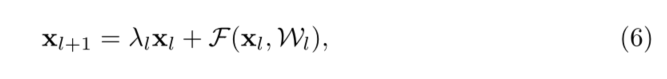
���� �� l ��_l ��l?��һ�����Ʊ���(Ϊ�˼����,������Ȼ����f�Ǻ��ʽ)���ݹ��Ӧ�������ʽ,���ǵõ���һ��������ʽ(4)�ķ���:
x L = ( �� i = l L ? 1 �� i ) x l + �� i = l L ? 1 ( �� j = i + 1 L ? 1 �� j ) F ( x i , W i ) \mathbf{x}_{L}=\left(\prod_{i=l}^{L-1} \lambda_{i}\right) \mathbf{x}_{l}+\sum_{i=l}^{L-1}\left(\prod_{j=i+1}^{L-1} \lambda_{j}\right) \mathcal{F}\left(\mathbf{x}_{i}, \mathcal{W}_{i}\right) xL?=(��i=lL?1?��i?)xl?+��i=lL?1?(��j=i+1L?1?��j?)F(xi?,Wi?) �ɵõ�:
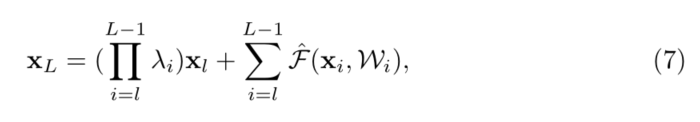
����,���� F ^ \hat{\mathcal{F}} F^���������յ�ʣ�ຯ���С���ʽ(5)����,������������ʽ�ķ���:
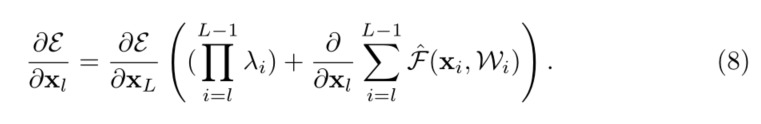
�빫ʽ(5)��ͬ,�ڹ�ʽ(8)��,��һ���ӷ�����һ�����ӵ��� �� i = l L ? 1 �� i \prod_{i=l}^{L-1} \lambda_{i} ��i=lL?1?��i?,���ڼ��������(L�Ǵ��),�����i>1,������ӿ�����ָ�����;�������i�Ħ�i<1,������ӿ���ָ��С����ʧ,�����ֹ�������ź�ͨ����(shortcut)�ݷ�ʽ,����ʹ������Ȩ�ز㡣��������ͨ��ʵ��������������,��ᵼ���Ż����ѡ�
������������,��ʽ(3)i�е�ԭʼ��ʶ�������ӱ������� h ( x l ) = �� l x l h(x_l)=��_lx_l h(xl?)=��l?xl?�滻������������� h ( x l ) h(x_l) h(xl?)��ʾ�����ӵı任(����ѡͨ��1��1����),���ڵ�ʽ(8)��,��һ���� �� i = l L ? 1 h i �� \prod_{i=l}^{L-1} h_{i}^{'} ��i=lL?1?hi��?����� h �� h^{'} h����h��������ù���Ҳ���ܻ��谭��Ϣ����,��������ѵ����,������ʵ����ʾ�� (����shortcut����һ·������Ҫ���Ӳ���,�����谭��Ϣ����,�ͷ���)
3.1 Experiments on Skip Connections
������110���ResNet������ʵ��,��[1]����������������ResNet-110��54������ʣ�Ԫ(����3��3������),���Ҷ��Ż�������ս�ԡ����ǵ�ʵʩϸ��(����¼)��[1]��ͬ���ڱ�����,���DZ�����CIFAR��ÿ�ּܹ�5�����е�ƽ������,�Ӷ�����������仯��Ӱ�졣
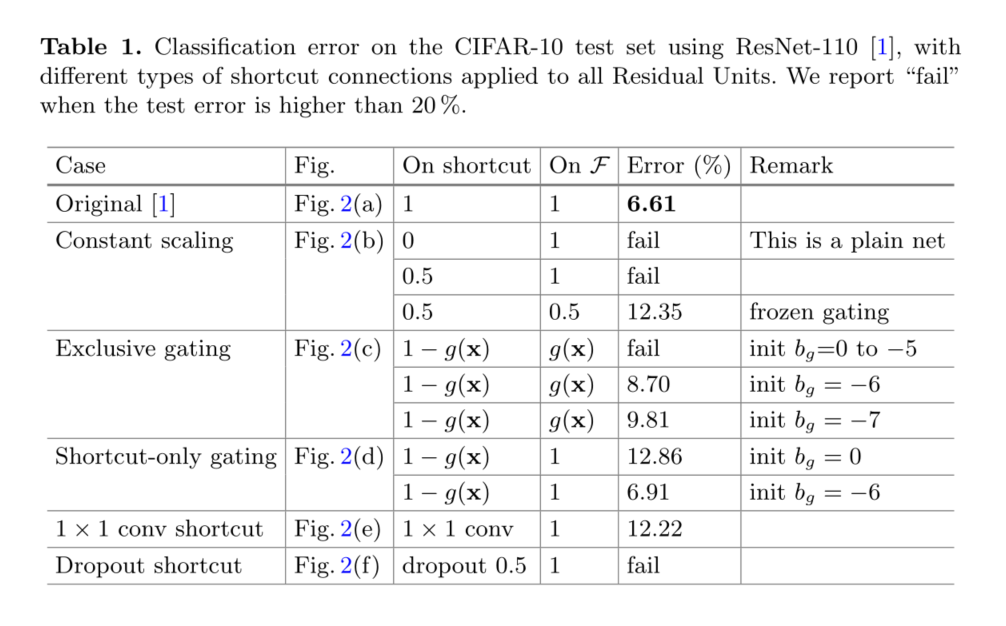
��Ȼ���ǵ����������������ʽf������,�������е�ʵ�鶼�ǻ���f=ReLU as in[1];��������һ������������f�����ǵĻ���ResNet-110�ڲ��Լ�����6.61%�Ĵ�����������(ͼ2�ͱ�1)�ıȽ��ܽ�����:
Constant Scaling
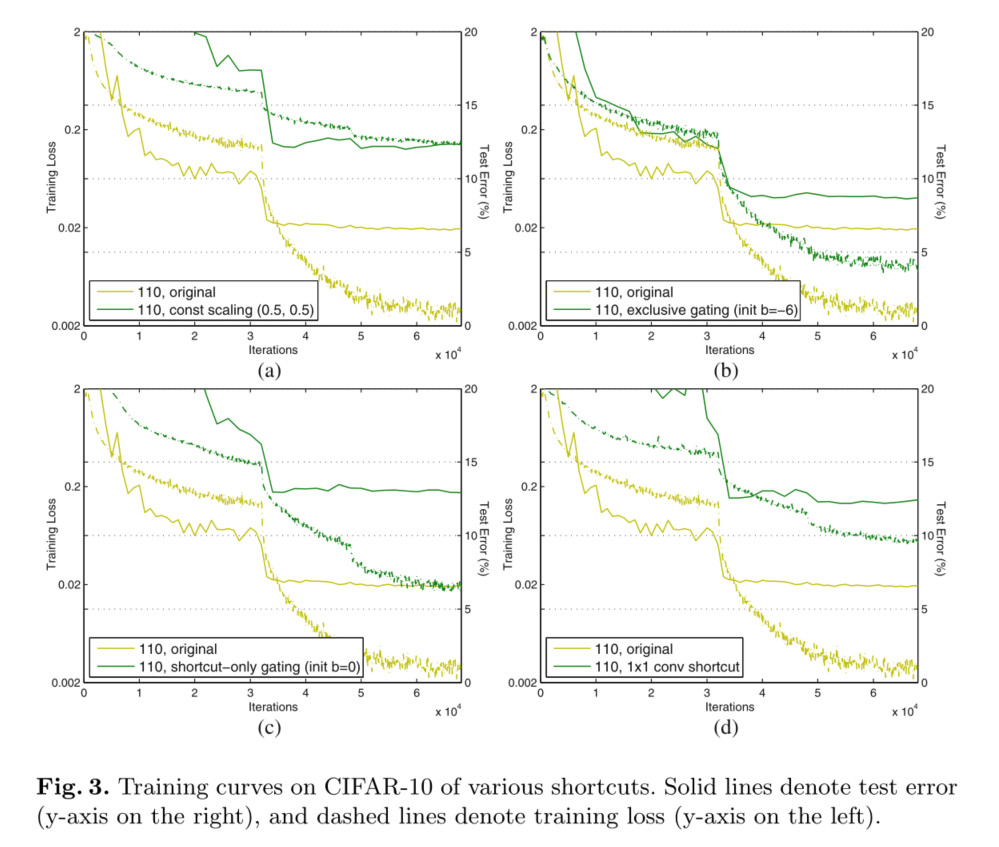
�������нݾ�,�������æ�=0.5(ͼ2(b))�����ǽ�һ���о��˱��F���������:(i)F�����;����(ii)F������Ϊ1?��=0.5�ij�������,��highway gating[6,7]����,������frozen gates��ǰһ������������Բ���;�����ܹ�����,���������(��1,12.35%)Զ����ԭʼResNet110(���ֲ�)��ͼ3(a)��ʾ,ѵ��������ԭʼResNet-110,��������ݾ��ź���Сʱ,�Ż�����������
Exclusive Gating
���ݲ���ѡͨ����[5]�Ĺ�·��[6,7],���ǿ���ѡͨ���� g ( x ) = �� ( W g x + b g ) g(x)=��(W_gx+b_g) g(x)=��(Wg?x+bg?),���б任��Ȩ��Wg��ƫ��bg��ʾ,Ȼ����sigmoid���� �� ( x ) = 1 1 + e ? x \sigma(x)=\frac{1}{1+e^{-x}} ��(x)=1+e?x1?���ھ���������,g(x)��1��1������ʵ�����ſع���ͨ��Ԫ������������źš�
�����о���[6,7]��ʹ�õġ�exclusive���š���F·����g(x)����,���·����1? g(x)���š���ͼ2(c)�����Ƿ���,ƫ�� b g b_g bg?�ij�ʼ������ѵ��ѡͨģ��������Ҫ,����[6,7]�е���2,������0��-10�ķ�Χ�ڶ�bg�ij�ʼֵ���г���������,ͨ��������֤��ѵ�������еݼ�����Ϊ-1������**����Ѽ�ֵ(?6)**����ѵ������ѵ��,���Խ��Ϊ8.70%(��1),��ȻԶԶ�����ResNet-110���ߡ�ͼ3(b)��ʾ��ѵ�����ߡ���1��������ʹ��������ʼ��ֵ�Ľ��,ָ����bgû���ʵ���ʼ��ʱ,��ռѡͨ���粻��������һ���õĽ��������
������ѡͨ���Ƶ�Ӱ����˫�ص�����1? g(x)�ӽ�1,�ſؿ�����Ӹ��ӽ�����,��������Ϣ����;�������������,g(x)�ӽ�0,�����ƺ���F��Ϊ�˵�������ѡͨ�����Կ��·����Ӱ��,��������һƪ�������о��˷�����ѡͨ���ơ�
Shortcut-Only Gating
�����������,����F��������;ֻ�п��·����1? g(x)ѡͨ����ͼ2(d)�������������,bg�ij�ʼ��ֵ��Ȼ����Ҫ������ʼ����bgΪ0ʱ(������Ԥ��Ϊ1? g(x)Ϊ0.5),����������12.86%�Ľϲ���(��1)����Ҳ���ɽϸߵ�ѵ�������ɵ�(ͼ3(c))��
����ʼ����bg�dz���ƫʱ(����?6) ,ֵΪ1?g(x)���ӽ�1,������Ӽ�����һ������ӳ�䡣���,���(6.91%,��1)���ӽ�ResNet-110���ߡ�
**1��1 Convolutional Shortcut. **
������,������1��1��������������������ݡ�[1](��Ϊѡ��C)��34��ResNet(16��ʣ�Ԫ)�ϵĸ�ѡ��������о�,����ʾ�����õĽ��,����1��1������ӿ��������������Ƿ���,��������ʣ�Ԫʱ,���������ˡ���ʹ��1��1�����ݾ�ʱ,110��ResNet�Ľ���ϲ�(12.22%,��1)��ͬ��,ѵ������ø���(ͼ3(d))����������˶���ʣ�Ԫ(ResNet-110Ϊ54)ʱ,��ʹ�����·��Ҳ���ܻ��谭�źŴ�������ʹ��1��1�����ݾ�ʱ,�����ڴ���ResNet-101��ImageNet�Ͽ��������Ƶ�����
Dropout Shortcut
���,������Dropout[11](����Ϊ0.5)������ʵ��,���������ݿ�ݷ�ʽ������ϲ�����Dropout[11](ͼ2(f))������δ��������һ���õĽ����������ͳ��ѧ�Ͻ�,Dropout���ڽݾ���ʩ��һ���˵ı��,����ֵΪ0.5,�볣�����0.5����,�����谭�źŴ�����
3.2 Discussions
��ͼ2�еĻ�ɫ��ͷ��ʾ,�����������Ϣ��������ֱ��·������ݷ�ʽ�ϵij˷�����(���š�ѡͨ��1��1�������˳�)���谭��Ϣ�����������Ż����⡣
ֵ��ע�����,�ſغ�1��1�����ݾ������˸���IJ���,����Ӧ�ñ����ݽݾ����и�ǿ�ı�����������ʵ��,����ݷ�ʽѡͨ��1��1�������������ݿ�ݷ�ʽ�Ľ�ռ�(��,���ǿ�����Ϊ���ݿ�ݷ�ʽ�����Ż�)��Ȼ��,���ǵ�ѵ�����������ݽݾ�,�������Щģ�͵��˻������Ż����������,�������ɱ��������������
�ܽ�:��ž���˵�в��shortcut��֧�ϲ�Ҫ���κζ���,����ԭ����Ϣ����
4 On the Usage of Activation Functions
�Ͻ��е�ʵ��֧�ֵ�ʽ(5) ��(8)�еķ���,�����ڼ���ӳɺ�fΪ����ӳ�䡣���������ʵ����,f��[1]����Ƶ�ReLU,���Է���(5) ��(8)������ʵ�����ǽ��Ƶġ������������о�f��Ӱ���� (�������ʹ��)
������ͨ�����°��ż����(ReLU��/��BN)����������ӳ�䡣ԭʼ�в�ṹ��ͼ4(a)-��ÿ��Ȩ�ز�֮��ʹ��BN,��BN֮�����ReLU,��ʣ�Ԫ�е����һ��ReLU����Ԫ�����֮��(f=ReLU)��ͼ4(b-e)��ʾ�����ǵ���ı�ѡ����,�������¡�
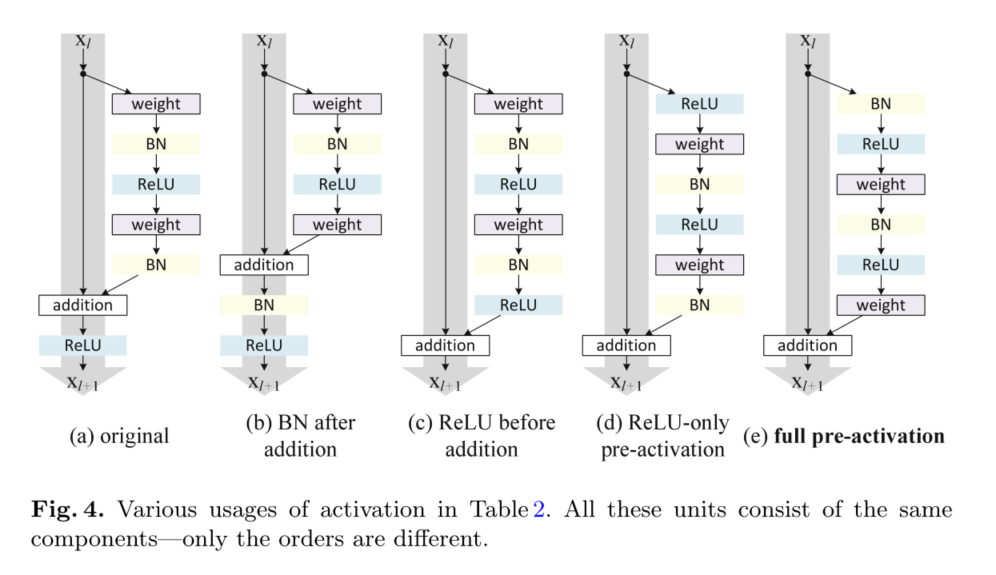
4.1 Experiments on Activation
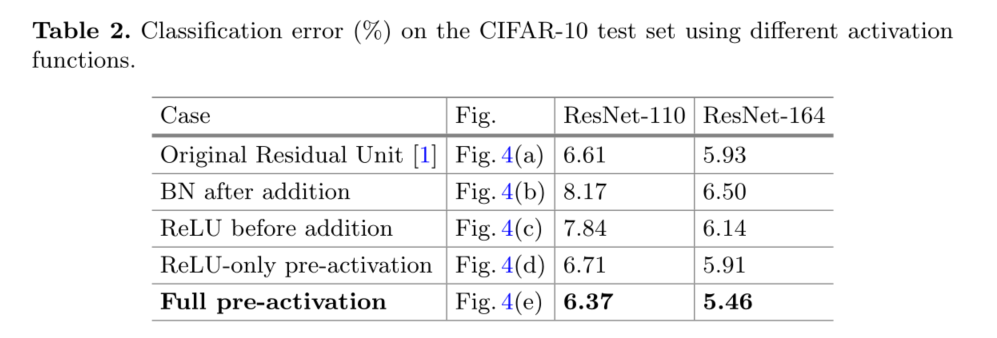
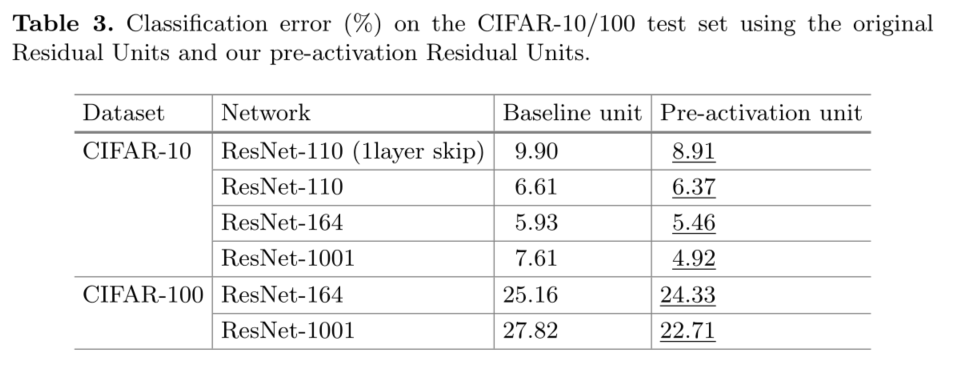
�ڱ�����,���ǽ���ResNet-110��164��ƿ��[1]��ϵ�ṹ(��ʾΪResNet-164)����ʵ�顣ƿ��ʣ�Ԫ��1��1�㽵ά��3��3���1��1��ָ�ά��ɡ���[1]�����,����㸴�Ӷ�����������3��3�вԪ������ϸ�ڼ���¼����ResNet-164��CIFAR-10�ϵľ������Ϊ5.93%(��2)��
BN After Addition
�ڽ�fת��Ϊ���ʽӳ��֮ǰ,���Dz�ȡ�෴�ķ���,�ڼӷ������BN(ͼ4(b))�������������,f�漰BN��ReLU������Ȼ��߲�ö�(��2)�����������Ʋ�ͬ,����BN��ı���ͨ���ݾ����ź�,���谭����Ϣ����,�ⷴӳ��ѵ����ʼʱ����ѵ����ʧ��������(ͼ6��)��
ReLU Before Addition
��fת��Ϊ���ʽӳ���һ����ѡ������Addition֮ǰ�ƶ�ReLU(ͼ4(c))��Ȼ��,��ᵼ�±任F�ķǸ����,��ֱ����,���в����Ӧ��ȡֵ(?��, +��). ���,ǰ�����ź��ǵ������ӵġ�����ܻ�Ӱ���������,����Ȼ��߲�(7.84%,��2)������������һ����ֵ����(?��, +��). ����ʣ�Ԫ(�������µ�Ԫ)�����������
Post-activation or Pre-activation?
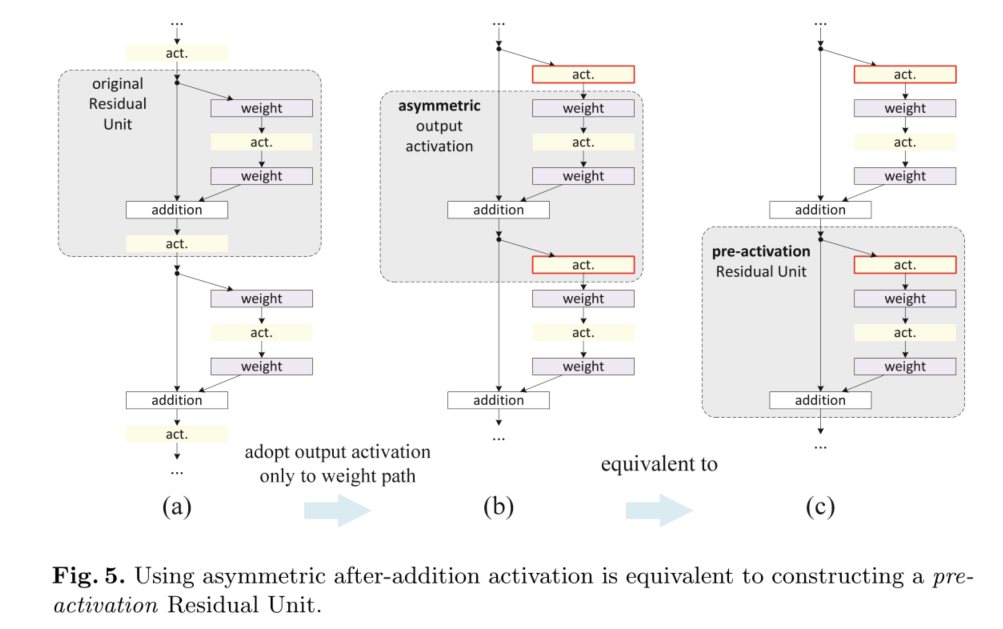
��ԭʼ���(��ʽ(1)��(2))��,���� x l + 1 = f ( y l ) x_{l+1}=f(y_l) xl+1?=f(yl?)��Ӱ����һ��ʣ�Ԫ�е�����·��: y l + 1 = f ( y l ) + F ( f ( y l ) , W l + 1 y_{l+1}=f(y_l)+F(f(y_l),W_{l+1} yl+1?=f(yl?)+F(f(yl?),Wl+1?��������,���ǿ�����һ�ֲ��Գ���ʽ,���м��� f ^ \hat{f} f^?ֻӰ��f·��:�����κ�l(ͼ5(a)��(b)), y l + 1 = y l + F ( f ^ ( y l ) , W l + 1 ) \mathbf{y}_{l+1}=\mathbf{y}_{l}+\mathcal{F}\left(\hat{f}\left(\mathbf{y}_{l}\right), \mathcal{W}_{l+1}\right) yl+1?=yl?+F(f^?(yl?),Wl+1?)��ͨ������������,���ǵõ���������ʽ:
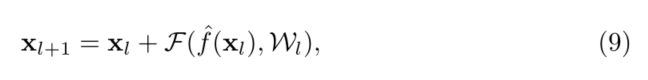
��������,ʽ(9)������ʽ(4),���ҿ���ʵ��������ʽ(5)�ķ���ʽ�����ڵ�ʽ(9)�е��²��Ԫ,�µļӳɺ��Ϊ���ʽӳ�䡣��������ζ��������ԳƲ����µ����Ӻ� f ^ \hat{f} f^?,���൱���������� f ^ \hat{f} f^?��Ϊ��һ��ʣ�Ԫ��Ԥ����������ͼ5��ʾ��
��/Ԥ����֮�����������Ԫ�����ӵĴ����������������N������ͨ����,��N?1�㼤��(BN/ReLU),������Ϊ������������Ǽ���ǰ������Ҫ��������ͨ�����Ӻϲ�����֧��,�����λ�ú���Ҫ��
������������������ƽ�����ʵ��:(i)��ReLUԤ����(ͼ4(d)),��(ii)��ȫԤ����(ͼ4(e)),����BN��ReLU����������֮ǰ���á���2��ʾ,����ReLU��Ԥ����������ResNet-110/164�ϵĻ����dz���������ReLU��δ��BN����ʹ��,����������BN�ĺô�[8]�� (��ʹ��ReLu������һЩ)
��֪�ι�,���˾��ȵ���,��BN��ReLU������Ԥ����ʱ,����õ������õĸ���(��2�ͱ�3)���ڱ�3��,���DZ�����ʹ�ø��ּܹ��Ľ��:(i)ResNet-110,(ii)ResNet-164,(iii)һ��110���ResNet�ܹ�,����ÿ����ݷ�ʽֻ����1��(��,һ��ʣ�Ԫֻ��1��),��ʾΪ��ResNet-110(1��)��,�Լ�(iv)һ��1001���ƿ���ܹ�,��333��ʣ�Ԫ(ÿ������ͼ��С����111��),��ʾΪ��ResNet-1001�������ǻ���CIFAR100������ʵ�顣��3��ʾ,���ǵġ�Ԥ���ģ��ʼ�����ڻ�ģ�͡����������������Щ�����
4.2 Analysis
���Ƿ���Ԥ�����Ӱ����˫�صġ�����,����f��һ������ӳ��,����Ż�����һ����(�����ResNet���)���ڶ�,ʹ��BN��ΪԤ����Ľ���ģ�͵�������
Ease of Optimization
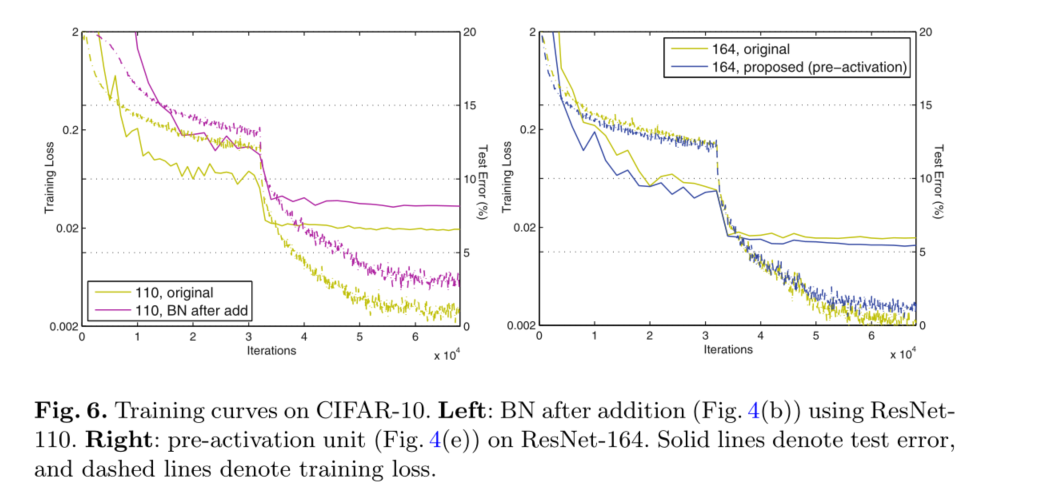
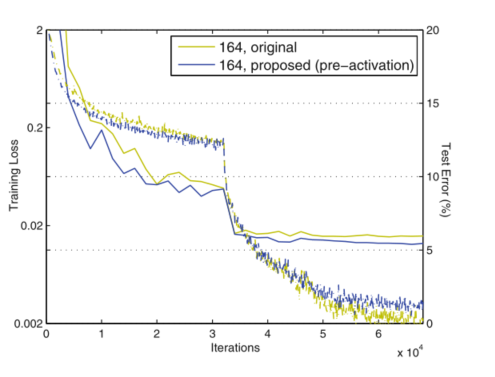
����Ч����ѵ��1001��ResNetʱ��Ϊ���ԡ�ͼ1��ʾ����Щ���ߡ�ʹ��[1]�е�ԭʼ���,��ѵ����ʼʱ,ѵ������dz������ؼ�С������f=ReLU,����ź�Ϊ��,���źŻ��ܵ�Ӱ��,����������ʣ�Ԫʱ,����Ӱ���������,��ʽ(3)(SOEq.(5))����һ���ܺõĽ���ֵ����һ����,��f�ǵ�λӳ��ʱ,�źſ���ֱ��������������Ԫ֮�䴫�������ǵ�1001��������Ժܿ����ѵ����ʧ(ͼ1)���������о�������ģ����,��Ҳʵ������͵���ʧ,������Ż��dzɹ��ġ�
���ǻ�����,��ResNet���н��ٵIJ�ʱ,f=ReLU��Ӱ�첢������(����,ͼ6(��)�е�164)����ѵ����ʼʱ,ѵ�������ƺ��е�����,���ܿ�ͻ���뽡��״̬��ͨ����ⷴӦ,���ǹ۲쵽,������Ϊ����һЩѵ����,Ȩ�ر�������һ��״̬,ʹ�õ�ʽ(1)�е� y l y_l yl?��Ƶ����λ�ڳ���0����f����ض���(����֮ǰ��ReLU, x l x_l xl?���ǷǸ���,����ֻ�е�f�Ĵ�С�dz���ʱ, y l y_l yl?�ŵ�����)��Ȼ��,����1000��ʱ,�ضϸ�ΪƵ����
Reducing Overfitting.
ʹ�ý����Ԥ���Ԫ����һ��Ӱ��������,��ͼ6(��)��ʾ��Ԥ����汾������ʱ�ﵽ���ߵ�ѵ����ʧ,�������ϵ͵IJ������������������CIFAR-10��100�ϵ�ResNet-110��ResNet-110(1��)��ResNet-164�϶����Թ۲쵽�����������BN������ЧӦ�����[8]����ԭʼ�вԪ(ͼ4(a))��,����BNʹ�źű���,����ܿ챻���ӵ���ݷ�ʽ��,��˺ϲ����ź�û�б�����Ȼ��,�÷DZ����źű�������һȨ�ز�����롣�෴,�����ǵ�Ԥ����汾��,����Ȩ�ز�����붼�ѱ�����
5 Results
��
6 Conclusions
�����о�����ʣ���������ӻ��Ʊ���Ĵ�����ʽ�����ǵ��Ƶ�����,���ݿ�����������Ӽ�������������ʹ��Ϣ����˳��������Ҫ������ʵ��֤���������ǵ��Ƶ�һ�µ��������ǻ��ṩ��1000���������,��������ѵ������߾��ȡ�

